







此次笔记记录我对IoTDB中时序数据文件TsFile的文件格式的学习理解
基本描述
TsFile 整体分为两大部分:数据区和索引区。二者通过分隔符2来分开。TsFile的结构在下图中展现的十分清晰,需要在学习的过程中多次结合文字回看,才能更好地理解。
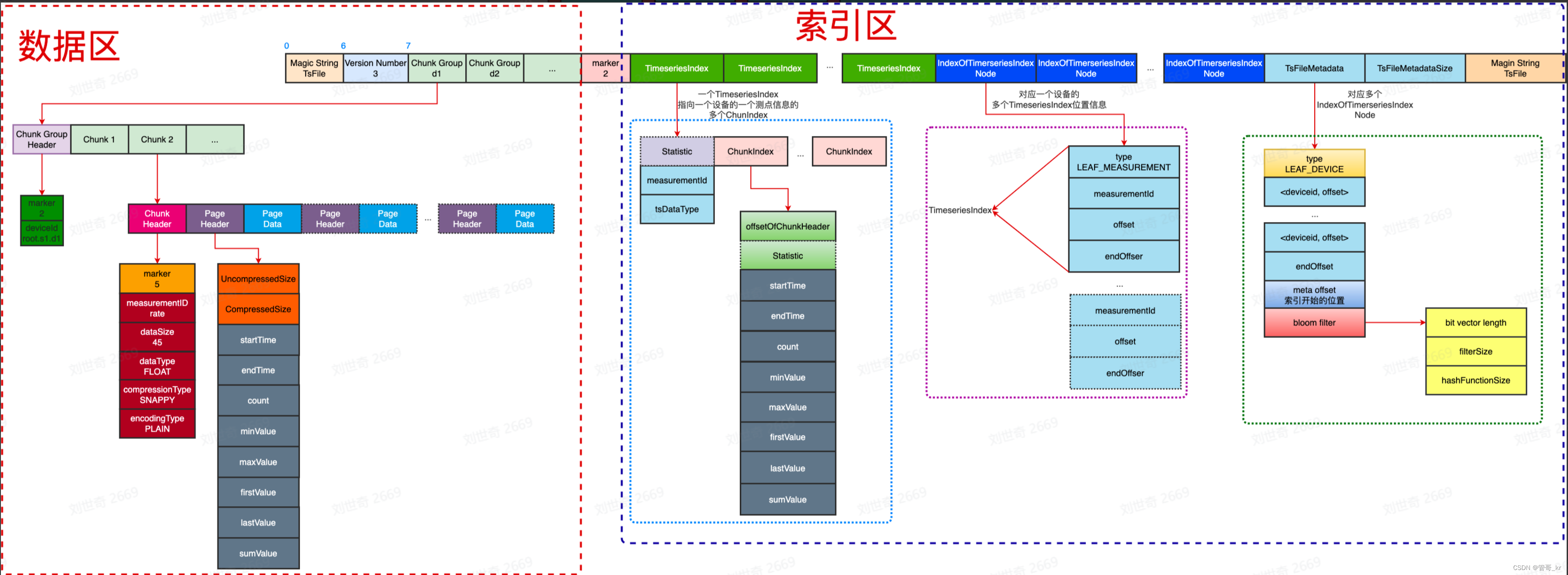
- 数据区包含三部分,由小到大分别为:
- Page数据页
- Chunk数据块
- ChunkGroup数据块组
- 索引区分为三部分:
- TimeseriesIndex:包含1个头信息和数据块索引(ChunkIndex)列表。头信息记录文件内某条时间序列的数据类型、统计信息(最大最小时间戳等);数据块索引(ChunkIndex)列表记录该序列各Chunk在文件中的 offset(offsetOfChunkHeader),并记录相关统计信息(最大最小时间戳等)
- IndexOfTimeseriesIndex:索引各TimeseriesIndex在文件中的 offset
- BloomFilter:针对实体(Entity)的布隆过滤器
- 索引区与数据区分离
- 将索引区与数据区分离,并单独保存在文件尾部是一种常见的数据库索引管理技术,可以提高查询性能和数据访问效率。
- 通过将索引区保存在文件尾部,可以避免在数据连续读取时频繁跳过不需要的索引。具体的实现方式可以是将索引数据结构(如B树、哈希表等)存储在文件尾部的固定位置,或者使用特定的文件结构将索引数据存储在文件尾部。
- 优点:
- 减少磁盘寻道:索引区保存在文件尾部,可以避免在数据区和索引区之间频繁切换,减少了磁盘寻道的开销。这样可以提高数据的连续读取性能,减少随机磁盘访问的次数。
- 提高查询性能:由于索引区和数据区分离,查询操作可以更快速地定位到所需的索引,然后再获取对应的数据。这样可以加快查询速度,并减少不必要的数据扫描。
- 节省内存空间:将索引区单独保存在文件尾部,可以节省内存空间。索引通常需要占用较多的内存,而将其保存在文件尾部可以避免占用主要数据区的内存空间。
- 索引文件的维护和管理:将索引区单独保存在文件尾部,使索引文件的维护和管理更加方便。可以独立地对索引文件进行备份、恢复和优化,而无需涉及主要数据区。
- 需要注意的是,将索引区与数据区分离并单独保存在文件尾部的实现方式可能因数据库管理系统的不同而有所差异。每个数据库系统可能有自己的索引管理策略和实现机制,具体的细节可能会有所不同。
-
数据区
- Page
- 概念:一个 Page 页存储了一段时间序列,是数据块被反序列化的最小单元(也就是说,数据按照page,一段一段地进行压缩)。 它包含一个 PageHeader 和实际的数据(time-value 编码的键值对)
- PageHeader结构:
- uncompressedSize 数据压缩前大小
- compressedSize SNAPPY压缩后大小
- statistics 统计量
- statistics包含的信息如下图所示:
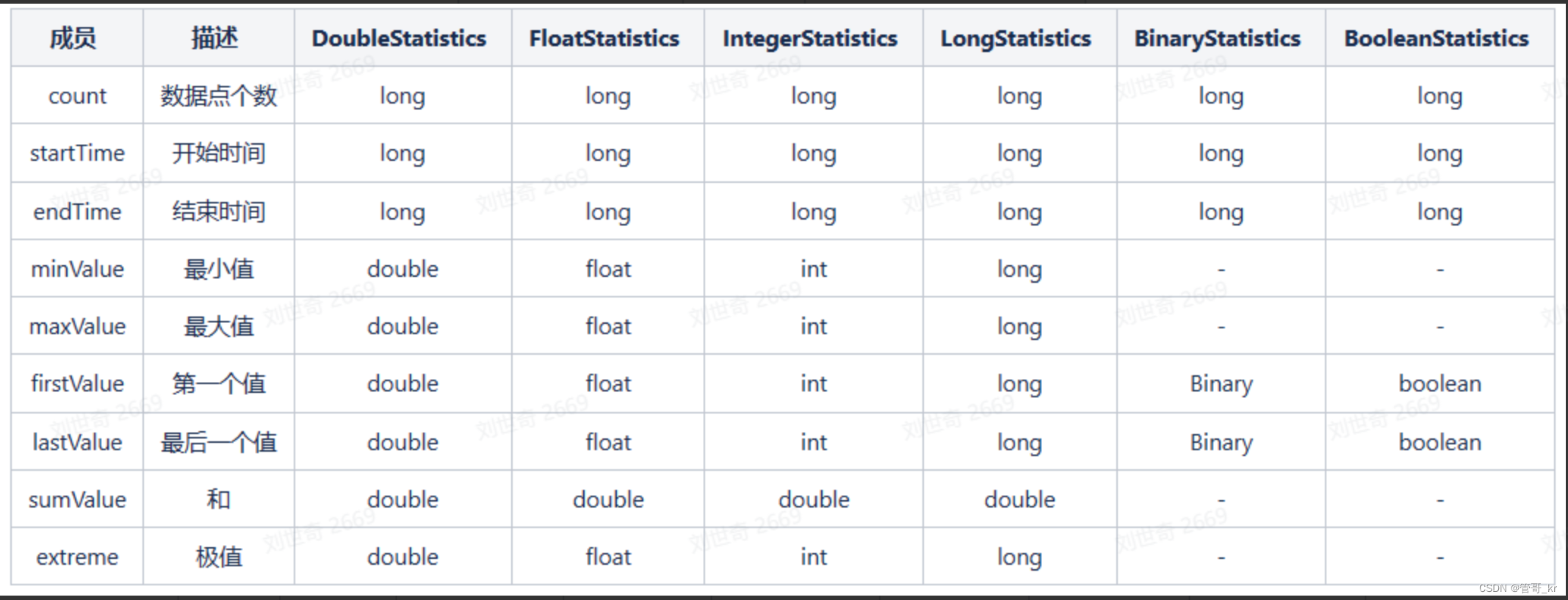
- statistics包含的信息如下图所示:
- Chunk
- 概念:一个 Chunk 存储了一个物理量(Measurement) 一段时间的数据,Chunk 内数据是按时间递增序存储的。Chunk 是由一个字节的分隔符 0x01、 一个 ChunkHeader 和若干个 Page 构成。
- ChunkHeader数据块头:
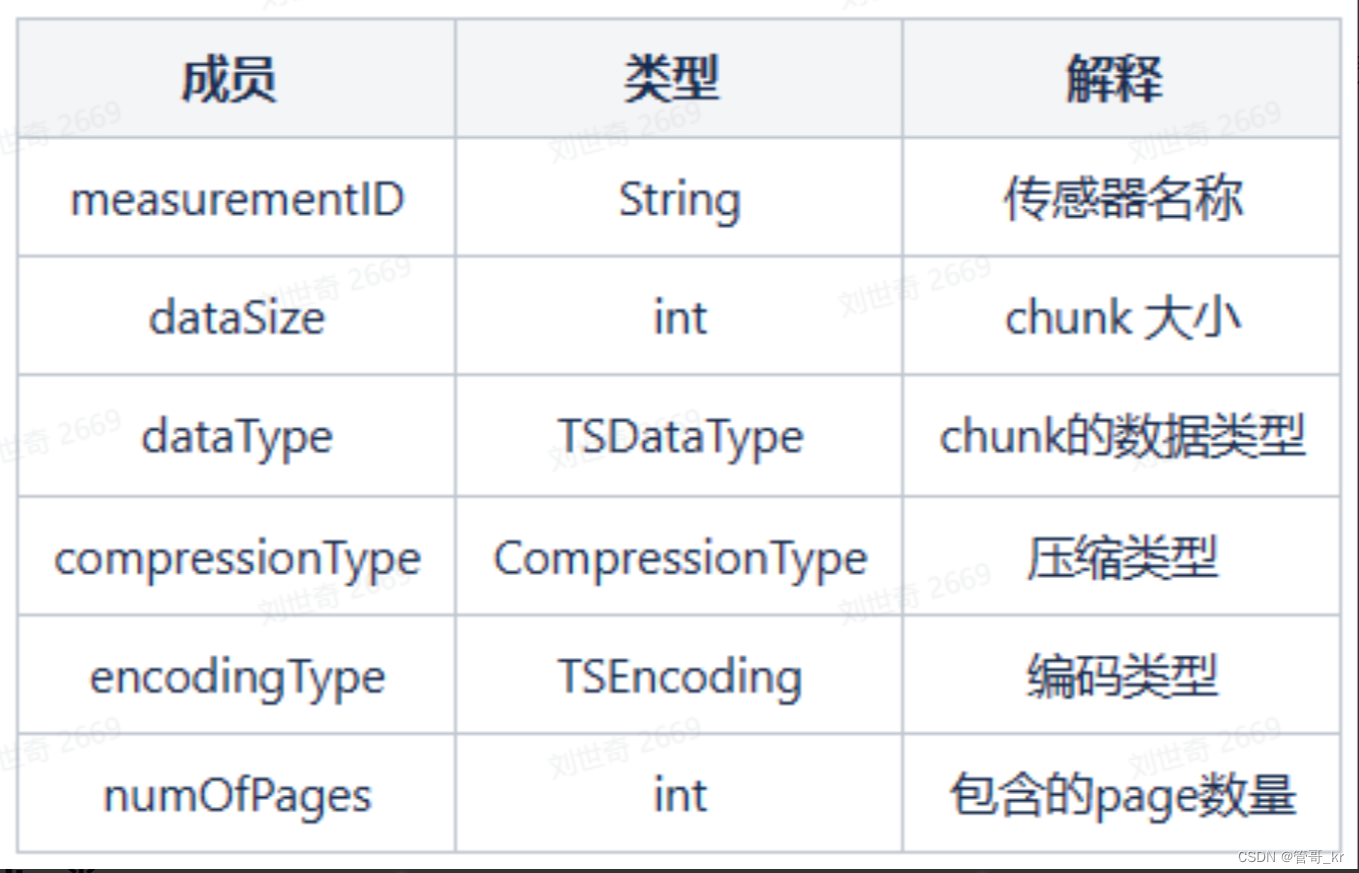
- ChunkGroup
- 包含一个实体的多个 Chunk。现在的版本中,没有ChunkGroupFooter,而是ChunkGroupHeader。
- Page
-
索引区
- 索引区整体是一个多级映射表,TsFileMetadata ==> IndexOfTimerseriesIndex Node ==> TimeseriesIndex ==> ChunkIndex ==> Chunk。
- TimeseriesIndex:它是时间序列索引,包含一个或多个ChunkMeta,即一个物理量的ChunkMeta列表
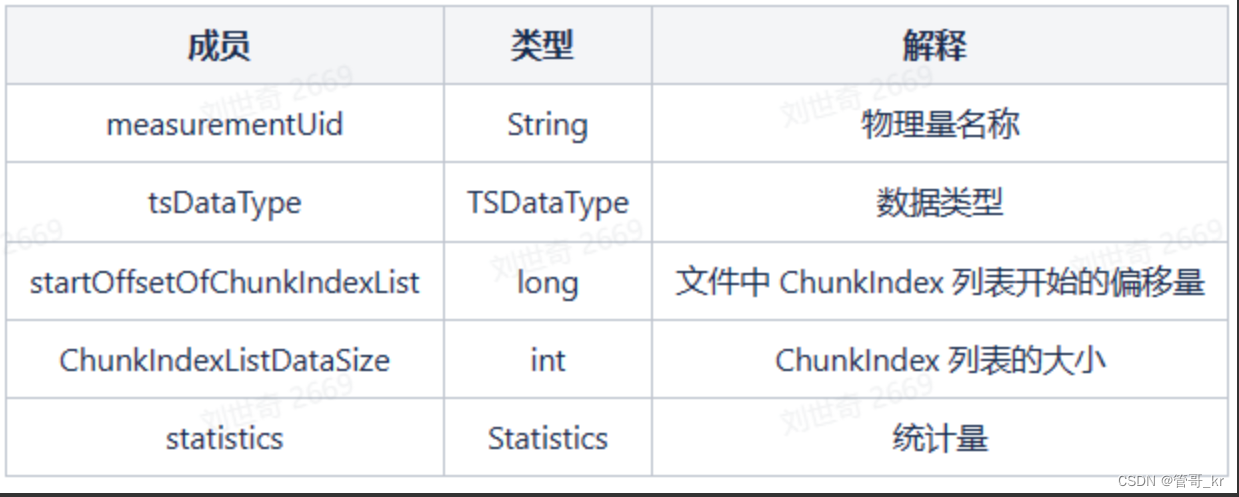
- 序列化到磁盘中时,这些成员都要写入磁盘。
- 它存储了一个物理量的多个Chunk的ChunkMeta,使用add_chunk_meta()函数进行收集ChunkMeta。
- IndexOfTimeseriesIndex:它是时间序列索引的索引(二级索引)
- BloomFilter:布隆过滤器用于判断一个元素是否存在于集合中。它通过使用位数组和一系列哈希函数来实现。它的核心思想是将每个元素映射到位数组中的多个位置,并将这些位置设置为1。当要判断一个元素是否存在时,将该元素经过相同的哈希函数映射到位数组上,如果所有对应位置都为1,则认为元素可能存在;如果至少有一个对应位置为0,则认为元素一定不存在。
-
心得体会
- 这一部分的学习相对而言是比较困难的,涉及到了许多没见过的名词,并且他们直接也有着较复杂的逻辑关系,即时有图片的辅助,理解起来也需要一定的功夫。之前所学的计算机组成原理和操作系统的基础知识对于理解TsFile的数据结构与索引起到了一定的帮助,能够相对容易地理解数据的不同单位和索引的多级索引。但对于一些更细化的数据块成员和函数的具体细节,我的水平有限,认知比较朦胧。
















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











