







MSH-Net:基于联合自适应蒸馏的模态共享幻觉网络用于缺失模态的遥感图像分类
作者:Shicai Wei,Yang Luo,Xiaoguang Ma,Peng Ren(IEEE高级会员),Chunbo Luo(IEEE会员)
摘要
基于学习的多模态数据因其强大的性能,在遥感领域受到越来越多的关注。尽管在训练时收集多种模态数据更为理想,但由于成像条件的限制,在实际应用场景中并非所有模态都能获取。因此,如何在模态缺失的情况下辅助模型进行推理,对于多模态遥感图像处理至关重要。在这项工作中,我们提出了一种通用框架——模态共享幻觉网络(MSH-Net),通过从不完全的推理模态中重建完整的模态共享特征来解决这一问题。与传统的特权模态幻觉方法相比,MSH-Net不仅有助于在模型推理时保留跨模态交互,还能随着缺失模态数量的增加很好地扩展。我们进一步开发了一种新的联合自适应蒸馏(JAD)方法,通过匹配表征和真实标签之间的联合概率分布,引导幻觉模型从多模态模型中学习模态共享知识。这克服了多模态模型和幻觉模型在输入和结构上的差异所导致的表征异质性,同时保留了由多模态线索优化的决策边界。最后,在四种常见的模态组合上进行的大量实验表明,所提出的MSH-Net能够有效解决模态缺失问题,并实现最先进的性能。代码可在https://github.com/shicaiwei123/MSHNet获取。
关键词
分类;深度学习;知识蒸馏;缺失模态;多模态;遥感
一、引言
遥感图像分类在地球观测中起着至关重要的作用,如城市规划、土地利用分析、环境监测等。近年来,随着深度学习技术的发展,利用多种模态信息的分类模型在实际应用中展现出强大的能力,受到了研究界越来越多的关注。尽管多模态方法比单模态方法表现更优,但在实际部署场景中,由于以下两个原因,它们可能会面临模态缺失的问题:第一,传感器故障可能导致模态信息完全丢失;第二,一些传感器(如卫星)的采样频率较低,增加了及时获取同一地区遥感图像的难度。因此,在部分模态缺失的实际场景中部署多模态遥感模型具有重要意义。
一般来说,仅在训练阶段可用的信息被定义为特权信息。具体而言,仅在训练阶段可用的数据模态称为特权模态,而在训练和推理阶段都可用的模态称为常规模态。迄今为止,人们已经做出了大量努力来处理具有特权模态的多模态分类问题,大多数方法可分为两类:基于辅助的方法和基于生成的方法。基于辅助的方法将特权模态数据视为辅助输入,并通过多任务学习利用它来辅助优化决策边界,即为特权模态数据引入额外的约束项。另一方面,基于生成的方法则提议从常规模态中恢复特权模态的信息,以辅助在模态缺失情况下的推理,因为它们共享相同的语义信息。由于辅助任务不一定满足无伤害保证,并且可能会限制当前主要任务的性能,所以先前的方法主要探索基于生成的方法来辅助处理模态缺失的遥感图像分类问题。
根据重建目标的类型,基于生成的方法可进一步分为两类:基于插补的方法和基于幻觉的方法。基于插补的方法通过插补算法重建特权样本,然后将其与常规样本结合作为多模态模型的输入。然而,样本重建不稳定,由于其复杂性,可能会引入有害噪声。因此,基于幻觉的方法被提出来处理从样本空间到特征空间的重建问题。它们首先训练一个幻觉模型,使用蒸馏算法重建特权表征,然后将幻觉模型和用常规模态数据训练的常规模型融合,以做出最终决策。尽管这些方法取得了不错的性能,但它们仍然存在两个局限性。一方面,它们在决策层面融合特权模态和常规模态的信息,这只包含了模态特定的信息,忽略了中间的模态共享属性,而已有研究表明模态共享属性是多模态遥感分类中的一个关键因素。另一方面,这类方法的幻觉分支数量会随着缺失模态数量的增加而增加,这不够灵活且繁琐,尤其在存在多个缺失模态的场景中。
同时,知识蒸馏作为一种知识转移技术,已被广泛用于训练幻觉模型。先前基于幻觉的方法主要集中在直接匹配中间表征的基于特征的蒸馏(FD)方法。由于幻觉模型和多模态模型的输入不同,让幻觉模型生成与多模态模型相同的特征图并不可行,这可能会导致过拟合,并限制模型在未见样本上的性能。作为一种可能的解决方案,我们可以通过用基于关系的蒸馏方法替代FD方法来训练幻觉模型,从而放宽约束。已有研究证明,这种方法 可以有效解决表征异质性问题。然而,现有的基于关系的方法仅考虑样本之间的关系,这不足以引导幻觉模型继承完整的模态共享信息,可能会导致次优的性能。
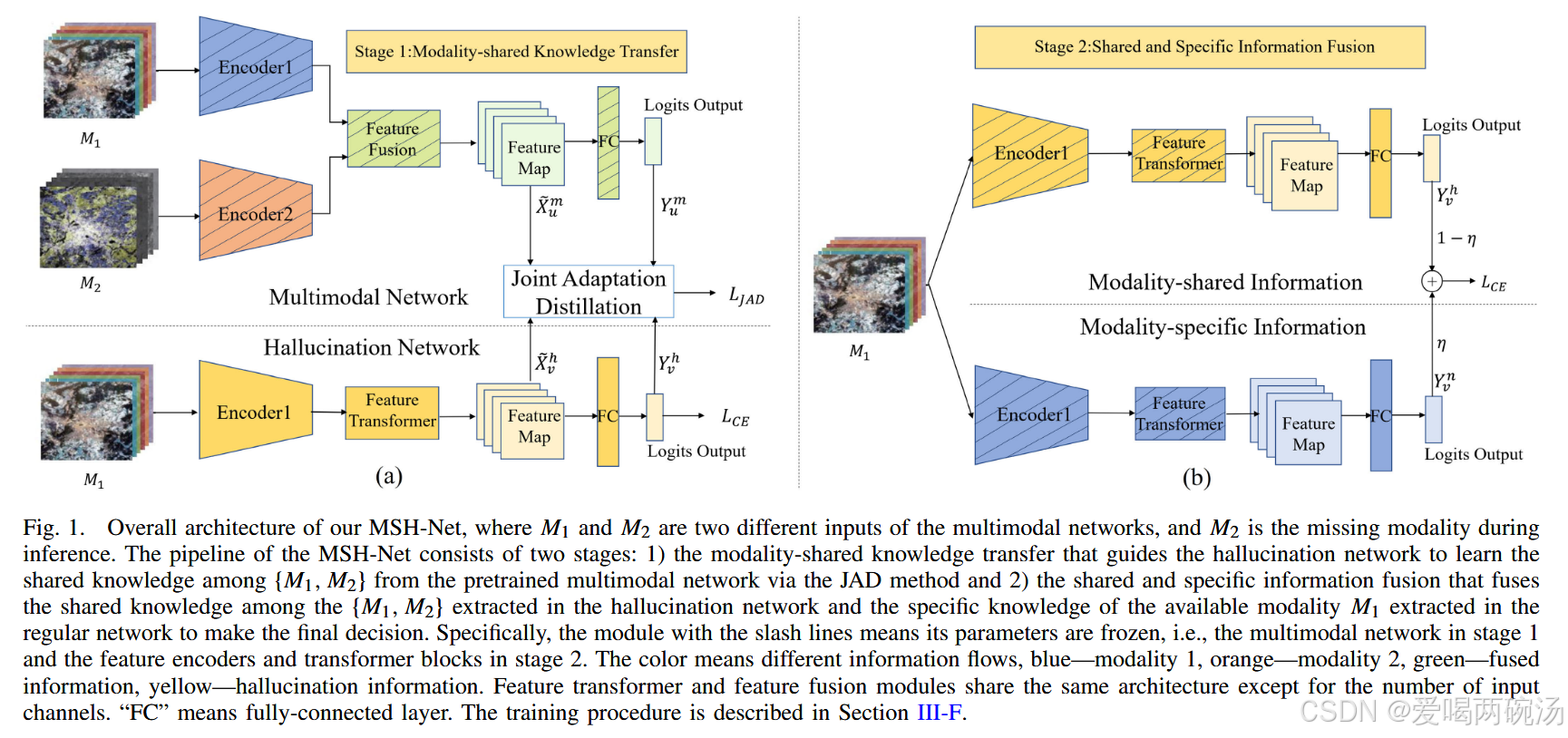
为了解决上述问题,我们提出了一种通用的模态共享幻觉网络(MSH-Net),用于处理存在缺失模态的遥感图像分类问题。如图1所示,MSH-Net首先训练幻觉模型,直接从预训练的多模态模型中学习模态共享知识,然后将其与提取模态特定属性的常规模型融合,以做出最终决策。与传统的仅从使用特权模态训练的模型中学习的幻觉方法相比,MSH-Net有助于从多模态模型中获取跨模态交互。此外,由于MSH-Net旨在恢复完整的多模态知识,而非缺失信息,因此它可以随着缺失模态数量的增加而扩展。其次,我们提出了联合自适应蒸馏(JAD)方法,通过匹配样本表征和最终预测输出的联合概率分布,将预训练多模态模型中的模态共享知识转移到幻觉模型中。这不仅简单地捕捉了多模态模型的表征间关系,还进一步引入了样本表征和最终预测输出之间的条件分布作为额外约束,以转移多模态模型优化后的分类边界,使幻觉模型能够继承全面的多模态知识,从而提高性能。这项工作的主要贡献总结如下:
- 我们提出了一种新颖的MSH-Net,通过恢复用于模型推理的模态共享特征,应对存在缺失模态数据的多模态遥感图像分类挑战。这有助于保留跨模态交互,并提高对多个缺失模态场景的可扩展性。
- 我们提出了JAD方法,通过同时匹配边际分布和条件分布,将多模态知识转移到幻觉模型中。这克服了表征异质性,同时获取了全面的模态共享信息。
- 在四种常见模态组合上进行的实验和消融研究,证明了所提出框架在处理缺失模态推理时的有效性和泛化性。
二、相关工作
(一)基于生成的方法
基于生成的方法可分为两类:基于插补的方法和基于幻觉的方法。基于插补的方法从可用模态图像中重建特权模态的像素信息,以供预训练的多模态分类模型处理缺失模态问题。例如,Zhu等人利用CycleGAN从CT图像生成MRI图像,以辅助纵隔肺癌分割。由于样本重建的复杂性和不稳定性,基于幻觉的方法被提出来重建特权模态的表征信息。Kampffmeyer等人从可用的RGB图像中生成数字表面模型(DSM)图像的表征,以提高光学土地覆盖分类性能。Kumar等人对多光谱(MS)土地覆盖分类中缺失的光谱数据进行表征生成。Li等人引入动态分层注意力蒸馏(DHAD),从RGB图像中生成合成孔径雷达(SAR)图像特征,以辅助土地覆盖分类。Liu等人提出了一种教师辅助网络,将从RGB图像中学到的知识转移,以辅助MS场景分类。Ni等人提出距离和角度蒸馏,将RGB知识转移到可穿戴设备上,用于人类活动识别。Hong等人引入跨模态知识蒸馏,将光探测和测距(LiDAR)信息转移到RGB模型中,用于自动驾驶。总之,这些工作旨在训练一个幻觉模型,通过直接匹配中间特征图来重建特权模型的表征。这可能会导致过拟合,并限制幻觉模型的性能,因为幻觉模型和特权模型的输入不同,无法强制它们生成相同的样本特征图。
(二)知识蒸馏
Hinton等人提出的知识蒸馏旨在将知识从强大的教师网络转移到较弱的学生网络,以促进监督学习。一般来说,它可以分为三类:基于响应的蒸馏、基于表征的蒸馏和基于关系的蒸馏。基于响应的蒸馏通过匹配软化的logits输出来将教师网络最后输出层的神经响应转移到学生网络。虽然基于表征的蒸馏直观易懂,但它无法转移教师网络学到的强大表征。因此,基于表征的蒸馏被提出来对中间特征图的知识进行建模,并通过最小化它们特征图的值、注意力图和注意力投影之间的差异,将知识转移到学生网络。此外,基于关系的蒸馏被提出来对不同层或数据样本之间的关系进行建模,并通过最小化特征对的相似性图、分布和数据间关系之间的差异来转移知识。尽管已经提出了许多基于关系的知识蒸馏方法,但它们仅考虑了表征关系,这可能不足以引导学生模型从教师模型中学习完整的信息。
三、方法
(一)概述
在本节中,我们将介绍MSH-Net,它引导幻觉网络直接从多模态网络中学习模态共享知识。如图1所示,MSH-Net的训练流程包括两个阶段:模态共享知识转移以及共享和特定信息融合。特别地,为了解决由结构和输入差异导致的表征异质性问题,我们提出了JAD方法,通过匹配边际分布和条件分布,将模态共享知识从多模态网络转移到幻觉网络。这有助于放宽优化目标,同时引导幻觉模型学习完整的多模态知识。
总之,我们将首先介绍方法中使用的符号。然后介绍JAD策略、模态共享知识转移以及共享和特定信息融合。最后,讨论网络训练和测试的细节。
(二)符号

设(\Theta)表示由模态(M_1,\cdots,M_U)组成的训练数据集,(\Psi)表示仅包含在实际应用场景中可用的模态(M_1,\cdots,M_V)的数据集。这里,数据集(\Psi)是通过从数据集中为每个样本移除缺失模态(M_{V + 1},\cdots,M_U)生成的。(X = (X_u, X_v))表示带有标签(Y)的配对小批量样本,其中(X_u)和(X_v)分别从样本集(\Theta)和(\Psi)中选取。(\tilde{X}{u}^{m}=\varphi{m}(X_{u}) \in R^{b ×c_{m} ×w_{m} ×t_{m}})和(\tilde{X}{v}^{h}=\varphi{h}(X_{v}) \in R^{b ×c_{h} ×w_{k} ×t_{h}})分别表示多模态网络和幻觉网络倒数第二层的特征图。这里,(b)是批量大小,(c)是特征通道数,(w)和(t)是空间维度。(Y_{u}{m}=f_{m}(\tilde{X}_{u}{m}) \in R^{b ×l})和(Y_{v}{h}=f_{h}(\tilde{X}_{v}{h}) \in R^{b ×l})分别表示多模态网络和幻觉网络的logits输出。这里,(l)表示土地覆盖类别数。最后,(\tilde{X}{v}^{n}=\varphi{n}(X_{v}) \in R^{b ×c_{n} ×w_{n} ×t_{n}})和(Y_{v}{n}=f_{n}(\tilde{X}_{v}{n}) \in R^{b ×l})分别表示用(X_v)预训练的常规模型的倒数第二层特征图和logits输出。
(三)联合自适应蒸馏
与传统的幻觉学习任务不同,模态共享幻觉是将知识从多模态网络转移到幻觉网络,此时教师网络和学生网络的输入和结构均不同。这扩大了表征差异,会阻碍知识转移。为了解决这个问题,我们提出了JAD方法,通过匹配样本表征和真实标签之间的联合概率分布,将模态共享知识从多模态网络转移到幻觉网络。这放宽了匹配特征值的约束,避免过拟合,同时保留了样本表征和真实标签之间的转移概率,以保留全面的多模态知识。
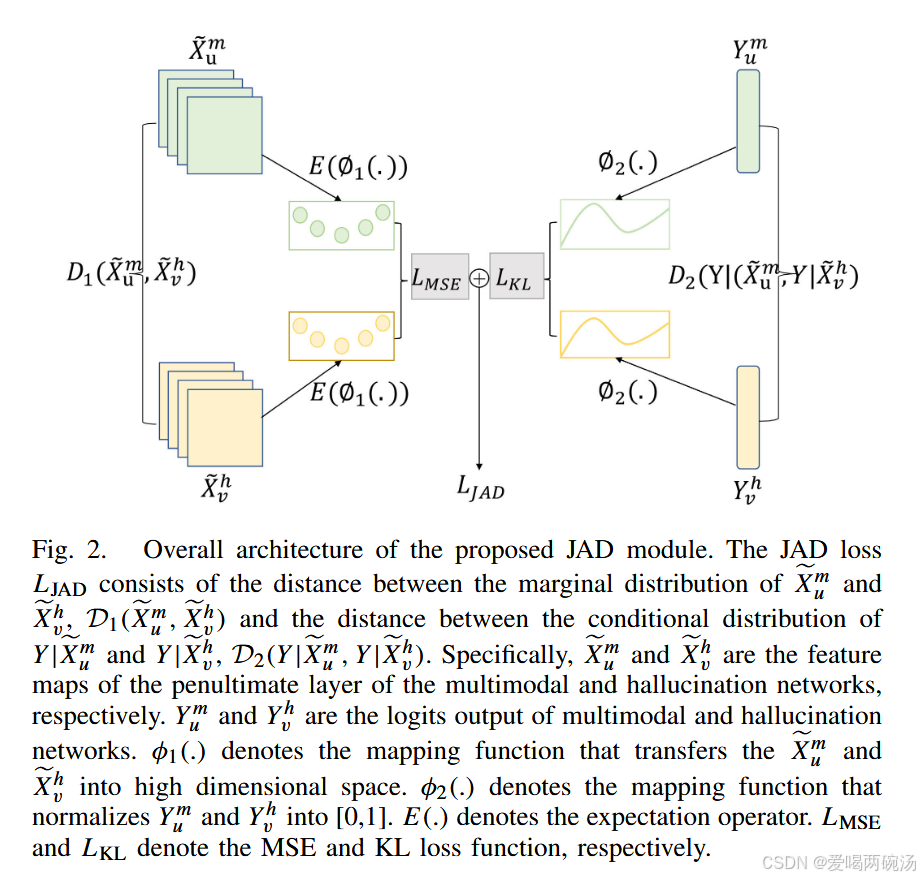
图2.拟议JAD模块的总体架构。JAD损失LJAD由Xeum和Xevh的边缘分布之间的距离D1(Xeum,Xevh)和Y|Xeum和Y|Xevh的条件分布之间的间距D2(Y|Xeom,Y|Xevh。具体来说,Xeum和Xevh分别是多模态和幻觉网络倒数第二层的特征图。Yum和Yvh是多模态和幻觉网络的logits输出。φ1(.)表示将Xeum和Xevh转换到高维空间的映射函数。φ2(.)表示将Yum和Yvh归一化为[0,1]的映射函数。E(.)表示期望算子。LMSE和LKL分别表示MSE和KL损失函数。
图2展示了JAD的整体架构,它嵌入到图1(a)和(b)中多模态网络和幻觉网络的倒数第二层和logits输出层。它通过最小化以下损失将知识从多模态网络转移到幻觉网络:
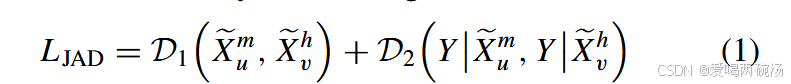
其中 D1(Xem u , Xevh) 是 Xem u 和 Xevh 的边际分布之间的距离,D2(Y |Xem u , Y |Xevh)是Y|Xem-u和Y|Xevh的条件分布之间的距离。因此,要计算 D1(Xem u , Xevh) 和 D2(Y |Xem u , Y |Xevh),我们需要分别估计 Xem u 、 Xevh、 Y |Xem u 和 Y |Xevh 的 分布。尽管已经提出了许多方法来解决这个问题,但准确的分布估计仍然困难和复杂 [42],这可能会限制对主要任务的学习。为了解决这个问题,我们进行了两项创新。
-
受最大平均差异 [44] 的启发,我们建议用 Xem u 和 Xevh 矩之间的最大距离来近似 D1(Xem u , Xevh)。这避免了估计其分布的问题,并且 D1(Xem u , Xevh) 可以改写如下:
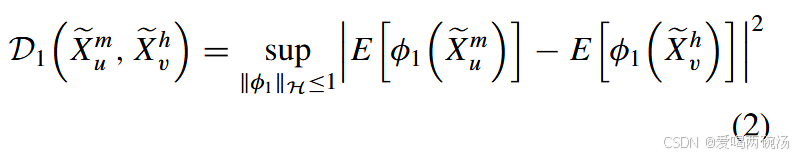
其中 φ1(.) 表示将 Xe m u , Xevh 转换为任意顺序的空间的映射函数,其在希尔伯特空间 H 中的范数小于 1。E[.] 是期望运算。由于样本的均值是期望的无偏估计值,∥φ1∥H ≤ 1,我们可以将 D1 ( Xe m u , Xevh) 改写如下:
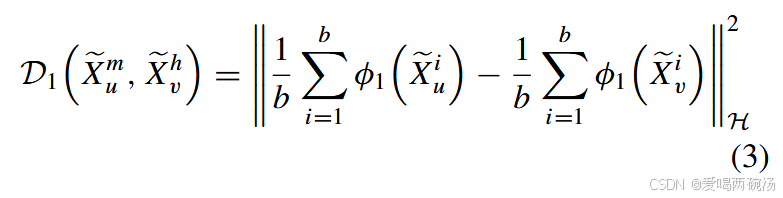
其中 Xei u = (Xem u )i 和 Xevj = (Xevh) j 分别是 Xu 和 Xv 中第 i 个和第 j 个样本的特征图。此外,这可以通过内核方法进行分解 [45]
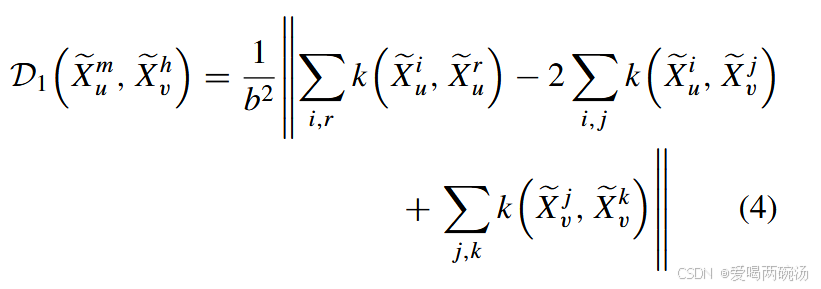
其中 k(x1, x2) 是内核函数。与之前的研究 [44] 类似,我们将其设置为高斯函数
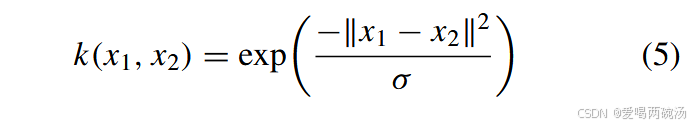
其中 exp(.) 表示指数运算,σ 表示方差。这样,我们可以计算特定 Xem u 和 Xevh 的边际分布距离 D1(Xem u , Xevh)。 -
我们建议估计 D2(Y |Xem u , Y |Xevh) 的 Git。具体来说,计算 D2(Y |Xem u , Y |Xevh) 定义如下:
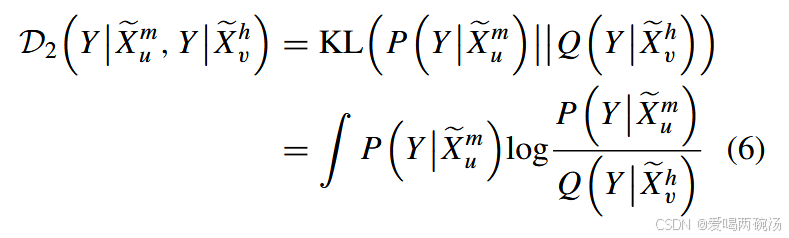
其中 KL(., .) 表示 KL 散度。P(Y |Xem u) 和 Q(Y |Xevh) 表示 Y |Xem U 和 Y |Xevh 的 10 个版本。根据蒙特卡洛算法,我们可以将积分计算转换为采样统计问题 [42],并将 D2(Y |Xem u , Y |xevh) 可以是重写如下:
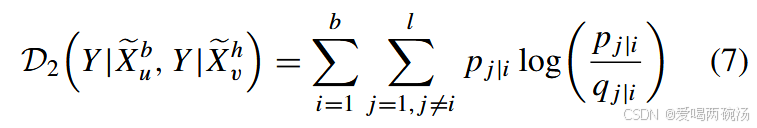
其中 p j|i 和 q j|i 是从 P(Y |Xeb u) 和 Q(Y |Xevh) 的 S它们分别表示从第 i 个表示 (Xem u )i 和 (Xevh)i 到第 j 个类别的条件概率。
由于神经网络的定义,最终的 logits 输出代表了样本属于每个类别的可能性 [46],我们可以通过 Y、m、u 和 Yvh 来计算 p j|i 和 q j|i。此外,为了满足概率的基本性质,我们建议使用 softmax 函数将 Y、m u 和 Yvh 归一化为 [0, 1]。因此 p j|i 和 q j|i 可以改写如下:
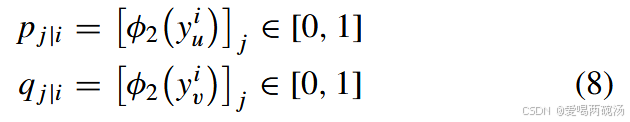
其中 yi u = (Y m u )i 和 yiv = (Yvh)i 分别表示 Xu 和 Xv 的第 i 个样本的 logits 输出。φ2(.) 表示 SOTFMAX 函数。[.]j 表示第 j 个分量。
(四)模态共享知识转移
现有方法通常通过恢复特权模态信息来处理缺失模态的土地覆盖分类问题。一方面,这只考虑了模态特定属性,忽略了对多模态分类至关重要的中间跨模态交互。另一方面,这种方法随着缺失模态数量的增加扩展性不佳,因为它需要为每个缺失模态训练特权分支。为了解决这些问题,我们提出了模态共享幻觉方法,引导幻觉模型直接从使用完整数据训练的多模态模型中学习模态共享知识。
如图1所示,我们以常见的设置(u = 2)和(V = 1)为例,解释模态共享知识转移的机制。这里我们假设(M_{2})为特权模态。总体而言,我们提议引导幻觉网络从预训练的多模态网络中学习模态(M_{1})、(M_{2})之间的共享知识。具体来说,多模态模型的训练已得到广泛研究,并且已经提出了许多有效的融合算法,如交叉融合、通道选择和跨通道重建。由于多模态模型训练与知识转移无关,因此可以使用各种结构和融合策略来实现。此外,由于知识转移的有效性高度依赖于结构相似性,幻觉网络的架构通过去除多模态网络中仅由缺失模态使用的模块来确定,从而最小化它们之间的结构差异。此外,为了应对剩余的结构和输入差异,引入图2中的JAD方法,通过匹配样本表示和真实标签之间的联合分布,将模态共享知识从多模态网络转移到幻觉网络。最后,第一阶段的总损失定义如下:
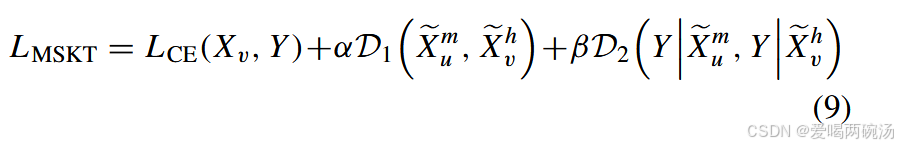
其中 LCE(Xv, Y ) 是手头任务的标签监督损失。α 和 β 是 balance 超参数。
(五)共享和特定信息融合
尽管模态共享知识转移通过引导幻觉网络从不完整模态(M_{1})中恢复模态(M_{1})、(M_{2})之间的共享知识,缓解了缺失(M_{2})的信息损失问题,但它只考虑了共享知识,忽略了模态(M_{1})的特定信息。值得注意的是,模态特定信息在多模态遥感土地覆盖分类中也非常重要。为了解决这个问题,我们引入共享和特定信息融合,考虑使用模态(M_{1})训练的常规模型。
如图1所示,我们提出了一种两流网络,对幻觉模型和常规模型产生的预测结果进行加权,以做出最终决策,使推理模型能够利用模态共享和特定信息。未标记数据(x_{v})的最终分类结果定义如下:
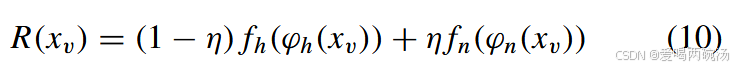
其中 η 是可学习的加权超参数。fh(.) 和 fn(.) 分别是幻觉和规则分支的样本表示和 logits 输出之间的非线性映射函数。此外,为了实现更好的性能,我们冻结了两个分支的特征编码器的参数,并通过以下训练损失在数据集 8 上微调它们的全连接层:
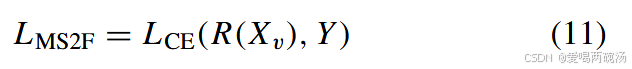
其中 LCE(., .) 是交叉熵损失。
(六)训练
所提出的MSH-Net的训练包括三个步骤:基线训练、幻觉训练和集成训练。
- 基线训练:基线训练旨在使用完整数据模态训练多模态网络,使用不完整数据模态(\Psi)训练常规模型,分别用于模态共享知识转移和共享与特定信息融合。具体来说,多模态网络的架构设置为MDLCNNs-Net,已被证明在多模态土地覆盖分类中是有效的。值得注意的是,所提出的MSH-Net与模型无关,多模态网络也可以使用其他架构实现,如CCR-Net和CHGFNet。如图1所示,常规模型的架构与幻觉网络的架构相同,将在幻觉训练中详细描述。最后,多模态网络和常规模型的训练损失均为交叉熵损失。
- 幻觉训练:如图1所示,幻觉训练旨在训练模态共享知识转移阶段的幻觉网络。幻觉网络的架构由第三节D部分介绍的过程确定,从而最小化多模态网络和幻觉网络之间的结构差异。具体来说,如图1所示,由于(M_{2})是特权模态,去除多模态网络中仅由(M_{2})使用的特征提取器,将剩余的由(M_{1})使用的特征提取器设置为幻觉网络的特征提取器。然后,由(M_{1})使用的特征融合和全连接模块也保留给幻觉网络。这里,由于幻觉网络的输入仅为(M_{1}),我们将特征融合模块称为特征变换器。训练损失是公式(9)中提出的(L_{MSKT})。最后,值得注意的是,预训练多模态网络的参数被冻结,只有幻觉网络是可学习的。
- 集成训练:如图1所示,此步骤训练集成网络,对幻觉网络和常规模型的logits输出进行加权,以做出最终决策。训练损失是公式(11)中提出的(L_{MS2F})。具体来说,它们的特征编码器和特征变换器模块的参数被冻结,只有全连接模块和加权因子(\eta)是可学习的。
四、实验
(一)数据集
在实验中,使用两个多模态数据集Huston2013和Augsburg进行定量和定性的性能评估。对这两个数据集的简要描述如下:
- Huston2013:该数据集由三个不同的数据源组成,包括高光谱(HS)图像、多光谱(MS)图像和LiDAR图像。其中,HS和LiDAR图像可从2013年IEEE GRSS数据融合竞赛中获得。MS图像是通过在空间和光谱域对原始HS图像进行降质生成的。具体来说,HS图像由144个HS波段组成,大小为349×1905,空间分辨率为2.5米。生成的MS图像与原始HS图像大小相同,有8个光谱波段,地面采样距离(GSD)为2.5米。LiDAR图像是与HS图像空间大小相同的灰度图像。最后,共有15个类别的15029个地面真实样本,详细信息见表I。
- Augsburg:该数据集由三个不同的数据源组成,包括HS图像、双极化SAR图像和DSM图像。具体来说,HS图像由180个波段组成。SAR图像由四个特征通道组成。DSM图像是灰度图像。每个波段的尺寸为332×485像素。最后,如表II所示,图像中共有七个类别,其地面真实值可用于78294个像素,这些像素被分为761个训练像素和77533个测试像素。
(二)实验设置
- 评估指标:在实验中,我们选择多模态土地覆盖分类任务来评估所提出的框架。这被认为是评估多模态学习质量的一个潜在应用。具体来说,我们报告了常见土地覆盖分类评估中的三个指标,包括总体准确率(OA)、平均准确率(AA)和Kappa系数(Ka),用于定量性能比较。
- 实现细节:所提出的方法在PyTorch平台上实现。整个框架使用SGD优化器进行训练,训练轮数为500,批量大小为32,学习率为1e - 3,动量为0.9。此外,对于所有模型,我们应用经典的余弦学习率策略来更新每次迭代的学习率,以便它们能够实现更好的性能。最后,为了考虑初始化中的随机性,将报告三次运行的平均结果。
除了训练设置外,数据准备对性能也非常重要。与传统的将整个图像作为网络输入的分类任务不同,遥感图像分类需要以像素为中心裁剪图像块作为输入。为了进行公平比较,我们按照先前的工作,通过“复制”操作扩展原始像素,并将图像块大小设置为7×7。此外,我们使用随机翻转进行数据增强。
3. 模态组合:为了评估所提出的MSH-Net的泛化性,我们在四种常见的多模态组合上进行实验。除了HS和MS图像的组合(HS - MS)外,我们还考虑了高度异质的组合,包括HS和LiDAR图像(HS - LiDAR)以及HS和SAR图像(HS - SAR)。此外,为了评估所提出的MSH-Net在多个模态(超过一个)缺失场景中的可扩展性,我们还在HS、SAR和DSM图像的组合(HS - SAR - DSM)上进行实验。
4. 比较方法:为了评估特权模态学习和所提出的MSH-Net在处理缺失模态的土地覆盖分类方面的有效性,我们将MSH-Net与两类方法进行比较。
- 第一类报告了使用相同模态数据进行训练和测试的多模态模型和常规模型的性能。具体来说,多模态模型使用每个模态组合的完整数据模态进行训练,而常规模型仅使用推理过程中不缺失的部分模态进行训练。为了简化描述,每个模态组合的这些模型的名称采用它们所使用的模态的名称。以HS和MS图像的组合为例,HS-Net表示使用HS图像训练的模型;MS-Net表示使用MS图像训练的模型;HS-MSNet表示同时使用HS和MS图像训练的模型。
- 第二类报告了通过不同蒸馏方法转移特权知识的最先进的特权模态学习方法的性能,包括通过FD的Hall-Net、通过基于logit的蒸馏(LD)的MARS-Net、通过对抗判别蒸馏(ADD)的ADD-Net以及通过DHAD的DH-ADNet。
(三)超参数配置
如前所述,所提出的蒸馏策略有两个超参数(\alpha)和(\beta),它们会影响所提方法的土地覆盖分类性能。为了探索这两个参数的影响,我们对HS-MS、HS-LiDAR和HS-SAR的模态组合进行实验,将(\alpha)从1.0变化到5.0,步长为1.0,(\beta)的值也从1.0变化到5.0,步长为1.0,同时保持其他参数不变。结果如图3所示,我们可以从中得到不同模态组合的最优参数组合。
首先,对于HS-MS组合,如图3(a)和(b)所示,当HS模态缺失时,将((\alpha, \beta))设置为(1, 2)更好,当MS模态缺失时,设置为(1, 1)更好。此外,对于HS-LiDAR组合,如图3(c)和(d)所示,当HS模态缺失时,((\alpha, \beta))选择(1, 5)更好,当LiDAR模态缺失时,(2, 1)更好。此外,对于HS-SAR组合,如图3(e)和(f)所示,当HS模态缺失时,我们可以将((\alpha, \beta))设置为(1, 5),当SAR模态缺失时,设置为(2, 1),这样模型可以分别达到最高准确率。
特别地,我们可以看到,当仅LiDAR或SAR模态可用于推理(HS模态缺失)时,HS-LiDAR和HS-SAR模态组合的最优超参数((\alpha, \beta))相同,均为(1, 5);当仅HS模态可用于推理(LiDAR或SAR模态缺失)时,均为(2, 1)。原因可能是它们都是高度异质的组合。因此,对于HS-SAR-DSM模态组合,当仅SAR或DSM模态可用于推理时,我们也将((\alpha, \beta))设置为(1, 5),当仅HS模态可用于推理时,设置为(2, 1)。
(四)HS-MS组合的结果与分析
表III列出了在HS-MS-LiDAR数据集上三种不同实验设置下,即基线、无HS模态和无MS模态,在OA、AA和Ka方面的定量性能比较。
首先,从完整模态的设置中可以观察到,使用HS和MS模态数据训练的HS-MS-Net优于仅使用HS模态数据训练的HS-Net和仅使用MS模态数据训练的MS-Net。这表明了多模态学习在土地覆盖分类中的有效性。然而,当HS模态和MS模态缺失时,HS-MS-Net的OA分别下降了27.49%和14.38%。这表明将传统的多模态模型应用于测试模态不完整的实际应用中是无效的。相比之下,所提出的MSH方法克服了这个问题,与单模态模型相比,保留了性能提升。具体来说,MSH方法的OA、AA和Ka分别比MS-net高1.01%、0.82%和1.12%,比HS-net高2.67%、1.97%和2.78%。
更重要的是,由MSH方法训练的模型能够有效地将模态共享信息从多模态模型转移到幻觉模型,比仅保留模态特定知识的基于蒸馏的方法具有更高的性能。具体来说,当HS模态缺失时,幻觉流通过图1(a)中的过程,将HS和MS模态之间的共享知识从多模态模型蒸馏到使用MS模态训练的幻觉模型中。在OA方面,这比传统的基于蒸馏的方法,包括DH-ADNet、ADD-Net、MARS-Net和Hall-Net,分别高出0.27%、0.41%、0.7%和1.28%。当MS模态缺失时,MSH方法在OA上比它们分别高出0.73%、1.04%、1.35%和1.41%。
(五)HS-LiDAR组合的结果与分析
本节进一步评估所提出的MSH方法在HS或LiDAR模态缺失场景下的性能,以研究其对高度异质模态组合的泛化能力。表IV分别报告了在HS-MS-LiDAR数据集上三种不同实验设置下,即基线、无HS模态和无LiDAR模态,在OA、AA和Ka方面的定量性能比较。
从表IV中可以看出,当HS模态缺失且仅有LiDAR模态可用于推理时,HS-LiDAR-Net的OA下降了79.53%,比LiDAR-Net低45.08%。另一方面,当LiDAR模态缺失且仅有HS模态可用于推理时,HS-LiDAR-Net的OA下降了44.88%,比HS-Net低37.48%。与HS和MS模态的组合相比,这里由于模态缺失导致的性能下降更为显著。因此,解决在实际场景中部署使用高度异质模态数据训练的模型时部分模态缺失的问题非常重要。
此外,值得注意的是,MSH-Net在所有三个指标上的表现也优于单模态训练的模型。具体来说,当仅有LiDAR模态可用于推理时,它分别将LiDAR-Net的OA、AA和Ka提高了5.1%、5.19%和5.46%;当仅有HS模态可用于推理时,分别将HS-Net的OA、AA和Ka提高了3.42%、2.73%和3.60%。上述改进证明了MSH-Net在处理高度异质模态组合中缺失模态的遥感分类问题上的泛化能力。此外,当HS模态缺失时,MSH-Net在OA上比DH-ADNet、ADD-Net、MARS-Net和Hall-Net分别高出1.74%、2.51%、2.92%和2.95%;当LiDAR模态缺失时,分别高出1.43%、1.76%、2.34%和2.43%。这表明在多模态高度异质的场景中,通过将模态共享知识转移到幻觉模型来处理缺失模态仍然是有效且优越的。
最后,图4展示了在给定场景下所考虑的比较算法的分类图。在定量和定性比较(图4和表IV之间)中存在相同的趋势,并且所提出的MSH-Net得出的分类图优于其他比较方法。以商业区为例,在黑色框中可以看出,由我们的MSH-Net得出的商业区分类图更完整,误分类更少。然而,HS-LiDARNet甚至无法提取出商业区。由HS-Net、Hall-Net、MARS-Net和ADD-Net得出的商业区分类图是不连续的,而由DH-ADNet得出的商业区分类图存在一些误分类。
(六)HS-SAR组合的结果与分析
我们还在Augsburg数据集的HS和SAR模态组合上进行了对比实验,以进一步评估MSH-Net的泛化能力。具体来说,由于成像机制不同,HS和SAR数据也具有高度异质性。表IV分别报告了在三种不同实验设置下,即基线、无HS模态和无SAR模态,在OA、AA和Ka方面的定量性能比较。
如表V所示,所提出的MSH-Net在部分模态缺失的情况下比传统多模态模型表现更好,并且优于其他竞争对手。具体来说,对于HS模态缺失的情况,MSH-Net的OA比DH-ADNet、ADD-Net、MARS-Net、Hall-Net和HS-SAR-Net分别高出0.36%、0.48%、0.59%、0.62%和71.27%。对于SAR模态缺失的情况,MSH-Net的OA比DH-ADNet、ADD-Net、MARS-Net、Hall-Net和HS-SAR-Net分别高出1.39%、1.71%、2.25%、2.45%和48.46%。这些结果再次证明了通过引导幻觉模型从多模态模型而不是特权模型中学习,来克服高度异质模态组合中模态缺失问题的有效性。
此外,当仅有HS模态可用于推理时,MSH-Net还将HS-Net的OA、AA和Ka分别提高了2.36%、1.76%和3.37%。这证明了引入额外的模态共享知识的有效性。更显著的是,在AA、OA和Ka方面,它甚至比使用完整模态训练和测试的HS-SAR-Net分别高出1.17%、3.34%和1.67%。这可能是因为我们同时利用了模态共享和模态特定特征,而HS-SAR-Net仅考虑了HS和SAR图像之间的模态共享特征。这显示了我们的方法在多模态遥感分类中处理模态缺失挑战的潜力,同时超越了使用完整模态训练的多模态模型。最后,尽管在仅有SAR模态可用于推理时,MSH-Net在OA和Ka方面的表现优于SAR-Net,但其AA比SAR-Net和其他竞争对手差。特别地,我们可以看到在基线设置中也存在这种现象,即HS-SAR-Net的OA比HS-Net高1.27,而AA比HS-Net低1.58%。这背后的原因可能是不平衡的样本分布导致模型在提高OA的同时忽略了每个类别的准确性。
最后,图5展示了分类图。显然,我们方法的分类图优于其他对比方法。例如,对于黑色框中的住宅区和水域,可以看出由我们的MSH-Net得出的住宅区和水域分类图更完整,误分类更少。相比之下,其他方法得出的分类图被工业区混淆了。
(七)HS-SAR-DSM组合的结果与分析
本节在HS、SAR和DSM图像的模态组合上进行实验,以评估MSH-Net在多个模态缺失场景中的可扩展性。具体来说,有四种设置,即基线、无HS和SAR模态、无SAR和DSM模态以及无HS和DSM模态。表VI报告了每种设置下在OA、AA和Ka方面的定量性能比较。
如表VI所示,我们可以看到,在模态缺失的设置下,所提出的MSH-Net比传统多模态模型表现更好,在基线设置下比单模态模型表现更好。具体来说,与HS-SAR-DSM-Net相比,当HS和SAR模态缺失时,MSH-Net将OA从1.98%提高到81.86%;当HS和DSM模态缺失时,从3.3%提高到83.35%;当SAR和DSM模态缺失时,从72.03%提高到92.99%。这些结果证明了MSH-Net克服多个模态缺失问题的有效性。此外,MSH-Net在OA方面比基线方法HS-Net高1.98%,比SAR-Net高0.85%,比DSM-Net高3.45%。这些结果证明了我们提出的模态共享特征转移在多个模态缺失时仍然有效。
(八)消融研究
在本节中,我们将研究所提方法中重要设计元素的有效性,包括JAD和模态共享知识转移。为此,我们在HS-LiDAR模态组合上对MSH-Net进行了广泛的消融实验。
- JAD策略的效果:为了研究JAD策略的效果,我们报告并比较了使用不同特权蒸馏策略实现的MSH-Net的性能。具体来说,对比的蒸馏方法包括匹配特征图值的FD和DHAD、匹配logit输出分布的LD以及匹配特征图分布的ADD。如表VII所示,使用JAD实现的MSH-Net在无HS模态和无LiDAR模态的设置下均取得了最佳性能。这证明了通过匹配多模态模型和幻觉模型的样本表示与真实标签之间的联合分布概率来转移模态共享知识的优越性。具体来说,在无HS模态的设置下,使用ADD方法实现的MSH-Net比使用DHAD和FD方法的分别高出0.37%和2.97%,这表明了匹配关系而非值来克服多模态网络和幻觉网络之间表征差异的有效性。此外,使用JAD方法实现的MSH-Net比使用ADD方法的高出0.98%,验证了为基于关系的蒸馏方法进一步引入样本表示和真实标签之间的条件约束的有效性。
- 模态共享知识转移的效果:在这里,我们报告并比较了MSH-Net和使用JAD方法实现的传统模态幻觉网络(MH-Net)的性能,以研究转移模态共享知识和特权模态知识的效果。如表VIII所示,在无HS模态和无LiDAR模态的设置下,MSH-Net在OA方面分别比MH框架高出1.68%和1.01%。这证明了从多模态模型向幻觉模型转移模态共享知识和特权模态知识的优越性。
- 骨干网络的效果:所提出的MSH-Net与模型无关,多模态网络除了MDL-CNNs-Net之外,还可以用其他架构实现。根据审稿人的建议,我们使用两种不同的骨干网络CCR-Net和PC2ANet来实现MSH-Net。为了与基线方法进行公平比较,我们在Huston2013数据集中的HS-LiDAR组合上进行实验,CCR-Net和PC2ANet也考虑了该组合。
如表IX所示,对于“有HS”的设置,无论使用CCR-Net还是PC2ANet作为骨干网络,MSH-Net都取得了最佳性能。特别是,MSH-Net使用相同的骨干网络,分别将HS-Net的性能在OA上提高了3.12%和2.72%。此外,对于“有LiDAR”的设置,无论使用CCR-Net还是PC2ANet作为骨干网络,MSH-Net也都取得了最佳性能。它使用相同的骨干网络,分别将LiDAR-Net的性能在OA上提高了4.58%和4.77%。这些结果证明了所提出的MSH-Net对不同骨干网络的鲁棒性。
五、讨论
(一)训练效率比较
网络参数和训练成本主要来自三个部分:特权模型训练、幻觉模型训练和集成微调。其中,微调的参数和成本对于所有模型都是相同的。因此,我们主要比较特权模型和幻觉模型训练的成本。我们通过PyTorch-OpCounter计算模型参数和训练FLOPs,这是一种常用的分析模型参数和操作的工具。
如表X所示,MSH-Net具有最少的参数(0.384M)和训练成本(16.08M FLOPs)。具体来说,在特权模型训练期间,传统方法是两阶段的。相比之下,MSH-Net直接将预训练的多模态模型作为特权模型,节省了近一半的参数和FLOPs。此外,在幻觉模型训练期间,ADD-Net、TAKD-Net和DH-ADNet由于蒸馏方法引入了额外的参数和成本。相比之下,MSH-Net、Hall-Net、MARS-Net和DASK-Net仅具有幻觉模型的参数和FLOPs。这也降低了计算开销。最后,值得注意的是,所有模型微调的参数和FLOPs分别为0.96e-3和3.84e-3,这可以忽略不计。
(二)对未探索模态的泛化能力
本文考虑了多模态遥感学习中使用的重要模态,包括HS、MS、SAR、LiDAR和DSM图像。它们可以分为与表面特征相关的四个信息源:光谱(HS、MS)、几何(MS)、介电特性(SAR)和高度(LiDAR和DSM)。所提出的解决方案可以推广到处理其他相关模态,如RGB、红外和PAN图像。一方面,它们也可以归入这四个信息流中。具体来说,RGB和红外模态是MS模态的子集,包含光谱和几何信息。PAN模态包含表面物体的几何信息。另一方面,我们的实验包括了来自四个信息源的同构组合(如HS-MS)和异质组合(如HS-LiDAR),并验证了所提出的MSH-Net对它们的有效性。因此,我们可以期望所提出的方法对这些未探索的模态具有泛化性。
(三)高度异质模态间可转移共享知识的存在
从理论上讲,一致性和互补性是多模态学习的两个基本特征。多个模态之间的语义一致性决定了无论它们有多大差异,都必然包含共享信息。关键问题是如何提取共享信息,特别是当模态高度异质时。这是多模态融合关注的一个基本问题。
尽管已经提出了许多多模态融合范式,但共享信息的度量往往是经验性的。具体来说,不同模态之间共享的知识应该对模态的缺失具有鲁棒性。因此,我们通过随机丢弃模态输入来评估多模态模型的性能,能够更有效地提取共享信息的模型应该比不能的模型表现更好。详细来说,我们通过随机将多模态输入之一设置为零来模拟模态缺失场景。然后,使用MDL-CNNs-Net的特征提取网络,我们考虑两种融合策略:交叉融合和决策融合,其中交叉融合是MDL-CNNs-Net中使用的原始融合策略。决策融合是一种基线方法,它仅通过平均预测输出来考虑模态特定信息。这有助于评估提取共享知识的有效性。为了评估它们在高度异质模态数据上的性能,我们在Huston2013的HS-LiDAR组合上进行实验。
如表XI所示,在“无LiDAR”和“无HS”设置的跨模态测试中,交叉融合的表现优于决策融合。这表明在高度异质的数据中,交叉融合模型比决策融合模型提取了更多的共享知识。
六、结论
在本文中,我们提出了一种通用框架MSH-Net,用于辅助处理存在缺失模态的多模态遥感图像分类问题。具体来说,MSH-Net引导幻觉模型直接从多模态模型中学习模态共享知识。这有助于保留多模态数据之间的跨模态交互,并提高在多个模态缺失场景中的可扩展性。除了传统的FD方法,我们还开发了一个JAD模块,通过匹配样本表示和真实标签之间的联合概率分布,将模态共享知识从多模态模型转移到幻觉模型中。这能够克服由于幻觉模型和多模态模型的输入和结构差异导致的表征异质性,同时保留由多模态线索优化的决策边界。最后,在四种常见模态组合上的大量实验结果验证了我们方法的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









