







一、卷积神经网络
1、发展历程:
AlexNet (2012)>>Going Deeper (2012~2014)>>VGG (2014)>>VGG (2014)>>GoogLeNet (Inception v1, 2014)
2、精度退化问题
模型层数增加到一定程度后,分类正确率不增反降。
二、残差
1、残差学习基本思路

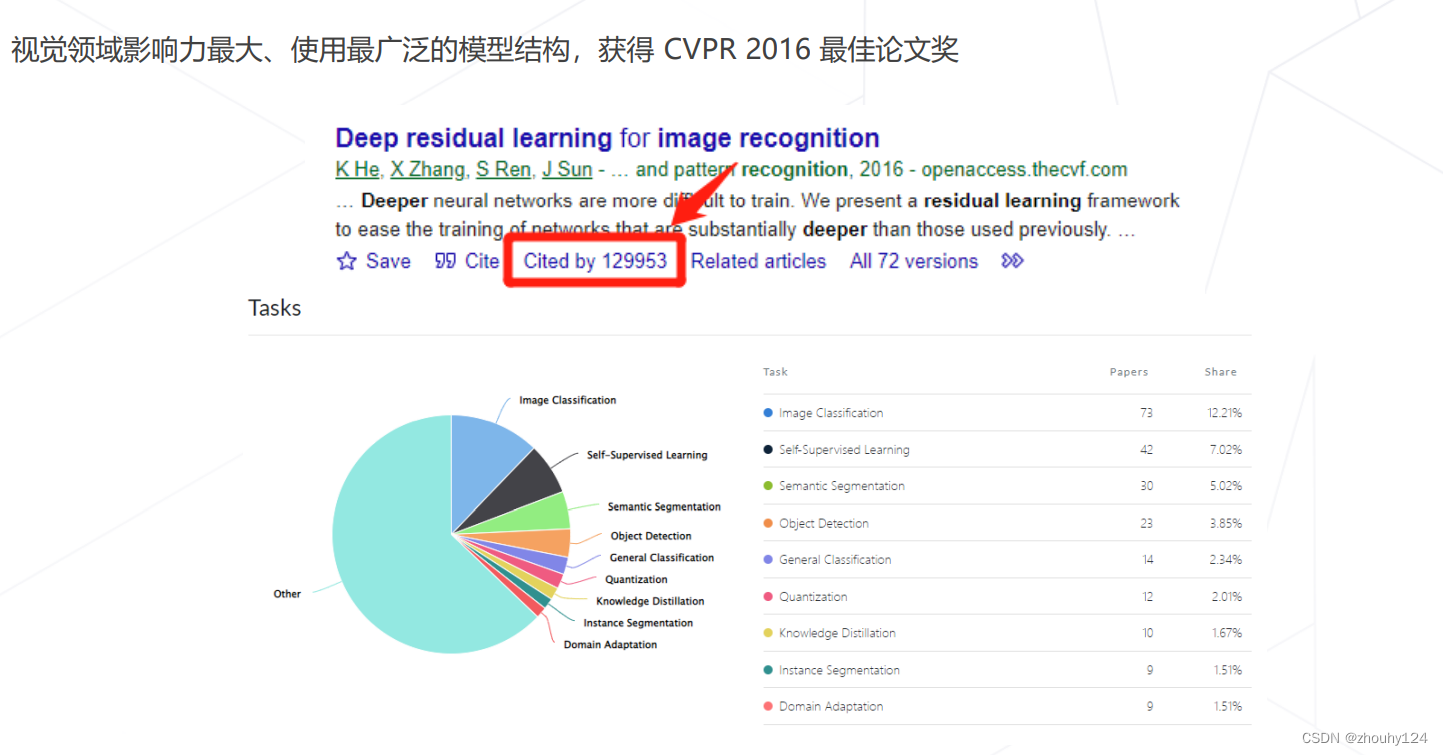
2、残差网络ResNet (2015)
以 VGG 为基础、保持多级结构、增加层数、增加跨层连接
两种残差模块:

成就及影响力:
优点:等同于多模型集成、残差链接让损失曲面更平滑
三、更强的的图像分类模型
1、神经结构搜索 Neural Architecture Search (2016+)
基本思路:借助强化学习等方法搜索表现最佳的网络
代表工作:NASNet (2017)、MnasNet (2018)、EfficientNet (2019) 、RegNet (2020) 等
2、Vision Transformers (2020+)
使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度。
代表工作:Vision Transformer (2020),Swin-Transformer (2021 ICCV 最佳论文)
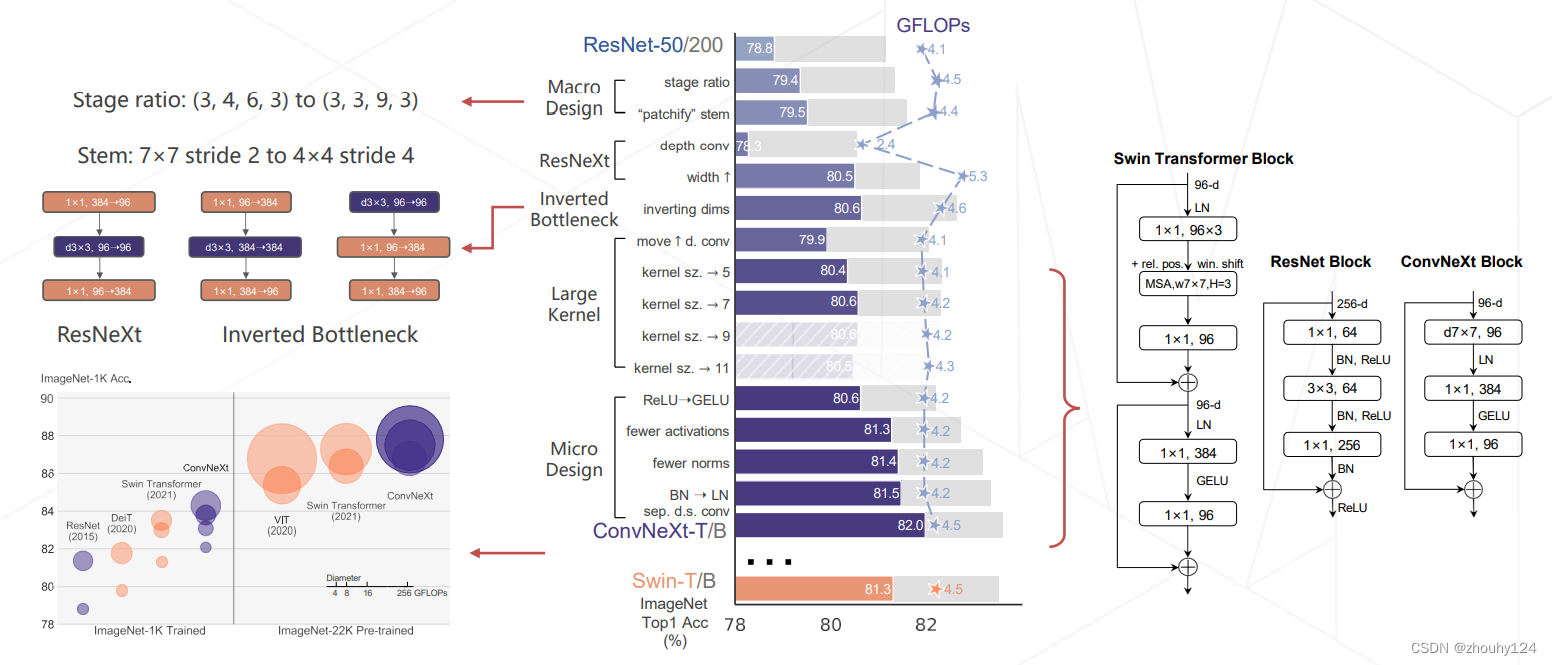
3、ConvNeXt (2022)
将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer
四、轻量化卷积神经网络
这部分主要讲解了卷积的参数量、卷积的计算量(乘加次数)、降低模型参数量和计算量的方法、GoogLeNet 使用不同大小的卷积核、ResNet 使用1×1卷积压缩通道数、可分离卷积、MobileNet V1/V2/V3 (2017~2019)、ResNeXt 中的分组卷积、
五、Vision Transformers
1、注意力机制 Attention Mechanism
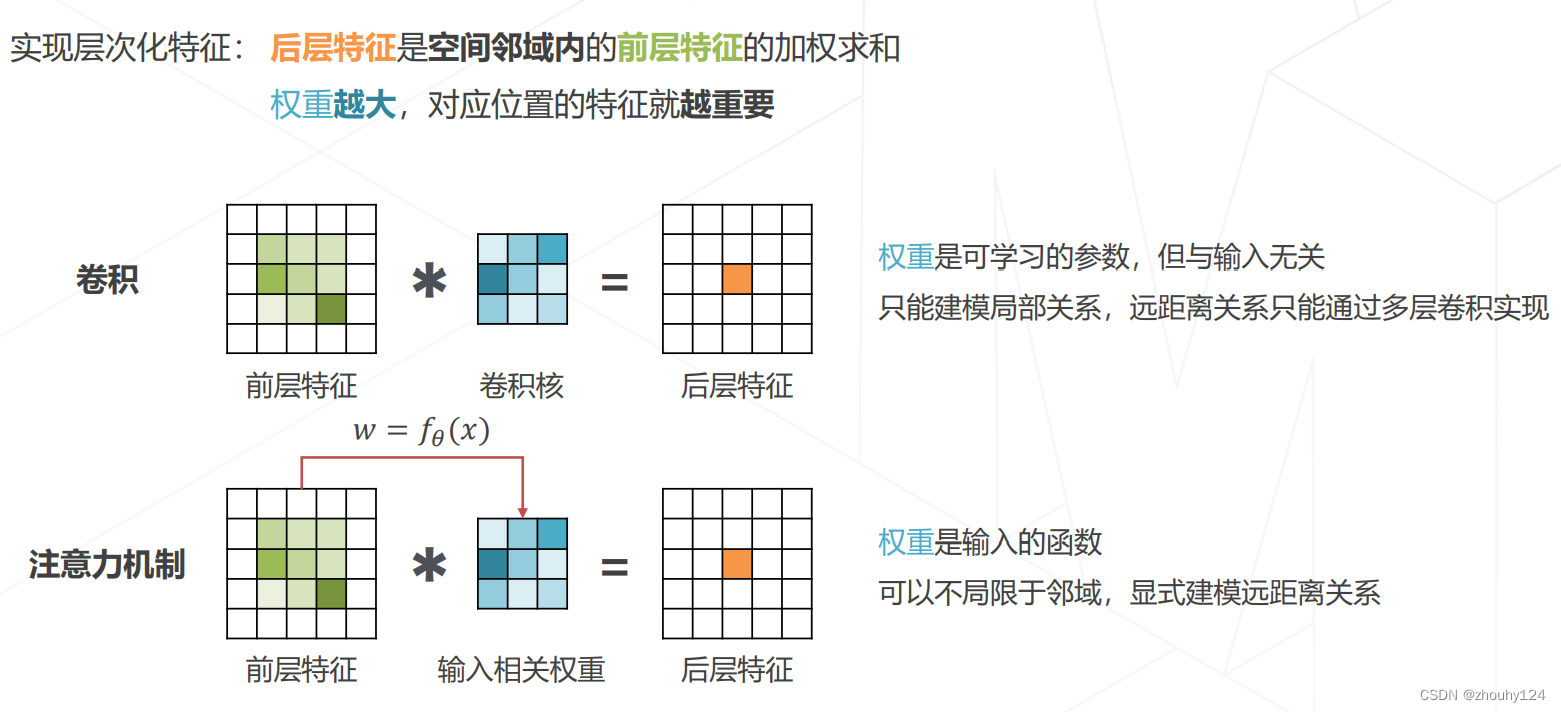
2、Why Attention

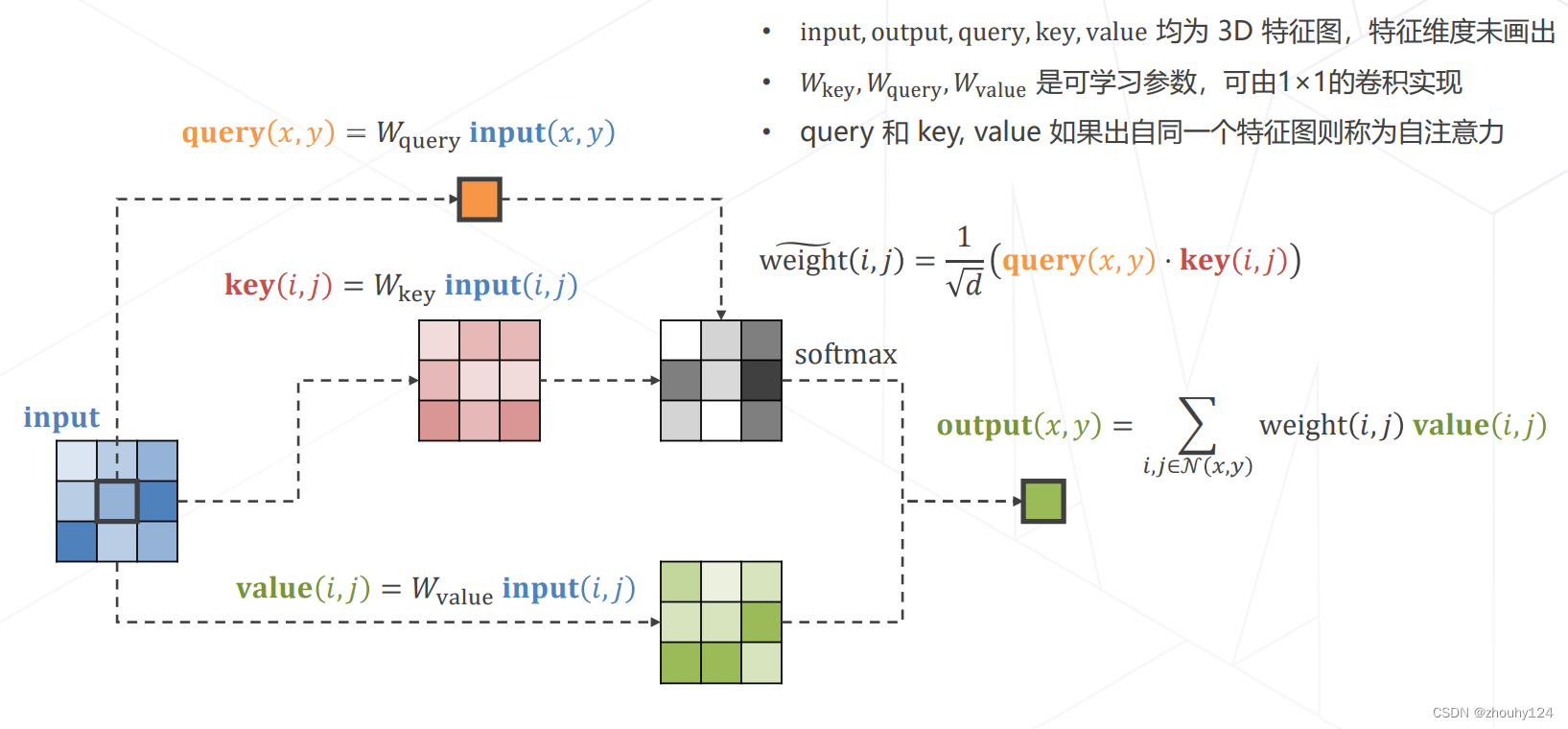
3、实现 Attention
4、多头注意力 Multi-head (Self-)Attention

5、1D 数据上的 Attention
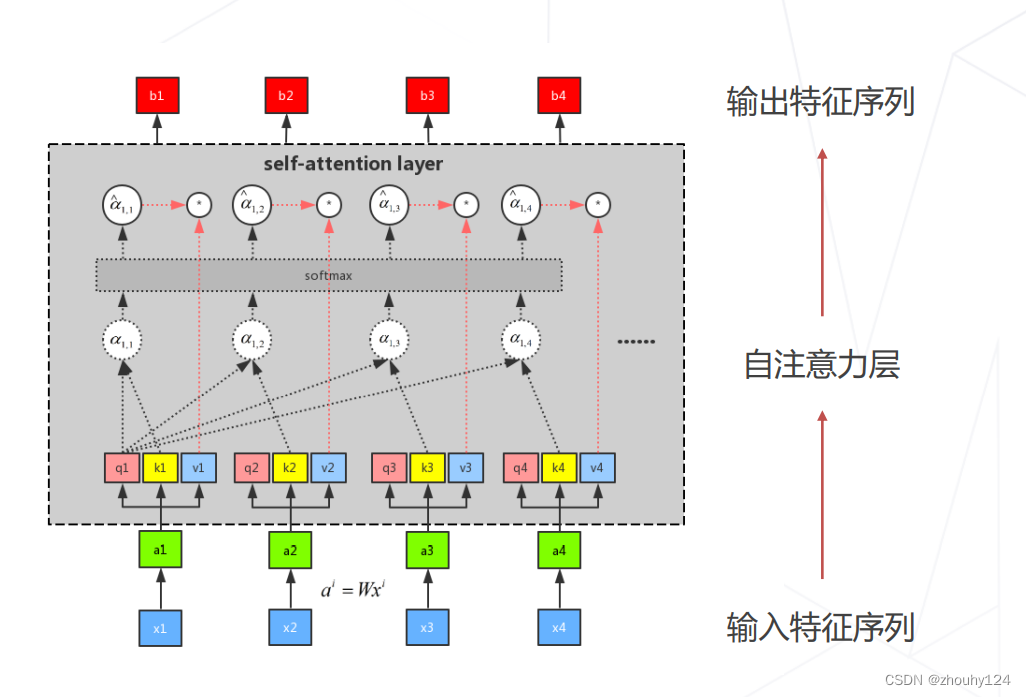
6、Vision Transformer (2020)
将图像切分成若干 16×16 的小块,当作一列"词向量",经多层 Transformer Encoder 变换产生特征
图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
注意力模块基于全局感受野,复杂度为尺寸的 4 次方
7、Swin Transformer (ICCV 2021 best paper)

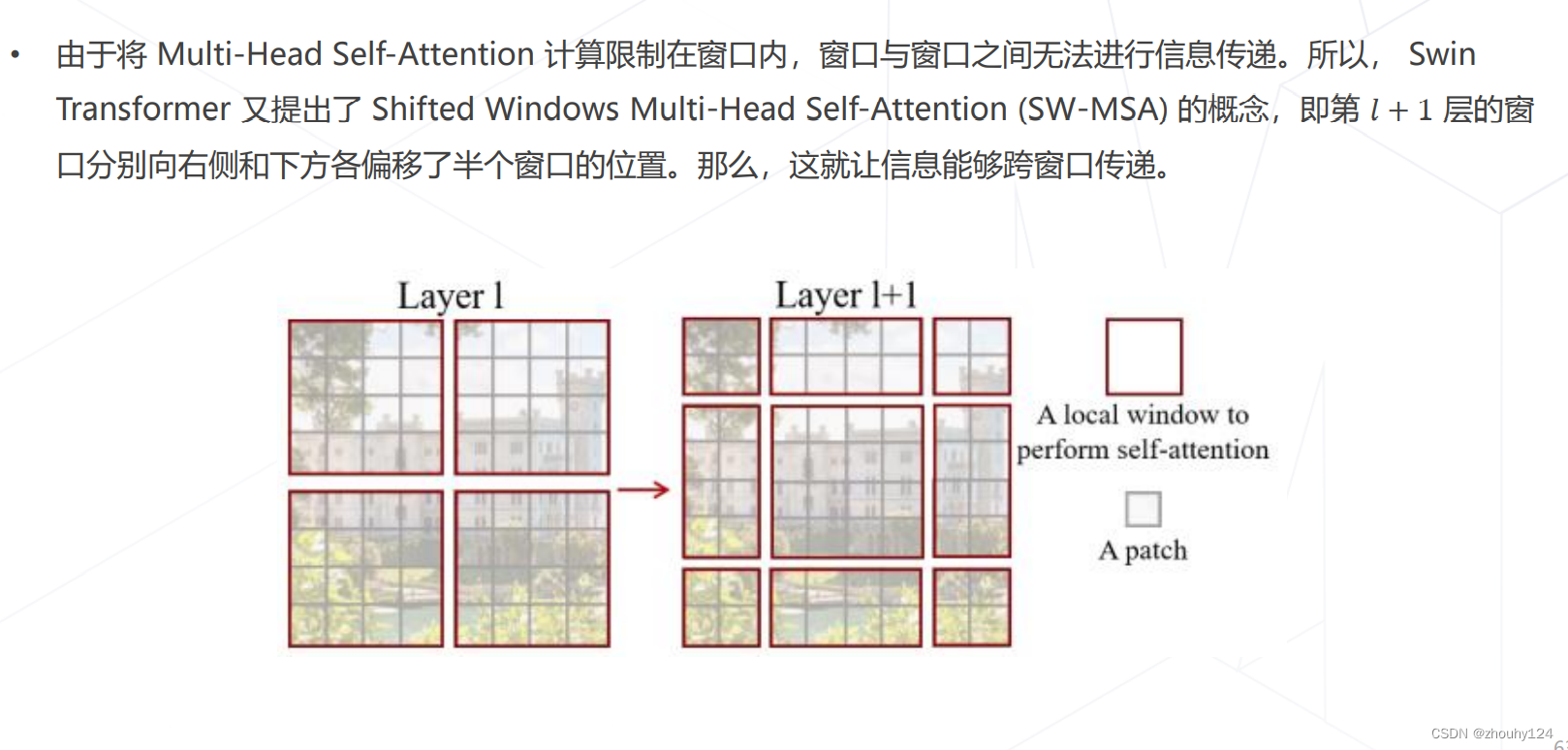
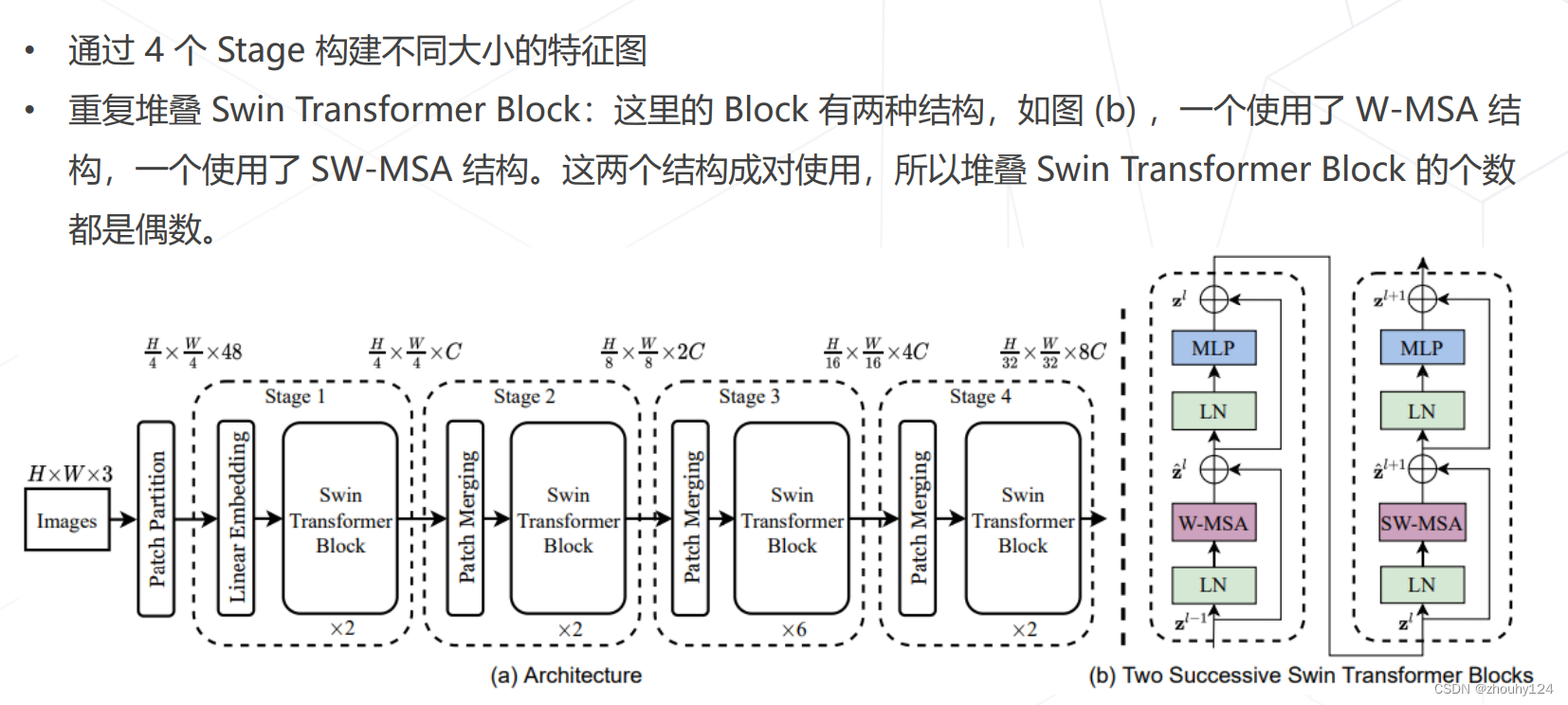
六、模型学习
1、模型学习的范式
1、范式一

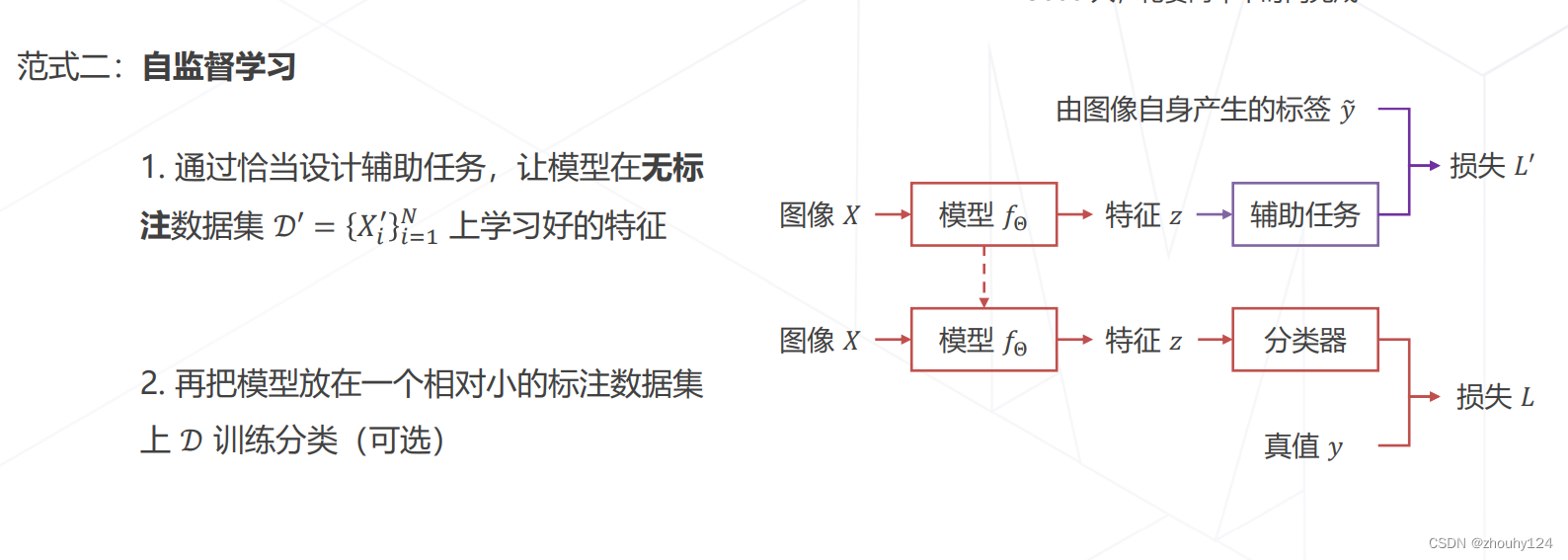
2、范式二
七、监督学习

交叉熵损失 Cross-Entropy Loss

优化目标 & 随机梯度下降
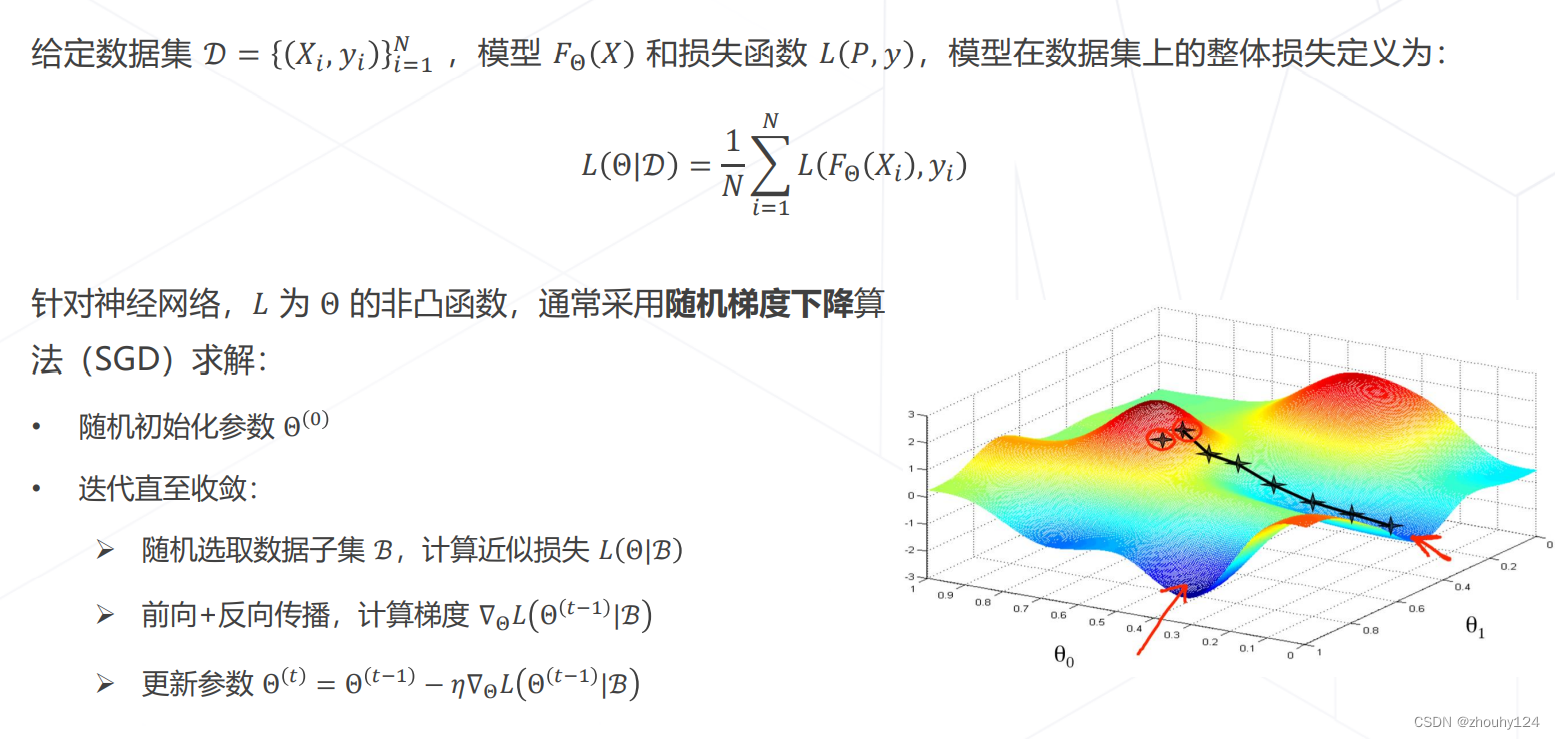
动量 Momentum SGD

基于梯度下降训练神经网络的整体流程

八、学习率与优化器策略
此模块涉及许多公式,不再展示。
权重初始化、学习率对训练的影响、学习率策略:学习率退火 Annealing、学习率策略:学习率升温 Warmup、Linear Scaling Rule、自适应梯度算法、正则化与权重衰减 Weight Decay、早停 Early Stoppin、模型权重平均 EMA、模型权重平均、
九、数据增强
训练泛化性好的模型,需要大量多样化的数据, 而数据的采集标注是有成本的。
图像可以通过简单的变换产生一系列"副本",扩充训练数据。
数据增强操作可以组合,生成变化更复杂的图像。
1、组合数据增强
2、组合图像 Mixup & CutMix
3、标签平滑 Label Smoothing
十、模型相关策略
丢弃层 Dropout、随机深度
十一、自监督学习
基于代理任务、基于对比学习、基于掩码学习
十二、总结

十三、MMClassification 介绍



















 4492
4492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









