







 超级会员免费看
超级会员免费看
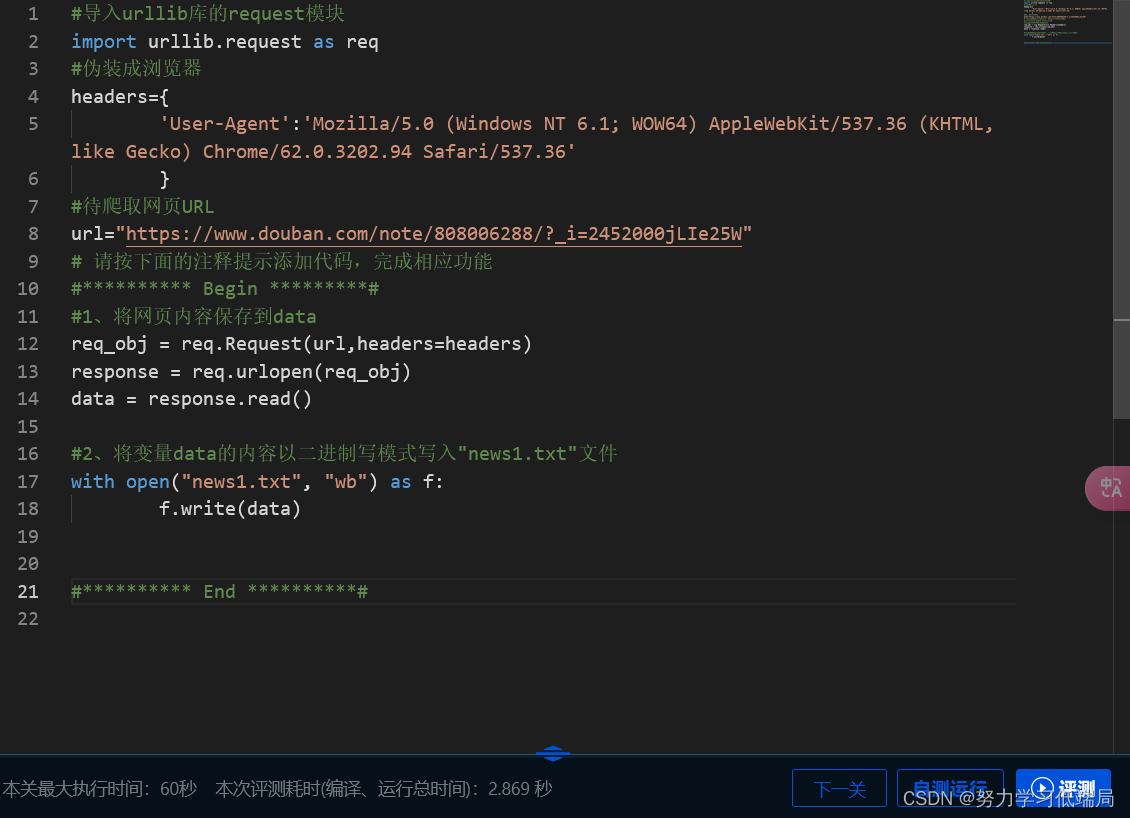
第1关:利用urllib库爬取网页内容
任务描述
本关任务:爬取指定网页内容,并将内容保存。
相关知识
为了完成本关任务,你需要掌握:1.urllib库。
第2关:利用bs4库提取网页内容
任务描述
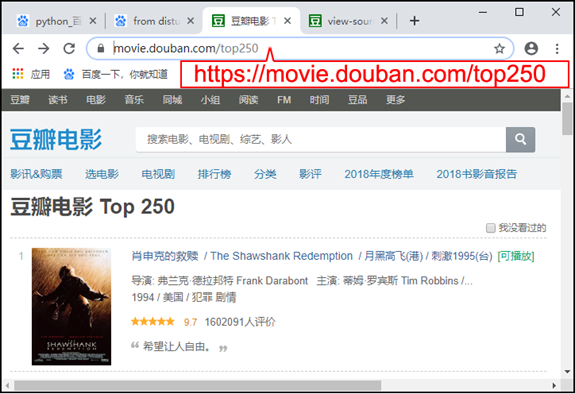
本关任务:爬取网页内容,并提取关键内容。 抓取豆瓣电影Top250网页,提取影片名、评分、链接三项数据,将数据保存到movie.csv文件中。 (1)爬取网址:豆瓣电影 Top 250
(2)源代码分析

(3)结果文件movie.csv工作表内容如下 :
本关任务:爬取指定网页内容,并将内容保存。
为了完成本关任务,你需要掌握:1.urllib库。
本关任务:爬取网页内容,并提取关键内容。 抓取豆瓣电影Top250网页,提取影片名、评分、链接三项数据,将数据保存到movie.csv文件中。 (1)爬取网址:豆瓣电影 Top 250
(2)源代码分析
(3)结果文件movie.csv工作表内容如下 :
 2994
1118
294
2994
1118
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文





















