






本文章是为了简单阐述es的多字段属性 7.x
PUT test
{
"mappings": {
"properties": {
"mytest":{
"type": "keyword",
"fields": {
"namess":{
"type":"keyword",
"normalizer":"test_normalizer"
}
}
}
}
},
"settings": {
"analysis": {
"normalizer":{
"test_normalizer":{
"type":"custom",
"filter":[
"lowercase"
]
}
}
}
}
}
这个PUT请求创建了一个名为test的索引,其中包括一个字段mytest,它是一个keyword类型的字段,并且有一个多字段namess,也是keyword类型,但使用了test_normalizer进行规范化。下面是请求的详细解释:
-
索引名称: test
- 这个PUT请求是针对名为test的索引进行的。
-
映射(Mappings):
- properties: 定义索引中字段的结构。
- mytest: 主字段,类型为keyword,用于存储精确的、不分词的值。
- mytest.fields.namess: 多字段,类型同样为keyword,但有额外的处理。它使用了 test_normalizer进行规范化,以实现不区分大小写的比较和搜索。
-
设置(Settings):
- analysis: 定义索引的分析配置。
- normalizer: 包含自定义的规范化器。
- test_normalizer: 定义的规范化器,类型为custom,包含一个过滤器lowercase,它会将所有字符转换为小写。
- 这个配置允许你在搜索mytest.namess时进行大小写不敏感的匹配,而mytest字段则保持原始输入,不受规范化影响。这在需要对特定字段进行大小写敏感和不敏感的搜索时非常有用。
PUT test/_doc/1
{
"mytest":"apple"
}
PUT test/_doc/3
{
"mytest":"Apple"
}
插入数据

这是已有的数据,当查询
不进行区分大小写,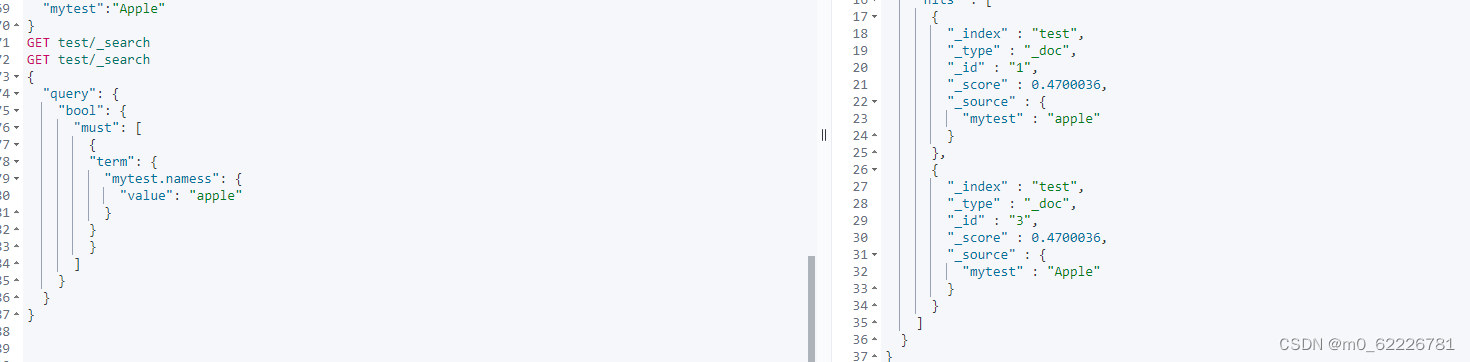
当进行子字段时,进行不区分大小写查询。
由于改变了mapping,所以需要重新reindex迁移数据,详情请看下篇文章
















 2318
2318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









