






目录
neighbors.KNeighborsClassifier参数说明
k近邻算法
K Nearest Neighbor算法又叫KNN算法
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
knn算法的核心思想是未标记样本的类别,由距离其最近的k个邻居投票来决定。
neighbors.KNeighborsClassifier参数说明
KNeighborsClassifier(n_neighbors=5,weights=’uniform’,algorithm=’auto’,leaf_size=30,p=2,metric=’minkowski’,metric_params=None,n_jobs=1,**kwargs)
KNN算法说明以及sklearn 中 neighbors.KNeighborsClassifier参数说明_一年又半的博客-CSDN博客_kneighborsclassifier 参数
n_neighbors: int, 可选参数(默认为 5)
用于kneighbors查询的默认邻居的数量
p: int, 可选参数(默认为 2)
用于Minkowski metric(闵可夫斯基空间)的超参数。对于任何 p ,使用的是闵可夫斯基空间(l_p)
p = 1, 相当于使用曼哈顿距离 (l1),
p = 2, 相当于使用欧几里得距离(l2)
knn实例
python绘图基础—scatter用法_xiaobaicai4552的博客-CSDN博客_ax.scatter
构造出X数据集,y是分类集,做中心点分别为[-2,2],[2,2],[0,4]的三个分类,在最后将X和y打印出来可以看到
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 生成数据
centers = [[-2,2], [2,2], [0,4]]
X, y = make_blobs(n_samples=60, centers=centers,
random_state=0, cluster_std=0.60)
print(X)
print("---------")
print(y)
把现在的这个训练集画出来
plt.scatter(c[:,0], c[:,1], s=100, marker='^',c='orange')
这一行画的是中心点
# 画出数据
plt.figure(figsize=(16,10), dpi=144)
c = np.array(centers)
# 画出样本
plt.scatter(X[:,0], X[:,1], c=y, s=100, cmap='cool')
# 画出中心点
plt.scatter(c[:,0], c[:,1], s=100, marker='^',c='orange')
plt.savefig('knn_centers.png')
plt.show()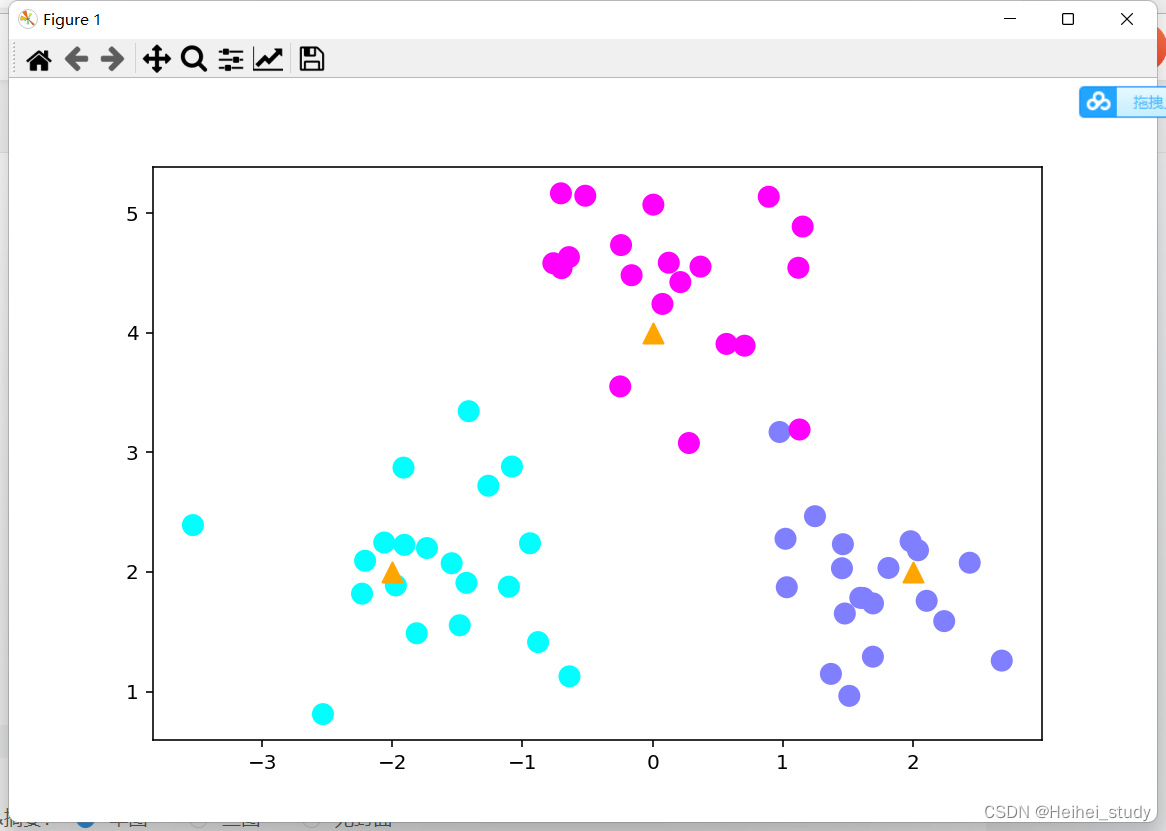
模型训练 使用了KNeighborsClassifier函数
# 模型训练
k = 5
clf = KNeighborsClassifier(n_neighbors = k)
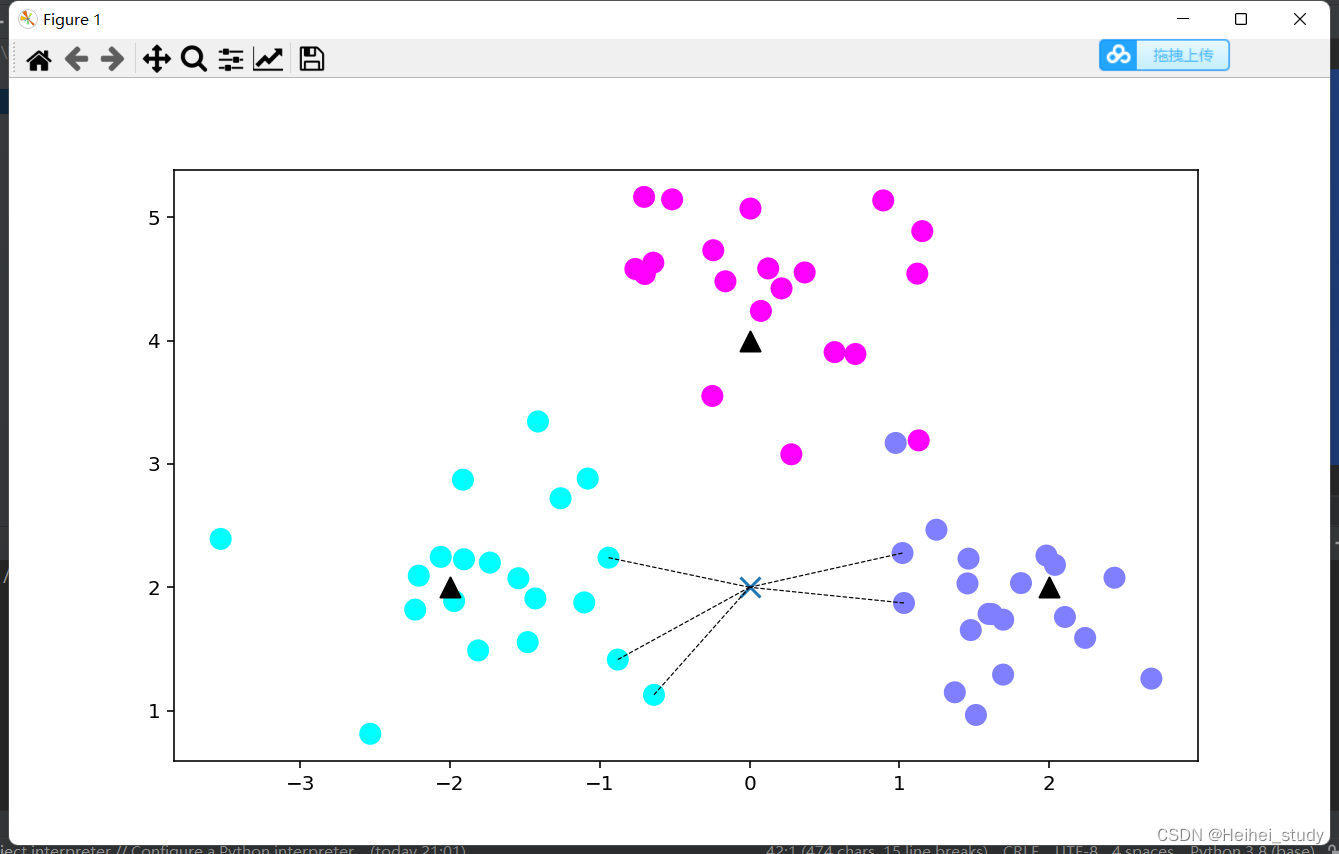
clf.fit(X, y)构造用于测试的的数据集,在这里y_sample使用了predict函数,得到的是分类结果集合,neighbors是用于测试的数据与他相邻的点的下标
# 进行预测
X_sample = np.array([[0, 2]])
y_sample = clf.predict(X_sample)
neighbors = clf.kneighbors(X_sample, return_distance=False)print(X_sample)
print(y_sample)
print(neighbors)
画出示意图
# 画出示意图
plt.figure(figsize=(16,10), dpi=144)
c = np.array(centers)
plt.scatter(X[:,0], X[:,1], c=y, s=100, cmap='cool') # 出样本
plt.scatter(c[:,0], c[:,1], s=100, marker='^',c='k') # 中心点
plt.scatter(X_sample[0][0], X_sample[0][1], marker="x",
s=100, cmap='cool') # 待预测的点
for i in neighbors[0]:
plt.plot([X[i][0], X_sample[0][0]], [X[i][1], X_sample[0][1]],
'k--', linewidth=0.6) # 预测点与距离最近的5个样本的连线
plt.savefig('knn_predict.png')
plt.show()
k-近邻算法梳理(从原理到示例)_JaquanC的博客-CSDN博客_k近邻算法的原理
神经网络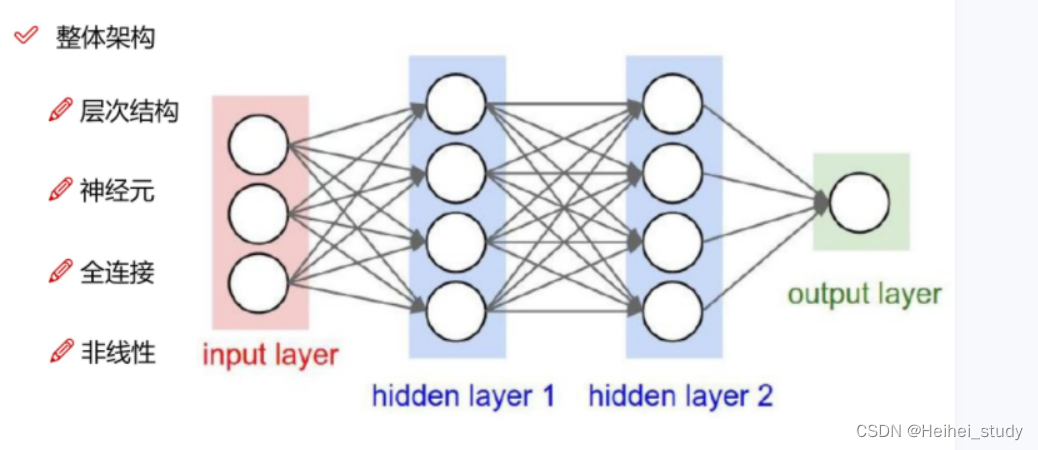
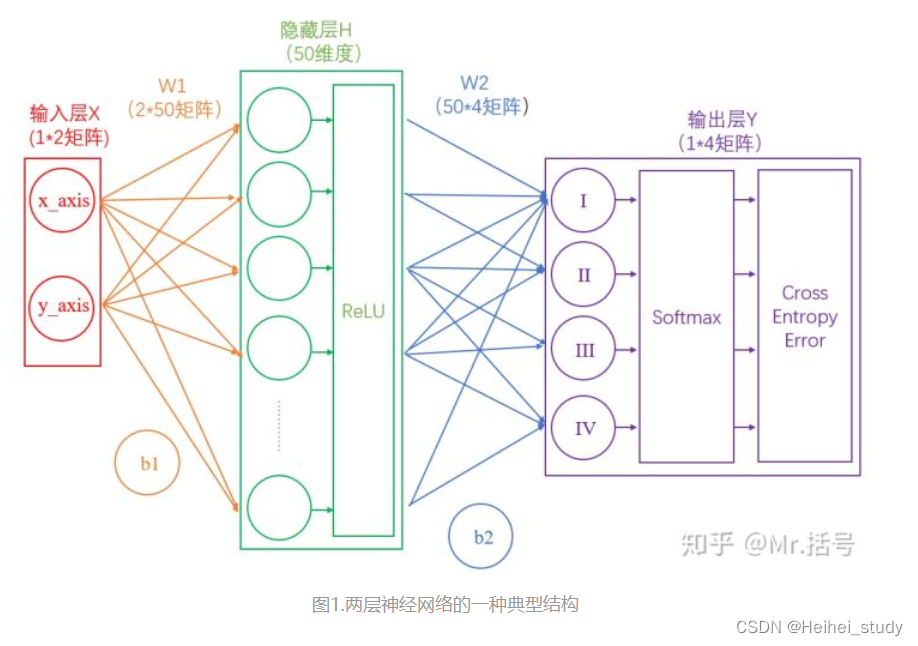
线性函数

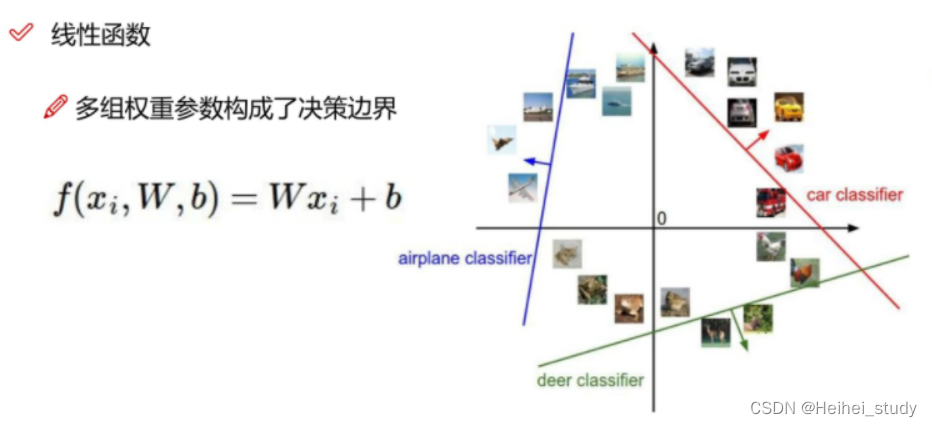
当w是一个数时,可以映射到一个二维平面上
从得分值变为概率值
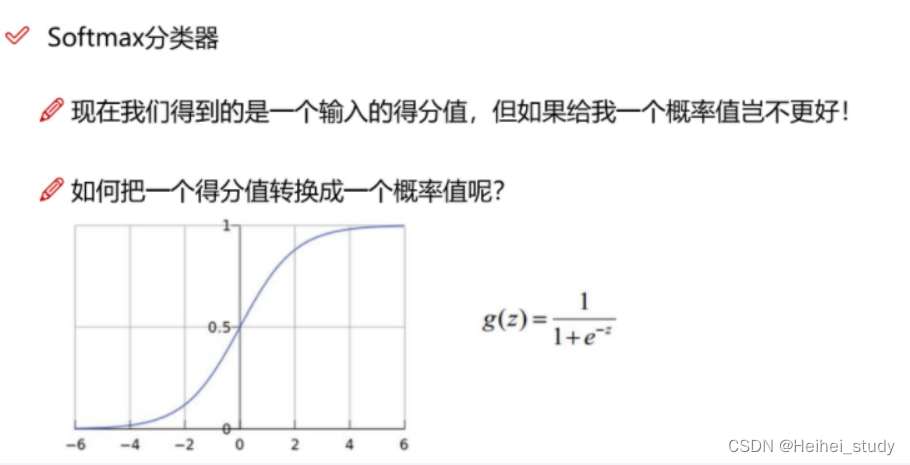

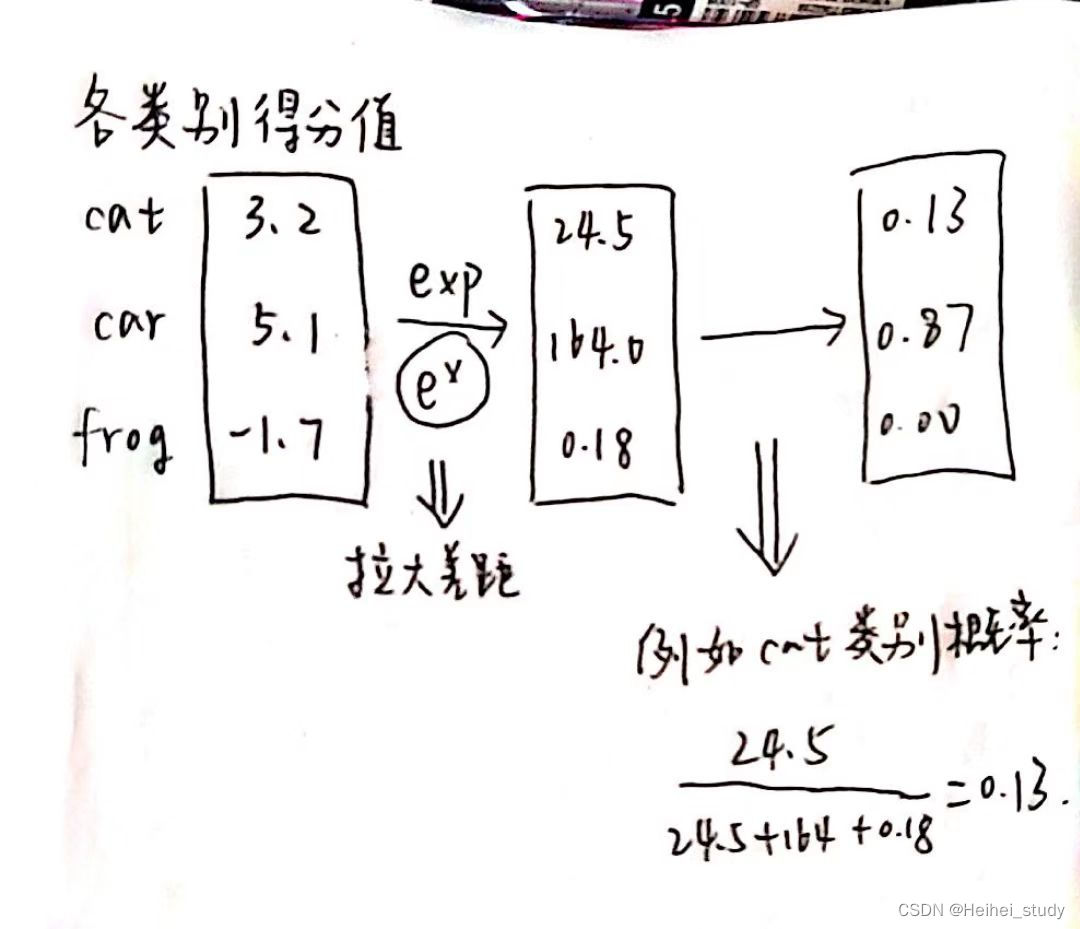
损失函数
衡量我们分类结果

激活层
激活层是为矩阵运算的结果添加非线性的
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









