






目录
一、算法定义
K最近邻(K-Nearest Neighbors,KNN)算法是一种用于分类和回归的监督学习算法。
KNN算法的主要思想可以简单概括如下:
-
训练阶段:在训练阶段,KNN算法将所有的训练样本和它们对应的标签存储在内存中,构建一个训练数据集。
-
预测阶段:在预测阶段,对于一个新的输入样本,KNN算法会计算该样本与训练数据集中每个样本的距离(通常使用欧氏距离或其他距离度量),然后选择与该样本距离最近的K个训练样本。
-
分类任务:对于分类任务,KNN算法会统计这K个最近邻样本中每个类别的出现次数,并将新样本分为出现次数最多的类别。这就是所谓的"K近邻投票法"。
-
回归任务:对于回归任务,KNN算法会取K个最近邻样本的标签值的平均值,作为新样本的预测值。
KNN算法性能:
KNN算法的关键参数是K值,它表示在预测阶段选择多少个最近邻样本。选择不同的K值可能会影响算法的性能。
通常情况下,K值的选择是根据具体问题和数据集来调整的。
其算法参数是k,参数选择需要根据数据来决定。
k值越大,模型的偏差越大,对噪声数据越不敏感,当k值很大时,可能造成欠拟合;
k值越小,模型的方差就会越大,当k值太小,就会造成过拟合。
欠拟合和过拟合
-
欠拟合(Underfitting):
- 欠拟合发生在模型过于简单,无法捕捉数据中的复杂关系时。简单模型通常具有较少的参数或较低的复杂度。
- 欠拟合的模型在训练数据上表现不佳,其训练误差和测试误差都较高。
- 欠拟合意味着模型没有学习到数据中的趋势和规律,通常是由于模型过于简单或特征选择不当造成的。
- 解决欠拟合的方法包括增加模型复杂度(例如增加神经网络的层数或多项式特征的次数)、选择更好的特征、增加数据量等。
-
过拟合(Overfitting):
- 过拟合发生在模型过于复杂,试图在训练数据上拟合噪声或随机变化时。复杂模型通常有较多的参数或较高的复杂度。
- 过拟合的模型在训练数据上表现得非常好,但在未见过的测试数据上表现不佳,测试误差远高于训练误差。
- 过拟合意味着模型过度记忆了训练数据中的噪声,而没有学到数据的真实规律,通常是由于模型复杂度过高、数据量不足或特征选择不当造成的。
- 解决过拟合的方法包括减小模型复杂度(例如降低神经网络的层数或减少多项式特征的次数)、增加更多的训练数据、使用正则化技巧(如L1正则化、L2正则化)来限制模型参数的大小、采用更好的特征选择方法等。
欠拟合和过拟合是模型泛化能力的两个极端。理想情况下,我们希望模型能够在训练数据上学到足够的信息以适应数据,同时不过度拟合噪声和随机性。要找到合适的模型复杂度和采取适当的预处理和正则化方法,以在训练和测试数据上都获得好的性能。
KNN算法优缺点
KNN算法的优点包括简单易懂、容易实现、对异常值不敏感等。
然而,它也有一些缺点,例如在处理大规模数据集时计算开销较大,对数据分布的假设较弱,需要合适的距离度量方法和特征缩放。
二、算法原理
算法通俗解释
K最近邻(KNN)算法的核心思想就像是找朋友一样。假设你不认识一个人,但你知道一些你的朋友,你想知道这个陌生人是什么类型的人。KNN的想法是,看看附近的K个朋友,如果大多数都是“好人”,那么这个陌生人可能也是“好人”,如果大多数都是“坏人”,那么这个陌生人可能也是“坏人”。
KNN根据陌生人与你的朋友们的相似度来判断陌生人的类型。首先,计算陌生人与每个朋友的相似程度(距离),然后找出与陌生人最近的K个朋友。如果这K个朋友中大多数是某种类型的,那么就认为陌生人也是那种类型。
KNN中的K是一个数字,它决定了要考虑多少个朋友来帮助判断。选择不同的K值可能会导致不同的判断结果。比如,如果K=3,就是找附近的3个朋友,如果K=5,就是找附近的5个朋友。
假设X_test为待找的好朋友,X_train为已找到的好朋友,算法原理的伪代码如下:
遍历X_train中的所有朋友,计算每个样本与X_test的相似程度(距离),并把距离保存在Distance数组中。
对Distance数组进行排序,取距离最近的k个点,记为X_knn。
在X_knn中统计每个类别的个数,即class0在X_knn中有几个样本,class1在X_knn中有几个样本等。
待标记样本的类别,就是在X_knn中样本个数最多的那个类别。
参考博客:https://blog.csdn.net/qq_25990967/article/details/122748881
算法的公式
K最近邻(KNN)算法主要涉及到两个公式:
-
距离度量公式:用来计算两个数据点之间的距离,常用的距离度量方法包括欧氏距离和曼哈顿距离。这两种距离的公式如下:
-
欧氏距离
如果有两个数据点 A 和 B,其中 A = (a1, a2, ..., an),B = (b1, b2, ..., bn),那么它们之间的欧氏距离可以表示为:
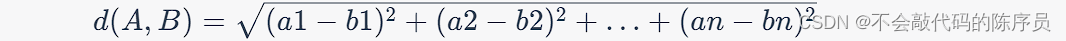
-
曼哈顿距离
曼哈顿距离是在一个坐标系中,两点之间的距离是各个坐标数值差的绝对值的和。如果有两个数据点 A 和 B,那么它们之间的曼哈顿距离可以表示为:
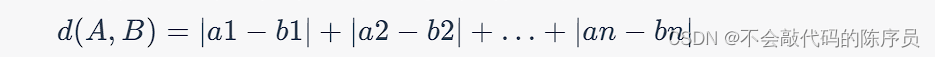
-
-
投票决策公式:用来决定一个未标记数据点的类别。KNN算法通过找到离该数据点最近的K个已标记数据点,然后对这K个数据点所属的类别进行投票,最终以票数最多的类别作为该数据点的预测类别。
如果有K个最近邻的数据点,分别属于不同的类别(假设有C个不同的类别),那么预测的类别可以通过以下公式确定:
预测类别 = 众数(K个最近邻的类别)
这些公式是KNN算法的核心。距离度量公式用来衡量数据点之间的相似度,而投票决策公式用来根据相似度来预测未标记数据点的类别。选择合适的距离度量方法和K值是KNN算法中的关键因素。
三、算法实现与应用
目标旨在对Pina印第安人的糖尿病进行预测。数据集引用自链接:蓝奏云。
模型搭建思路
首先读取数据集,然后对数据集进行预处理,获取该数据集的标签。在该模型中,我首先选择对特征进行归一化处理,使用StandardScaler对特征进行标准化处理,让各个特征对模型的影响权重相等。其次我使用train_test_split函数将该数据集分为训练集和测试集方便训练模型,然后,我创建一个KNN分类器对象,通过设置超参数K的值来指定使用多少个最近邻来进行分类。在这里,K被设置为5。最后,通过建立的KNN分类器对象训练划分好的数据集,得出最后结果。
KNN算法模型源码
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 读取数据
data = pd.read_excel(r'C:\Users\admin\Downloads\knn.xlsx', engine='openpyxl')
print(data)
# 获取特征和标签
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 特征归一化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化KNN分类器
knn = KNeighborsClassifier(n_neighbors=5) # 这里选择K=5
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
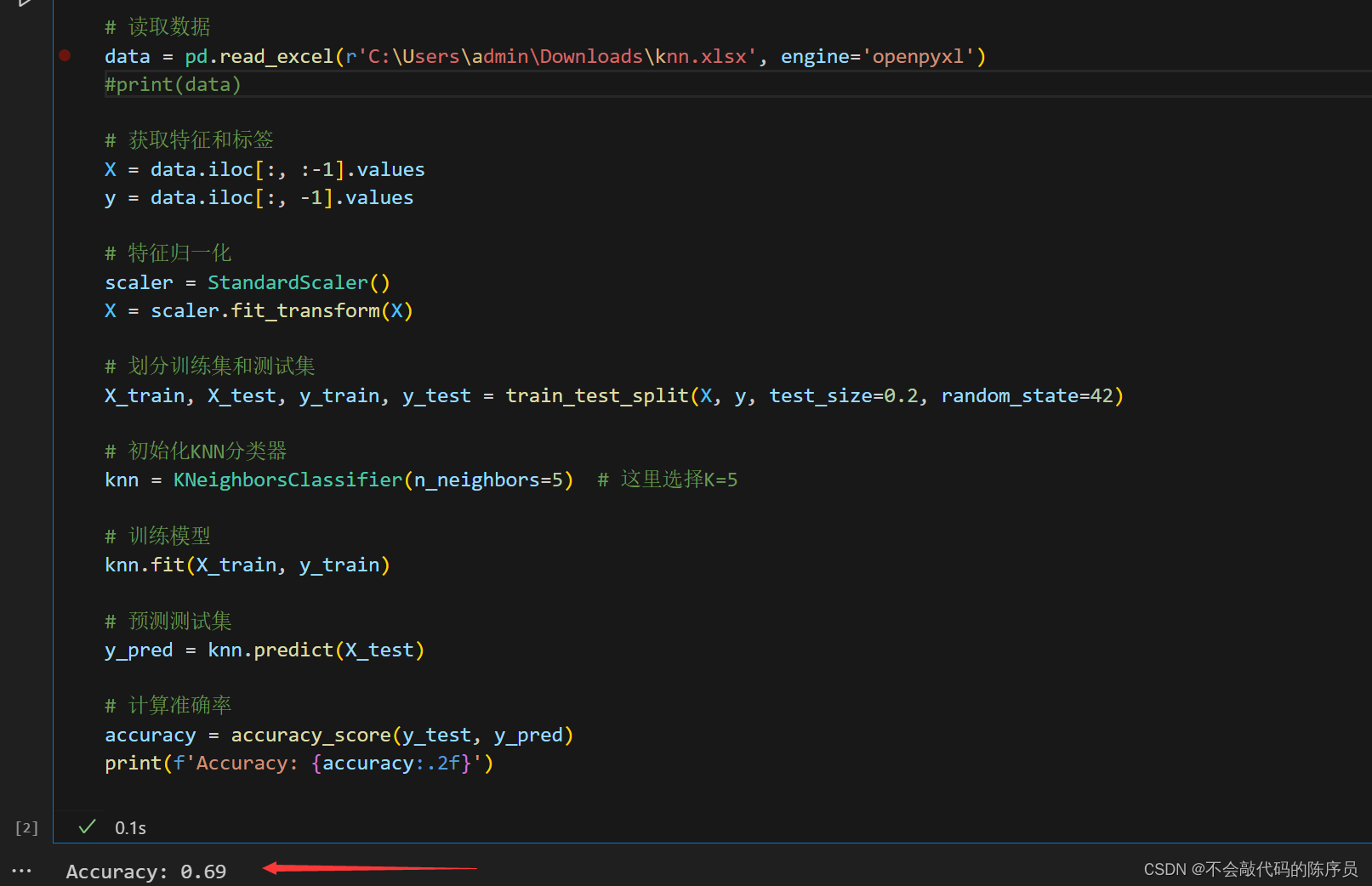
print(f'Accuracy: {accuracy:.2f}')代码运行效果图
四、总结
KNN算法是机器学习的入门算法,是我学到的第一个监督学习算法,用于分类和回归问题。它基于实例的学习方法,其中模型不会显式地学习数据的内部结构,而是存储训练数据,然后使用它们来进行预测。已经能够感觉到机器学习的头疼之处了!欢迎各位读者提出意见!

















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









