







前言
在大数据时代,数据的获取和分析是学术研究和项目开发的重要环节。通过网络爬虫,我们可以自动化地从网页中提取所需的数据,极大地提高了数据收集的效率。本文将介绍如何使用Python爬虫获取山东大学各学院官网的数据。
目标
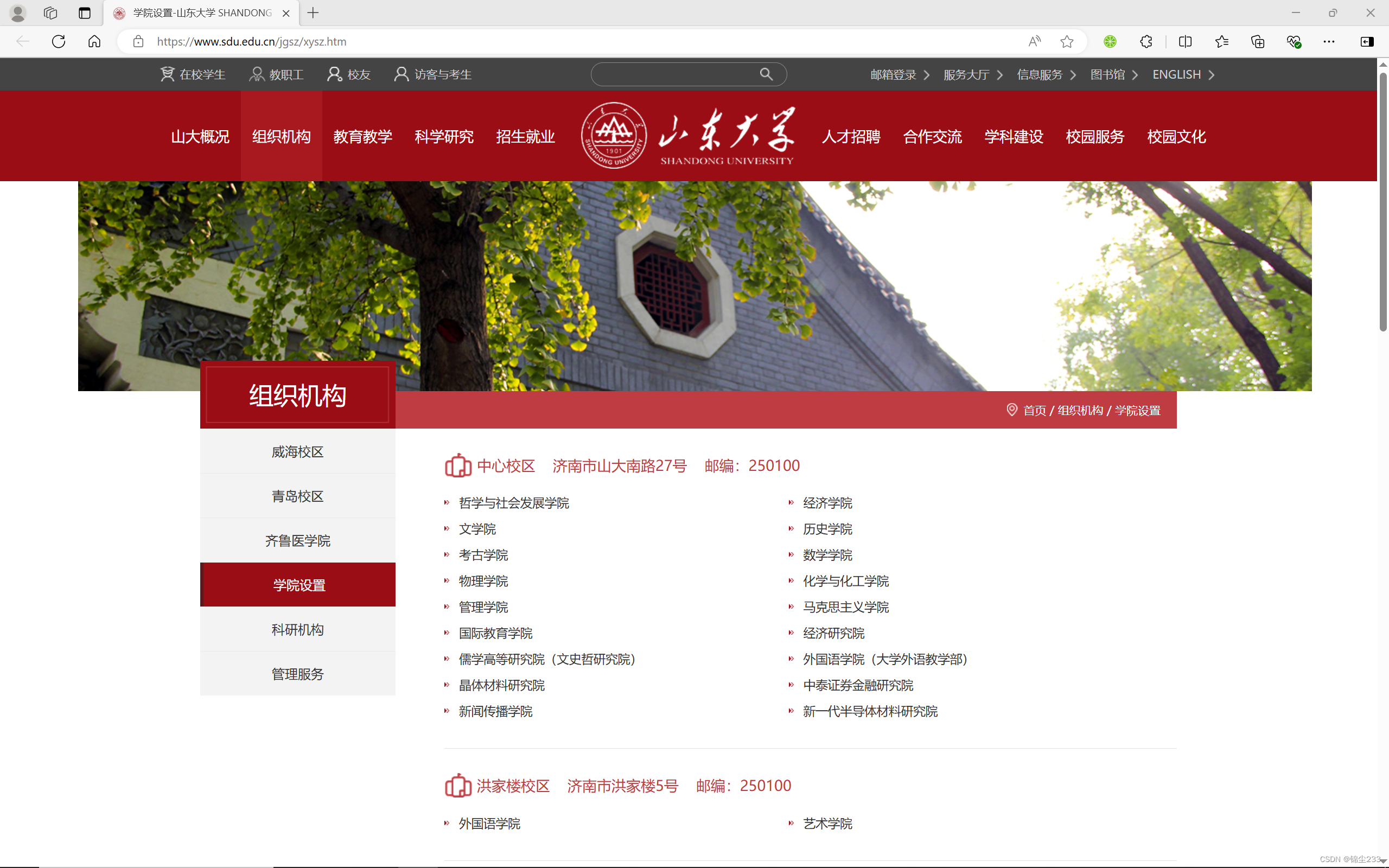
我们的目标是从山东大学机构设置页面获取各学院的链接,并进一步爬取每个学院的介绍页面。以下是具体的步骤和代码实现。
环境准备
-
安装Python:确保系统中安装了Python 3.x。
-
安装必要的库:我们需要使用Selenium库进行网页交互。可以通过以下命令安装:
pip install selenium
爬虫代码
以下是完整的Python代码,用于从山东大学机构设置页面爬取各学院的链接,并进一步爬取每个学院的介绍页面:
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import csv
def setup_driver():
options = webdriver.EdgeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
driver = webdriver.Edge(options=options)
return driver
def get_college_links(driver, url):
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'wp_article_list')))
college_elements = driver.find_elements(By.CSS_SELECTOR, '.wp_article_list a')
college_links = {element.text: element.get_attribute('href') for element in college_elements}
return college_links
def get_college_info(driver, url):
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'content')))
title = driver.find_element(By.TAG_NAME, 'h3').text
paragraphs = driver.find_elements(By.TAG_NAME, 'p')
content = '\n'.join([para.text for para in paragraphs])
return title, content
def save_to_csv(college_data, filename):
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['学院', '链接', '标题', '内容']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for data in college_data:
writer.writerow(data)
def main():
driver = setup_driver()
base_url = "https://www.sdu.edu.cn/jgsz/xysz.htm"
college_links = get_college_links(driver, base_url)
college_data = []
for college, link in college_links.items():
print(f"正在爬取 {college} 的信息...")
title, content = get_college_info(driver, link)
college_data.append({'学院': college, '链接': link, '标题': title, '内容': content})
time.sleep(2) # 防止爬取过快被封禁
save_to_csv(college_data, 'sdu_colleges.csv')
driver.quit()
if __name__ == "__main__":
main()
代码解析
-
设置驱动:我们使用Edge浏览器作为驱动,配置不加载图片以提高爬取速度。
def setup_driver(): options = webdriver.EdgeOptions() options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) driver = webdriver.Edge(options=options) return driver -
获取学院链接:从机构设置页面中提取所有学院的链接。
def get_college_links(driver, url): driver.get(url) WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'wp_article_list'))) college_elements = driver.find_elements(By.CSS_SELECTOR, '.wp_article_list a') college_links = {element.text: element.get_attribute('href') for element in college_elements} return college_links -
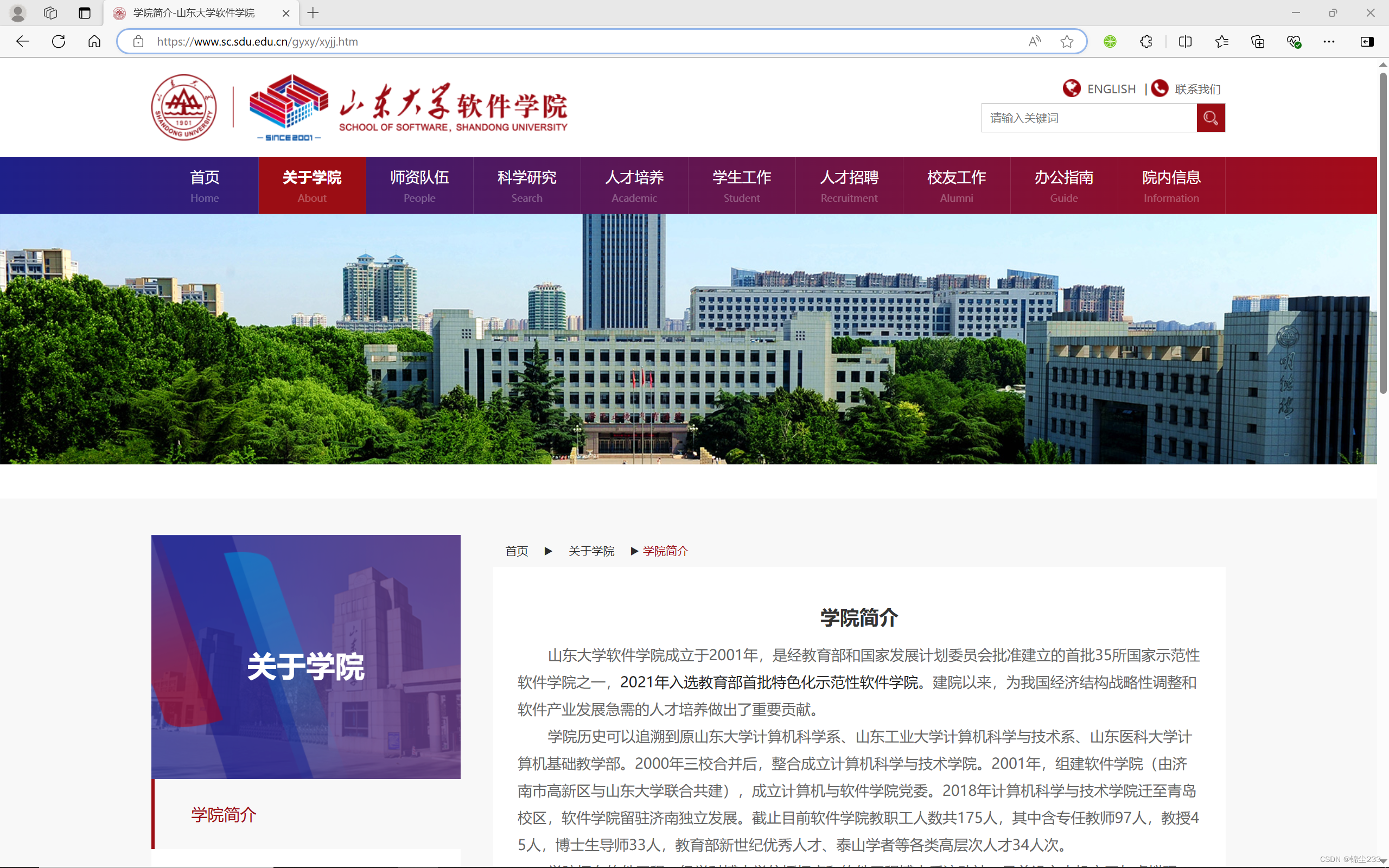
获取学院介绍信息:进入每个学院的主页,提取学院简介的标题和内容。
def get_college_info(driver, url): driver.get(url) WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'content'))) title = driver.find_element(By.TAG_NAME, 'h3').text paragraphs = driver.find_elements(By.TAG_NAME, 'p') content = '\n'.join([para.text for para in paragraphs]) return title, content
-
保存数据到CSV:将爬取到的数据保存到CSV文件中,以便后续分析和处理。
def save_to_csv(college_data, filename): with open(filename, 'w', newline='', encoding='utf-8') as csvfile: fieldnames = ['学院', '链接', '标题', '内容'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for data in college_data: writer.writerow(data)
-
主函数:组织各个步骤,进行数据爬取和保存。
def main(): driver = setup_driver() base_url = "https://www.sdu.edu.cn/jgsz/xysz.htm" college_links = get_college_links(driver, base_url) college_data = [] for college, link in college_links.items(): print(f"正在爬取 {college} 的信息...") title, content = get_college_info(driver, link) college_data.append({'学院': college, '链接': link, '标题': title, '内容': content}) time.sleep(2) # 防止爬取过快被封禁 save_to_csv(college_data, 'sdu_colleges.csv') driver.quit()
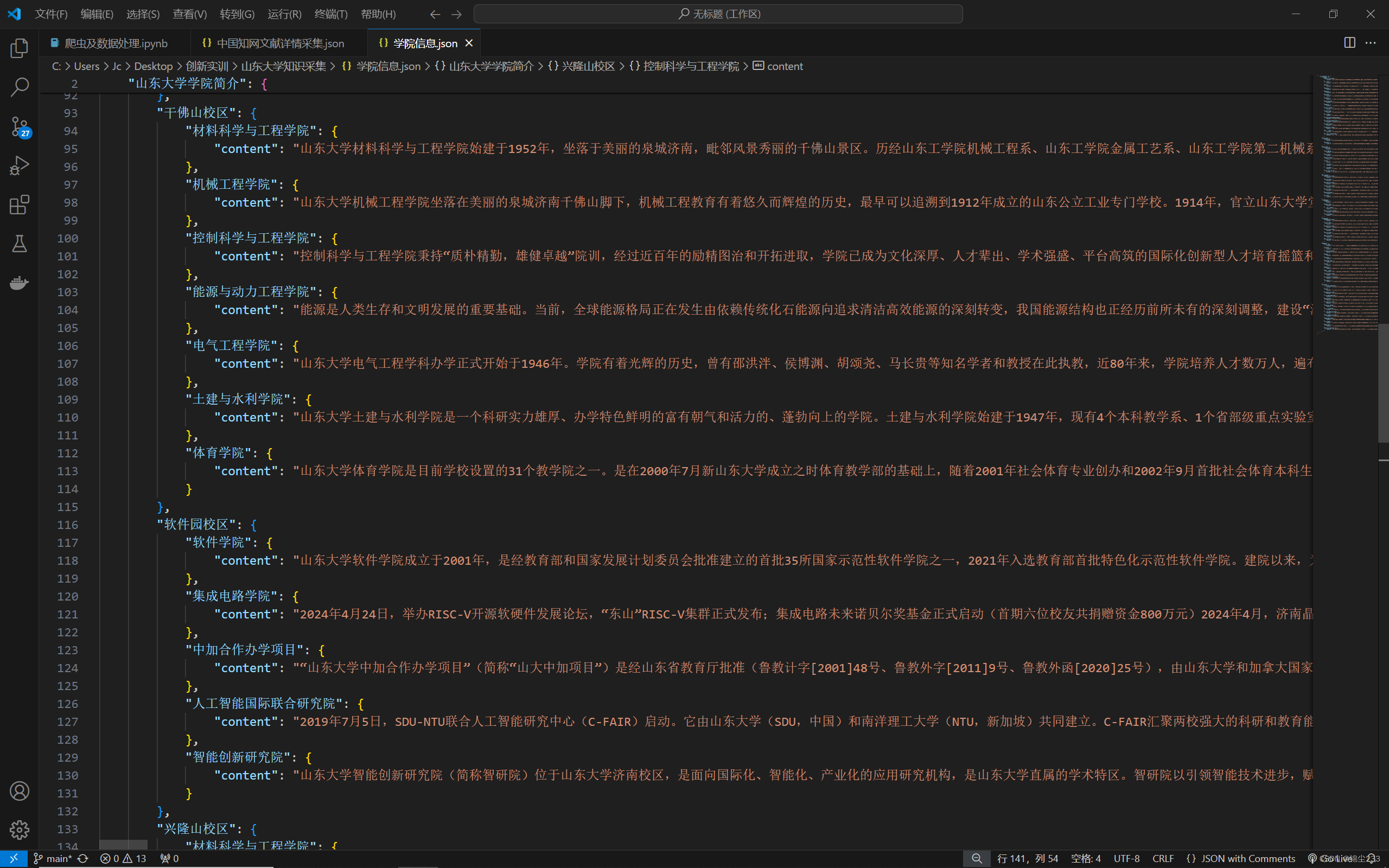
结果展示
通过上述代码,我们成功地从山东大学机构设置页面获取了各学院的链接,并进一步爬取了每个学院的介绍信息。最终将数据保存到CSV文件中,方便后续的分析和研究。
总结
本文介绍了如何使用Python和Selenium库编写爬虫,自动化地获取山东大学各学院官网的信息。通过合理的代码结构和步骤,我们可以高效地完成数据爬取任务。希望通过这篇文章,读者能够掌握基本的爬虫编写方法,并应用到实际的数据采集工作中。















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









