






(导师和师兄的文章,仅自己学习用)


本文提出了一种新颖的基于进化策略的进化算法,称为 DMOES,它可以有效地解决动态环境中的多目标优化问题。首先,设计了一种高效的自适应精确可控变异算子,供个体探索和利用决策空间。其次,模拟的各向同性磁粒子生态位可以引导个体保持均匀的距离和范围,以自动逼近整个帕累托前沿。第三,非支配解(NDS)引导的迁移(没看懂这个词什么意思)可以分别通过 NDS 和 支配解,两种不同的策略促进种群收敛。因此,当环境发生变化时,我们的算法可以跟踪新的近似Pareto集并尽快逼近Pareto前沿。此外,DMOES 可以获得收敛性好、多样化的 Pareto 前沿,且群体规模小得多,计算成本也低得多。个体数量越多,所得到的近似帕累托前沿的轮廓就越清晰。最后,所提出的算法通过 FDA、dMOP、UDF 和 ZJZ 测试套件进行评估。与一些选定的最先进的动态多目标进化算法相比,实验结果已被证明可以提供有竞争力且通常更好的性能。
1.动态多目标优化
DMOP的数学模型可以用公式表示如下:
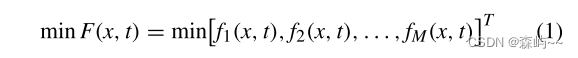

其中x = [x1,x2,...xN]属于,是搜索空间,并且X由N个决策向量组成。
是搜索空间。f(x,t)由M个目标函数组成。
表示目标空间,DMOP和MOP之间的区别在于DMOP的目标函数在时间步长t代内保持静止。t是离散时间实例,t =(1/nt)[(τ/τt)],其中nt、τt和τ分别表示变异的程度、变化的频率和迭代计数器。

定义1(动态帕累托优势):设u和v是两个决策向量,u在时间t处支配v,表示为,对任意i属于{1,....,M},fi(u,t)≤fi(v,t),那么存在j属于{1,....,M},fj(u,t)≤fj(v,t)
定义2(动态帕累托最优解):如果在时间t,决策向量u不能被决策空间中的任何其他决策向量支配,则u被称为在时间t的帕累托最优解或NDS。
定义3(动态帕累托最优集,PSt):时间t的所有Pareto最优解的集合称为时间t的Pareto集合。
定义4(动态帕累托前沿,PFt):在时间t的目标向量的集合从在时间t的所有帕累托最优解映射。
1.1精确可控变异算子


变量p是控制决策空间中的局部搜索的参数,变量q是控制决策空间中的全局搜索的参数。函数Random(p)可以生成1到p范围内的伪随机数。
如果所需的搜索利用精度是0.001,则参数p可以被设置为3(即小数点以下三位数)随机数(p)应该在{1,2,3}的集合中,则[1/(10 ^Random(p))]的对应值将在{0.1,0.01,0.001}的集合中。Random(9)的值可以被认为是从1到9的随机系数。显然,这些变异方程可以在所需的最小精度0.001内生成所有相邻解。
等式(4)和(5)可以生成小于或大于原始xi的β的新个体,这可以被认为是探索远离xi的决策空间。
显然,具有(2)和(3)的变异算子可以从其原始值生成小的变化x,这对于局部搜索是有用的。另一方面,具有(4)和(5)的变异算子可以产生远离原始值的个体,这有助于跳出局部最优。在精度可控变异算子中,参数p和q建议由决策者按所需的搜索精度来设置。p和q的数目越小,对于较小的决策空间,收敛得越快。
即上述式子中参数P是对于局部搜索进行调节,而参数Q则是跳出局部搜索,用于全局搜索调节
伪代码如下:

1.2模拟各向同性磁性颗粒的小生境

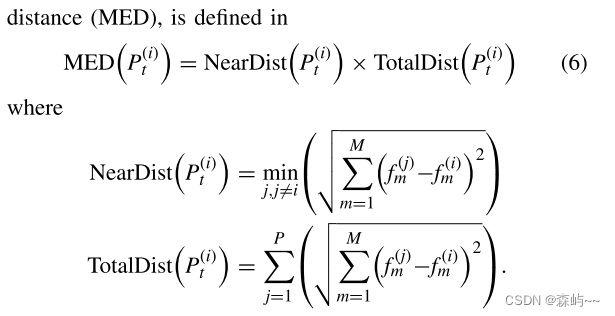
提出了一种新的小生境策略来模仿各向同性磁性粒子在磁场中的行为,引导个体保持均匀的距离和延伸以自动逼近整个帕累托前沿。小生境距离,称为最大延伸距离MED。

在该等式中,是第t代群体Pt中的第i个个体。TotalDist(
)计算
和
之间的欧几里得距离的总和。TotalDist(
)的较大值意味着解
已经远离其他个体。NearDist(
)计算
和
之间的最小欧几里得距离。NearDist(
)的值越大意味着个体距离越好。所提出的MED策略是NearDist()和TotalDist()的乘积。MED越大意味着个体已经扩展了总体边界,并且个体已经获得了更好的距离。如果NDS中的原始解和变异的新解相对于彼此是非支配的,则应选择具有较大MED值的更好距离解。(保持多样性,跳出局部最优解)
欧氏距离越小,两个向量的相似度越大;欧氏距离越大,两个向量的相似度越小。
NearDist()越大证明这个距离掌控的越好
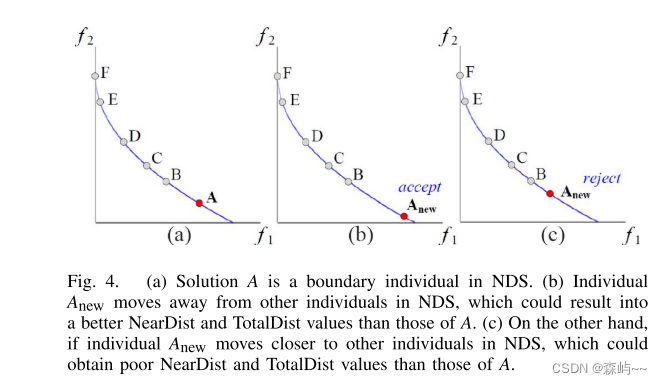
解A是NDS中的边界个体。(b)个体Anew远离NDS中的其他个体,这可能导致比A更好的NearDist和TotalDist值。(c)另一方面,如果个体Anew向NDS中的其他个体移动得更近,则可能获得比A差的NearDist和TotalDist值。
(获取更大的一个边界)

(a)解决方案B是NDS中的中间个体。(b)个体Bnew移动远离NDS中的最近邻居,这可能导致比B更好的NearDist值。(c)另一方面,如果个体Bnew移动得更靠近NDS中的其他个体,则其可能获得比B差的NearDist值。
NearDist()越大证明这个距离掌控的越好,保持一个均匀的间隔。图5表述很明确
伪代码:

1.3 非支配解引导迁移
为了快速跟踪新的PFt,我们的算法为NDS和DS设计了不同的收敛策略,如图2所示。一方面,NDS中的个体可以被具有更好收敛性的非支配变异新解所取代特性。另一方面,DS中的个体可能会被与NDS距离更近的变异新解所取代。
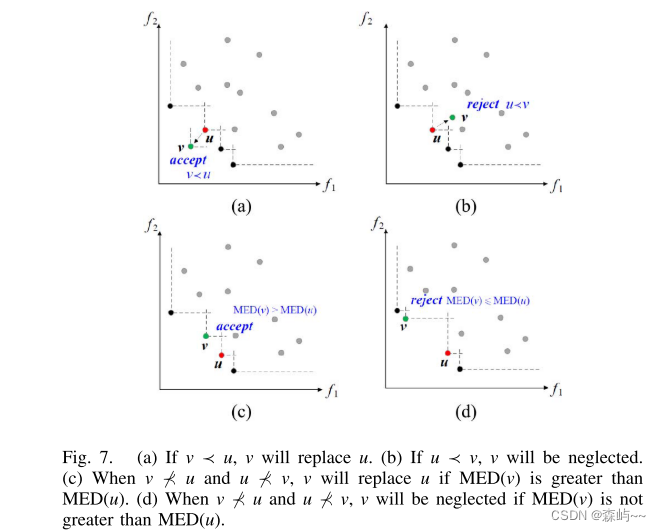
图7一目了然,(a)如果v支配u,v将替代u。(b)如果u支配v,v被拒绝。(c)如果相互不支配,当v的MED大于u时,v将替代u。(d)如果相互不支配,当v的MED小于u时,v将被拒绝。
此方法针对NDS

(a) 目标空间中的 NDS 和 DS,其中 NDS 包括个体 A、B、C、D 和 E。 (b) 在决策空间中,如果 v 更接近 NDS,v 将取代 u。 (c) 在决策空间中,如果 v 远离 NDS,则 v 将被忽略。
其中MinDIst2NDS计算公式如下:
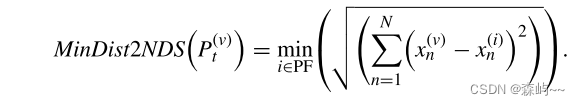
针对DS
通过这种方式,NDS 可以引导全体人口收敛到新的 PFt。另外,NDS和DS的划分不仅是为了收敛,也是为了多样性的目的。 DS中个体的生态位计算或维护分布会浪费大量的计算资源。

参考文献
K. Zhang, C. Shen, X. Liu and G. G. Yen, "Multiobjective Evolution Strategy for Dynamic Multiobjective Optimization," in IEEE Transactions on Evolutionary Computation, vol. 24, no. 5, pp. 974-988, Oct. 2020, doi: 10.1109/TEVC.2020.2985323.

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











