






文章目录
项目要求
根据电商日志文件,分析:
1.统计页面浏览量(每行记录就是一次浏览)
2.统计各个省份的浏览量(需要解析IP)
3.日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。 本项目中需要解析出: ip、url、 pageld (topicld对应的页面ld)、 unovincecity
数据集

问题1统计页面浏览量
- WebLogPVMapper.java
处理Web日志数据,并计算每行日志的PV(页面浏览量)
package com.weblogpv;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WebLogPVMapper extends Mapper <LongWritable, Text, Text, IntWritable>>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//分割每一行内容,
context.write(new Text("line"), new IntWritable(1));
}
}
- WebLogPvReducer.java
处理经过Mapper阶段输出的中间数据,并计算每个省份的页面浏览量(PV),实现了对每个省份页面浏览量的累加计算
package com.weblogpv;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WebLogPvReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable outputValue = new IntWritable( );
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException, IOException {
//key :省份; value:<1,1,1,1>
int sum = 0;
for (IntWritable value:values) {
sum+= value.get();
}
outputValue.set( sum );
context.write( key,outputValue );
}
}
- WebLogPVMapReduce.java
用于配置和运行一个Hadoop MapReduce作业,目的是处理Web日志数据并计算页面浏览量(PV)
package com.weblogpv;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class WebLogPVMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//2、创建job
Job job = Job.getInstance( this.getConf(), "WebLogUVMapReduce" );
//设置job运行的主类
job.setJarByClass( WebLogPVMapReduce.class);
//设置Job
//a、input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("hdfs://hadoop102:8020/trackinfo/input/trackinfo.txt");
TextInputFormat.setInputPaths( job, inputPath);
//b、map
job.setMapperClass( WebLogPVMapper.class );
job.setMapOutputKeyClass( Text.class );
job.setMapOutputValueClass( IntWritable.class );
//c.partitioner
job.setNumReduceTasks(1);
//d、reduce
job.setReducerClass( WebLogPvReducer.class);
job.setOutputKeyClass( Text.class );
job.setOutputValueClass( IntWritable.class );
//e、output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("hdfs://hadoop102:8020/trackinfo/output");
//如果输出目录存在,先删除
FileSystem hdfs = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration());
if(hdfs.exists(outputPath)){
hdfs.delete( outputPath,true );
}
TextOutputFormat.setOutputPath( job,outputPath );
//第四步,提交job
boolean isSuccess = job.waitForCompletion( true );
return isSuccess?0:1 ;
}
public static void main(String[] args) {
Configuration configuration = new Configuration();
///public static int run(Configuration conf, Tool tool, String[] args)
try {
int status = ToolRunner.run( configuration,new WebLogPVMapReduce(),args );
System.exit( status );
} catch (Exception e) {
e.printStackTrace();
}
}
}
- Main方法
Hadoop MapReduce应用程序的main方法,负责启动和运行整个MapReduce作业
public static void main(String[] args) {
Configuration configuration = new Configuration();
///public static int run(Configuration conf, Tool tool, String[] args)
try {
int status = ToolRunner.run( configuration,new WebLogPVMapReduce(),args );
System.exit( status );
} catch (Exception e) {
e.printStackTrace();
}
}
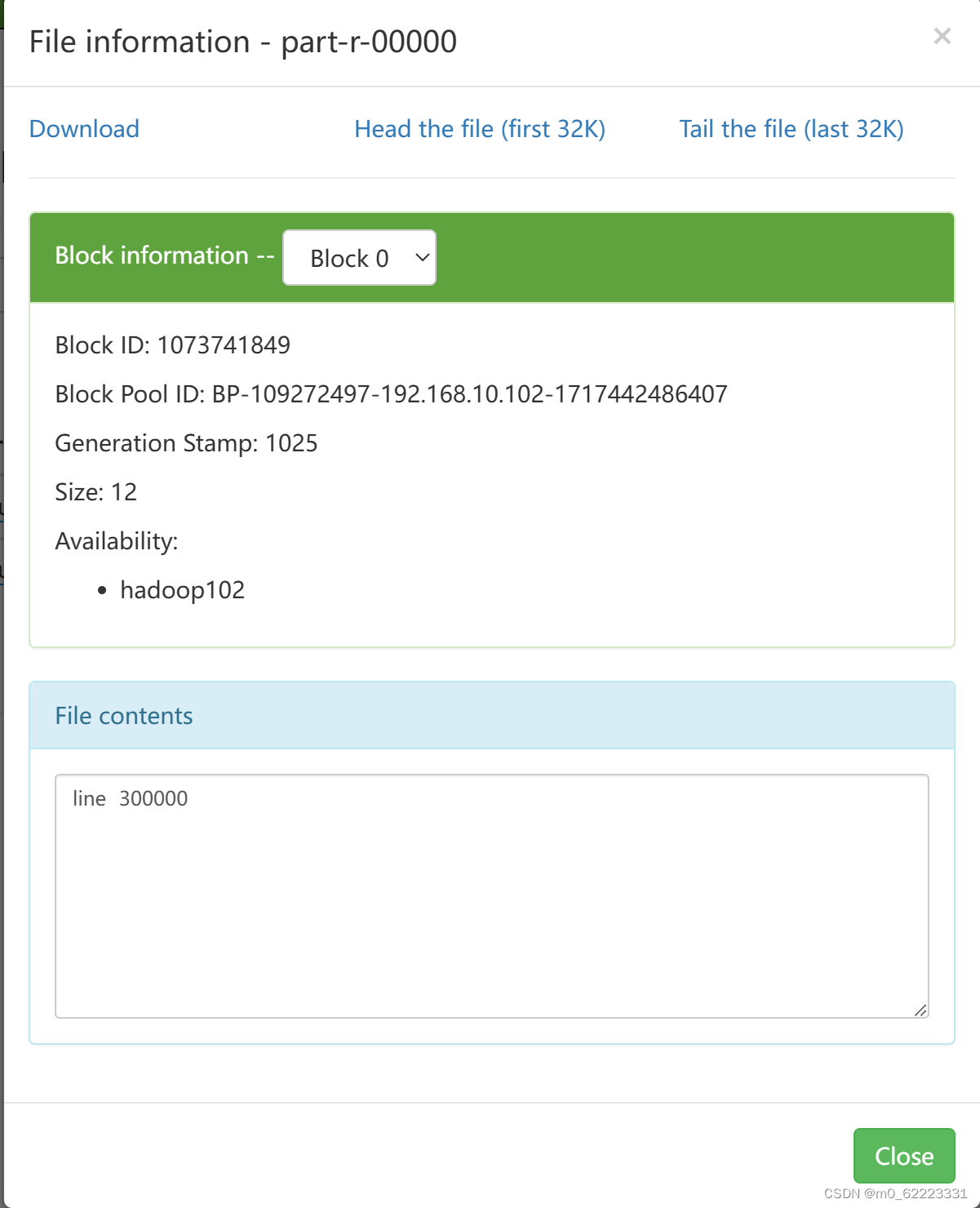
结果















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









