








1.Counting Sort 计数排序

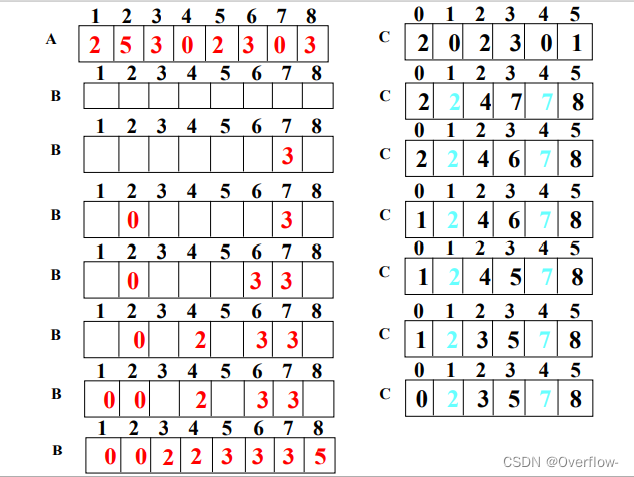
先完善C数组:首先将各个数字的计数填入数组,再根据前两项和等于第三项得出小于等于这个数的计数。最后put each A[i] for i=n to 1 into B[C[A[i]]] 也就是倒序将A中元素根据C中值放入B数组。

第二个for就是一个计数操作,线性扫描A数组,碰到一个数一次就给它在C上计数+1。
这里是倒叙将A中数根据计数放入B中的,如果想要正序放入,在更新C数组时在C数组每一位上的就得是小于这个数的计数。也就是再进行填B之前的C数组变成了0-2-2-4-7-7。此时我们发现0这个数没有位置放了,一开始的计数就是0,所以我们应该给每一位都加一变成1-3-3-5-8-8,再正序扫描A数组将A[i]根据C中计数填入B,A[i]填入以后C[A[i]]也应该减一。
O(n+k)的时间复杂度,在数据范围(k)太大的时候就别用啦

In-place Algorithm:
在计算机科学中,一个原地算法(in-place algorithm)是一种使用小的,固定数量的额外之空间来转换资料的算法。当算法执行时,输入的资料通常会被要输出的部份覆盖掉。不是原地算法有时候称为非原地(not-in-place)或不得其所(out-of-place)。
简单来说,就是在不新建大量额外空间(就是固定空间,无论数据多大,都不改变的那种)的基础上对原数据进行操作。
2.Radix Sort 根排序



看r和logn的相对大小决定是否适合使用拓展的根排序。
3.Bucket Sort 桶排序
适用条件:输入独立且均匀地分布在【0,1)上。
将[0,1)分成n个同等容量的小桶,将输入数据分配至n个小桶中,分别在各个小桶中对元素进行排序并存储。
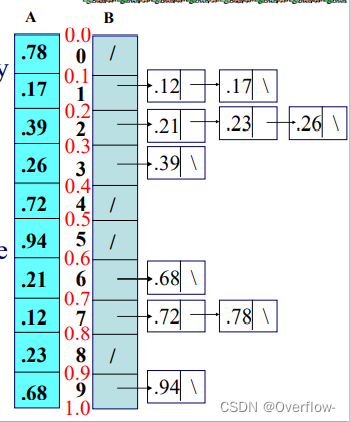

时间复杂度分析:
S2-S3的插入操作对每个元素都是θ(1)的,合起来是θ(n)。
S4-S5的for循环:对每一个桶都使用插入排序得到有序的list,插排最坏时间复杂度为O(n²),但是整个for循环却未必是O(n²),从概率上看一个数落在每个桶的概率是随机的,并且倾向于均匀分布在各个桶。设随机变量Xij:A[j]是否落在B[i]上;此事件为真Xij取1,otherwise取0.

















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









