







使用DeepKE进行实体和关系抽取的深度解析
引言
实体和关系抽取是自然语言处理(NLP)中的两个核心任务。实体抽取(NER,Named Entity Recognition)旨在从文本中识别出特定类型的实体,如人名、地名、组织等。而关系抽取(RE,Relation Extraction)则用于识别这些实体之间的关系。这些任务在知识图谱构建、信息检索、问答系统等应用中起着关键作用。本文将深入解析如何使用DeepKE工具进行实体和关系抽取,涵盖数据准备、模型训练和优化等环节。
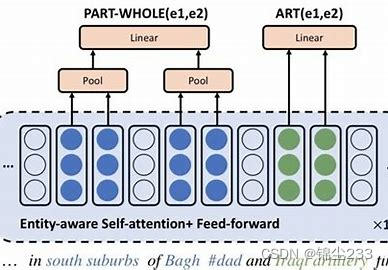
DeepKE简介
DeepKE是一个开源的深度学习知识抽取工具,支持多种信息抽取任务,包括实体识别、关系抽取和属性抽取。DeepKE由浙江大学的知识图谱实验室(ZJUKG)开发,旨在为研究人员和开发者提供一个统一且模块化的框架,以便从非结构化文本中提取信息。
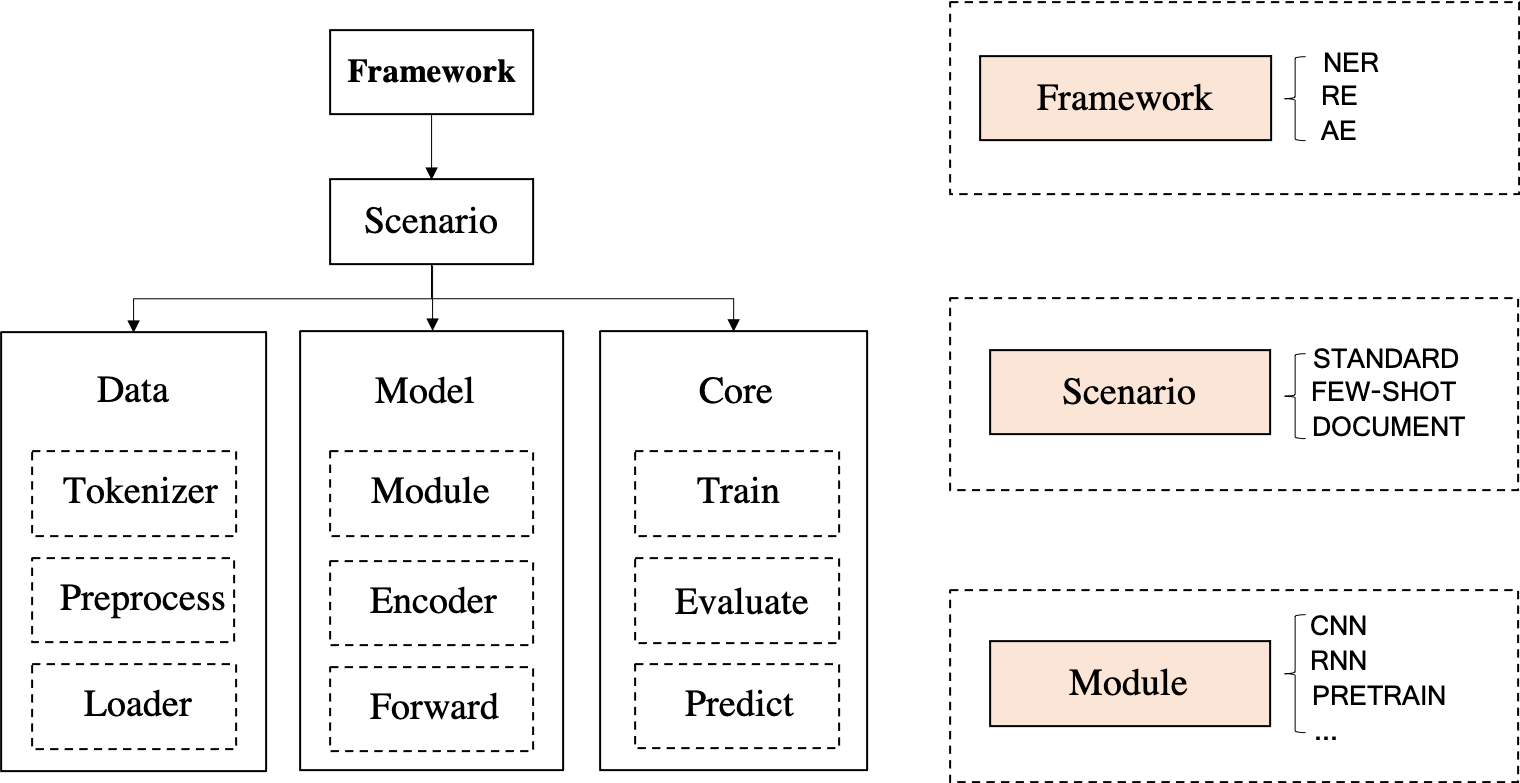
DeepKE的主要特点包括:
- 多场景支持:DeepKE支持标准单句、低资源(few-shot)、文档级和多模态(图文结合)设置,满足不同场景下的信息抽取需求。
- 模块化设计:DeepKE包含数据预处理、模型训练、评估和预测等模块,用户可以根据需求选择和组合不同模块。
- 多语言支持:DeepKE支持中英文多语言模型训练和应用,提供灵活的语言模型支持。
数据准备
数据准备是进行实体和关系抽取的基础。主要包括以下步骤:
-
数据收集:获取包含目标实体和关系的文本数据。常用的数据集包括CoNLL-2003(用于英文NER任务)、People’s Daily(用于中文NER任务)、DuIE(用于中文RE任务)等。
-
数据标注:对文本中的实体和关系进行标注,形成训练数据。可以使用工具如LabelStudio进行标注。数据标注的质量直接影响模型的性能,因此需要保证标注的准确性和一致性。
-
数据预处理:包括文本清洗、分词、标注格式转换等。DeepKE提供了一些预处理工具,简化了这一过程。例如,用户可以使用DeepKE内置的分词工具对中文文本进行分词,并将标注数据转换为模型训练所需的格式。
模型训练
在DeepKE中,模型训练包括模型选择和训练参数设置。
模型选择
DeepKE支持多种模型架构,如BERT、CNN、RNN、Transformer等。根据任务需求选择合适的模型非常重要。例如,BERT在处理上下文相关信息方面表现优异,适合实体和关系抽取任务。以下是几种常见的模型架构:
- BERT:基于Transformer的预训练模型,能够捕捉上下文中的双向信息,在NER和RE任务中表现出色。
- CNN:卷积神经网络,适用于处理固定长度的文本片段,具有计算效率高的优点。
- RNN:循环神经网络,能够处理序列数据,适合处理连续的文本信息。
- Transformer:自注意力机制模型,具有并行计算能力强、捕捉长距离依赖关系的优势。
训练参数设置
训练过程中需要设置一些关键参数,如学习率、批量大小、训练轮次等。DeepKE提供了详细的配置文件,用户可以根据具体任务调整这些参数。此外,DeepKE还集成了Weight & Biases工具,用于可视化和自动调优超参数,提高模型的训练效果。
- 学习率:控制模型参数更新的速度。过高的学习率可能导致模型震荡,过低的学习率则可能使模型收敛速度过慢。
- 批量大小:每次迭代中使用的样本数量。较大的批量大小可以稳定梯度更新,但需要更多的内存资源。
- 训练轮次:整个数据集被训练的次数。训练轮次过多可能导致过拟合,过少则可能导致欠拟合。
优化过程
-
超参数调优:超参数调优是提升模型性能的重要步骤。通过实验确定最佳的超参数组合,例如可以通过网格搜索或贝叶斯优化来调整学习率、批量大小等。Weight & Biases工具提供了可视化和自动调优功能,帮助用户高效调整超参数。
-
模型评估:使用验证集评估模型性能,常用评估指标包括准确率、精确率、召回率和F1分数。DeepKE提供了多种评估工具,方便对模型进行全面评估。例如,可以使用F1分数衡量模型在实体识别和关系抽取任务中的综合表现。
实战案例
以下是一个具体的实体和关系抽取案例,使用DeepKE的步骤如下:
安装DeepKE
首先,安装DeepKE工具:
pip install deepke
准备数据
下载并解压数据集:
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz
将数据集放置在指定目录下,确保文件结构符合DeepKE的要求。
训练模型
进入标准关系抽取任务目录,运行训练脚本:
cd DeepKE/example/re/standard
python run.py
在训练过程中,可以通过配置文件调整参数,如学习率、批量大小等。
预测
训练完成后,修改配置文件中的模型路径,运行预测脚本:
python predict.py
预测结果将保存在指定目录下,用户可以根据需要进行后续处理和分析。
实体和关系抽取示例
我们使用DeepKE对李白的《将进酒》进行实体和关系抽取。以下是部分提取出的结果:
-
原始文本:
李白,字太白,号青莲居士,是唐玄宗时期的一位著名诗人。他的作品《将进酒》广为流传,这首诗以其豪放的风格和深刻的思想而著称。李白与友人岑勋、元丹丘时常相聚,他们在诗作中被称为岑夫子和丹丘生。 岑夫子,名岑勋,是唐玄宗时期的人,籍贯南阳。他的生平不详,但多次出现在李白的诗作中,似乎是李白的密友之一。 丹丘生,名元丹丘,是一位道教徒,也生活在唐玄宗时期。他的生平同样不详,但在李白的作品中频频出现,表明他与李白有深厚的交情。 陈王曹植,字子建,生于沛国谯,是三国时期著名的文学家、诗人和音乐家。曹植是曹操与武宣卞皇后所生的第三子,曾被封为陈王。他的作品《名都篇》描写了洛阳贵游子弟的奢华生活,反映了当时的社会风貌。 李白的《将进酒》不仅是对人生豪情的抒发,也是对古今英雄的敬仰。在诗中,李白引用了岑夫子和丹丘生,表达了对友谊的珍视。他还提到了曹植的《名都篇》和平乐观,显示了他对历史和文学的深刻理解。 -
提取出的实体和关系:
人物节点:
- 李白:姓名:李白,字:太白,号:青莲居士,朝代:唐玄宗时期,职业:诗人,作品:《将进酒》等。
- 岑夫子:姓名:岑勋,朝代:唐玄宗时期,籍贯:南阳人,简介:生平不详,多次出现在李白的诗作当中。
- 丹丘生:姓名:元丹丘,职业:道教徒,朝代:唐玄宗时期,简介:生平不详,多次出现在李白的诗作当中。
- 陈王曹植:姓名:曹植,朝代:三国时期,字:子建,籍贯:沛国谯,简介:三国时期文学家、诗人、音乐家。
关系:
- 李白-将进酒:作者-作品
- 李白-岑夫子:好友
- 李白-丹丘生:好友
- 将进酒-岑夫子:引用
- 将进酒-丹丘生:引用
- 将进酒-曹植:引用
- 将进酒-平乐观:引用
- 将进酒-黄河入海口:引用
总结与展望
通过本文的解析,我们了解了使用DeepKE进行实体和关系抽取的基本流程。从数据准备、模型选择到训练和优化,DeepKE提供了一套完整的解决方案,帮助用户高效地进行知识抽取。未来,随着深度学习技术的发展,DeepKE有望在更多复杂场景下实现更高效的知识抽取。此外,DeepKE的模块化设计和多语言支持为其在实际应用中的灵活性和扩展性提供了保障。

















 4896
4896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









