







分层稀疏子空间聚类(HESSC):一种用于高光谱图像分析的自动方法
作者:Kasra Rafiezadeh Shahi1,∗, Mahdi Khodadadzadeh1, Laura Tusa1, Pedram Ghamisi1, Raimon Tolosana-Delgado2, Richard Gloaguen1
- 德国弗莱贝格09599,赫尔姆霍兹 - 德累斯顿 - 罗森多夫中心(HZDR),赫尔姆霍兹弗莱贝格资源技术研究所(HIF),“勘探技术” 部门,Chemnitzer Str. 40;
- m.khodadadzadeh@hzdr.de (M.K.); l.tusa@hzdr.de (L.T.); p.ghamisi@hzdr.de (P.G.); r.gloaguen@hzdr.de (R.G.)
- 德国弗莱贝格09599,HZDR - HIF,“建模与评估” 部门,Chemnitzer Str. 40;
- r.tolosana@hzdr.de
通讯作者:K.rafiezadeh - shahi@hzdr.de
- r.tolosana@hzdr.de
摘要:高光谱成像技术正成为远程获取不同物体精细光谱信息的最重要工具之一。然而,高光谱图像(HSIs)在大多数应用中需要专门的处理。因此,在过去几十年里,人们提出了多种机器学习技术。在这些机器学习技术中,无监督学习技术因其无需任何先验知识而受到欢迎。具体而言,基于稀疏子空间的聚类算法在将高光谱图像聚类为有意义的组方面引起了特别关注,因为此类算法能够处理高维和高度混合的数据,这在实际应用中很常见。尽管如此,基于稀疏子空间的聚类算法通常需要较高的计算能力,且耗时较长。此外,聚类的数量通常是预先设定的。在本文中,我们提出了一种新的基于分层稀疏子空间的聚类算法(HESSC),它能够以稳健且快速的方式处理上述问题,并自动估计聚类的数量。在实验中,HESSC被应用于三个真实的岩芯样本和一个著名的农村基准(即特伦托)高光谱图像数据集。为了评估HESSC的性能,我们将新提出的算法与最先进的基于稀疏子空间的算法进行了定量和定性的比较。此外,为了与传统聚类算法进行比较,我们还将HESSC的性能与K - 均值算法和模糊C均值(FCM)算法进行了对比。所得的聚类结果表明,与其他应用的聚类算法相比,HESSC在对高光谱图像进行聚类时表现出色。
关键词:高光谱图像;基于子空间的聚类;分层结构;无监督学习;稀疏表示;集成学习
1. 引言
高光谱成像技术能够在每个像素上获取数百个窄光谱带,根据传感器特性,其覆盖的光谱范围从可见光到近红外(VNIR,0.4 - 1μm)、短波红外(SWIR,1 - 2.5μm)以及长波红外光谱(LWIR,8 - 13μm)。利用如此精细的光谱信息,可以对不同的材料和物体进行准确区分,这使得高光谱图像(HSIs)成为土地覆盖分类和矿物填图等广泛应用的重要信息来源。
然而,由于多种原因,高光谱图像的分析是一项具有挑战性的任务。例如:(1)所捕获的光谱信息与相应材料之间存在固有的非线性关系;(2)高维性(也称为波段)的存在以及相应代表性样本数量有限,这导致了所谓的维数诅咒;(3)相邻波段之间存在大量冗余;(4)数据中存在混合像素和不同类型的噪声。
为了应对上述挑战并处理高光谱图像,在过去几十年中人们提出了多种机器学习技术。在已开发的机器学习技术中,监督分类技术在不同应用中对高光谱图像进行分类时表现良好。然而,对于高光谱图像的分类,完全监督算法使用每个类别的一组代表性样本,也称为训练样本。在大多数情况下,获取训练样本既昂贵又耗时。因此,无监督学习技术(也称为聚类技术)在许多领域,如计算机视觉、模式识别和数据挖掘中引起了相当大的关注,因为它可以在没有任何标签的情况下对输入数据进行分类。
传统的聚类算法(例如K - 均值和模糊C均值(FCM))通常使用数据点之间的距离度量将它们分组为聚类。例如,K - 均值利用欧几里得距离来衡量数据点之间的相似性;欧几里得距离较小的数据点被分组到同一个聚类中。然而,在传统算法中,在开始处理高光谱图像之前需要定义子空间的维数。此外,由于随机初始化,此类算法的性能不稳定。
受人类视觉系统稀疏编码机制的启发,稀疏表示作为一种强大的方法被开发出来,用于多种计算机视觉任务,包括人脸识别、图像超分辨率和数据分割等。稀疏表示的概念也已成功扩展到处理高光谱图像分类这一具有挑战性的任务中。对于稀疏表示分类(SRC),输入信号(通常是像素向量)由来自字典的样本(原子)的稀疏线性组合来表示,其中现有的训练数据通常用于生成字典。SRC通常具有避免典型监督分类器通常进行的繁重且昂贵的训练过程的重要优势,因为它直接在字典上进行操作。
在文献[19]中,Chen等人提出了一种基于像素的稀疏模型,以监督方式对高光谱图像进行分类。该方法假设光谱像素可以近似表示为由同一类别的字典原子所张成的低维子空间。为了进一步提高光谱分类器的性能并生成更高质量的分类图,文献[19]将空间信息纳入分类框架,形成了联合稀疏模型(JSM)。基于稀疏表示模型开发了许多分类技术,对该方法进行了改进。尽管稀疏表示的概念在处理监督问题方面已经成熟,但在无监督问题中,由于没有训练数据来塑造用于稀疏分类的字典,它仍处于起步阶段。
在过去十年中,基于稀疏子空间的聚类算法已成功应用于高光谱图像分析。例如,在文献[15]中,Elhamifar等人提出了一种名为稀疏子空间聚类(SSC)的无监督学习算法。在SSC中,整个数据集用于识别子空间的数量以及属于每个子空间的数据点。尽管SSC提供了良好的聚类结果,但其缺点之一是处理更大的数据集需要更多的时间和计算能力。
在文献[30]中,作者提出了一种通过正交匹配追踪的稀疏子空间聚类算法(SSC - OMP)。SSC - OMP使用正交匹配追踪算法作为一种贪婪特征选择方法,来计算稀疏优化问题中最稀疏的系数。因此,计算得到的稀疏系数矩阵用于对数据进行聚类。然而,在这种算法中,聚类的数量必须预先定义。
在文献[26]中,作者提出了基于示例的子空间聚类(ESC),这被认为是一种快速的基于稀疏子空间的算法,用于对大型数据集进行聚类。ESC通过使用一些代表性样本来对所有数据进行聚类。由于使用少量样本塑造字典,ESC能够在可接受的处理时间内分析更大的数据集。在ESC中,为了定义代表性样本的子集,首先随机选择子集中的第一个样本,然后基于此选择其他样本。尽管ESC能够有效地处理数据,但其概念存在一些局限性。在ESC中,没有选择子集中第一个样本的标准,这导致算法的不确定性增加。换句话说,由于代表性样本子集中第一个样本的随机选择,算法不稳定。此外,在ESC中,聚类的数量必须预先定义。
在文献[32]中,Wu等人提出了一种分层稀疏子空间聚类算法,用于在多个分辨率下对数据集进行聚类。Wu等人提出的算法能够以半自动方式对数据进行分类,并且对于获取不同分辨率的信息很有用。然而,由于它在分层结构的每个节点中使用SSC对数据进行聚类,这会非常耗时,从而显著降低了算法的效率。
在本文中,为了解决上述挑战,我们提出了一种新的基于分层稀疏子空间的聚类算法来分析高光谱图像。所提出的算法能够以快速且稳健的方式处理大型数据集。在该算法中,使用分层结构在不同细节级别分析数据。分层结构的基础是一种基于套索(lasso)的二元聚类算法,为了加速聚类分析,在该算法中选择一个随机样本进行二元聚类过程。为了减少随机选择的影响,采用了基于熵的集成算法。此外,为了自动生成聚类的数量,通过比较父节点和子节点计算得到的重建误差值来定义一个标准。在最后一步,为每个终端节点分配一个标签以生成最终的聚类图。因此,我们可以将所提出算法的贡献总结如下:
- 我们提出了一种基于稀疏子空间的聚类算法,通过使用一种新颖的套索 - 二元聚类算法,显著降低了计算能力需求。
- 由于在其结构中纳入了基于熵的共识算法,所提出的算法能够提供稳健且稳定的结果,这减少了套索 - 二元聚类算法中初始随机选择样本的影响。
- 所提出的算法受益于已定义的标准,这使得自动生成聚类的数量成为可能。
本文的组织结构如下。第2节详细阐述了最先进的基于稀疏子空间的算法和所提出的算法。随后,第3节展示并讨论了实验结果。最后,第4节致力于结论和展望。
2. 方法论
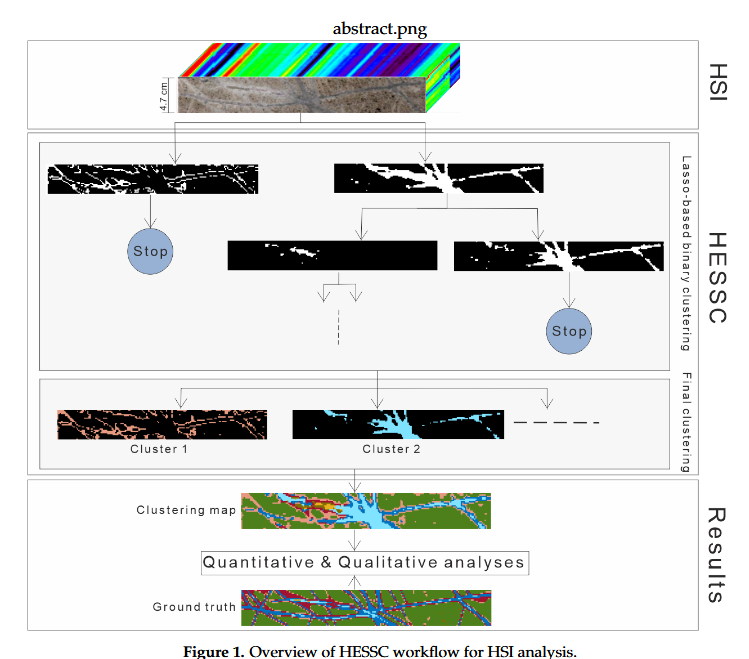
在以下部分,将概述最先进的子空间聚类算法(例如可扩展的基于示例的子空间聚类)。然后详细阐述所提出的聚类算法(HESSC)。所提出算法的工作流程如图1所示。
2.1 最先进的基于稀疏子空间的聚类算法概述
为了更好地理解所提出算法的概念,我们首先介绍稀疏字典学习的概念。设
Y
=
[
y
1
,
y
2
,
.
.
.
,
y
N
]
T
∈
R
D
×
N
Y=[y_{1}, y_{2},..., y_{N}]^{T} \in \mathbb{R}^{D ×N}
Y=[y1,y2,...,yN]T∈RD×N表示高光谱图像,其中
N
N
N是像素数量,
D
D
D是
Y
Y
Y中的光谱带数量(
y
i
=
[
y
i
1
,
y
i
2
,
.
.
.
,
y
i
D
]
T
y_{i}=[y_{i1}, y_{i2},..., y_{iD}]^{T}
yi=[yi1,yi2,...,yiD]T表示
Y
Y
Y中第
i
i
i个像素的测量光谱,
i
∈
1
,
2
,
.
.
.
,
N
i \in{1,2,..., N}
i∈1,2,...,N是高光谱图像中的像素索引)。为了便于解释,假设
Y
Y
Y没有任何类型的误差(例如噪声、测量故障等)。在字典学习问题中,每个
y
i
y_{i}
yi可以由来自光谱字典
A
=
[
a
1
,
a
2
,
.
.
.
,
a
h
]
∈
R
D
×
h
A=[a_{1}, a_{2},..., a_{h}] \in \mathbb{R}^{D ×h}
A=[a1,a2,...,ah]∈RD×h的几个原子的线性或仿射组合来表示,其中
A
A
A是预先定义的由
h
h
h个光谱组成的光谱字典。上述表示可以表述如下:
[y_{i}=A c_{i}, (1)]
其中
c
i
=
[
c
i
1
,
c
i
2
,
.
.
.
,
c
i
h
]
∈
R
h
c_{i}=[c_{i1}, c_{i2},..., c_{ih}] \in \mathbb{R}^{h}
ci=[ci1,ci2,...,cih]∈Rh是信号
y
i
y_{i}
yi的表示系数向量。也可以将方程(1)转换为矩阵形式如下:
[Y=A C, (2)]
其中
C
=
[
c
1
,
c
2
,
.
.
.
,
c
N
]
∈
R
h
×
N
C=[c_{1}, c_{2},..., c_{N}] \in \mathbb{R}^{h ×N}
C=[c1,c2,...,cN]∈Rh×N是可以表示一组数据点的稀疏系数矩阵。然而,
A
A
A通常是超完备的,这导致问题不适定。有很多方法可以处理这个不适定问题。其中一种方法是采用稀疏性原理,通过求解以下优化问题可以得到稀疏系数矩阵:
[min _{C} \quad| C| _{0}]
其中
∥
C
∥
n
\|C\|_{n}
∥C∥n是
C
C
C的
ℓ
n
\ell_{n}
ℓn范数,可以计算为
∥
C
∥
n
=
∑
i
=
1
N
(
∑
j
=
1
N
∣
c
i
j
∣
n
)
1
n
\|C\|_{n}=\sum_{i=1}^{N}(\sum_{j=1}^{N}|c_{ij}|^{n})^{\frac{1}{n}}
∥C∥n=∑i=1N(∑j=1N∣cij∣n)n1 。在方程(3)中,
ℓ
0
\ell_{0}
ℓ0范数表示
C
C
C中非零元素的数量。方程(3)中的问题是一个NP难问题,可以通过贪婪算法(即基追踪)来解决。然而,这样的算法会导致次优解。为了处理NP难问题的情况,在方程(3)中用
ℓ
1
\ell_{1}
ℓ1范数代替
ℓ
0
\ell_{0}
ℓ0范数,
ℓ
1
\ell_{1}
ℓ1范数是
ℓ
0
\ell_{0}
ℓ0范数最接近的凸近似。因此,可以将方程(3)重写为以下凸问题:
[min _{C} \quad| C| _{1} \quad S.t., Y=A C, \quad (4)]
稀疏子空间聚类(SSC)是应用最广泛的基于子空间的聚类算法之一。在SSC中,数据的自表示性意味着每个数据点可以写成同一子空间中其他数据点的线性组合。换句话说,方程(4)中的字典
A
A
A被
Y
Y
Y取代。此外,我们假设
Y
Y
Y中的数据点可以从
H
H
H个线性子空间的并集中抽取,这些子空间可以表示为
{
S
h
}
h
=
1
H
\{S_{h}\}_{h = 1}^{H}
{Sh}h=1H,各自的维度为
{
d
h
}
h
=
1
H
\{d_{h}\}_{h = 1}^{H}
{dh}h=1H。因此,我们可以将
Y
Y
Y表示为
Y
=
Y
1
∪
Y
2
∪
Y
3
∪
⋯
∪
Y
H
Y = Y_{1} \cup Y_{2} \cup Y_{3} \cup \cdots \cup Y_{H}
Y=Y1∪Y2∪Y3∪⋯∪YH,其中每个
Y
h
∈
R
D
×
N
h
Y_{h} \in \mathbb{R}^{D ×N_{h}}
Yh∈RD×Nh是
Y
Y
Y的一个子矩阵,由来自
S
h
S_{h}
Sh子空间的
N
h
N_{h}
Nh个像素组成(还假设
N
h
>
d
h
N_{h}>d_{h}
Nh>dh)。子空间建模的主要目的是使用
Y
Y
Y识别潜在的子空间。因此,亲和形式的稀疏优化问题可以写为:
[min _{C}| C| _{1}]
其中施加约束
d
i
a
g
(
C
)
=
0
diag(C)=0
diag(C)=0,
C
∈
R
N
×
N
C \in \mathbb{R}^{N ×N}
C∈RN×N是为了避免将一个数据点表示为自身的线性组合。此外,
C
T
1
=
1
C^{T}1 = 1
CT1=1是一个约束,以确保它是一个仿射子空间的情况。1是一个所有元素都为1的向量。方程(5)中的优化问题可以通过采用交替方向乘子法(ADMM)来求解。为了更好地理解ADMM求解器,感兴趣的读者可以参考[39,40]。从数据点获得最稀疏的系数矩阵后,计算对称非负相似矩阵
W
∈
R
N
×
N
W \in \mathbb{R}^{N ×N}
W∈RN×N,
W
=
∣
C
∣
+
∣
C
∣
T
W = |C|+|C|^{T}
W=∣C∣+∣C∣T。
W
W
W需要是对称的,以确保来自同一子空间的所有节点相互连接。在SSC的最后一步,对相似矩阵应用谱聚类以生成最终的聚类结果。尽管SSC提供了可靠的结果,但该算法存在内存不足的问题,因为SSC使用
Y
Y
Y中的所有数据点来求解方程(5)中的稀疏优化问题。这个问题导致在大型数据集中计算时间非常长。
通过正交匹配追踪的稀疏子空间聚类算法(SSC - OMP)是一种基于稀疏子空间的算法,它使用OMP来求解方程(5)中的优化问题。在SSC - OMP中,假设数据受到噪声污染。为了求解方程(5),选择一个使绝对值与残差的乘积最大化的数据点。因此,SSC - OMP可以写为:
[min _{C}| C| _{1}]
其中
κ
\kappa
κ表示从
Y
Y
Y中选择的用于计算最稀疏系数的数据点数量。
κ
\kappa
κ是根据数据中存在的噪声来选择的。计算方程(6)中的
C
C
C之后是计算
W
W
W,最后一步是对
W
W
W应用谱聚类。然而,聚类的数量应该预先知道。此外,
κ
\kappa
κ的确定也很关键。
另一种最近先进的基于稀疏子空间的聚类算法是基于示例的子空间聚类(ESC)。在文献[26]中,You等人提出了ESC来应对SSC在大型数据集中的可扩展性问题。在ESC中,选择一些代表性样本(也称为 “示例”)来计算最稀疏的系数矩阵,其中代表性样本的第一个样本是随机选择的。ESC中的优化问题可以表述如下:
[min {C, \mathcal{Y}{0}}| C| {1}+\frac{\lambda}{2}\left| Y-\mathcal{Y}{0} C\right| _{F}^{2},]
其中稀疏系数矩阵是
C
∈
R
P
×
N
C \in \mathbb{R}^{P ×N}
C∈RP×N,
λ
\lambda
λ是稀疏性和保真度项之间的权衡参数,
Y
0
=
[
y
1
,
y
2
,
.
.
.
,
y
P
]
∈
R
D
×
P
Y_{0}=[y_{1}, y_{2},..., y_{P}] \in \mathbb{R}^{D ×P}
Y0=[y1,y2,...,yP]∈RD×P是从
Y
Y
Y中选择的代表性样本(“示例”)的子集,其中
P
P
P(
P
∈
Z
P \in \mathbb{Z}
P∈Z且
P
<
<
N
P<<N
P<<N)需要预先定义。为了计算方程(7)中的
C
C
C,使用LARS算法的套索版本。由于方程(7)中计算的
C
C
C的维度,为了获得最终的聚类图,对相似矩阵
W
∈
R
N
×
N
W \in \mathbb{R}^{N ×N}
W∈RN×N应用谱聚类步骤,
W
W
W是使用每个
c
i
c_{i}
ci的
t
t
t近邻计算得到的。在ESC中,
y
0
y_{0}
y0用作字典来求解方程(7)中的最小化问题。因此,通过使用数据点子集而不是整个数据,处理时间将有效减少。据我们所知,ESC尚未被用于分析高光谱图像。尽管ESC能够快速处理相对较大的数据集,但其概念存在一个缺点;如前所述,在ESC中,子集
y
0
y_{0}
y0的第一个样本是随机选择的。随后,其余的代表性样本通过使用文献[26]中提出的最远优先搜索方法来确定,该方法使用方程(7)作为成本函数。由于
y
0
y_{0}
y0中第一个样本的随机选择,算法的可靠性受到影响。此外,在ESC中,
P
P
P的选择是另一个缺点,因为选择合适数量的代表性样本对最终聚类结果有很大影响。
2.2 分层稀疏子空间聚类(HESSC)
在本小节中,将详细描述所提出的算法。该方法包括以下三个阶段:(1)分层结构(一棵树),它允许从高光谱图像中在不同层次检索信息(见图2);(2)基于套索的二元聚类,这是HESSC结构的核心部分,应用于树的每个节点上的现有数据点(见图3);(3)标准定义,将在2.2.3节详细描述,它决定当前节点是否可以进一步分裂。在HESSC的第三阶段使用这个标准,能够为被分析的数据集自动生成合适数量的聚类。算法返回的聚类由分层结构的叶节点定义,这些叶节点是不再进一步分裂的节点。具体来说,与这些节点相关的数据点定义了最终的聚类。
2.2.1 HESSC中的分层结构
用 Y r , l b Y_{r, l_{b}} Yr,lb表示与树的第 b b b层的第 r r r个节点相关联的数据点集,其中 r = 1 , 2 r = {1,2} r=1,2, b ∈ 0 , 1 , . . . , l b \in {0,1,..., l} b∈0,1,...,l , l l l是一个用户定义的参数,它指定高光谱图像需要被探索到什么层次,并间接定义了HESSC中聚类数量的上限( 2 l 2^{l} 2l)。 Y r , l b Y_{r, l_{b}} Yr,lb由 N r , l b N_{r, l_{b}} Nr,lb个像素组成,且 N r , l b < N N_{r, l_{b}} < N Nr,lb<N 。在HESSC中,建立了一种基于树的数据结构,以在不同细节层次描述高光谱图像中数据点的现有变化。此外,HESSC通过在每个节点将数据划分为更小的子集来降低计算成本。如图2所示,第一个节点与原始高光谱图像相关联( Y l 0 = Y Y_{l_{0}} = Y Yl0=Y )。随后,二元聚类算法(图3)应用于 Y l 0 Y_{l_{0}} Yl0 ,将与当前节点相关的 Y l 0 Y_{l_{0}} Yl0分裂为两组,分别表示为 Y 1 , l 1 Y_{1, l_{1}} Y1,l1和 Y 2 , l 1 Y_{2, l_{1}} Y2,l1 ,它们是第一层的两个节点。从数学上讲,这相当于 Y l 0 = Y 1 , l 1 ∪ Y 2 , l 1 Y_{l_{0}} = Y_{1, l_{1}} \cup Y_{2, l_{1}} Yl0=Y1,l1∪Y2,l1 。结果,每个节点的分裂过程持续进行,直到树达到其最大层次,此时没有任何约束的叶节点数量等于 2 l 2^{l} 2l ,或者满足HESSC中定义的标准(见2.2.3节)。尽管如此,上述整个过程依赖于HESSC背后的主要思想,即基于套索的二元聚类。在当前节点获得二元聚类结果后,根据定义的标准,做出是否划分当前节点的决策。
2.2.2 HESSC中的二元聚类
所提出方法的核心是一种基于套索函数的二元聚类算法。HESSC中的稀疏优化问题与ESC最小化问题等价,如公式(7)所示。因此,我们可以将HESSC的优化问题写为:
[min {C}| C| {1}+\frac{\lambda}{2}\left| Y{r, l{b}}-\overline{y}_{i} C\right| _{F}^{2},]
其中
C
∈
R
1
×
N
r
,
l
b
C \in \mathbb{R}^{1 ×N_{r, l_{b}}}
C∈R1×Nr,lb表示计算得到的稀疏系数,它等同于公式(8)中的
c
2
c_{2}
c2 ,
y
‾
i
\overline{y}_{i}
yi是从
Y
r
,
l
b
Y_{r, l_{b}}
Yr,lb中随机选择的一个样本。公式(7)和(8)中优化问题的主要区别在于,在HESSC中,不是使用一组代表性样本,而是使用一个随机样本
y
‾
i
\overline{y}_{i}
yi来求解稀疏优化问题。在ESC中,随着
P
P
P的增加,执行时间往往会变慢,而在公式(8)中,求解优化问题所需的处理时间比公式(7)相关的优化问题要少。公式(8)中优化问题的计算负担大大降低,因为只选择一个随机样本求解稀疏优化问题。由于
y
‾
i
\overline{y}_{i}
yi是随机选择的,为了减少二元聚类过程中的随机性影响,HESSC采用了基于熵的共识聚类算法(ECC),该算法在文献[33]中提出。据我们所知,这是首次尝试在高光谱图像分析框架中使用ECC。ECC最初使用一种基本聚类算法(例如K - 均值算法),通过改变聚类数量来获得
k
k
k个不同的聚类结果(数据集的不同分组)。随后,ECC使用香农熵作为效用函数,来量化两个聚类结果之间的相似性(效用函数的值越高,两个聚类结果彼此越接近),并寻找与基本聚类算法产生的所有
k
k
k个聚类输出具有最大相似性的集成聚类。为了实现ECC,开发了一种改进的距离K - 均值算法来获得最终的聚类图。在文献[33]中,增加以下参数之一会增加执行时间:(1)ECC算法中的迭代次数
I
I
I ;(2)聚类输出的数量,用
k
k
k表示,这些输出连接起来作为ECC的输入;(3)
c
c
c ,即高光谱图像中的聚类数量。虽然在HESSC中,参数
c
c
c等于2,但增加
I
I
I和
k
k
k也会增加HESSC的执行时间。有关ECC的更多详细信息,感兴趣的读者可参考文献[33]。通过求解公式(8)提取出最稀疏的系数矩阵后,将最稀疏的系数按升序排序,然后计算
Y
r
,
l
b
Y_{r, l_{b}}
Yr,lb中第
i
i
i个元素的累积和(
C
S
i
CS_{i}
CSi ),即
C
S
i
=
∑
i
=
1
N
r
,
l
b
s
o
r
t
e
d
(
c
i
)
CS_{i}=\sum_{i = 1}^{N_{r, l_{b}}} sorted(c_{i})
CSi=∑i=1Nr,lbsorted(ci) ,其中
C
S
i
CS_{i}
CSi是一个具有
N
r
,
l
b
N_{r, l_{b}}
Nr,lb个元素的向量。然后,
C
S
i
CS_{i}
CSi通过其第
N
r
,
l
b
N_{r, l_{b}}
Nr,lb个元素(即
C
S
i
CS_{i}
CSi中的最大值)在0到1之间进行归一化。因此,为了生成
Y
r
,
l
b
Y_{r, l_{b}}
Yr,lb的二元聚类结果,使用特定的阈值标准,即
C
S
i
C
S
i
N
r
,
l
b
>
τ
\frac{CS_{i}}{CS_{iN_{r, l_{b}}}}>\tau
CSiNr,lbCSi>τ ,其中
0
<
τ
<
1
0<\tau<1
0<τ<1是用户定义的阈值,所有
C
S
i
C
S
i
N
r
,
l
b
\frac{CS_{i}}{CS_{iN_{r, l_{b}}}}
CSiNr,lbCSi小于或大于
τ
\tau
τ的点分别被分配到聚类0或1。
我们将 τ \tau τ设置为0.5,因为这个值足够大以捕获高光谱图像中的一般信息,同时又足够小以捕获其中的详细信息。然而,如果希望在每个聚类中捕获更多细节,则需要将 τ \tau τ设置得接近0。所提出的二元聚类算法的结构如图3所示。在运行二元聚类步骤 k k k次后(每次选择的 y ‾ i \overline{y}_{i} yi不同),将所有 k k k个二元输出堆叠形成一个二元矩阵(BM)。在我们提出的算法中, k k k和 I I I分别设置为100和40。这些值是文献[33]的开发者建议的默认最优值。之后,对BM应用ECC,将父节点分裂为两个子节点。上述过程持续进行,直到满足HESSC的某个标准。最终,为分层结构的每个叶节点的数据点分配一个标签,以生成最终的聚类图。
2.2.3 聚类数量的自动生成
在HESSC中定义了以下标准,以自动生成最具代表性的聚类数量。最优参数依赖于分层结构中每个节点的重建误差值。无论如何,第一个节点
Y
l
0
Y_{l_{0}}
Yl0都会被划分为两个节点(
Y
1
,
l
1
Y_{1, l_{1}}
Y1,l1和
Y
2
,
l
1
Y_{2, l_{1}}
Y2,l1 ),且
Y
l
0
=
Y
1
,
l
1
∪
Y
2
,
l
1
Y_{l_{0}} = Y_{1, l_{1}} \cup Y_{2, l_{1}}
Yl0=Y1,l1∪Y2,l1 。假设在
l
1
l_{1}
l1层中,矩阵
C
r
,
l
1
=
Y
r
,
l
1
Y
r
,
l
1
T
C_{r, l_{1}} = Y_{r, l_{1}}Y_{r, l_{1}}^{T}
Cr,l1=Yr,l1Yr,l1T的特征分解可以得到
C
r
,
l
1
=
Q
r
,
l
1
Λ
Q
r
,
l
1
T
C_{r, l_{1}} = Q_{r, l_{1}}\Lambda Q_{r, l_{1}}^{T}
Cr,l1=Qr,l1ΛQr,l1T ,其中
Q
r
,
l
1
=
[
q
1
,
.
.
.
,
q
N
r
,
l
1
]
∈
R
D
×
N
r
,
l
1
Q_{r, l_{1}} = [q_{1},..., q_{N_{r, l_{1}}}] \in \mathbb{R}^{D ×N_{r, l_{1}}}
Qr,l1=[q1,...,qNr,l1]∈RD×Nr,l1和
Λ
=
d
i
a
g
(
λ
1
,
λ
2
,
.
.
.
,
λ
N
r
,
l
1
)
\Lambda = diag(\lambda_{1}, \lambda_{2},..., \lambda_{N_{r, l_{1}}})
Λ=diag(λ1,λ2,...,λNr,l1)分别是
Y
r
,
l
1
Y_{r, l_{1}}
Yr,l1的特征向量和特征值。因此,通过获得
Q
r
,
l
1
Q_{r, l_{1}}
Qr,l1和
Λ
\Lambda
Λ ,可以估计每个子空间的维度。每个子空间的正交基可以写为
U
=
[
q
1
,
.
.
.
,
q
d
r
,
l
1
]
U = [q_{1},..., q_{d_{r, l_{1}}}]
U=[q1,...,qdr,l1] ,其中
d
r
,
l
1
d_{r, l_{1}}
dr,l1是在第
r
r
r个节点和
l
1
l_{1}
l1层中识别出的子空间维度。
d
r
,
l
b
d_{r, l_{b}}
dr,lb参数可以使用能量阈值估计为
d
r
,
l
b
=
m
i
n
d
∑
i
=
1
d
λ
i
∑
i
=
1
N
r
,
l
b
λ
i
≥
α
d_{r, l_{b}} = min _{d} \frac{\sum_{i = 1}^{d} \lambda_{i}}{\sum_{i = 1}^{N_{r, l_{b}}} \lambda_{i}} \geq\alpha
dr,lb=mind∑i=1Nr,lbλi∑i=1dλi≥α ,为了捕获每个节点中数据的更高变化,
α
\alpha
α固定为0.99。接着,使用父节点和子节点的重建误差值来进一步划分子节点。父误差(
E
r
E_{r}
Er )和子误差(
E
r
′
E_{r}'
Er′ )可以表示为:
[\begin{aligned} E_{r} & =\frac{\left| Y_{r, l_{b}-1}\left(1-U_{1, l_{b}-1} U_{1, l_{b}-1}^{T}\right)\right| {F}^{2}}{\left| Y{r, l_{b}-1}\right| {F}^{2}} \ E{r}’ & =\frac{\left| Y_{r, l_{b}}\left(1-U_{r, l_{b}} U_{r, l_{b}}^{T}\right)\right| {F}^{2}}{\left| Y{r, l_{b}}\right| _{F}^{2}} \end{aligned} (9)]
因此,如果 ( E r − E r ′ ) E r ≥ β \frac{(E_{r}-E_{r}')}{E_{r}} \geq\beta Er(Er−Er′)≥β ,则子节点将进一步分裂,其中 0 ≤ β ≤ 1 0 \leq\beta \leq1 0≤β≤1是一个预定义参数,用于控制节点的划分, β \beta β越接近0意味着聚类结果的聚类数量越多。
3. 实验结果
3.1 数据采集与描述
为了全面比较应用的聚类算法,使用了三个真实的岩芯高光谱图像和一个著名的基准数据集(即特伦托数据集)。本节致力于数据采集方法以及所使用岩芯样本的矿物学信息。使用SisuRock岩芯扫描仪获取岩芯样本的高光谱图像。该扫描仪配备了AisaFENIX VNIR - SWIR高光谱传感器和FENIX传感器,覆盖380 - 2500nm的光谱范围,共450个波段。在这种设置下,获得的像素大小为1.5mm/像素。此外,经过训练的地质学家对岩芯样本进行了目视分析,并根据岩芯的矿脉和基质成分将其划分为不同区域。从斑岩系统内不同位置采集的三个岩芯样本用于测试所提出的方法。第一个样本由27×190个像素组成,其特征是普遍存在钙钠质向钾质蚀变。基质主要由斜长石、石英、黑云母和绿泥石组成。该样本中存在两种主要的矿脉类型:以硫化物为中心线、具有低强度蚀变晕(主要由白云母组成)的石英脉,以及以硫化物为中心线、向纯硫化物脉过渡的硫酸钙脉。后一种矿脉类型显示出更高的强度和更宽的由白云母组成的蚀变晕。第二个样本也由27×190个像素组成,在这个样本中,岩石基质主要由斜长石、石英和绿泥石组成,这是该系统中钠质 - 叶腊石质过渡的特征。该样本包含三种主要的矿脉类型:具有宽白云母蚀变晕的硫化物脉,被主要由石英、硫酸钙和硫化物组成的第二种脉交叉切割;最后,具有几乎不可见蚀变晕的细硫化物脉被前面提到的两种脉交叉切割。样本3由28×189个像素组成,其特征是普遍的钾质蚀变;基质主要由长石、黑云母和少量绿泥石组成。该样本中也存在两种主要的矿脉类型:以硫化物为主、具有高强度白云母蚀变晕的脉,以及以硫化物或硫化物和硫酸钙为中心线的石英脉。在两种主要矿脉类型重新张开或交叉切割的地方,可以观察到复杂的矿脉成分。
此外,特伦托数据集被用作基准,以比较不同聚类算法的性能。特伦托数据集是在意大利特伦托市南部的一个农村地区采集的。该数据集由166×600个像素组成。该地区的高光谱图像由AISA Eagle传感器捕获。高光谱图像由63个光谱波段组成,范围从402.89nm到989.09nm。高光谱图像的空间分辨率和光谱分辨率分别为1m和9.2nm。采集高光谱图像的感兴趣区域包括以下六个不同的类别:苹果树、建筑物、地面、木材、葡萄园和道路。
3.2 评估指标
为了评估应用的聚类算法的性能,选择了三个验证指标,其合理性在文献[44]中有所描述。用
G
=
[
g
1
,
g
2
,
.
.
.
,
g
N
]
G = [g_{1}, g_{2},..., g_{N}]
G=[g1,g2,...,gN]表示高光谱图像的真实情况。高光谱图像的聚类结果表示为
M
=
[
m
1
,
m
2
,
.
.
.
,
m
N
]
M = [m_{1}, m_{2},..., m_{N}]
M=[m1,m2,...,mN] ,其中
m
i
=
1
,
2
,
3
,
.
.
.
,
L
m_{i} = {1,2,3,..., L}
mi=1,2,3,...,L 。第一个指标是聚类准确率(CA),它通过计算在所有可能的标签排列中正确标记像素的最大比例来衡量。CA可以表述如下:
[max {\pi \in \Pi} \frac{100}{N} \sum{i}^{N} n_{i, \pi(i)} (10)]
其中
Π
\Pi
Π是
{
1
,
2
,
.
.
.
,
N
}
\{1,2,..., N\}
{1,2,...,N}的所有排列的集合,
n
i
j
n_{ij}
nij等于
M
i
M_{i}
Mi和
G
j
G_{j}
Gj之间匹配的元素数量(
n
i
j
=
∣
M
i
∩
G
j
∣
n_{ij} = |M_{i} \cap G_{j}|
nij=∣Mi∩Gj∣ )。为了计算
n
i
j
n_{ij}
nij ,应用了一种聚类标签和真实标签之间的匹配函数。关于所应用的匹配函数的更详细阐述可以在文献[31]中找到。
聚类结果的第二个评估指标是所谓的F - 度量。F - 度量可用于报告
M
M
M对
G
G
G的描述程度;F - 度量值的范围在0到1之间。F - 度量值越接近1,意味着
M
M
M对
G
G
G的描述越好。为了计算两个分区的F - 度量,需要两个变量:第一个变量是精度,等于
p
i
j
=
n
i
j
∣
G
j
∣
p_{ij}=\frac{n_{ij}}{|G_{j}|}
pij=∣Gj∣nij ,第二个变量是召回率,可以写为
r
i
j
=
n
i
j
∣
M
i
∣
r_{ij}=\frac{n_{ij}}{|M_{i}|}
rij=∣Mi∣nij 。对于第
i
j
ij
ij项,F - 度量可以计算为
F
i
j
=
2
∗
r
i
j
∗
p
i
j
r
i
j
+
p
i
j
F_{ij}=\frac{2 * r_{ij} * p_{ij}}{r_{ij}+p_{ij}}
Fij=rij+pij2∗rij∗pij ,
j
∈
1
,
2
,
.
.
.
,
N
j \in{1,2,..., N}
j∈1,2,...,N 。此外,总体F - 度量由下式给出:
[max {\pi \in \Pi} \frac{100}{N} \sum{i}^{N} \mathcal{F}_{i, \pi(i)}]
第三个指标是调整兰德指数(ARI),它基于兰德指数度量。兰德指数被引入用于比较不同聚类算法的性能。兰德指数是根据两个不同分区的列联表(混淆矩阵)计算的 —— 在这种情况下,是聚类结果向量
M
M
M和真实标签向量
G
G
G之间的混淆矩阵。因此,在兰德指数中,列联表的信息可用于衡量两个分区之间的一致性程度。在文献[46]中,Hubert等人提出了ARI,它是对原始兰德指数的修正,以消除偶然性的影响。ARI的数学公式为:
ARI的范围通常在{0,1}之间。ARI越接近1,意味着
M
M
M和
G
G
G的一致性越高。然而,ARI也可能得到负值,这表明
M
M
M和
G
G
G之间的一致性甚至比随机结果预期的还要低。不过,为了更便于解释,我们以百分比形式呈现得到的ARI。因此,ARI越接近100%越好,相比之下,接近0%则较差。
3.3 聚类结果的定量分析
为了对K - 均值、FCM、ECC、SSC、SSC - OMP、ESC和HESSC在岩芯高光谱图像上的性能进行定量评估,由地质学家绘制每个样本的参考图。随后,将生成的参考图调整为高光谱图像的大小。每个样本的聚类数量是根据从实验室测量和地质学家的地质解释中获得的先验知识来确定的。接着,使用上述评估指标将不同聚类算法的输出相互进行比较(表1 - 3)。在实验中,对于ECC、SSC和SSC - OMP,使用了其开发者在[15,31,33]中提出的默认参数。此外,如2.1节所述,对于ESC,需要预先定义作为代表性样本数量的P。因此,如图4所示,对于每个岩芯样本,ESC在具有不同数量代表性样本(范围在{1, 2, …, 100})的情况下运行。选择聚类准确率(CA)最高的“示例”数量用于进一步研究。样本1、样本2和样本3选择的示例数量分别为41(CA = 32.51)、77(CA = 38.32)和71(CA = 44.03)。对于特伦托数据集,使用了开发者在[26]中建议的默认值。如前所述,K - 均值、FCM、ECC、SSC、SSC - OMP和ESC需要预先定义聚类数量才能运行。然而,在HESSC中,聚类数量是自动生成的。因此,通过试错法调整HESSC中的参数β,以实现与生成的参考数据相似的聚类数量。对于每个数据集的聚类数量,样本1、样本2、样本3和特伦托数据集分别定义为7、8、4和6个聚类。定量评估结果如表1所示。对于样本1,HESSC在对矿物进行聚类时表现良好。在第一个样本中,HESSC(CA = 53.12 ± 0.00)的性能明显优于其竞争算法。在HESSC之后,SSC - OMP(CA = 45.39 ± 0.83)的表现优于其他算法,如SSC和ESC。对于第二个样本,如表2所示,HESSC的结果为CA = 46.53 ± 0.00,优于其他竞争算法。就样本2的F - 度量而言,ESC(F - 度量 = 26.26 ± 5.85)的表现优于HESSC(F - 度量 = 22.23 ± 0.00)。此外,ECC在CA、F - 度量和ARI测量方面分别比K - 均值高出近3%、1%和2%。根据表3中的结果,HESSC(CA = 61.31 ± 0.58)的表现优于ESC(CA = 50.03 ± 11.19)。总体而言,HESSC在所有三个岩芯样本上,基于不同评估指标的表现最为准确,且在10次试验中的标准差几乎最低。另一个观察结果是,尽管ECC在所有样本上的表现与K - 均值相似,但它的标准差比K - 均值低,这表明ECC比K - 均值的性能更稳定。在所有应用的聚类算法中,FCM和SSC的表现最弱。如表4所示,与其他聚类算法相比,HESSC对特伦托数据集的聚类更准确(CA = 56.39 ± 0.00)。使用不同聚类算法对三个岩芯高光谱图像进行聚类的聚类图如图5所示。在特伦托数据集中,在基于距离的算法中,FCM(CA = 53.88 ± 0.00)的表现优于K - 均值和ECC。然而,SSC - OMP(CA = 34.80 ± 0.00)和ESC(CA = 33.66 ± 0.02)在聚类任务中的表现较弱。如图6所示,与其他聚类算法相比,HESSC能更准确地识别不同类别,即建筑物、木材和道路。然而,HESSC无法区分苹果树和木材。SSC - OMP得到的聚类图显示其在特伦托数据集上的表现比其他算法弱,这可能是由于所选样本数量的原因。需要注意的是,由于内存问题,SSC无法在我们的计算机上对该数据集进行处理。
3.4 执行时间
本小节致力于评估每个聚类算法的处理时间。处理时间的结果如表5所示。所有应用的算法都在一台配备Intel© core - i9 7900X处理器和128GB内存的计算机上用MATLAB实现。如表5所示,K - 均值在处理所有数据集的数据时速度很快。然而,就CA、F - 度量和ARI而言,K - 均值的性能由于其随机初始化而不稳定,因此与其他算法相比,它的鲁棒性较差。对于三个岩芯样本,原始的SSC导致了最长的处理时间,这表明该算法计算成本高昂。这种高处理时间的原因是SSC使用ADMM来解决稀疏优化问题。此外,由于内存限制,SSC无法应用于特伦托数据集。尽管SSC - OMP和ESC速度很快,但从CA来看,它们的性能与HESSC相比很弱。这可能是由于为解决其优化问题而选择的样本数量(即κ和P)。基于这一观察,增加P和κ会使聚类过程变慢。在HESSC中,ECC步骤的时间复杂度负担在各个节点之间分配,这导致原始ECC的执行时间减少。然而,ECC仍然是HESSC结构中最耗时的步骤。与HESSC相比,ECC在所有岩芯样本上的速度快了近30秒。ECC更快的性能可能是由于存在用户在ESC中定义的较小代表性样本子集。尽管如此,HESSC在所有三个岩芯样本上都比特伦特数据集上的SSC - OMP快近30秒。
3.5 聚类结果的定性分析
从地质角度来看,经过训练的地质学家检查了如图5所示的聚类输出。对于三个样本的大多数特征,K - 均值、FCM和ECC表现出相似的性能。在样本1的情况下,HESSC的表现优于其他算法,能够绘制出矿脉成分的变化。然而,对于所有方法,硫化物的分布似乎都略有不准确。此外,HESSC对样本基质中可用的小变化不太敏感,这些小变化在勘探目的中被认为是可以忽略的。一个缺点是HESSC遗漏了基质中富含黑云母的区域,这可能表明向矿床钾质带的过渡。虽然其他方法,如K - 均值、FCM、ECC和ESC绘制了基质中的变化,但它们也无法准确区分富含黑云母的区域。对于样本2,可以观察到这些方法的类似性能。HESSC、K - 均值、FCM和ECC能够识别出较厚的亚垂直矿脉的成分变化,从富含硫化物的矿脉填充到富含石英的矿脉填充。由于所用传感器的空间分辨率,所有方法都无法准确识别细硫化物脉。对于亚水平硫化物矿脉,SSC、SSC - OMP和ESC对其的绘制与亚垂直矿脉类似,但没有像其他方法那样将其误分类为基质。HESSC也将部分矿脉与亚垂直矿脉匹配,另一部分与基质匹配。同时,所有方法都识别出了蚀变晕中非常细微的变化,这些变化在生成的参考图中未被考虑。矿脉和晕与参考数据存在差异的原因可以归因于蚀变晕的细微成分变化对光谱响应的影响比石英 - 硫化物比率的影响更大。在样本3的情况下,与其他方法相比,HESSC能更好地绘制出富含黑云母的基质。在矿脉识别方面,所有方法都存在困难。首先,由于传感器的空间分辨率,基质中心的非常细的矿脉被遗漏了。此外,右侧以硫化物为中心线的石英脉被所有方法遗漏或误分类为带有白云母蚀变晕的细硫化物脉。在参考数据中定义的硫化物类别在HESSC生成的图中似乎略有保留。在SSC、SSC - OMP和ESC中,该类别被外推到基质中;此外,K - 均值、FCM和ECC高估了该类别。然而,由于参考数据的重采样,一些硫化物标记也在其中丢失了,因此这将影响每种方法的定量评估。
3.6 自动生成聚类数量的评估
为了评估聚类数量的自动生成方式,我们建议在使用HESSC时为三个不同样本设置固定参数。地质学家对获得的结果进行了目视检查。此外,将使用自动生成聚类数量的HESSC的性能与其他应用的聚类算法进行了比较。HESSC自动生成的相同聚类数量也用作K - 均值、FCM、SSC、SSC - OMP和ESC的输入。对于自动生成的聚类,可以进行与先前结果类似的性能评估。如图7所示,在样本3的情况下,自动生成的聚类数量相同,因此不再重复方法比较。此外,在本次评估中,样本1和样本2都分配了六个聚类。样本1的结果与较高聚类数量时获得的结果相对一致;然而,硫化物类别缺失,被通常解释为硫化物 - 石英的类别所取代。基质中存在更强的变化,富含黑云母的类别被K - 均值、FCM、ECC、SSC和HESSC识别出来,但略有高估。在样本2的情况下,聚类数量的减少导致HESSC对亚垂直矿脉成分变化的敏感性降低,以及K - 均值对矿脉和蚀变晕的混淆。同时,蚀变晕的绘制似乎受噪声影响较小,并且与RGB图像中明显的变化一致。在K - 均值、FCM和ECC的情况下,观察到与蚀变晕变化相关的准确性下降。ESC和SSC在与上一小节中呈现的较高聚类数量方面表现出类似的性能。
3.7 HESSC算法中参数的敏感性
在本节中,研究了HESSC算法中每个参数的敏感性。HESSC中有三个主要参数(即l、τ和β)会影响自动生成过程。如第2节所述,l是一个预定义参数,用于指示算法应进行的细节级别(深度)。换句话说,l用于定义算法可以实现的聚类数量的上限( 2 l 2^{l} 2l )。为了评估HESSC中其他参数(τ,β)的敏感性,定义了两种不同的场景,并使用样本1的实验结果如表6和表7所示。在第一种场景中,假设β固定为0.5。结果,随着τ值从0.1增加到0.9,聚类数量最终增加到5,如表6所示。因此,τ可以被描述为一个定义HESSC中所需细节量的参数。为了获得更详细的结果,希望将 τ \tau τ设置得远小于1。另一方面,如表7所示,当 τ = 0.5 \tau = 0.5 τ=0.5时,随着β值从0增加到1,聚类数量减少。因此,为了获得更多的聚类,有必要使 β < 0.5 \beta < 0.5 β<0.5 。
4. 结论
在本文中,我们提出了一种分层聚类算法(HESSC),它能够以稳健且快速的方式分析高光谱图像。采用分层方法在不同细节级别分析高光谱图像。所得分层结构的每个节点中的主要处理任务包括基于稀疏子空间的二元聚类算法,其中在树的每个节点中使用随机样本计算稀疏表示矩阵以解决稀疏优化问题。为了减少随机性的影响,HESSC中采用了基于熵的集成算法。此外,HESSC能够通过使用一个包含每个节点重建误差值的标准自动生成聚类数量。如果子节点的重建误差低于父节点的重建误差,则子节点继续分裂;否则,子节点不再进一步分裂。对三个真实岩芯高光谱图像以及特伦托基准数据集的实验结果支持了我们关于所提出的基于分层稀疏子空间的聚类算法性能的研究结果。
作为未来可能的工作,将研究纳入高光谱图像空间信息的影响,因为与距离较远的像素相比,相邻像素更有可能具有相似的聚类标签。此外,我们将把所提出的算法应用于不同类型和更大的数据集,以进一步研究HESSC的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









