






 NSGA-II是一种改进的遗传算法,通过快速非支配排序降低计算复杂度,引入拥挤度和精英策略保持种群多样性。它利用非支配等级和拥挤度来优化种群,确保Pareto最优解的生成。
NSGA-II是一种改进的遗传算法,通过快速非支配排序降低计算复杂度,引入拥挤度和精英策略保持种群多样性。它利用非支配等级和拥挤度来优化种群,确保Pareto最优解的生成。
1.带精英策略的非支配排序的遗传算法(NSGA-II)
2000年,Deb又提出NSGA的改进算法一带精英策略的非支配排序遗传算法(NSGA-II),针对以上的缺陷通过以下三个方面进行了改进:
1.提出了快速非支配排序法,降低了算法的计算复杂度。
2.提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
3.引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
2.基本原理
2.1快速非支配排序法
首先解释一下什么叫支配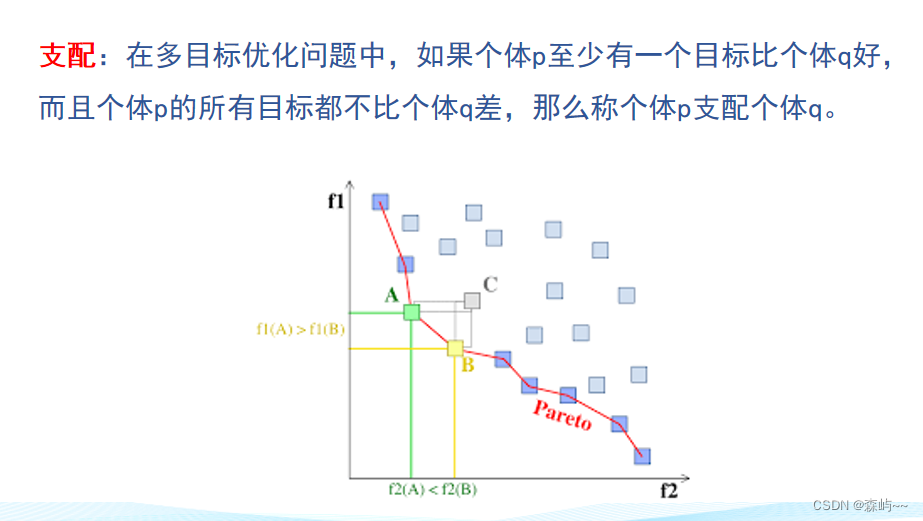
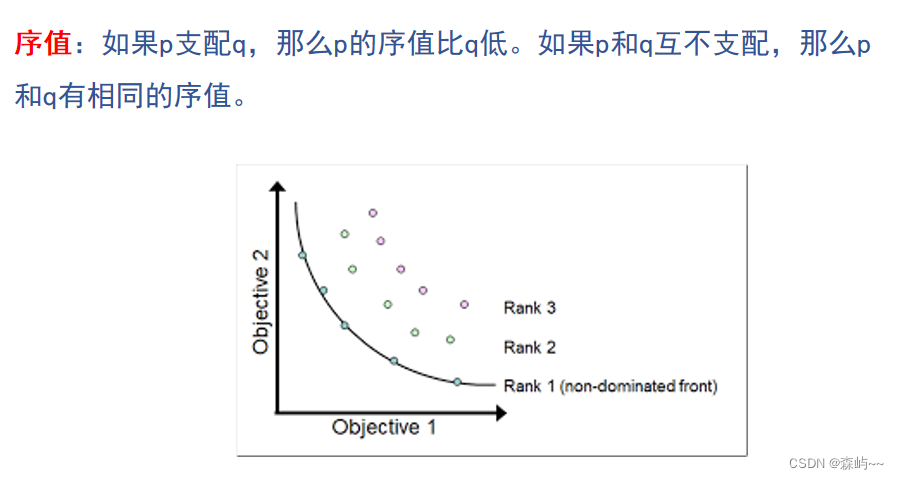
在生成最优的帕累托前沿(Rank 1)前,可能会生成多个rank。那么快速非支配排序就是按照这个rank序列来进行一个排序。
NSGA-II对第一代算法中非支配排序方法进行了改进:对于每个个体 i 都设有以下两个参数 n(i) 和 S(i),
1.n(i) 为在种群中支配个体 i 的解个体的数量。(别的解支配个体 i 的数量)
2.S(i) 为被个体 i 所支配的解个体的集合。(个体 i 支配别的解的集合)
(1)通过循环比较找到种群中所有ni = 0的个体,赋予其非支配等级为1,并将这些个体存入非支配集合rank1中。
(2)集合rank1中的每一个个体,将其所支配的个体集合中的每个个体的nj都减去1,若nj-1=0则将个体j存入集合rank2中,并赋予其中的个体非支配等级2。
(3)之后对rank2中的个体重复上述操作,直至所有个体都被赋予了非支配等级。
非支配等级也称作Pareto等级,其中Pareto等级为1的个体由于不受其他个体的支配,叫做非支配解,也叫 Pareto最优解,而解集所形成的曲线叫做Pareto前沿。
仔细理解一下就是 ni=0时,rank =1 是Pareto最优解,里面的个体会支配一些个体集合。nj是种群中支配个体j的的解个体数量,如果nj-1=0,证明此事n(j)已经没有可以支配的其他个体了,那么久赋予其中个体非支配等级2。(这一段需要好好体会一下)
2.2确定拥挤度
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)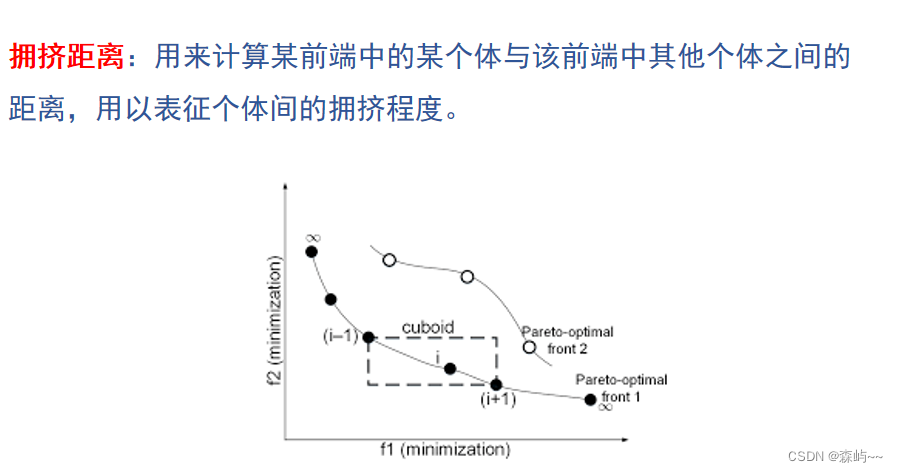

由于经过了排序和拥挤度的计算,群体中每个个体 i 都得到两个属性:非支配序 i(rank) 和拥挤度 ,则定义偏序关系:当满足条件 i(rank) <j(rank) ,或满足 i(rank) = j(rank) 且id >jd 时,定义,也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
总的来说就是优先选择rank其次是distance
2.3 精英策略
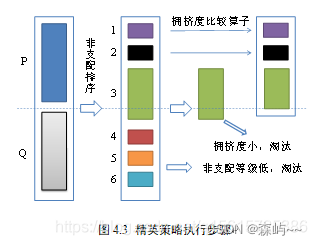
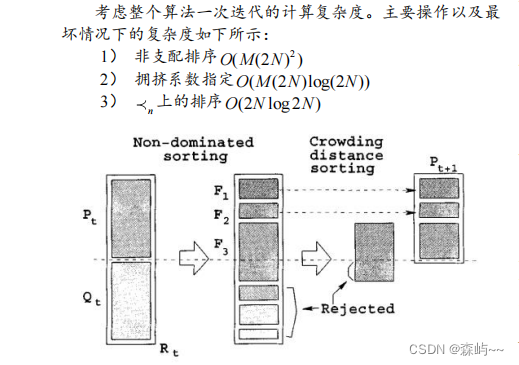
NSGA-II算法引入了精英策略,达到保留优秀个体淘汰劣等个体的目的。精英策略通过将父代与子代个体混合形成新的群体,扩大了产生下一代个体时的筛选范围。以图所示的例子进行分析,图中P表示父代种群,设其中的个体数量为n,Q表示子代种群,具体步骤如下:
(1)将父代种群和子代种群合并形成新的种群。之后对新种群进行非支配排序,本例中将种群分成了6个Pareto等级。
(2)进行新的父代的生成工作,先将Pareto等级为1的非支配个体放入新的父代集合当中,之后将Pareto等级为2的个体放入新的父代种群中,以此类推。
(3)若等级为k的个体全部放入新的父代集合中后,集合中个体的数量小于n,而等级为k+1的个体全部放入新的父代集合中后,集合中的个体数量大于n,则对第k+1等级的全部个体计算拥挤度并将所有个体按拥挤度进行降序排列,之后将等级大于k+1的个体全部淘汰。本例中可以看出k为2,所以对Pareto等级为3的个体计算拥挤度并按其进行降序排序,等级为4~6的个体全部淘汰。
(4) 将等级k+1中的个体按步骤2中排好的顺序逐个放入新的父代集合中,直到父代集合中的个体数量等于n,剩余的个体被淘汰。
整个NSGA-Ⅱ的基本思路是这样,具体matlab如何实现,本人实力有限以两个简单函数做个示范,后续找到合适的再来改进
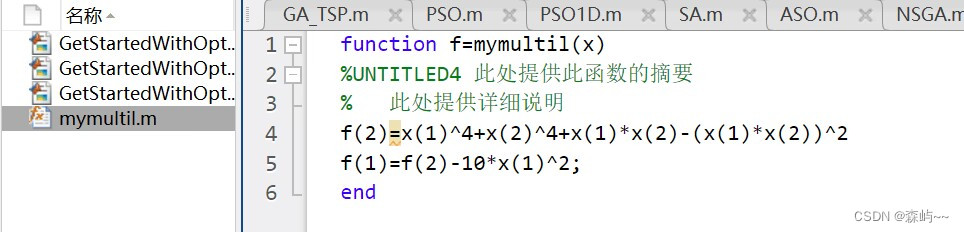
这个是求解 两个函数的帕累托最优解 ,函数具体表达式在下图(注意文件名)
clear;
clc;close
navar = 2;
lb= [0,-5];
ub= [5 0];
x1=linspace(lb(1),ub(1));
x2=linspace(lb(2),ub(2));
obj=[];
for i=1:length(x1)
for j=1:length(x2)
obj=[obj;mymultil([x1(i) x2(j)])];
end
end
scatter(obj(:,1),obj(:,2))
%%
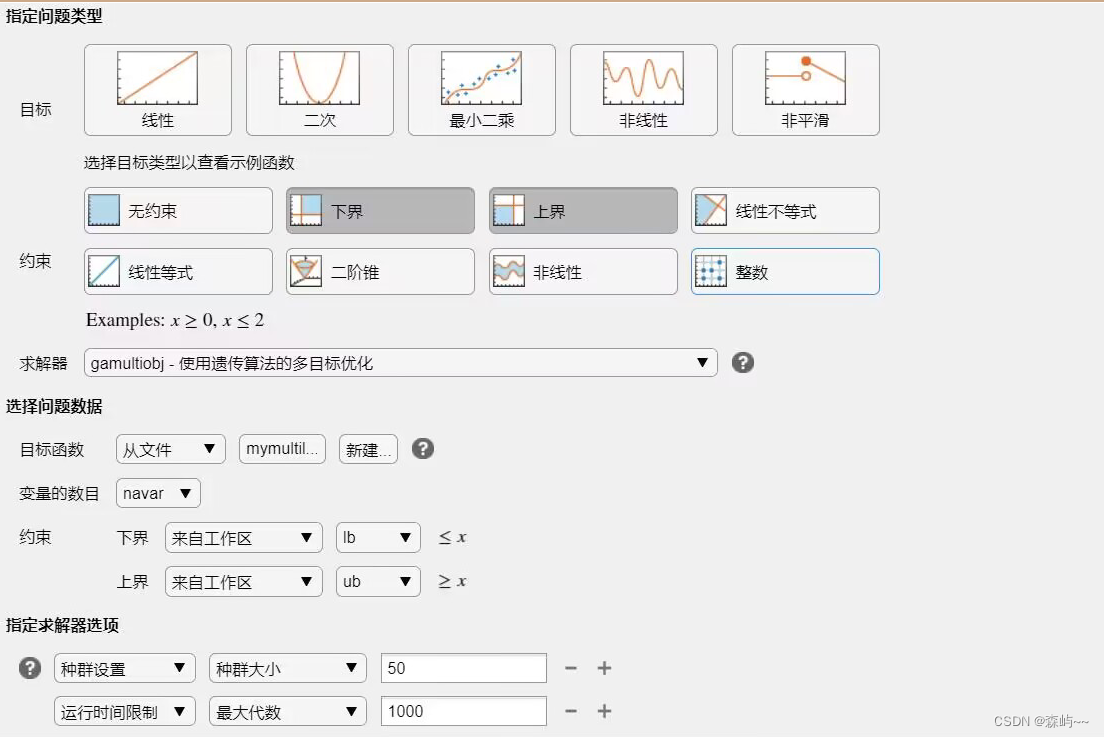
optimtool
调用matlab自带的工具箱
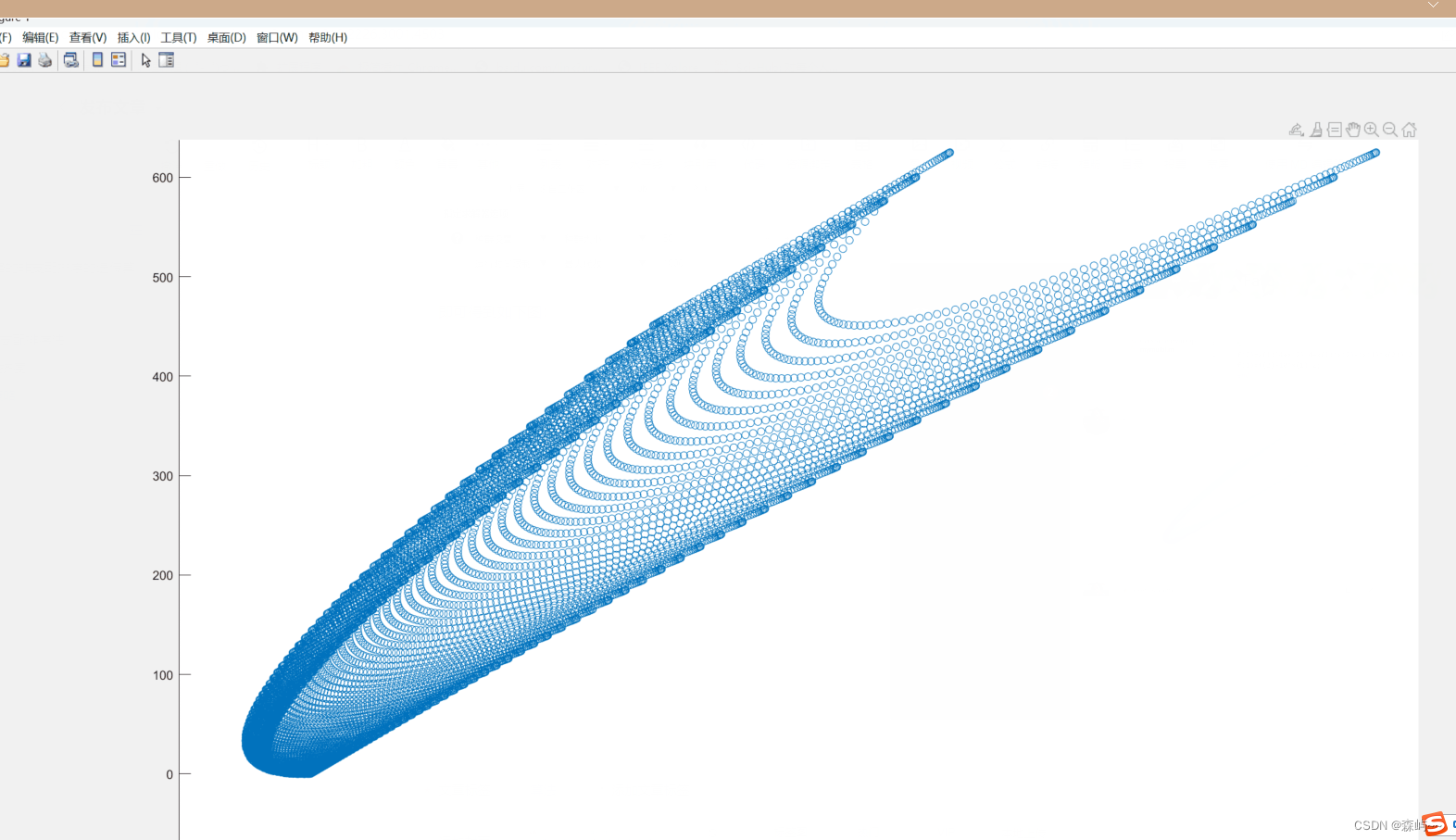
即可得到如下图:
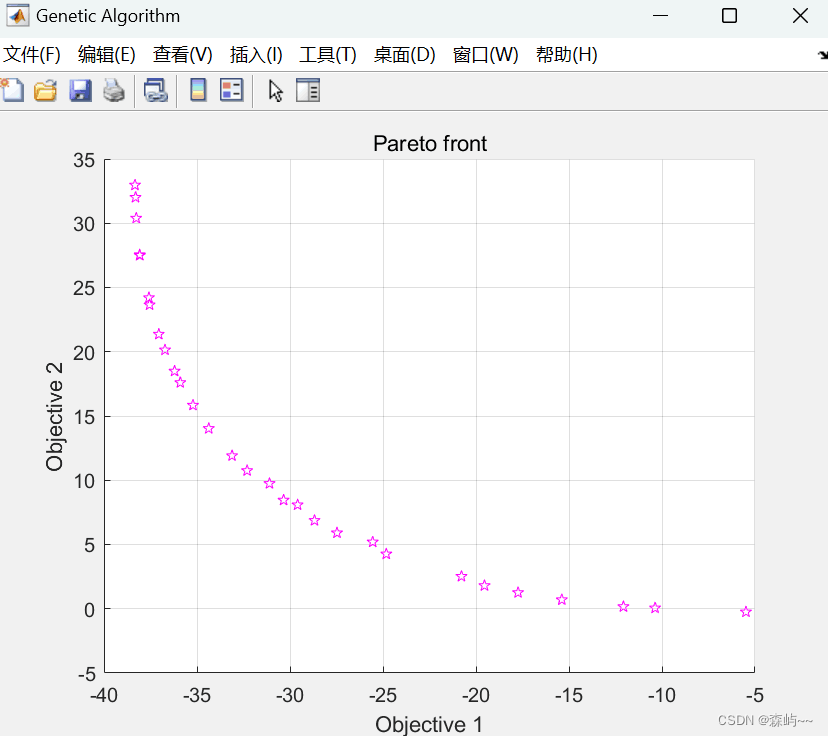
非支配排序遗传算法(NSGA,NSGA-II )-CSDN博客
function rank = fastNonDominatedSort(population)
% population: 种群的目标函数值,大小为 populationSize x numObjectives
% rank: 种群中每个个体的等级
[populationSize, numObjectives] = size(population);
rank = zeros(populationSize, 1); % 初始化等级为0
dominatedSet = cell(populationSize, 1); % 存储每个个体的被支配集合
dominateCount = zeros(populationSize, 1); % 每个个体的支配计数
for i = 1 : populationSize
dominatedSet{i} = []; % 初始化被支配集合为空
dominateCount(i) = 0; % 初始化支配计数为0
end
for i = 1 : populationSize
for j = 1 : populationSize
if i == j
continue;
end
% 比较个体 i 和个体 j 的目标函数值
if all(population(i,:) <= population(j,:)) && any(population(i,:) < population(j,:))
dominatedSet{i} = [dominatedSet{i} j]; % 将个体 j 添加到个体 i 的被支配集合中
elseif all(population(j,:) <= population(i,:)) && any(population(j,:) < population(i,:))
dominateCount(i) = dominateCount(i) + 1; % 个体 i 的支配计数增加
end
end
if dominateCount(i) == 0 % 如果个体 i 没有被其他个体支配
rank(i) = 1; % 将等级设为1
end
end
currentRank = 1;
currentFront = find(rank == currentRank); % 当前等级的个体
while ~isempty(currentFront)
nextFront = []; % 下一等级的个体
for i = 1 : length(currentFront)
p = currentFront(i);
% 更新被支配个体的支配计数
for j = 1 : length(dominatedSet{p})
dominateCount(dominatedSet{p}(j)) = dominateCount(dominatedSet{p}(j)) - 1;
% 如果被支配个体不再被支配
if dominateCount(dominatedSet{p}(j)) == 0
rank(dominatedSet{p}(j)) = currentRank + 1; % 设置等级为下一等级
nextFront = [nextFront dominatedSet{p}(j)]; % 添加到下一等级的个体列表中
end
end
end
currentRank = currentRank + 1;
currentFront = nextFront; % 更新当前等级的个体列表
end
end


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











