







一、研究背景和意义
国内生产总值(GDP)是宏观经济领域中最为关注的经济统计数据之一,它反映了一个国家或地区在一定时期内所创造的所有最终商品和服务的总价值。GDP的增长率不仅仅是一个国家经济健康状况的关键指标,还直接关系到国家的社会稳定和人民生活水平。因此,对GDP增长的因素进行深入研究具有极其重要的经济和政策意义。.....
二、理论部分
随机森林(Random Forest)是一种经典的Bagging模型,其弱学习器为决策树模型。如下图所示,随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型)或者投票(针对分类模型)情况来获取最终结果。
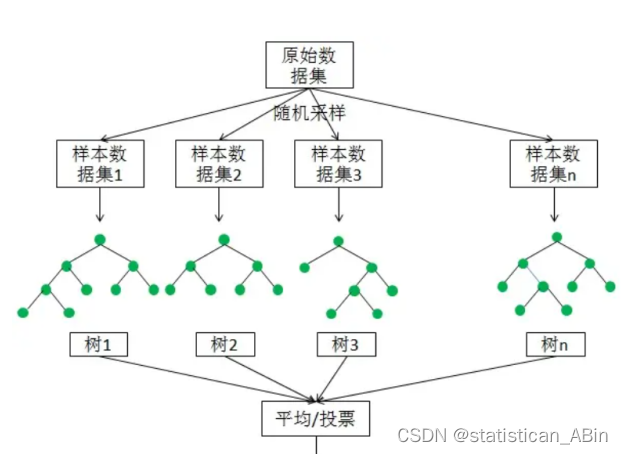
为了保证模型的泛化能力(或者说通用能力),随机森林在建立每棵树的时候,往往会遵循两个基本原则:数据随机和特征随机。
1.数据随机:随机地从所有数据当中有放回地抽取数据作为其中一棵决策树的数据进行训练。举例来说,有1000个原始数据,有放回的抽取1000次,构成一组新的数据(因为是有放回抽取,有些数据可能被选中多次,有些数据可能不被选上),作为某一个决策树的数据来进行模型的训练。
2.特征随机:如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征,在使用Python构造随机森林模型时,默认取特征的个数k是M的平方根。
随机森林在 bagging 的基础上,再次对特征做了一次随机选择,比如对于自助采样后的每一个子数据集(总共 m 个子数据集),我们并不会像决策数那样用到所有的特征,随机森林会从所有的特征中随机选择一个包含 k(k<n) 个特征的子集。当有一条新数据进来,在随机森林的 m 棵树会各自给出一个答案,如果是分类任务,我们就选择投票法,如果是回归任务则一般选择平均值作为输出。不像决策树,越靠近根节点的特征重要性越高,在随机森林中,在每个特征都是有可能成为 “主角” 的,也不容易出现过拟合的问题。
相比于单独的决策树模型来说,随机森林模型由于集成了多个决策树,其模型的预测会更加准确,且模型不容易造成过拟合的现象,模型的泛化能力增强。
三、实证分析
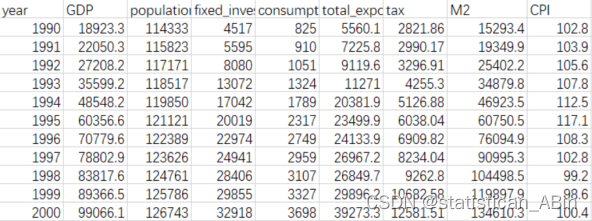
本文选取1990-2020年的GDP、税收等数据,数据为东方财务网爬取而得,其中包括人口(population),固定资产投资(fixed_investments),消费(consumption_level),净出口(total_export_import_volume),税收(tax),广义M2货币,物价指数(CPI),上述变量作为解释变量X,我国GDP作为被解释变量y。首先进行数据展示,如图所示。
library(readxl)
library(dplyr)
library(ggplot2)
library(openxlsx)读取数据

接下来进行统计性描述分析:

每个经济指标都包含了以下统计量:最小值(Min.)、第一四分位数(1st Qu.)、中位数(Median)、均值(Mean)、第三四分位数(3rd Qu.)和最大值(Max.)。例如:年份(year):数据集涵盖从1990年到2020年的时间范围。
GDP:最小值为18923,最大值超过了100万。
人口(population):最小值超过了11万,最大值为141万。....
接下来进行可视化
# 创建数据框
data <- data.frame(year = data1$year, GDP = data1$GDP)
# 绘制折线图s
ggplot(data, aes(x = year, y = GDP)) +
geom_line(color = "blue") +
labs(title = "GDP随时间变化的折线图", x = "年份", y = "GDP") +
theme_minimal()+
theme(plot.title = element_text(hjust = 0.5))
横轴代表年份,从1990年到2020年,纵轴代表GDP的值。从图中可以看出,GDP从1990年开始逐渐上升,到了2000年左右上升的速度加快,直到2020年,呈现出一个典型的指数增长趋势。
# 创建包含年份和固定投资的数据框
data_investments <- data.frame(year = data1$year, fixed_investments = data1$fixed_investments)
# 绘制柱状图
ggplot(data_investments, aes(x = factor(year), y = fixed_investments)) +
geom_bar(stat = "identity", fill = "purple") +
labs(title = "固定投资随年份的柱状图", x = "年份", y = "固定投资") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # 旋转 X 轴标签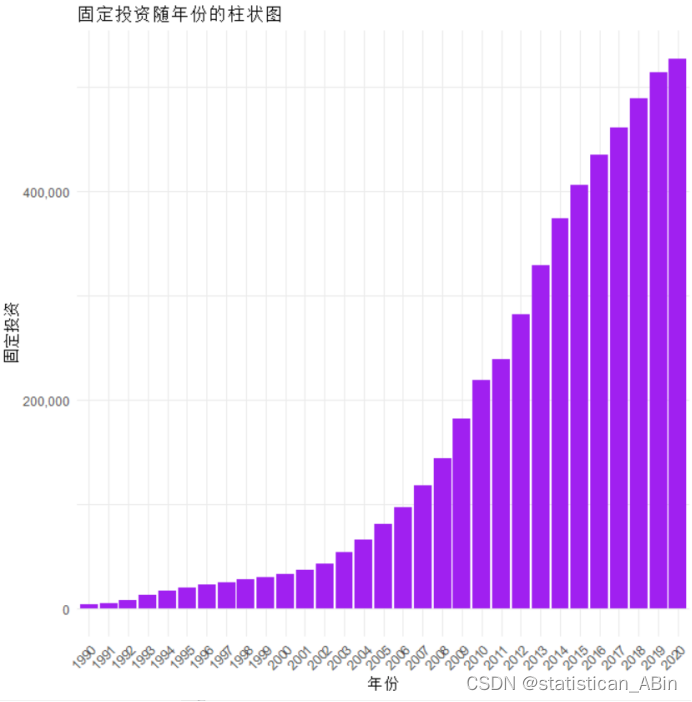 柱状图表明,在所示的时间范围内,固定投资的净值有显著的增长趋势,尤其在2000年之后增长速度加快,这可能反映了该地区或国家的经济发展和投资活动的增加。柱状图的增长趋势可以用来分析经济政策、市场情绪、资本支出的变化等多种经济因素。
柱状图表明,在所示的时间范围内,固定投资的净值有显著的增长趋势,尤其在2000年之后增长速度加快,这可能反映了该地区或国家的经济发展和投资活动的增加。柱状图的增长趋势可以用来分析经济政策、市场情绪、资本支出的变化等多种经济因素。
下面绘制热力图,相关性矩阵热图(Correlation Matrix Heatmap):用于显示不同特征之间的相关性
 从这张热图上可以看出,某些指标之间存在高度的正相关性,如M2和CPI在图中是黄色,这意味着它们的相关性较高。而其他如GDP与固定投资之间的相关性较低,因为它们的颜色是较深的蓝色。
从这张热图上可以看出,某些指标之间存在高度的正相关性,如M2和CPI在图中是黄色,这意味着它们的相关性较高。而其他如GDP与固定投资之间的相关性较低,因为它们的颜色是较深的蓝色。
随机森林模型预测
library(randomForest)
library(caret)
# 随机森林回归
X <- data1[, -1] # 选择除了第一列外的所有特征作为 X
y <- data1[, 1] # 选择第一列作为目标变量 y
# 数据标准化
preprocessParams <- preProcess(X, method = c("center", "scale")) # 标准化处理
X_s <- predict(preprocessParams, X) # 标准化后的特征
# 随机森林模型拟合和评价
model <- randomForest(x = X_s, y = y, ntree = 5000, mtry = trunc(ncol(X) / 3), importance = TRUE, na.action = na.omit)
# 输出模型评分
print(model) 总的来说,这个随机森林模型看起来在回归任务中表现出色,它使用了大量的树来进行预测,并且能够解释目标变量中大部分的方差,均方残差也相对较小,这表明它对数据的拟合效果很好。
总的来说,这个随机森林模型看起来在回归任务中表现出色,它使用了大量的树来进行预测,并且能够解释目标变量中大部分的方差,均方残差也相对较小,这表明它对数据的拟合效果很好。
后面可视化每个变量的重要性: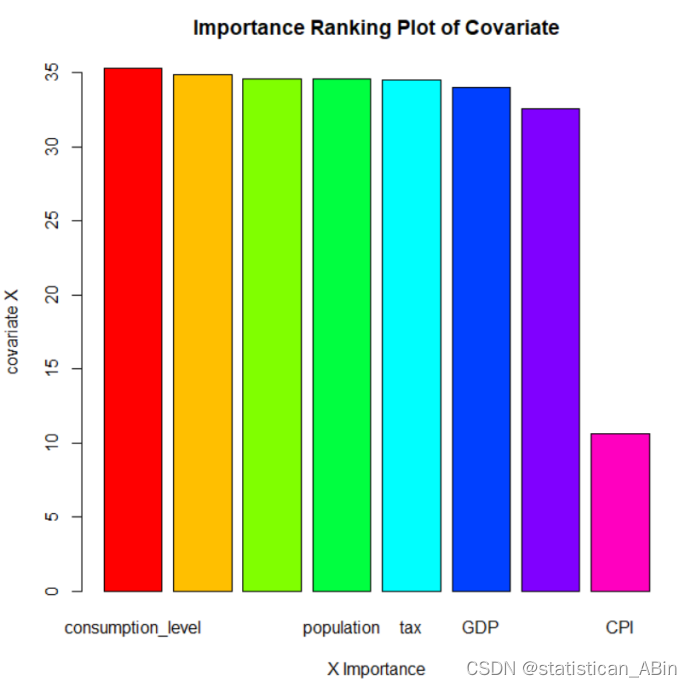
这张图片是一个柱状图,标题为“协变量的重要性排名图”。图中展示了几个经济指标对于某个模型或分析的相对重要性。具体指标包括消费水平(consumption_level)、人口(population)、税收(tax)、国内生产总值(GDP)和消费者价格指数(CPI)。每根柱子的长度代表了对应指标的重要性,重要性由柱子的高度来表示。
四、结论
在本研究中,我们运用随机森林模型对中国GDP增长的关键因素进行了深入分析,涵盖了1990年至2020年的数据。通过多个解释变量,建立了一个强大的回归模型,成功解释了99.19%的目标变量方差,且均方残差表现良好,随后也可视化了每个特征重要性,其中投资是最为重要的因素。
.....
创作不易,希望大家多点赞关注!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









