






注意:仅供参考,为大家提供一点帮助,文中有很多可以优化的地方,鉴于个人精力,时间有限,写的项目能将就完成课程设计
gitee:SearchEngine: 互联网搜索引擎大作业 (gitee.com)
要求:
(一) 建立并实现文本搜索功能
◼ 利 用 / 调 用 开 源 搜 索 引 擎 Lucene(Apache Lucene - Welcome to Apache Lucene), ElasticSearch(Elasticsearch:官方分布式搜索和分析引擎 | Elastic) 或 者 Lemur(Lemur Project Home)实现文本搜索引擎。查阅相关资料,安装软件。
◼ 对经过预处理后的500个英文和中文文档/网页建立搜索并实现搜索功能。
◼ 通过上述软件对文档建立索引(Indexing),然后通过前台界面或者已提供的界 面,输入关键字,展示搜索结果。
◼ 前台可通过网页形式、应用程序形式、或者利用已有的界面工具显示。
◼ 实现英文搜索及中文搜索功能。
(二) 比较文档之间的相似度
◼ 通过余弦距离(Cosine Distance)计算任意两个文档之间的相似度,列出文档原文,并给出相似度值。
◼ 尝试实现一个文档查重程序。
(三) 对下载的文档,利用K-Means聚类算法进行聚类。
◼ 将下载的500个中文/英文文档聚为20个类,并显示聚类之后所形成的三个最大的类,及每个类中代表性的文档(即,离类中心最近的五个文档)。
◼ 将文档分别聚类成不同数量的类,如:5、10、25、50等,比较聚类结果的异同与变化。
◼ 距离计算公式,可采用余弦距离,也可用欧式距离。
一、建立并实现文本搜索功能
1.1.开发环境搭建
使用Elasticsearch实现全文内容检索
Elasticsearch是一个开源的搜索文献的引擎,大概含义就是你通过Rest请求告诉它关键字,他给你返回对应的内容,就这么简单。
Elasticsearch封装了Lucene,Lucene是apache软件基金会一个开放源代码的全文检索引擎工具包。Lucene的调用比较复杂,所以Elasticsearch就再次封装了一层,并且提供了分布式存储等一些比较高级的功能。
基于Elasticsearch有很多的插件,我这次用到的主要有两个,一个是kibana,一个是Elasticsearch-head。
1.1.1.软件下载及配置
-
安装
Elasticsearch版本为7.17.3
【网址】Past Releases of Elastic Stack Software | Elastic
-
使用内置的jdk,配置环境变量ES_JAVA_HOME
![]()
-
进入
config目录--->打开elasticsearch.yml文件(虚拟机访问就必须要修改,主机可以不用修改)

-
windows下启动Elasticsearch服务,直接运行bin目录下的Elasticsearch.bat文件
-
判断ES是否启动成功,直接访问 http://localhost:9200/

-
安装kibana(7.17.3)
【kibana】Past Releases of Elastic Stack Software | Elastic
-
运行bin目录下的kibana.bat文件
-
【访问网址】http://localhost:5601/
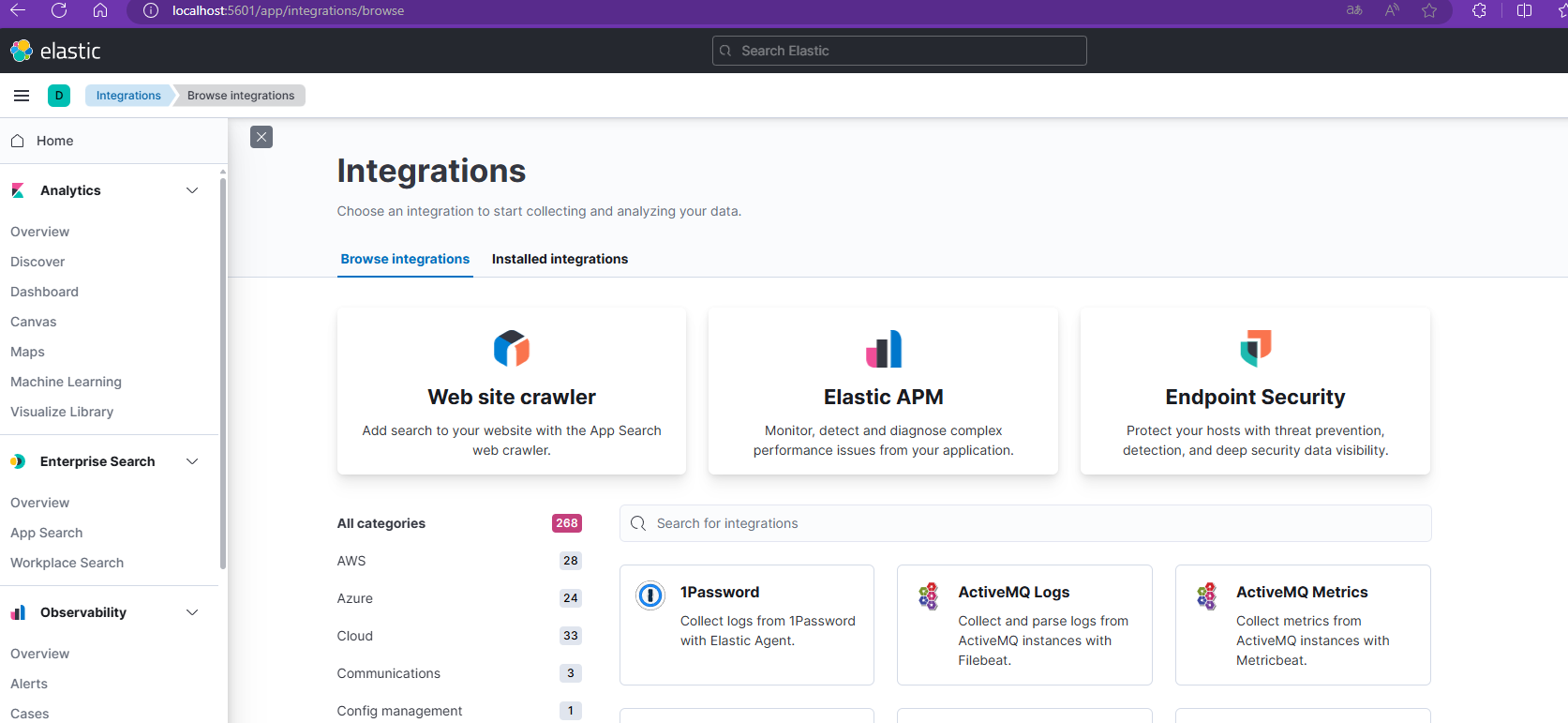

1.2.在Python中与Elasticsearch进行交互
-
在Python中与Elasticsearch进行交互,需要安装Elasticsearch-py
pip install elasticsearch
-
编写python代码:
-
main.py处理英文文档
from elasticsearch import Elasticsearch import os import json from datetime import datetime # 创建 Elasticsearch 客户端实例 es = Elasticsearch([{'host': 'localhost', 'port': 9200, 'scheme': 'http'}]) # 创建索引 def create_index(index_name): index_mapping = { "mappings": { "properties": { "title": {"type": "keyword"}, "contents": {"type": "text"}, "indexdate": {"type": "date"} } } } es.indices.create(index=index_name, body=index_mapping) # 导入数据 def index_documents(index_name, folder_path): for filename in os.listdir(folder_path): if filename.endswith(".txt"): with open(os.path.join(folder_path, filename), "r", encoding="utf-8") as file: document = { "title": filename, "contents": file.read(), "indexdate": datetime.now() } es.index(index=index_name, body=document) # 主函数 def main(): index_name = "novels_index" # 指定索引名称 # 获取当前脚本文件所在的目录路径 current_dir = os.path.dirname(os.path.abspath(__file__)) # 构建小说数据文件夹的相对路径 folder_path = os.path.join(current_dir, "..", "English_Process", "pro_e") # 创建索引 create_index(index_name) # 导入数据 index_documents(index_name, folder_path) if __name__ == "__main__": main() -
main_C.py处理中文文档
from elasticsearch import Elasticsearch import os from datetime import datetime # 创建 Elasticsearch 客户端实例 es = Elasticsearch([{'host': 'localhost', 'port': 9200, 'scheme': 'http'}]) # 删除索引 def delete_index(index_name): if es.indices.exists(index=index_name): es.indices.delete(index=index_name) print(f"索引 '{index_name}' 删除成功。") else: print(f"索引 '{index_name}' 不存在。") # 创建索引 def create_index(index_name): index_mapping = { "mappings": { "properties": { "title": {"type": "keyword"}, "contents": {"type": "text"}, "indexdate": {"type": "date"} } } } es.indices.create(index=index_name, body=index_mapping) print(f"索引 '{index_name}' 创建成功。") # 导入数据 def index_documents(index_name, folder_path): for filename in os.listdir(folder_path): if filename.endswith(".txt"): with open(os.path.join(folder_path, filename), "r", encoding="utf-8") as file: document = { "title": filename, "contents": file.read(), "indexdate": datetime.now() } es.index(index=index_name, body=document) print("数据导入完成。") # 主函数 def main(): index_name = "novels_index_c" # 指定索引名称 # 获取当前脚本文件所在的目录路径 current_dir = os.path.dirname(os.path.abspath(__file__)) # 构建小说数据文件夹的相对路径 folder_path = os.path.join(current_dir, "..", "Chinese_Process", "temp") # 删除现有索引 delete_index(index_name) # 创建索引 create_index(index_name) # 导入数据 index_documents(index_name, folder_path) if __name__ == "__main__": main() -
1.3.在kibana中建立索引库
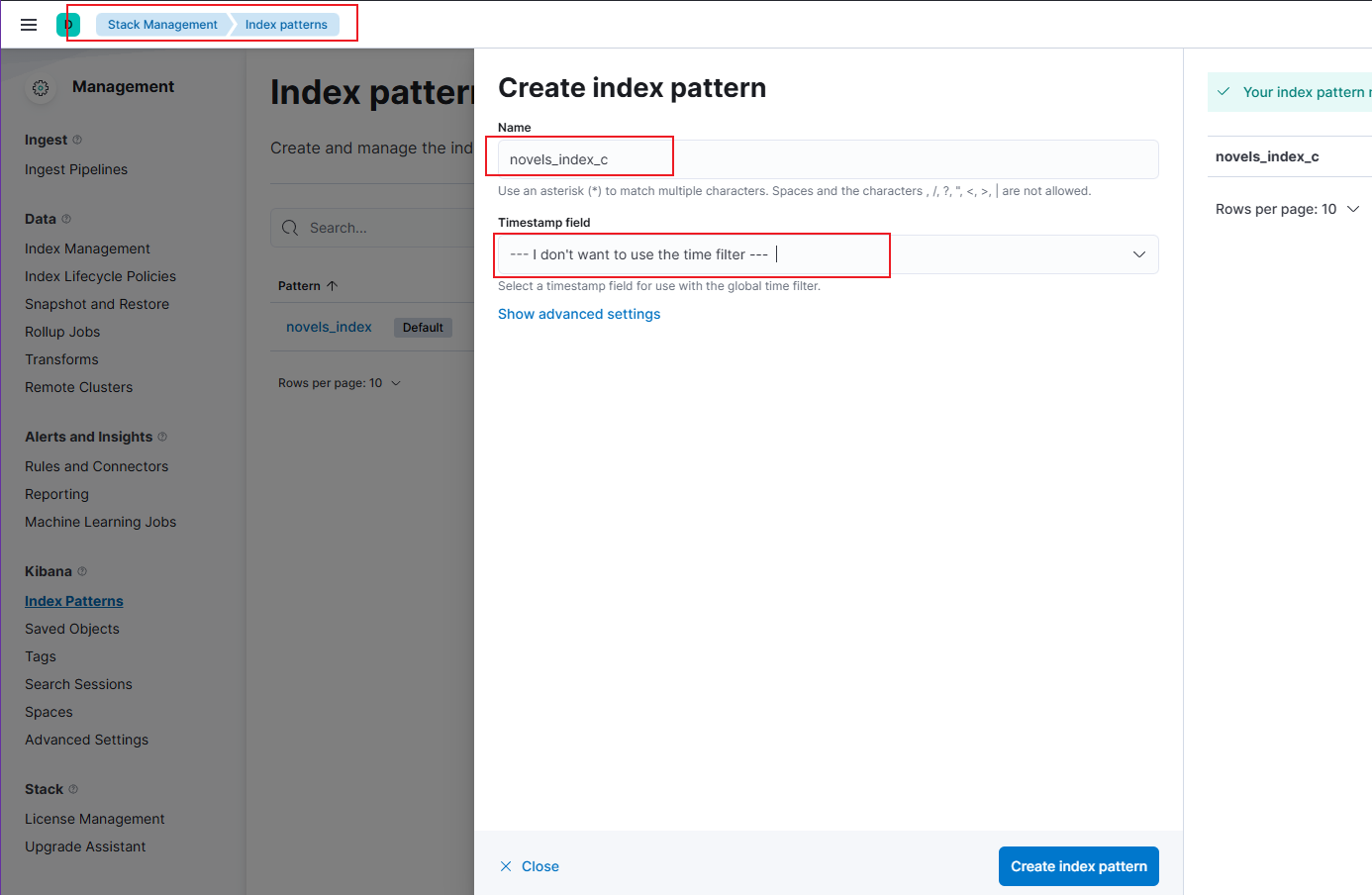
-
如图建立两个对应的索引库,novels_index是英文文档对应的索引库,novels_index_c是中文文档对应的索引库
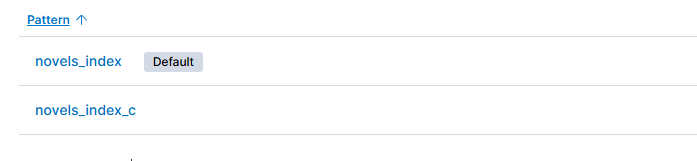
-
英文文档和中文文档各有500个

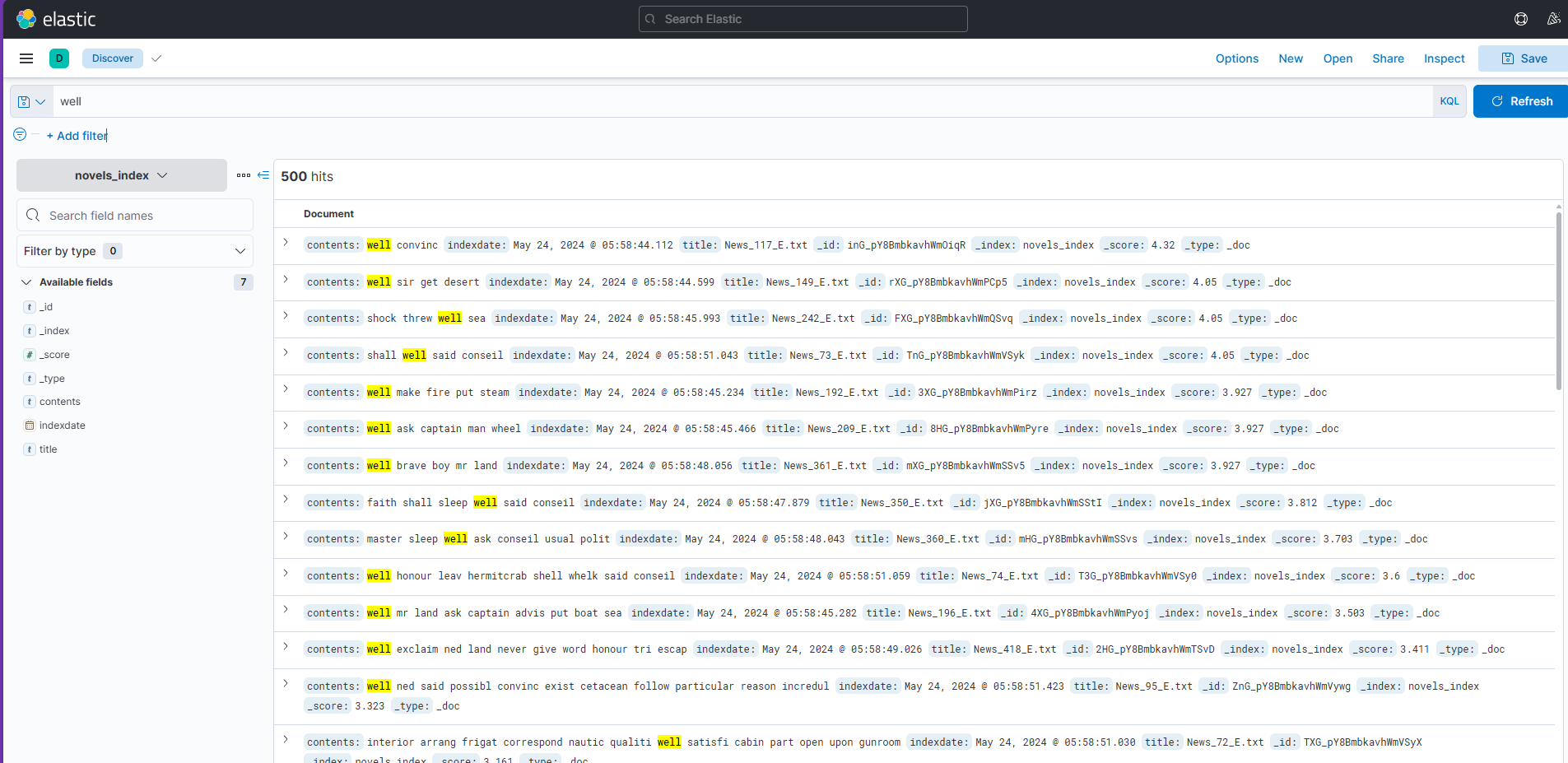
1.4.搜索结果展示
1.4.1.英文搜索结果
1.4.2.中文搜索结果
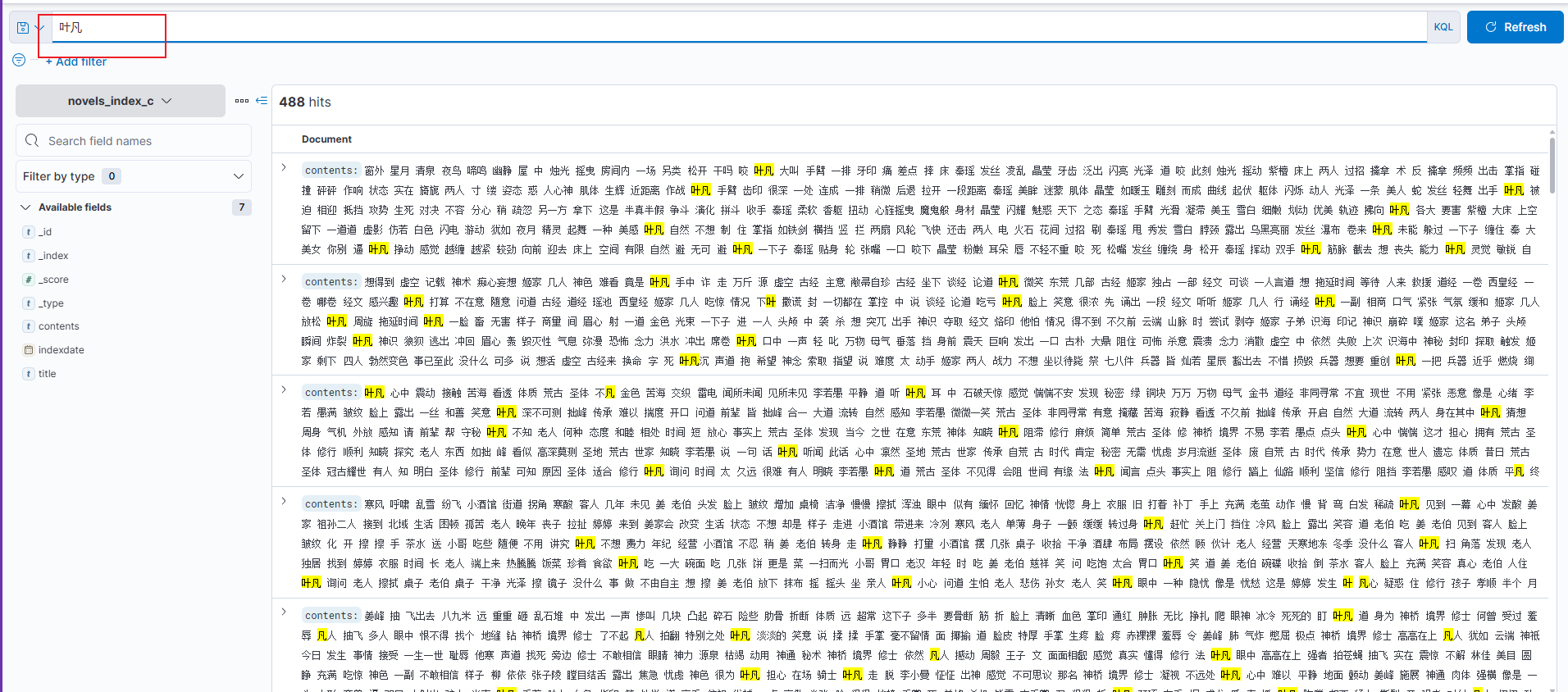
二、比较文档之间的相似度
2.1.通过余弦距离(Cosine Distance)计算任意两个文档之间的相似度,列出文档原文,并给出相似度值。
2.1.1.数据说明
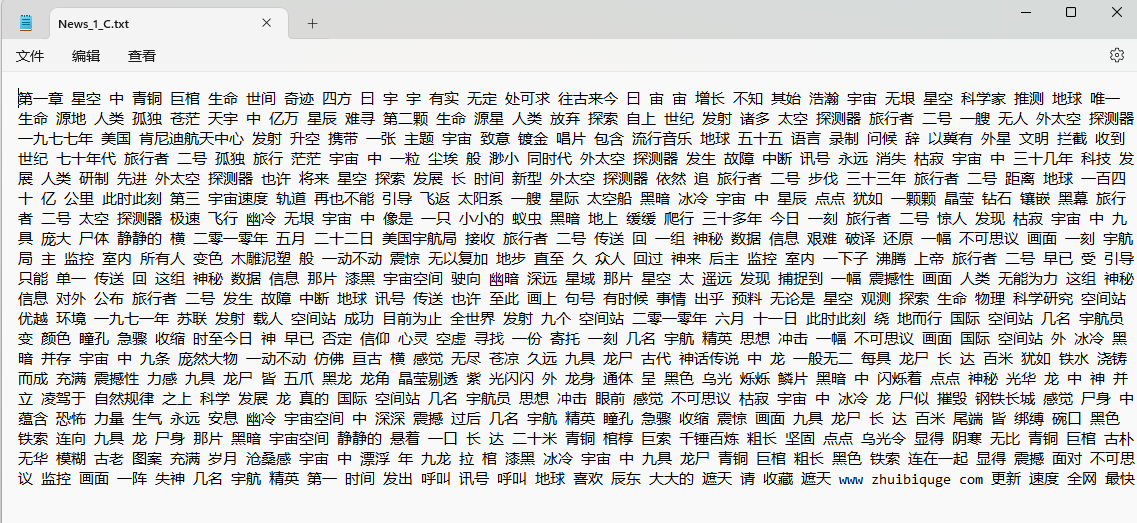
在进行正式的操作之前,我想对后续进行处理的数据进行说明,首先,我在某小说网上爬取了一篇小说的500个网页,然后进行了中文分词(jieba)和删除停用词操作,最后处理的结果展示如下如所示:
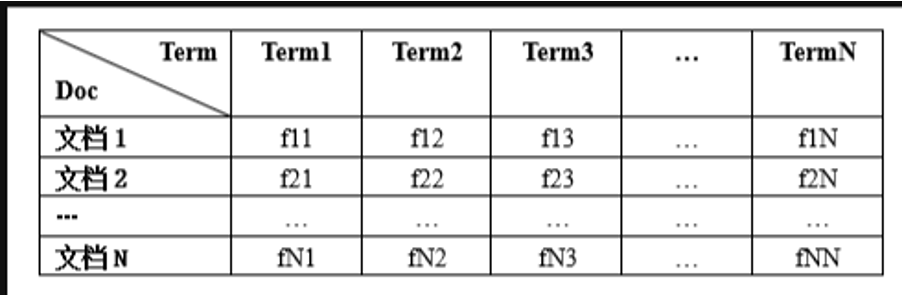
2.1.2.根据文档建立词频矩阵
2.1.2.1.什么是词频?
词频指某个词(term)在文章中出现次数,若某个词(不包括停用词)在文章中出现的频率很高,则说明这个词可能比较重要。
2.1.2.2.sklearn中的CountVectorizer类
对于词频矩阵的建立,这里直接调用sklearn库中的CountVectorizer类,通过该类的方法fit_transform()可以获取一个词频矩阵,其中每一行代表一个文档,每一列代表词在该文档中出现的频率,词频矩阵的结构如下图所示:
2.1.3.根据词频矩阵求tf-idf矩阵
2.1.3.1.tf-idf简介
idf的全称为inverse document frequency,即反向文档频率,它的含义是包含某个词的文档数,其计算公式为:
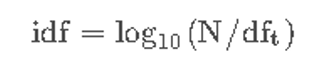
其中N 为文档总数,df_t 为所有文档中包含词汇t的文档数。
2.1.3.2.sklearn中的TfidfTransformer类
要想求得包含文档中对应词的tf-idf值的tf-idf矩阵,可以使TfidfTransformer类,通过该类的fit_transform()方法可以获取对应的tf-idf矩阵,其结构如下图所示:
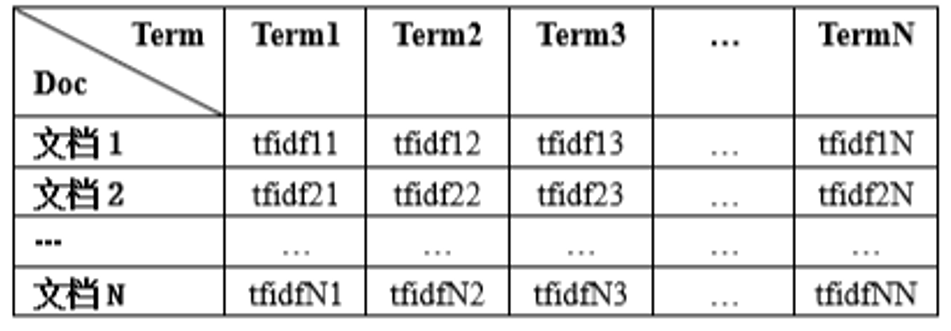
2.1.4.L2归一化
2.1.4.1.计算公式
设一个向量( x 1 , x 2 , x 3 , . . . , x N ) (x_1,x_2,x_3,...,x_N)(x 1,x2,x3,...,xN),其归一化后的向量为( y 1 , y 2 , y 3 , . . . , y N )
则归一化的公式为:
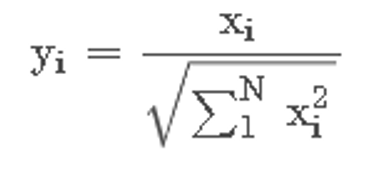
2.1.5.求余弦距离
2.1.5.1计算公式
由于上述的tfidf矩阵进行了L2归一化,因此求两个文档的余弦距离的公式为:
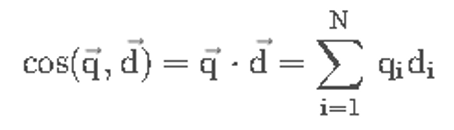
经过计算后的余弦距离矩阵结构如下:

2.1.2具体实现:
2.1.2.1英文文档实现
-
python代码
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 获取当前脚本文件所在的目录路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 构建小说数据文件夹的相对路径
folder_path = os.path.join(current_dir, "..", "English_Process", "pro_e")
# 获取文件夹中的所有文件
file_list = os.listdir(folder_path)
# 存储文档内容的字典,键为文件名,值为内容
documents = {}
# 读取文档内容并存储到字典中
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
documents[file_name] = content
# 将文档内容转换为列表
content_list = list(documents.values())
# 创建一个TfidfVectorizer对象并拟合整个文档集合
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(content_list)
# 计算相似度
for i, doc1 in enumerate(file_list):
for j, doc2 in enumerate(file_list):
if j > i: # 避免重复计算相似度
# 输出文件名
print("Document 1:", doc1)
print("Document 2:", doc2)
# 获取对应的TF-IDF特征向量并计算余弦相似度
tfidf_vector1 = tfidf_matrix[i]
tfidf_vector2 = tfidf_matrix[j]
cosine_sim = cosine_similarity(tfidf_vector1, tfidf_vector2)[0][0]
# 输出相似度
print("Similarity Score:", cosine_sim)
print()
# 输出文档内容
print("Content of", doc1, ":", documents[doc1][:100]) # 输出部分内容
print("Content of", doc2, ":", documents[doc2][:100]) # 输出部分内容
print()
-
比对任意文档相似度(文档内容只展示部分):

-
文档121和402对比:
相似度为0.027750074665011625

-
文档121和390对比:
相似度为0.06336882280846401

-
文档121和393对比:
相似度为0.06021977230979611
2.1.2.1中文文档实现
-
python代码
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 获取当前脚本文件所在的目录路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 构建小说数据文件夹的相对路径
folder_path = os.path.join(current_dir, "..", "Chinese_Process", "temp")
# 获取文件夹中的所有文件
file_list = os.listdir(folder_path)
# 存储文档内容的字典,键为文件名,值为内容
documents = {}
# 读取文档内容并存储到字典中
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
documents[file_name] = content
# 将文档内容转换为列表
content_list = list(documents.values())
# 创建一个TfidfVectorizer对象并拟合整个文档集合
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(content_list)
# 计算相似度
for i, doc1 in enumerate(file_list):
for j, doc2 in enumerate(file_list):
if j > i: # 避免重复计算相似度
# 输出文件名
print("Document 1:", doc1)
print("Document 2:", doc2)
# 获取对应的TF-IDF特征向量并计算余弦相似度
tfidf_vector1 = tfidf_matrix[i]
tfidf_vector2 = tfidf_matrix[j]
cosine_sim = cosine_similarity(tfidf_vector1, tfidf_vector2)[0][0]
# 输出相似度
print("Similarity Score:", cosine_sim)
print()
# 输出文档内容
print("Content of", doc1, ":", documents[doc1][:100]) # 输出部分内容
print("Content of", doc2, ":", documents[doc2][:100]) # 输出部分内容
print()
-
比对任意文档相似度(文档内容只展示部分):

-
文档105和348对比:
相似度为0.02340114312833783

-
文档105和340对比:
相似度为0.043146515194696596

-
文档101和20对比:
相似度为0.021055687535140852
2.2.尝试实现一个文档查重程序
文档查重是一种通过比较文本内容的相似性来确定是否存在抄袭或重复内容的方法。我们已经对需要进行查重的文档进行预处理了,并从预处理后的文本中提取特征向量并进行了相似度计算,我们可以根据与现有的文档比对得到的文档相似度的最大值来判断查重率。
2.2.1.python代码(中文文档只需要修改文件路径即可)
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 获取当前脚本文件所在的目录路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 构建小说数据文件夹的相对路径
folder_path = os.path.join(current_dir, "..", "English_Process", "pro_e")
# 获取文件夹中的所有文件
file_list = os.listdir(folder_path)
# 存储文档内容的字典,键为文件名,值为内容
documents = {}
# 读取文档内容并存储到字典中
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
documents[file_name] = content
# 输入文件名
input_file_name = input("请输入文件名:")
# 检查输入文件是否存在
if input_file_name not in documents:
print("输入文件不存在!")
exit()
# 获取输入文件的内容
input_document_content = documents[input_file_name]
# 将文档内容转换为列表
content_list = list(documents.values())
# 创建一个TfidfVectorizer对象并拟合整个文档集合
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(content_list)
# 存储相似度的列表
similarities = []
# 计算输入文件与其他文件的相似度
input_file_index = file_list.index(input_file_name)
input_tfidf_vector = tfidf_matrix[input_file_index]
for i, tfidf_vector in enumerate(tfidf_matrix):
if i != input_file_index: # 避免与自身比较
cosine_sim = cosine_similarity(input_tfidf_vector, tfidf_vector)[0][0]
similarities.append((cosine_sim, file_list[i]))
# 找到最大相似度的文件
max_similarity, max_similarity_file = max(similarities)
# 输出最大相似度
print("最大相似度:", max_similarity)
# 输出输入文件内容
print("\n输入文件内容({}):".format(input_file_name))
print(input_document_content[:1000]) # 输出部分内容
# 输出最大相似度文件的内容
print("\n最大相似度文件({})的内容:".format(max_similarity_file))
max_similarity_file_content = documents[max_similarity_file]
print(max_similarity_file_content[:1000]) # 输出部分内容
2.2.2.测试:
1.(英文)输入:News_1_E.txt
输出:

最大重复率文档为39号文件,查重率为15%。
-
(中文)输入:News_2_C.txt
输出:

故能找到的最大重复率文档为4号文件,查重率为27%
-
(中文)输入:News_200_C.txt
输出:

故能找到的最大重复率文档为201号文件,查重率为23%
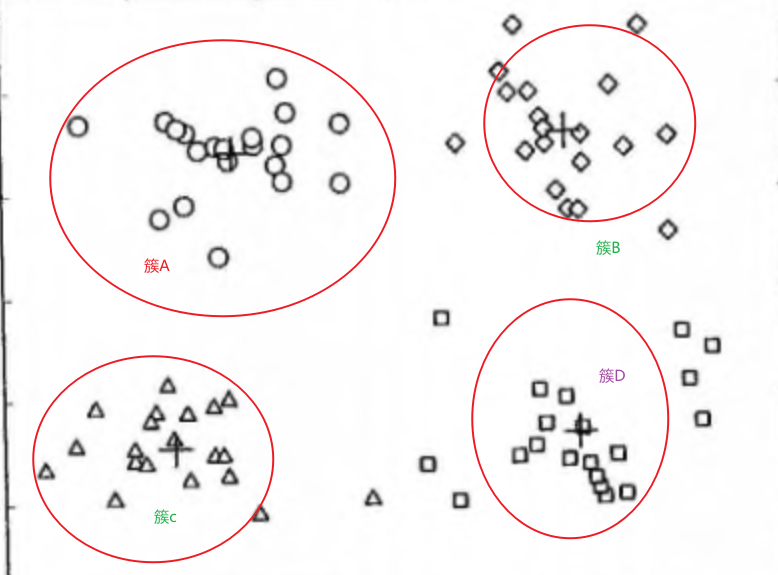
三、对下载的文档,利用K-Means聚类算法进行聚类。
3.1.K-Means算法原理:
教你学Python34-K-Means(K-均值)聚类算法-CSDN博客
K-Means算法的基本原理是:通过迭代的方式,将数据点划分到最接近的类簇中心点所代表的类簇中,然后根据每个类簇内的所有点重新计算该类簇的中心点(取平均值),再不断重复此过程,直至类簇中心点的变化很小或达到指定的迭代次数。
聚类数目(K)的选择: K-Means算法的第一步是确定要将数据划分成多少个簇。这个选择通常基于领域知识或使用Elbow方法等统计技巧来确定。K的选择对于聚类结果有着重要的影响。如果K选择过小,可能会导致簇的划分不够细致,无法准确地反映数据的结构;如果K选择过大,可能会导致簇的划分过于细致,会被数据的噪声影响,导致分类不准确。
距离的度量: K-Means使用欧式距离(Euclidean distance)来度量数据点之间的相似性,但也可以根据具体问题选择其他距离度量方法。
质心: 每个簇都有一个质心,它是该簇内所有数据点的均值。质心代表了簇的中心位置。
优化目标: K-Means的优化目标是最小化每个数据点到其所属簇质心的距离之和。
3.2.算法实现
1.使用TF-IDF向量化文档,然后将其输入到聚类算法中。
2.运行聚类算法,并将文档聚类成不同数量的类。
3.对每个聚类进行分析,找出每个类的代表性文档。
4.比较不同聚类数量下的聚类结果。
py thon代码实现
import os
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import cosine_distances
from collections import defaultdict
# 定义函数用于加载文档
def load_documents(folder_path):
documents = {}
file_list = os.listdir(folder_path)
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
documents[file_name] = content
return documents
# 定义函数用于进行聚类
def perform_clustering(documents, num_clusters):
# TF-IDF向量化
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(list(documents.values()))
# 使用K均值聚类
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(tfidf_matrix)
# 返回文档所属的聚类和TF-IDF矩阵
return kmeans.labels_, tfidf_matrix
# 定义函数用于找出每个类的代表性文档
def find_representative_documents(documents, cluster_labels, tfidf_matrix, num_representatives=5):
cluster_centers = defaultdict(list)
for idx, label in enumerate(cluster_labels):
cluster_centers[label].append(idx)
representative_documents = {}
for cluster, members in cluster_centers.items():
centroid = np.mean(tfidf_matrix[members].toarray(), axis=0)
distances = cosine_distances([centroid], tfidf_matrix[members])
closest_indices = np.argsort(distances[0])[:num_representatives]
representative_documents[cluster] = [list(documents.keys())[members[i]] for i in closest_indices]
return representative_documents
# 定义函数用于输出结果
def print_results(representative_documents):
for cluster, docs in representative_documents.items():
print(f"类别 {cluster + 1} 中的代表性文档:")
for doc in docs:
print(doc)
print()
# 获取当前脚本文件所在的目录路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 加载英文文档
english_folder_path = os.path.join(current_dir, "..", "English_Process", "pro_e")
english_documents = load_documents(english_folder_path)
# 加载中文文档
chinese_folder_path = os.path.join(current_dir, "..", "Chinese_Process", "temp")
chinese_documents = load_documents(chinese_folder_path)
# 尝试不同的聚类数量
for num_clusters in [5, 10, 25, 50]:
print(f"聚类数量:{num_clusters}")
# 进行英文文档聚类
english_cluster_labels, english_tfidf_matrix = perform_clustering(english_documents, num_clusters)
english_representative_documents = find_representative_documents(english_documents, english_cluster_labels,
english_tfidf_matrix)
# 输出英文文档聚类结果
print("英文文档聚类结果:")
print_results(english_representative_documents)
# 进行中文文档聚类
chinese_cluster_labels, chinese_tfidf_matrix = perform_clustering(chinese_documents, num_clusters)
chinese_representative_documents = find_representative_documents(chinese_documents, chinese_cluster_labels,
chinese_tfidf_matrix)
# 输出中文文档聚类结果
print("中文文档聚类结果:")
print_results(chinese_representative_documents)
3.3.测试
聚类数量为5:
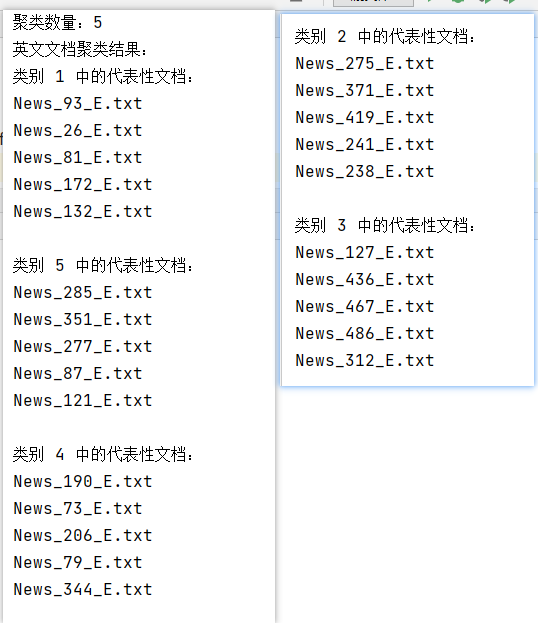
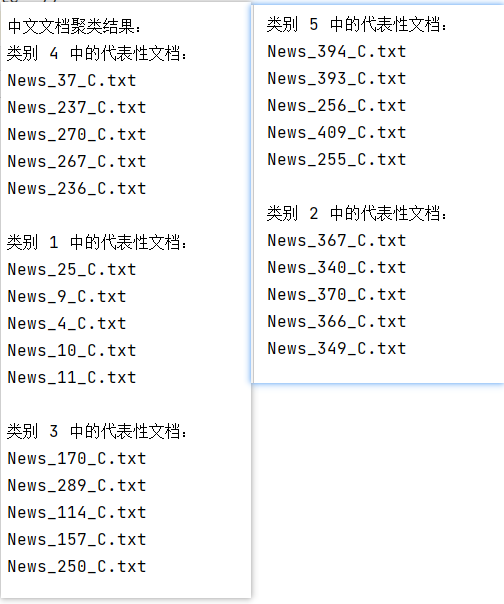
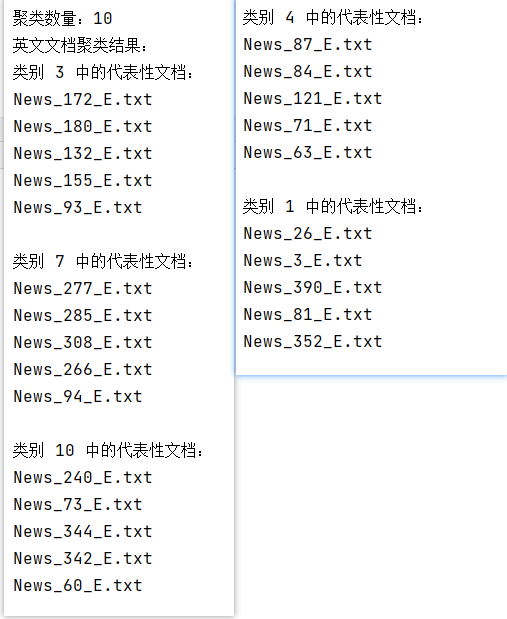
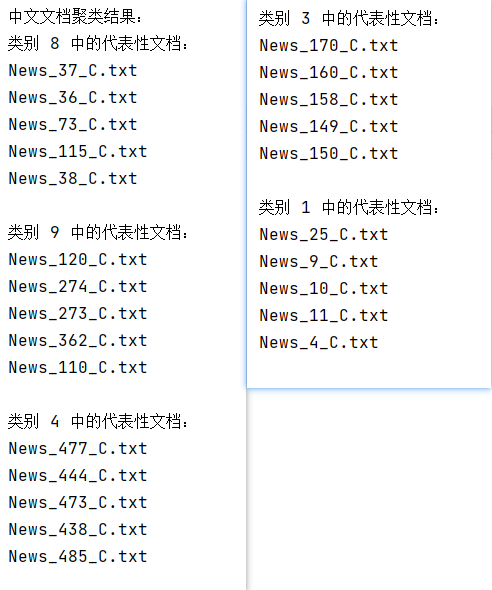
聚类数量为10:
聚类数量为25:
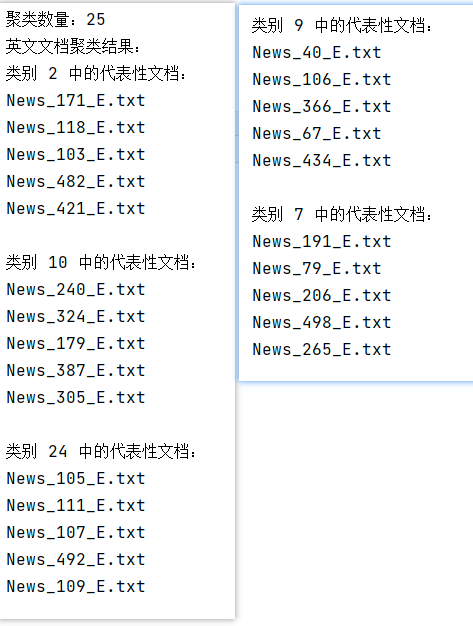
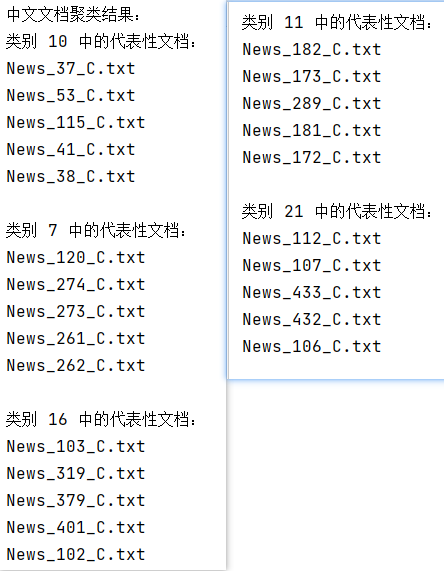
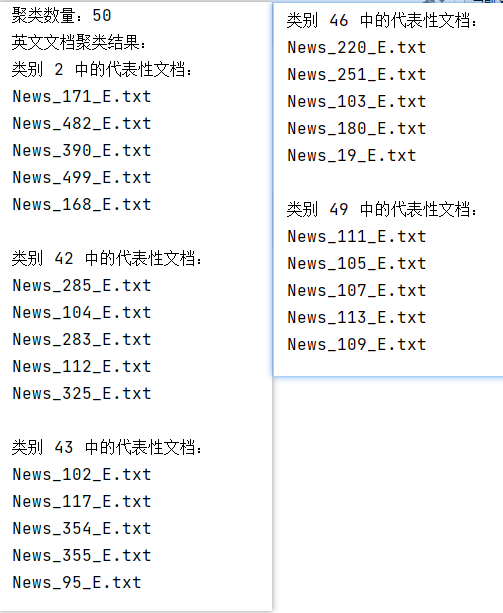
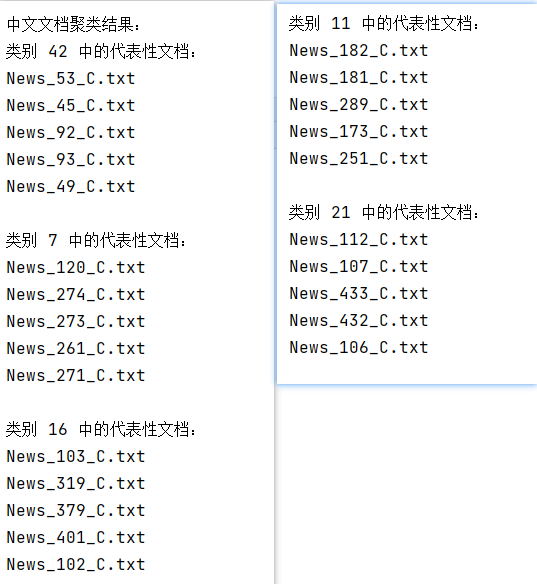
聚类数量为50:
四、总结
通过本次学习,我深入理解并掌握了文本搜索引擎的构建、文档相似度计算以及文档聚类分析的相关技术和方法,以下是我对学习内容的总结和思考:
首先,通过ElasticSearch,我实现了高效的中英文文档搜索功能。其次,掌握了余弦相似度的计算方法,并成功应用于文档查重。然后,通过K-Means算法,将文档进行聚类,并分析了不同K值对聚类结果的影响。这些学习不仅提升了我的技术能力,还为后续的文本数据处理和分析工作打下了坚实的基础,通过不断实践和优化,将能够进一步提高文档处理和分析的效率和准确性。
学习文档相似度的背景是为了应对抄袭、重复内容等问题。文档相似度可以帮助我们识别和比较不同文档之间的相似性,从而提供更准确的信息并保护原创性。在文档相似度计算中,预处理是一个关键步骤,通过去除特殊字符、标点符号、停用词以及词干化等方法,可以减少噪音和提高计算效率。特征提取则是将文本表示为特征向量的过程,常用的方法有词袋模型和TF-IDF等。这些处理能够将文本转化为机器学习算法可以处理的数值表示。
在文档相似度计算中,常见的相似度度量方法有余弦相似度和Jaccard相似度等。余弦相似度可以度量两个向量的夹角,从而反映其相似性,而Jaccard相似度则可以衡量两个集合的相似性。选择合适的相似度度量方法对于准确度的提高非常重要。在实现文档相似度计算的过程中,我们需要进行适当的调参和优化。例如,选择合适的聚类数目K和设置相似度阈值等参数都会影响结果的准确性。此外,还可以考虑使用更复杂的特征提取方法、深度学习模型或优化相似度计算的性能等。
学习只是第一步,实践和改进是更重要的后续步骤。通过在实际应用中尝试不同的数据集和参数设置,我们可以进一步了解文档相似度算法的表现和局限性,并通过不断的改进和优化来提高算法的准确性和效率。















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









