






目录
1. Gini系数: Gini系数是一种衡量不纯度的方法,它的定义如下:
2. 信息熵: 信息熵是另一种常用的不纯度度量,它用于评估数据集中信息的混乱程度。信息熵的定义如下:
3.信息增益:信息增益是决策树算法中的一个重要概念,用于帮助选择最佳特征来划分数据集,以最大程度地提高数据集的纯度。
引言
机器学习领域涵盖了众多强大的算法和模型,用于解决各种复杂的问题。决策树是其中一个备受欢迎的模型,因其出色的可解释性、灵活性以及在实际应用中的广泛应用而备受瞩目。
1. 决策树模型的简介
决策树是一种基于树状结构的监督学习模型,它可以应用于分类和回归问题。决策树的构建类似于人类在做决策时的思维过程:从根节点出发,沿着树的不同分支进行一系列决策,最终到达叶节点,得出最终的决策结果。这个过程使得模型易于理解,能够直观地展示特征对输出的影响。
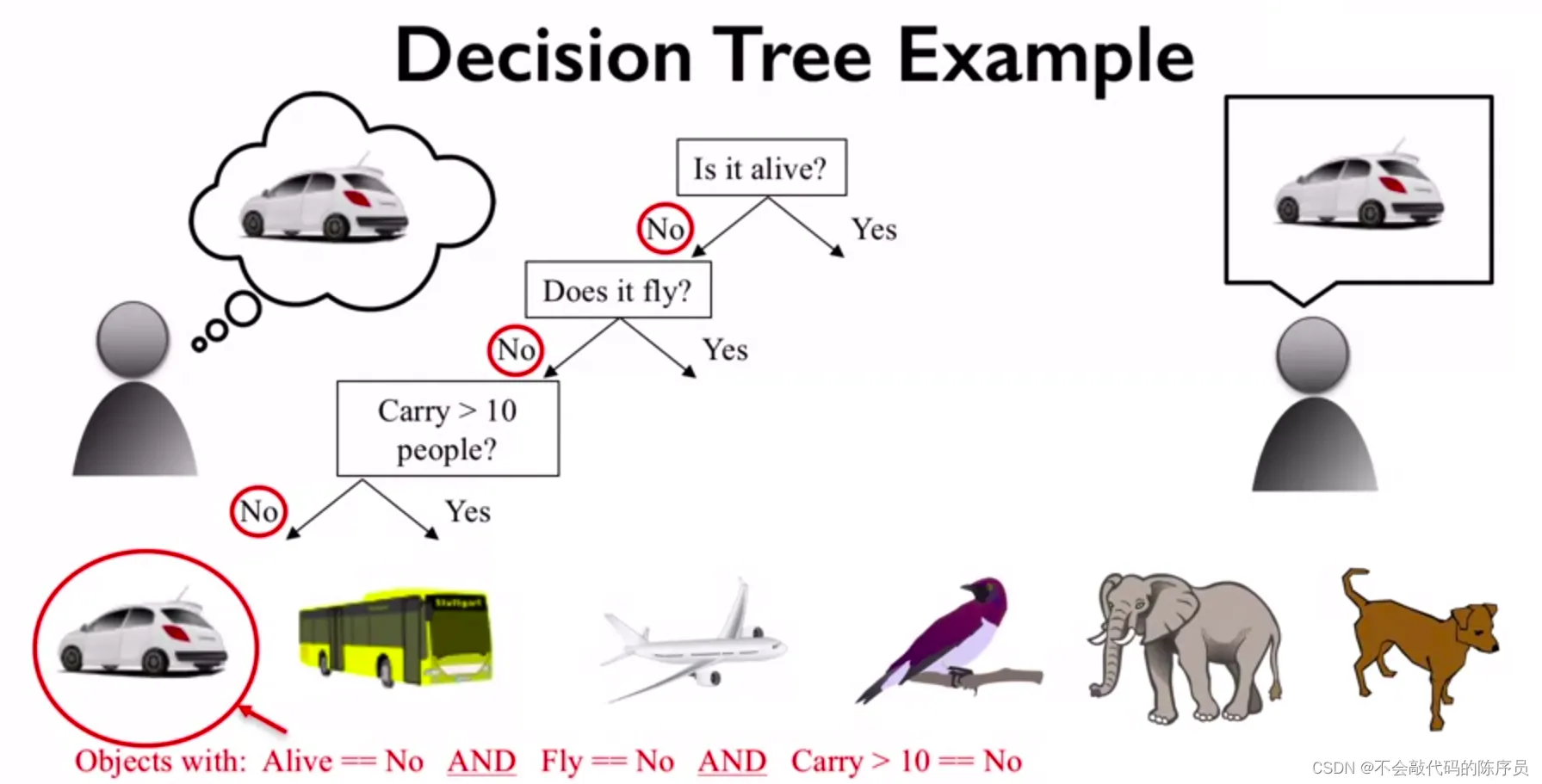
2. 决策树的应用场景和重要性
决策树在各种领域都有广泛的应用,包括但不限于以下领域:
- 医疗诊断:医生可以利用决策树来辅助诊断疾病,根据患者的症状和检查结果做出决策。
- 金融领域:银行和金融机构可以使用决策树来评估信用风险,制定信贷政策,并进行投资组合管理。
- 自然语言处理:决策树可用于自然语言处理任务,如情感分析、文本分类和语法分析。
- 工业生产:生产工厂可以使用决策树来优化生产过程,减少能源消耗和生产成本。
- 图像识别:决策树可用于图像识别和计算机视觉任务,如人脸识别和物体检测。
决策树模型的重要性在于其能够处理多类别分类问题、数值型数据、文本数据等多种数据类型,且在解释模型预测和特征选择方面非常强大。此外,决策树还可用于构建集成学习模型,如随机森林和梯度提升树,以进一步提高模型性能。
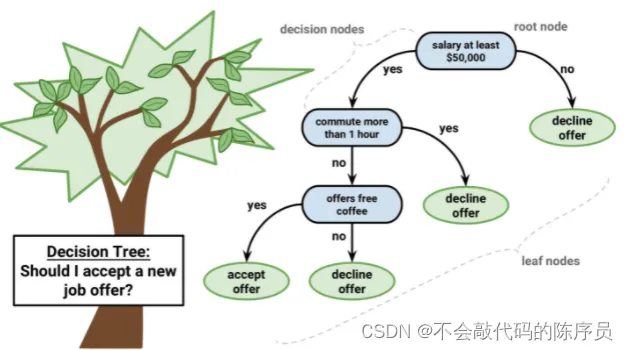
决策树的基本概念
决策树是一种树状结构的模型,它在机器学习领域具有广泛的应用。以下是决策树的基本概念:
1. 树状结构:
- 决策树是一种层次化的树状结构。树的顶部是根节点,最底部是叶节点,而中间的节点则表示决策规则。
- 节点和边:决策树由节点和边组成。节点代表了特征或属性,而边表示了特征值与不同节点的连接。
2. 决策规则:
- 每个节点代表一个特征或属性。在分类问题中,节点通常表示某一特征的取值范围,如年龄、性别等。在回归问题中,节点可以表示数值型特征。
- 边代表决策规则:每个节点通过边与下一个节点连接,表示了一种决策规则。这些规则根据输入特征的取值来确定下一个节点。
3. 叶节点:
- 叶节点是决策树的末端节点,代表了最终的决策结果。对于分类问题,叶节点通常代表一个类别标签;对于回归问题,叶节点则代表一个具体的数值输出。
4. 决策树的预测过程:
- 在预测过程中,从根节点开始,根据输入特征的取值沿着树的路径向下遍历。每个节点根据特征的取值选择对应的边,直到到达叶节点。
- 叶节点的值即为决策树的输出,可以是类别标签或数值。预测过程是根据特征的取值遍历树来确定输出值。
决策树的优势在于它的可解释性,用户可以清晰地了解每个决策是如何由特征决定的。这使得决策树成为了一种广泛应用于问题求解、数据分析和预测任务的机器学习模型。在实际应用中,决策树可用于分类、回归、特征选择和数据可视化等多个领域。
不纯度度量
在决策树中,不纯度度量是一种用于评估数据集纯度或杂质程度的方法,通常用于选择最佳分裂点以构建决策树。在这里,我们将详细介绍两种常用的不纯度度量:Gini系数和信息熵,以及它们与数据集纯度的关系。
1. Gini系数: Gini系数是一种衡量不纯度的方法,它的定义如下:
对于一个数据集,假设有 𝐾 个类别,每个类别的概率分别为 𝑝1,𝑝2,...,𝑝𝐾 ,则 Gini系数可以通过以下公式计算:
Gini(𝑝1,𝑝2,...,𝑝𝐾) = 1 - Σ(𝑝𝑖^2)
其中,Σ表示对所有类别的概率求和。Gini系数的取值范围在 0 到 1 之间,值越小表示数据集的纯度越高,值越大表示不纯度越高。
示例:假设一个数据集包含两个类别(是和否),分别占比 60% 和 40%。计算Gini系数如下:
Gini(0.6, 0.4) = 1 - (0.6^2 + 0.4^2) = 0.48
2. 信息熵: 信息熵是另一种常用的不纯度度量,它用于评估数据集中信息的混乱程度。信息熵的定义如下:
对于一个数据集,假设有 𝐾 个类别,每个类别的概率分别为 𝑝1,𝑝2,...,𝑝𝐾 ,则信息熵可以通过以下公式计算:
Entropy(𝑝1,𝑝2,...,𝑝𝐾) = -Σ(𝑝𝑖 * log2(𝑝𝑖))
其中,Σ表示对所有类别的概率求和。信息熵的取值范围也在 0 到 1 之间,与Gini系数一样,值越小表示数据集的纯度越高,值越大表示不纯度越高。
3.信息增益:信息增益是决策树算法中的一个重要概念,用于帮助选择最佳特征来划分数据集,以最大程度地提高数据集的纯度。
信息增益的计算公式如下:
IG(𝐷, 𝐴) = 不纯度(𝐷) - Σ(|𝐷𝑣| / |𝐷| * 不纯度(𝐷𝑣))
其中,IG表示信息增益,𝐷表示原始数据集,𝐴表示一个特征,𝐷𝑣表示根据特征𝐴分割出的子集,不纯度(𝐷𝑣)表示子集𝐷𝑣的不纯度,|𝐷𝑣|表示子集𝐷𝑣的样本数量,|𝐷|表示原始数据集的样本数量。
信息增益的计算过程分为以下几个步骤:
- 首先,计算原始数据集𝐷的不纯度,可以使用信息熵或Gini系数。
- 然后,对于每个特征𝐴,将数据集𝐷分割成若干子集𝐷𝑣,计算每个子集的不纯度(使用信息熵或Gini系数)。
- 最后,计算信息增益,它等于原始数据集的不纯度减去所有子集不纯度的加权和。
信息增益的计算帮助决策树算法选择最适合用于分割数据集的特征,因为信息增益越大,表示该特征能够更大程度地提高数据集的纯度,有助于决策树的构建。
决策树的构建算法
在决策树的构建过程中,我们需要考虑特征选择、分裂节点和剪枝这三个关键步骤。
1. 特征选择
特征选择是决策树构建的第一步,它决定了每个节点如何选择最佳特征来进行数据集的划分。通常,特征选择有两种常用的方法:信息增益和基尼不纯度。
-
信息增益:信息增益是决策树算法中最常用的特征选择方法之一。它是基于信息论的概念,用于度量一个特征对数据集纯度的提升程度。信息增益越大,表示选择该特征后数据集的纯度提高得越多。信息增益的计算过程已在前面的内容中详细介绍。
-
基尼不纯度:基尼不纯度是另一种用于特征选择的方法。它度量了从数据集中随机选择两个样本,它们类别不一致的概率。基尼不纯度越低,表示数据集的纯度越高。基尼不纯度的计算过程如下:
基尼(𝐷) = 1 - Σ(𝑝𝑖²)
其中,𝑝𝑖表示类别𝑖在数据集𝐷中的比例。
2. 分裂节点
一旦选择了最佳特征,下一步是分裂节点。分裂节点的目标是根据选定的特征将数据集划分成若干子集,每个子集对应一个分支。这个过程是递归的,每个分支又可以看作一个节点,继续选择最佳特征进行分裂,直到达到某个停止条件,如树的深度达到预定值或节点的样本数量小于某个阈值。
示例:假设我们选择了特征“年龄”来进行分裂,可以将数据集划分成多个子集,每个子集对应一个年龄段。
3. 剪枝
剪枝是决策树构建的最后一步,它用于解决过拟合问题。过拟合是指模型在训练数据上表现很好,但在未见过的数据上表现不佳的情况。剪枝的目标是简化决策树,减小决策树的复杂度,从而提高其泛化能力。
剪枝的方法和策略有很多种,包括前剪枝和后剪枝。前剪枝是在构建树的过程中,根据一些预定的条件提前终止树的分裂,例如限制树的最大深度或节点的最小样本数。后剪枝是在树已经构建完成后,根据一些条件来删除一些节点,将其合并为叶节点或删除整个子树。
剪枝是为了在保持决策树的预测能力的同时,减小其复杂性,提高模型的泛化能力。
决策树的代码实现
1. Scikit-Learn库
其中包含了现成的决策树模块,可以方便地构建和训练决策树模型。
首先,我们需要导入Scikit-Learn库并加载示例数据集:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
接下来,我们可以创建一个决策树分类器并进行训练:
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X, y)
这样,我们就构建了一个决策树模型并使用Iris数据集进行了训练。
用库实现的一个例子:
# 导入所需库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, export_text
import matplotlib.pyplot as plt
# 加载鸢尾花数据集作为示例数据
iris = load_iris()
X = iris.data
y = iris.target
# 创建决策树分类器
tree_classifier = DecisionTreeClassifier(random_state=42)
tree_classifier.fit(X, y)
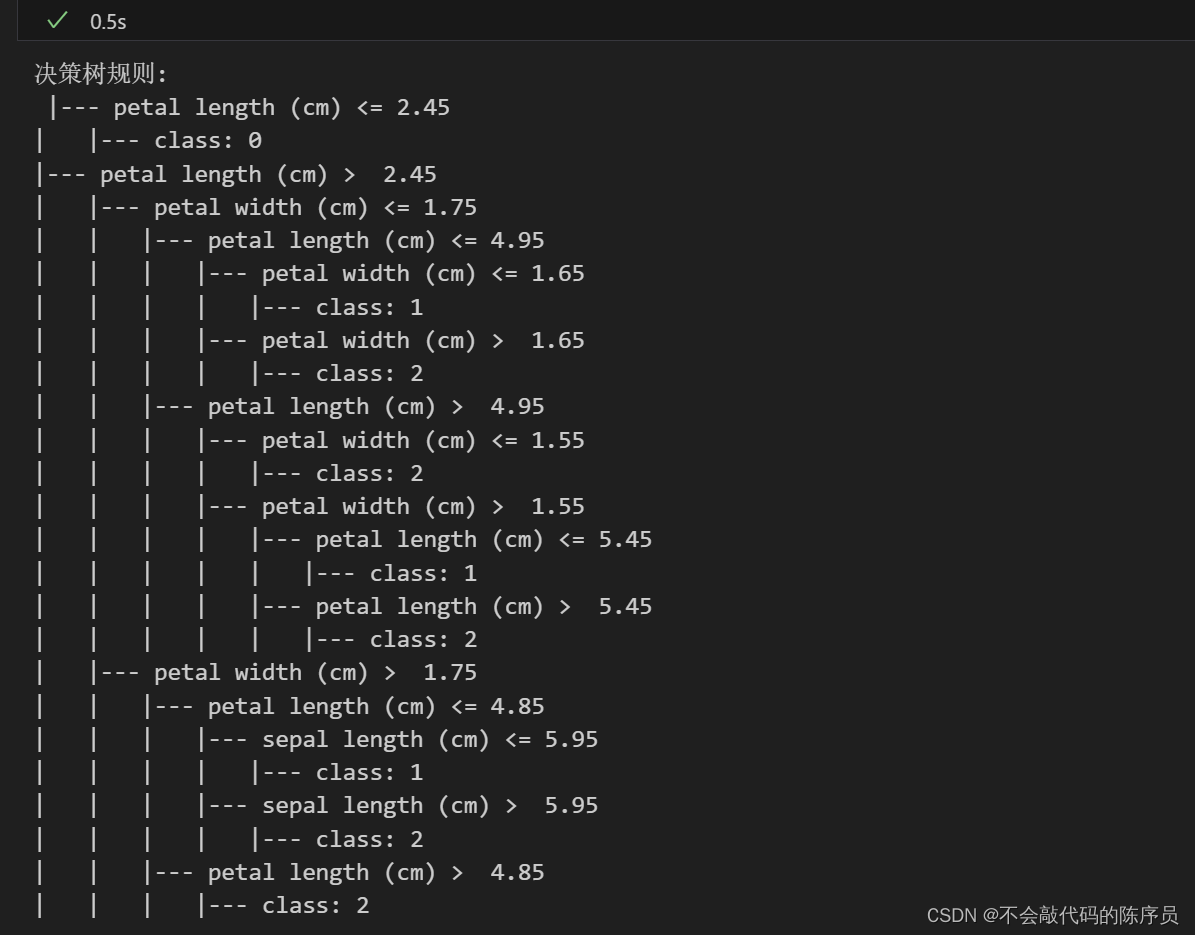
# 输出决策树的规则
tree_rules = export_text(tree_classifier, feature_names=iris.feature_names)
print("决策树规则:\n", tree_rules)
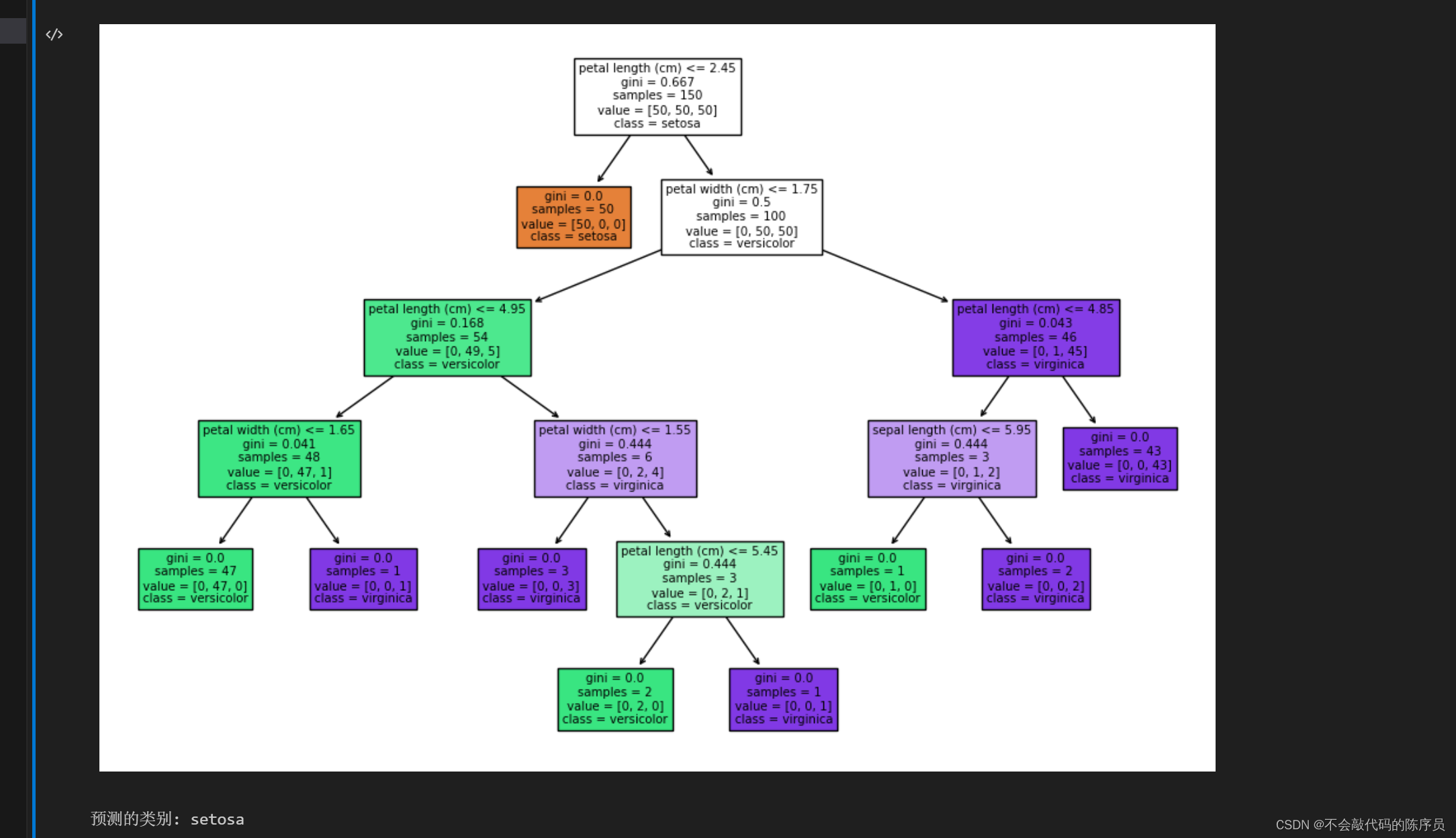
# 画出决策树
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 8))
plot_tree(tree_classifier, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
# 使用决策树进行预测
sample_data = [[5.1, 3.5, 1.4, 0.2]] # 用一个鸢尾花的特征作为示例
predicted_class = tree_classifier.predict(sample_data)
print("预测的类别:", iris.target_names[predicted_class][0])
2.Python实现
可以使用Python和NumPy库来实现,同时附上例子:
import numpy as np
class DecisionTree:
def __init__(self, max_depth=None):
self.max_depth = max_depth
self.tree = None # 添加tree属性
def fit(self, X, y):
self.tree = self._grow_tree(X, y)
def _grow_tree(self, X, y, depth=0):
n_samples, n_features = X.shape
n_labels = len(np.unique(y))
# 处理特殊情况:当标签为空时,返回一个叶节点
if n_labels == 0:
return Node(value=None)
if (
depth >= self.max_depth
or n_labels == 1
or n_samples < 2
):
leaf_value = max(set(y), key=list(y).count)
return Node(value=leaf_value)
best_feature, best_threshold = self._best_split(X, y)
if best_feature is not None:
left_mask = X[:, best_feature] <= best_threshold
X_left, y_left = X[left_mask], y[left_mask]
X_right, y_right = X[~left_mask], y[~left_mask]
left = self._grow_tree(X_left, y_left, depth + 1)
right = self._grow_tree(X_right, y_right, depth + 1)
return Node(feature=best_feature, threshold=best_threshold, left=left, right=right)
else:
leaf_value = max(set(y), key=list(y).count)
return Node(value=leaf_value)
def _best_split(self, X, y):
n_samples, n_features = X.shape
if n_samples <= 1:
return None, None
gini = self._gini(y)
best_gini = 1.0
best_feature, best_threshold = None, None
for feature_index in range(n_features):
feature_values = X[:, feature_index]
thresholds = np.unique(feature_values)
for threshold in thresholds:
left_mask = feature_values <= threshold
y_left = y[left_mask]
y_right = y[~left_mask]
gini_left = self._gini(y_left)
gini_right = self._gini(y_right)
gini = (len(y_left) * gini_left + len(y_right) * gini_right) / (len(y_left) + len(y_right))
if gini < best_gini:
best_gini = gini
best_feature = feature_index
best_threshold = threshold
return best_feature, best_threshold
def _gini(self, y):
m = len(y)
return 1.0 - sum((np.sum(y == c) / m) ** 2 for c in np.unique(y))
class Node:
def __init__(self, feature=None, threshold=None, value=None, left=None, right=None, gini=None): # 添加gini属性
self.feature = feature
self.threshold = threshold
self.value = value
self.left = left
self.right = right
self.gini = gini # 存储Gini不纯度
# 在 _grow_tree 函数中设置 gini 值
def _grow_tree(self, X, y, depth=0):
# ...
if best_feature is not None:
# ...
left = self._grow_tree(X_left, y_left, depth + 1)
right = self._grow_tree(X_right, y_right, depth + 1)
best_gini = self._gini(y) # 计算 Gini 不纯度
return Node(feature=best_feature, threshold=best_threshold, left=left, right=right, gini=best_gini)
else:
leaf_value = max(set(y), key=list(y).count)
return Node(value=leaf_value, gini=0.0) # 对于叶节点,Gini 不纯度设置为 0.0
X = np.array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3.0, 1.4, 0.2],
[6.2, 2.2, 4.5, 1.5],
[6.7, 3.1, 4.7, 1.5],
[6.7, 3.1, 5.6, 2.4],
[4.6, 3.6, 1.0, 0.2],
[5.7, 4.4, 1.5, 0.4]])
y = np.array([0, 0, 1, 1, 2, 0, 1]) # 修改标签以避免空标签
# 创建决策树并训练
tree = DecisionTree(max_depth=3)
tree.fit(X, y)
def print_tree(node, depth=0):
if node.feature is not None:
print(" " * depth + f"Feature {node.feature} <= {node.threshold}, Gini={node.gini}")
print_tree(node.left, depth + 1)
print(" " * depth + f"Feature {node.feature} > {node.threshold}, Gini={node.gini}")
print_tree(node.right, depth + 1)
else:
print(" " * depth + f"Class {node.value}")
print_tree(tree.tree)

总结
机器学习是一门苦差事,需要学习的内容是相当的多。只能寄托于现有的工具尽量可能夺地去收集资料并学习好这门课程。















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









