







机器学习的基本框架-Framework of ML

训练的三个基本步骤,如上图所示。
我们一般直接跑sample code,往往只能得到baseline的结果,那如何获得更好的结果呢,本节会简略的回答这个问题。
攻略:

如果说你觉得你对自己的训练结果不满意的话,第一步应该先检查你的training data 的loss,如果你的模型在training data上的loss比较大,那么你需要思考这是model bias还是optimization的问题。
model bias:

model bias可能意味着你的模型太过于简单了,以至于最优解根本就不在你model的集合里,这时你或许需要增加更多的特征来使你的model更具有弹性,例如加深网络层数,把20层的网络加深到56层之类的。
另一种可能,你的模型已经足够好了,但是你的优化求解没做好,即你没有找到最优解:例如使用梯度下降法陷入局部最优了
which one?

好的,如果你发现你在training data上的loss已经比较小了,那么你需要查看它在test data上的loss情况如何。
过拟合
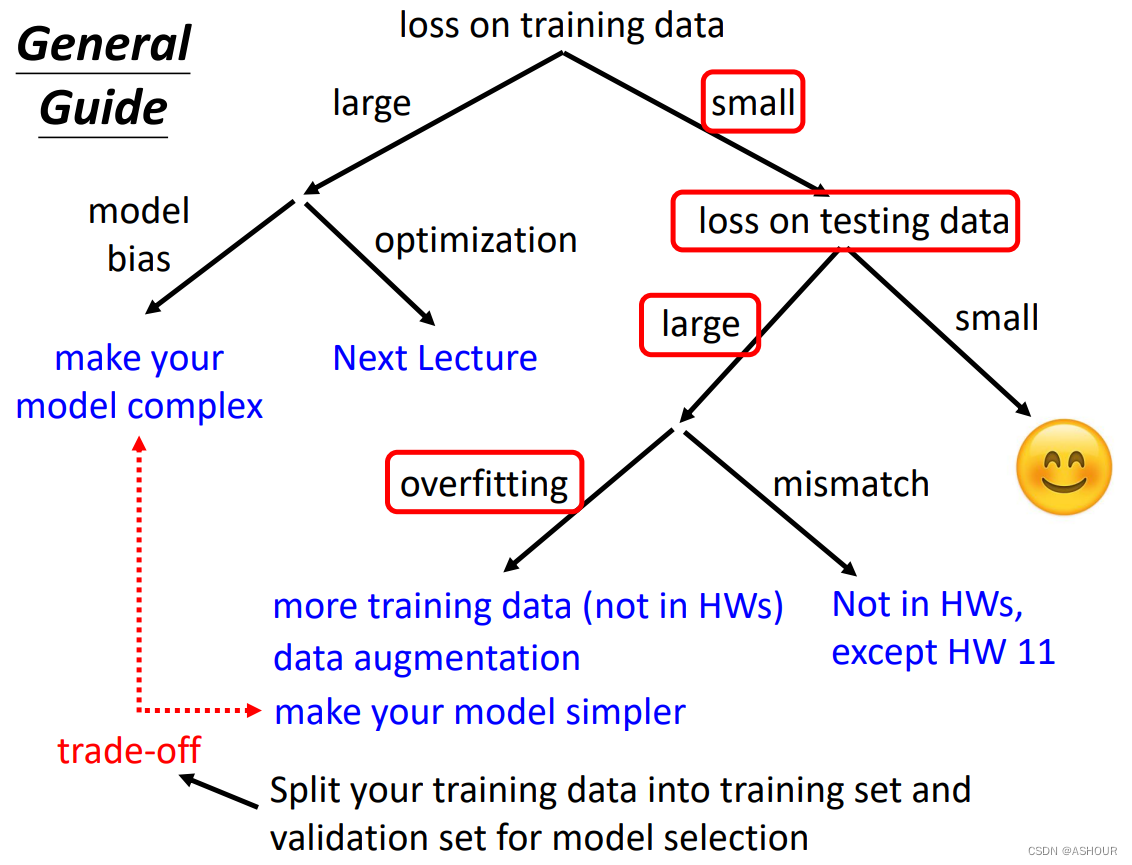 如果你发现你的model在training data上的loss比较小,但在test data上的loss很大,那么很可能你的model overfitting也就是过拟合了。
如果你发现你的model在training data上的loss比较小,但在test data上的loss很大,那么很可能你的model overfitting也就是过拟合了。
下面举一个过拟合的极端例子:
 定义这个函数为,如果输入属于训练集,则输出对应的正确标签,反之则输出随机,这个极端的函数在训练集上的损失为0,但是在测试集上的loss可想而知会非常大。
定义这个函数为,如果输入属于训练集,则输出对应的正确标签,反之则输出随机,这个极端的函数在训练集上的损失为0,但是在测试集上的loss可想而知会非常大。
一般过拟合的情况:
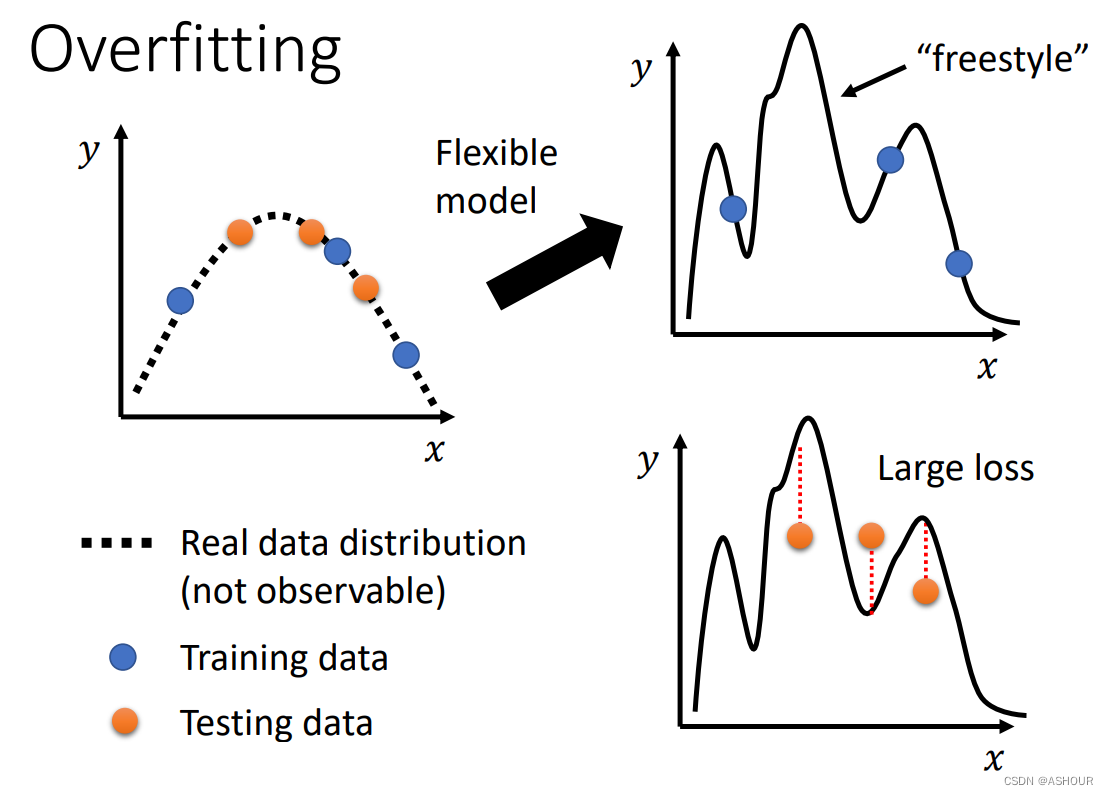
解决过拟合的方法:
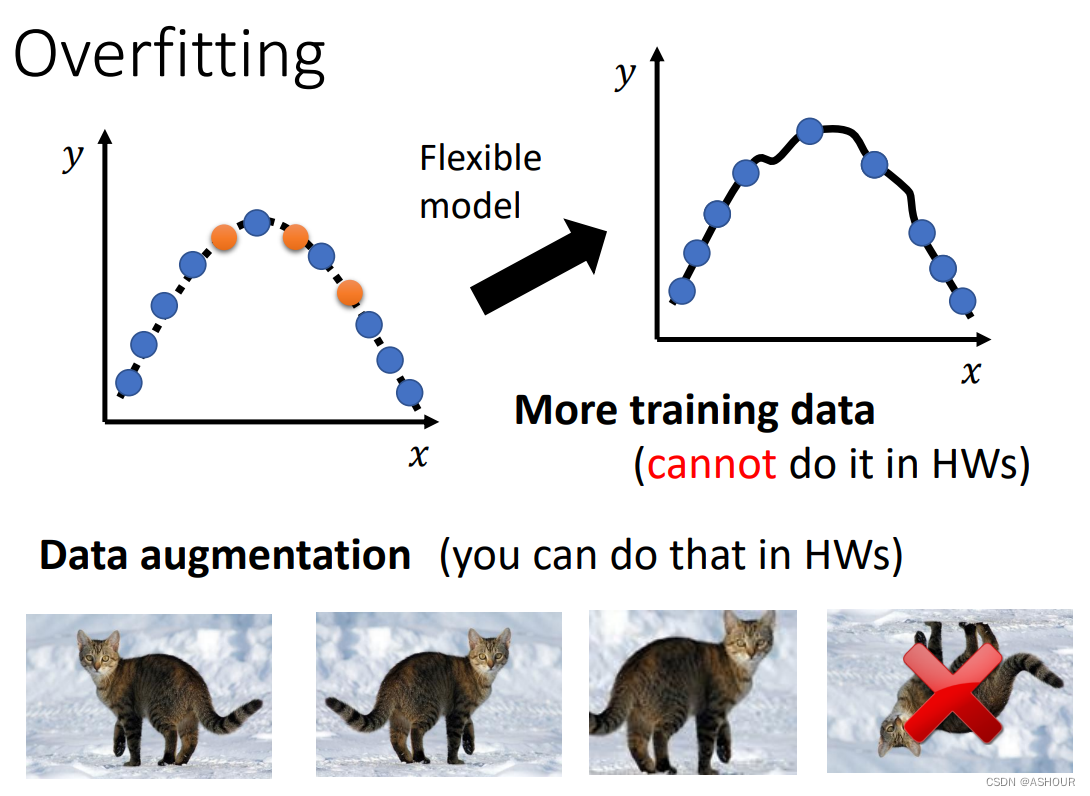 可以提供更多的训练数据,更多的训练数据意味着更多的限制,模型弹性变小也就不容易过拟合了
可以提供更多的训练数据,更多的训练数据意味着更多的限制,模型弹性变小也就不容易过拟合了
数据增强-Data augmentation:如图我们可以将一张图片作一下变化,例如镜像翻转,放到其中某部分,这不好影响我们识别的结果,但是提供更多的丰富的训练数据。
另外的常用的方法:

模型的弹性:
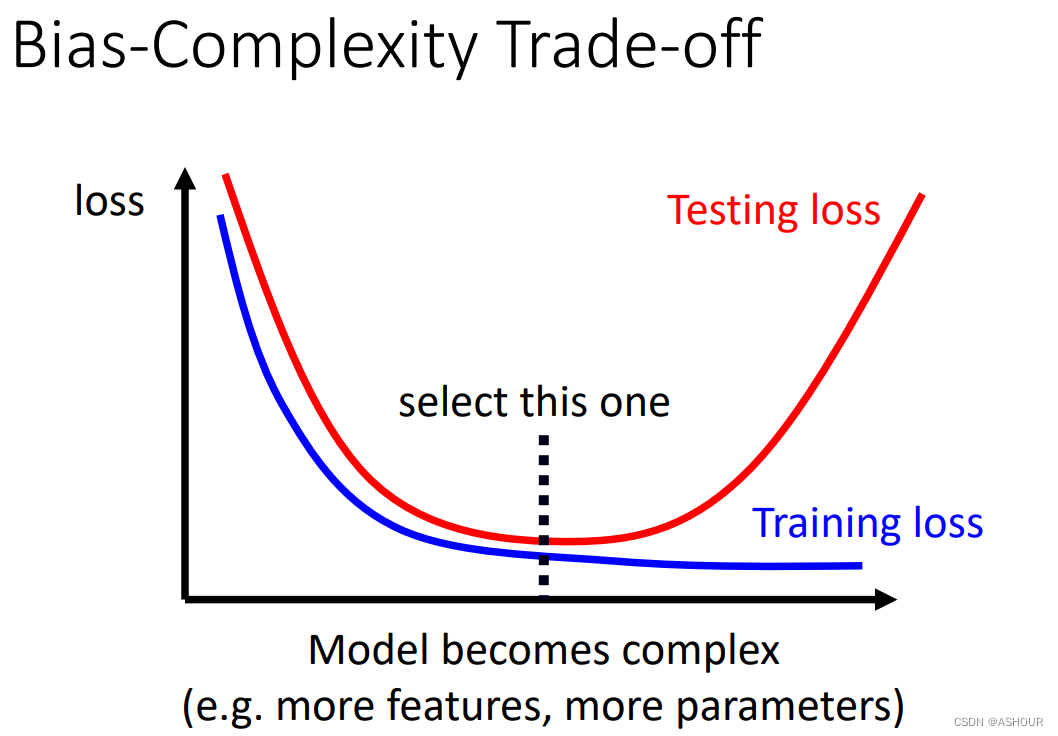 如图,一般来讲,随着模型复杂度的提升,模型在training data上的loss是会越来越小的,但是一旦模型过于复杂,就会发生overfitting的现象,而我们想要找到则是中间黑线的对应的模型。
如图,一般来讲,随着模型复杂度的提升,模型在training data上的loss是会越来越小的,但是一旦模型过于复杂,就会发生overfitting的现象,而我们想要找到则是中间黑线的对应的模型。
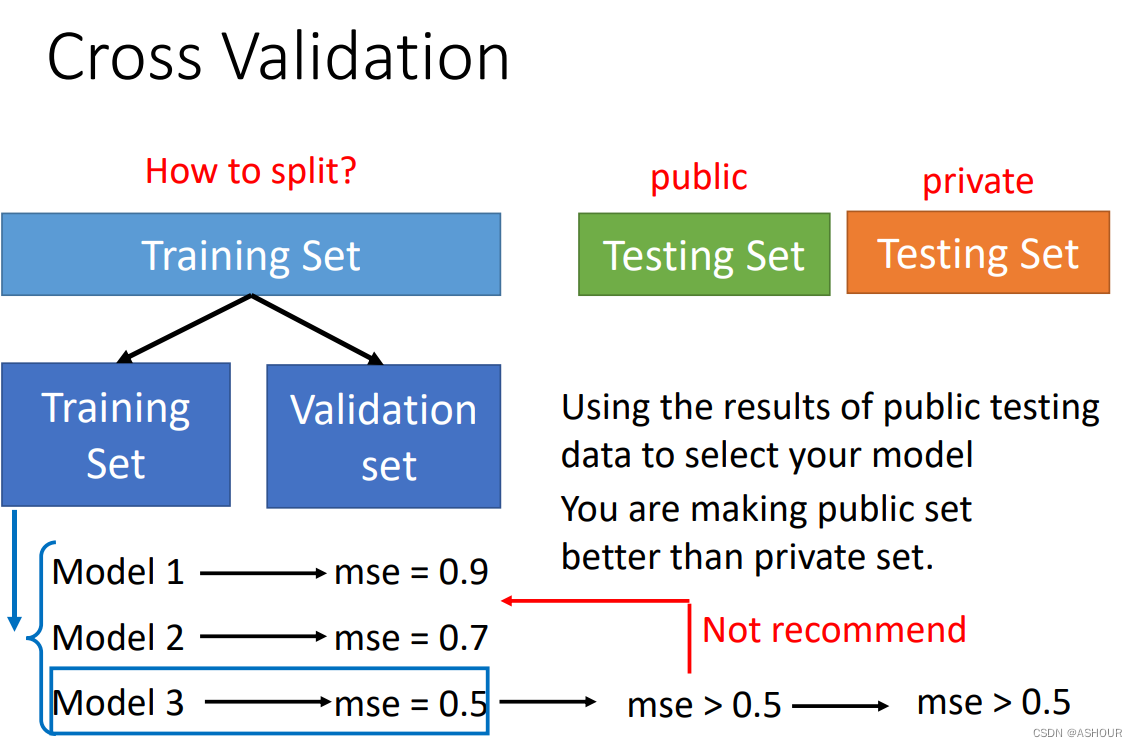
更重要的一环-交叉验证

交叉验证-提高model在private上的正确率:














 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









