







学了一学期,发现我连最基本的一些过程都说不上来,最近在调试结课作业,为了能顺利的将整个过程讲解下来,这里总结一下简单实现。
一、卷积网络
1、卷积层
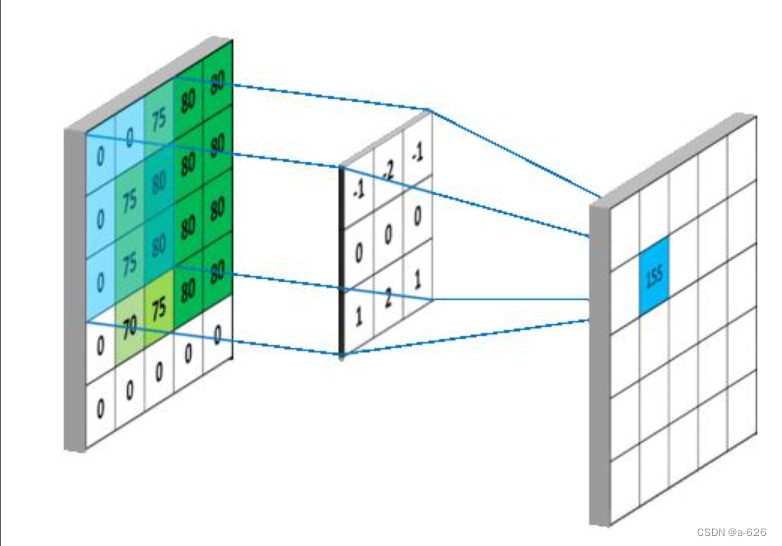
卷积层是卷积神经网络(CNN)中的核心组件之一,用于提取输入数据中的特征并创建特征映射。在卷积层中,会定义多个卷积核(也称为滤波器),每个卷积核都会在输入数据上进行滑动并执行卷积操作,从而生成输出特征图。
具体来说,卷积操作可以有效地捕获输入数据中的局部模式和特征,因为卷积核的参数共享机制可以减少模型的参数数量并提高特征提取的效率。此外,卷积操作还可以保留空间结构信息,有助于对图像、文本等数据进行处理。
卷积层通常涉及一些重要的超参数,如卷积核的大小、步长(stride)、填充(padding)等,这些超参数会影响着卷积操作的输出尺寸以及特征提取的效果。
卷积过程实质上就是两个矩阵做乘法,在卷积过程后,原始输入矩阵会有一定程度的缩小,比如自定义卷积核大小为3*3,步长为1时,矩阵长宽会缩小2,所以在一些应用场合下,为了保持输入矩阵的大小,我们在卷积操作前需要对数据进行扩充,常见的扩充方法为0填充方式,即设置padding的值。
例如:
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)这里面的参数用于创建一个二维卷积层的,下面是各个参数的详细介绍:
in_channels:输入的通道数,对于灰度图像来说,通道数为1;对于RGB彩色图像来说,通道数为3。这里in_channels=1,表示输入的是灰度图像。
out_channels:输出的通道数,也就是卷积核的数量,每个卷积核都会产生一张特征图作为输出。因此,这个参数指定了卷积层输出的特征图数量。
kernel_size:卷积核的大小,可以是一个整数或者是一个元组,如果是一个整数,表示卷积核的高和宽相同;如果是一个元组,表示分别指定卷积核的高和宽。
stride:卷积核的步长,指定在输入上卷积核的滑动步长,用于计算输出特征图的尺寸。默认值为1,表示逐个像素地遍历输入,也可以指定为一个整数或者是一个元组。
padding:填充的大小,指定在输入的四周填充0的层数,可以是一个整数或者是一个元组,用于控制卷积操作的输出尺寸。默认值为0,表示不进行填充。
综合来说,nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)表示创建了一个输入通道数为1、输出通道数为16的二维卷积层,卷积核的大小为3x3,步长为1,填充为1。这样的卷积层将会对输入数据进行卷积操作并输出16张特征图,其中卷积核的大小为3x3,并且在卷积操作中进行了填充以保持输出特征图的尺寸。
具体的内容可以看这个视频:
2、ReLU激活函数
作用:在神经网络中引入非线性,以增强网络的表示能力和学习复杂模式。
inplace=True 表示在原地进行操作,即将激活函数ReLU的计算结果直接覆盖到输入变量中,而不是创建一个新的变量来存储计算结果。
如果输入 x 大于 0,那么输出 y 就等于 x;如果输入 x 小于等于 0,那么输出 y 就等于 0。这就是 ReLU 函数的计算过程,它的形式非常简单,但在神经网络中具有重要的作用,能够引入非线性并且解决梯度消失问题。
【官方双语】一个例子彻底理解ReLU激活函数_哔哩哔哩_bilibili
3、池化层
作用是通过降采样来减少特征图的尺寸,提取主要特征并且减少模型对位置的敏感性。
有最大池化和平均池化两种形式。
二、全连接网络
全连接层
作用:将神经网络中的所有神经元都连接到上一层的每一个神经元上,用于学习输入数据的复杂特征和进行最终的分类或回归。
学习率
学习率是指在训练神经网络时用来更新模型参数的步长大小,即每次参数更新时的调整幅度,过大会导致震荡,过小会导致收敛缓慢。















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









