







Value at Risk(VaR)是一种统计技术,用于量化投资组合在正常市场条件下可能遭受的最大潜在损失。它是风险管理和金融领域中一个非常重要的概念。VaR通常以货币单位表示,用于估计在给定的置信水平和特定时间范围内,投资组合可能遭受的最大损失。例如,一个1%的一日VaR为$1百万意味着在任何给定的日子里,只有1%的概率投资组合的损失会超过100万美元。
选取一支你感兴趣的股票,画出最近一年的收益率时序图,并用R语言求该股票最近一年收益率的均值,方差和标准差
数据和BG
这里我选取的是googel的股票,使用dailyReturn函数算出它的收益率,前五行如下:
daily.returns
2023-08-15 -0.0100686499
2023-08-16 -0.0083217753
2023-08-17 0.0094794095
2023-08-18 -0.0189347291
2023-08-21 0.0071394947
接下来可视化:
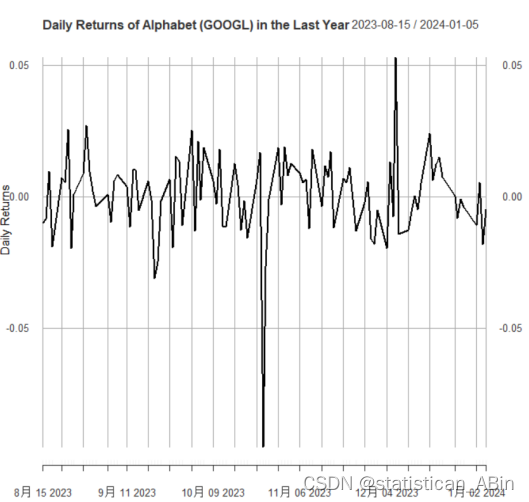
接下来分别使用mean,var,sd函数进行算出结果:
Mean of returns: 0.000487064370016916
Variance of returns: 0.000277345687220339
Standard deviation of returns: 0.0166536989050583
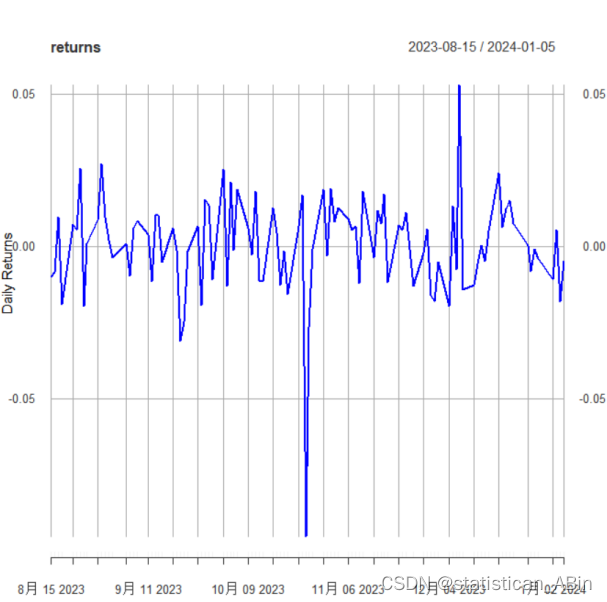
对该股票采用Weibul1分布法估计其180天周期90%置信水平的VaR序列(用前180天历史数据预测未来180天的日度VaR,并画出Va 时序图
90% 置信水平的 VaR: 0.0023112336283049
计算所有日期的 VaR并画图
另选一只股票,采用排序法计算其一年期 70%置信度的日度 VaR,若回测时次日跌幅超过 VaR 预测的闯值,则判定为一次“违约’。采用交易量、拆幅(最高价减最低价)和收益率MACDKDJOBVCCI等来预测违约估计 logit 模型,然后评价你的模型效果 (NP、ROC、CAP),并提出些可行改进方案。
这里选取的是APPLE的股票数据,设置API接口获取:
同样也是计算日度收益率,前5行如下:
daily.returns
2023-08-15 0.0000000000
2023-08-16 -0.0049591434
2023-08-17 -0.0145551339
2023-08-18 0.0028160920
2023-08-21 0.0077368331
计算采用排序法计算其一年期 70%置信度的日度 VaR,若回测时次日跌幅超过 VaR 预测的闯值,则判定为一次“违约’。写成相应的代码:
var_70 <- quantile(returns, 0.3) # 70%分位数即为VaR
default_event <- ifelse(returns < var_70, 1, 0)
default_event
default_event输出示例如下:
daily.returns
2023-08-15 0
2023-08-16 0
2023-08-17 1
2023-08-18 0
2023-08-21 0
接下来分别计算各个特征并且最终合并文件:
# 计算交易量
volume <- AAPL$AAPL.Volume
Volume
# 计算拆幅
range <- AAPL$AAPL.High - AAPL$AAPL.Low
Range
# 计算收益率
returns <- dailyReturn(AAPL$AAPL.Close)
returns
# 计算MACD指标
macd_data <- MACD(AAPL$AAPL.Close)
macd_data
# 将计算结果添加到数据框中
KDJ_data <- data.frame(Date = index(AAPL), K = K, D = D, J = J)(具体见源代码)
KDJ_data
# 计算OBV指标
AAPL$OBV <- OBV(AAPL$AAPL.Close, AAPL$AAPL.Volume)
AAPL$OBV
# 计算CCI,AAPL 是一个有效的时间序列对象,包含高、低、收盘价数据列
Hi <- AAPL$AAPL.High
Lo <- AAPL$AAPL.Low
Cl <- AAPL$AAPL.Close
cci_data <- CCI(cbind(Hi, Lo, Cl), n = 20, constant = 0.015)
cci_data
在特征处理完成之后,包括每个特征的缺失值、数据不平衡等等问题,将这几个特征合并到一个csv文件
最终数据合并如下:
| macd | signal | K | D | J | OBV | |
| 2023-08-15 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 43622593 |
| 2023-08-16 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -3342264 |
| 2023-08-17 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -69405146 |
| 2023-08-18 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -8232996 |
| 2023-08-21 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 38078883 |
| 2023-08-22 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 80163128 |
| CCI | Returns | macd.1 | macd_data | Volume | default_event | |
| 2023-08-15 | 15.587 | 0.000 | 0.502 | 0.607 | 43622593 | 0 |
| 2023-08-16 | 15.587 | -0.005 | 0.502 | 0.607 | 46964857 | 0 |
| 2023-08-17 | 15.587 | -0.015 | 0.502 | 0.607 | 66062882 | 1 |
| 2023-08-18 | 15.587 | 0.003 | 0.502 | 0.607 | 61172150 | 0 |
| 2023-08-21 | 15.587 | 0.008 | 0.502 | 0.607 | 46311879 | 0 |
| 2023-08-22 | 15.587 | 0.008 | 0.502 | 0.607 | 42084245 | 0 |
# 建立逻辑回归模型
model <- glm(default_event ~ ., data = train_data, family = "binomial")
model

Coefficients:这里列出了模型的系数估计值,每个变量对应一个。例如,macd 变量的系数估计值为 1.256e+01,而 signal 的系数为 7.701e+01。系数的正负号表示了该变量对响应变量的影响方向。正系数表示随着特征值的增加,响应变量的对数几率也增加(在二项逻辑回归中,对数几率是成功概率与失败概率的比值的自然对数),而负系数则表示对数几率减小。注意,有些变量旁边标有 NA,这通常表示这些变量因为多重共线性或其他原因从模型中被排除了。
# ROC 曲线和 AUC
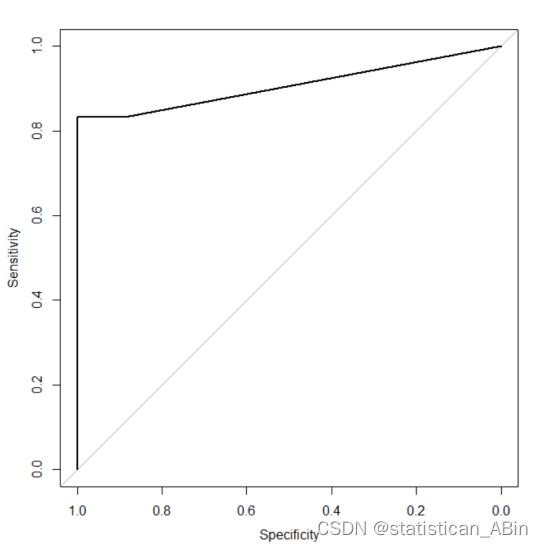
理想情况下,ROC 曲线会向左上角弯曲,靠近左上角的(0,1)点,这表明模型具有很高的真正例率和很低的假正例率。在这张图中,曲线开始时沿着 y 轴急剧上升,表明在低假正例率下模型能够实现相对较高的真正例率。总体而言,这个 ROC 曲线表明模型在某些阈值设置下对正类的预测有一定的准确性。
Area under the curve: 0.9074
曲线下面积(AUC)为 0.9074 表示模型具有很高的区分能力。
# 调用函数绘制 CAP 曲线
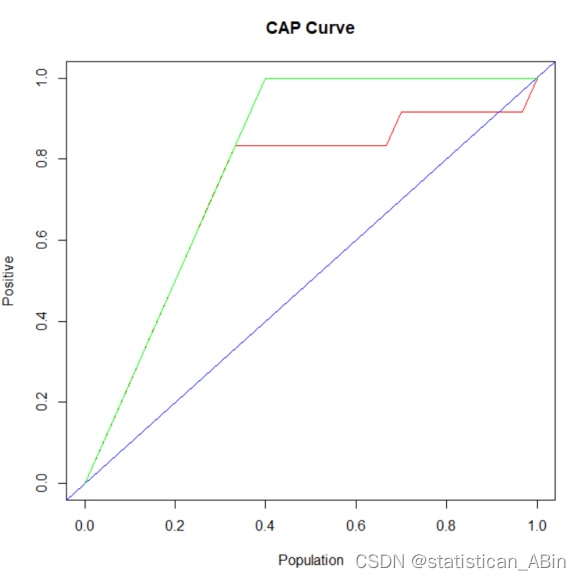
基于这些指标,以下是一些改进模型性能的策略:
数据重新采样:如果数据集不平衡,即违约和非违约的案例数量有很大差异,可以尝试过采样少数类别或欠采样多数类别。也可以使用合成数据生成技术,如 SMOTE,来合成新的正例。
特征工程:检查是否有可能从现有数据中创建更有信息量的特征。评估并可能移除对预测不具有统计显著性的特征。使用特征选择技术来识别和保留最重要的特征等....














 4328
4328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









