









线性回归(Linear regression)
首先,先来了解一下,监督学习算法是如何工作的。
首先向学习算法提供训练集,而学习算法的任务就是输出一个函数,用h表示。
h代表假设函数(hypothesis),该函数的作用是通过输入的值x来预测值y,即h是x到y的一个映射,如下图所示。

那我们该怎么表示h呢?
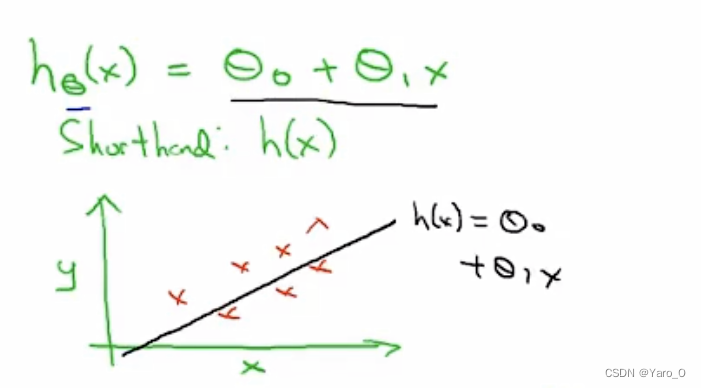 h是一个线性函数,而这个模型被称为线性回归
h是一个线性函数,而这个模型被称为线性回归
如何让数据与线性回归函数更加拟合呢?(2-2)
代价函数(平方误差函数)

要得到最拟合的线性回归方程,就是要找到使预测值h(xi)和实际值yi的差最小的Θ0和Θ1。
注意:这个代价函数是针对线性回归方程的,对于求解其他问题,可寻找更加合理的代价函数
代价函数的作用(2-3)
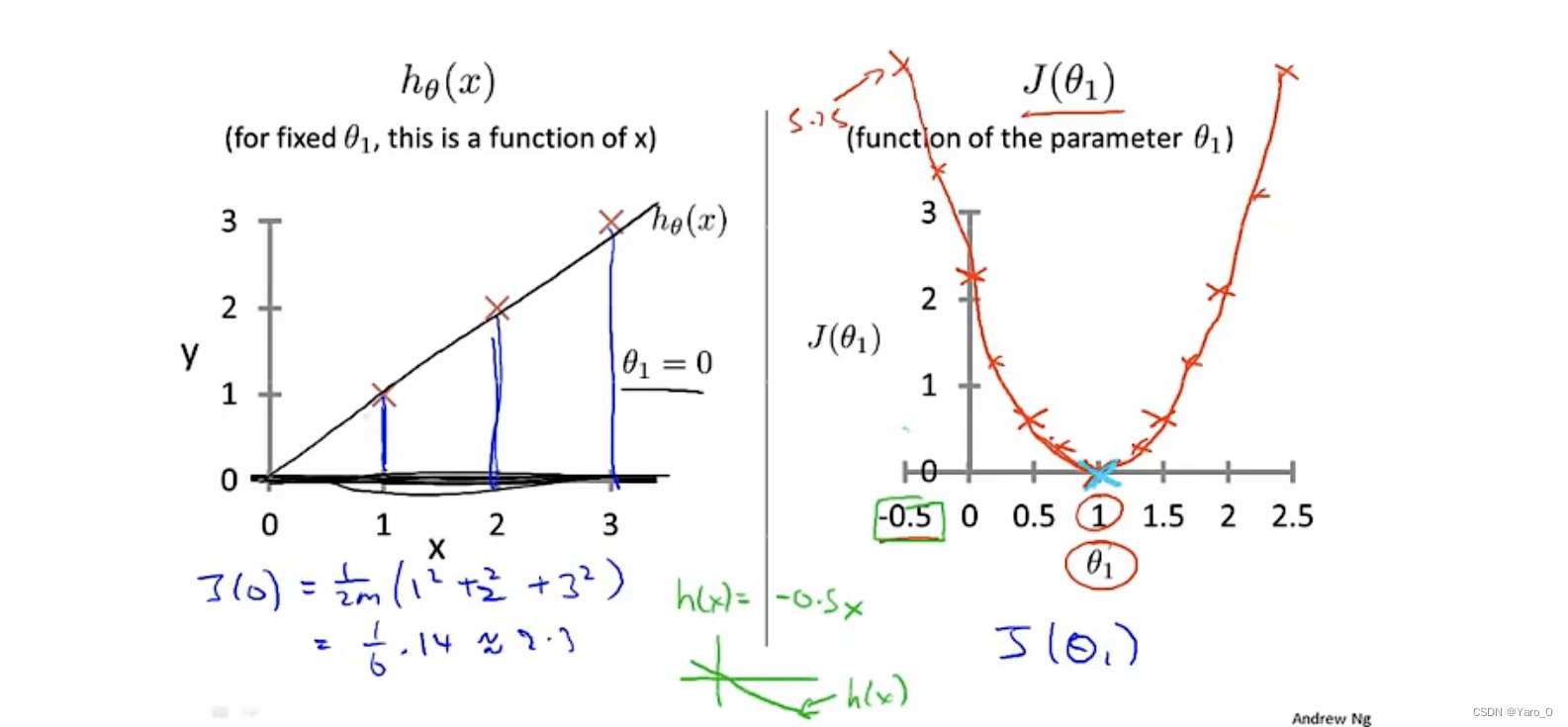
为了更好地可视化,在上图中,另Θ0等于0,则h(x)是一条经过原点的直线。
通过不断改变Θ1的值,计算J(Θ1),得到右图图像,可观察到J(Θ1)呈现的图像是先上升后下降,最低点的Θ1即为最合适的Θ1。
如果Θ0不等于0呢?

梯度下降算法(Gradient descent)(2-5/2-6)
作用:可以将代价函数J最小化(同样也可以最小化其他任意函数)
思路(以J(Θ0,Θ1)为例):
1、初始化Θ0,Θ1;
2、不停地一点点改变Θ0、Θ1,来使J(Θ0,Θ1)变小,直到找到局部最小的J(Θ0,Θ1)
用图像直观理解
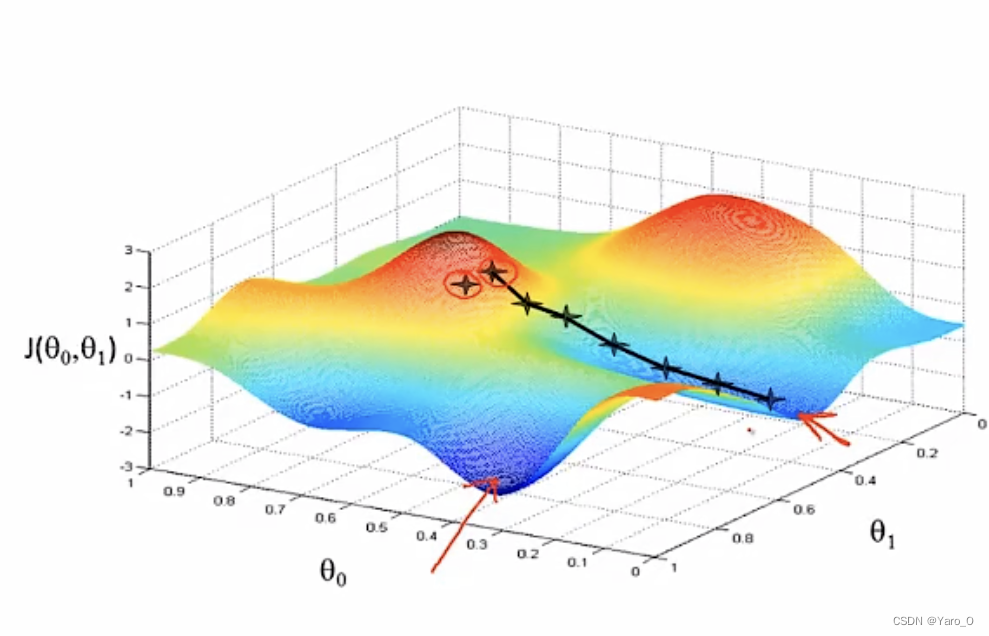
在某一点,360°环绕后寻找下降最快的点,并往那个方向移动一小步,重复进行该步骤,直到找到局部最优解。
数学原理:

(1):= 表示赋值,把右边的值赋给左边
(2) α:学习率(learning rate),用来控制梯度下降时,我们迈出多大的步子,即如果 α很大,梯度下降就很迅速;
注意:α不能太小也不能太大。
如果太小的话,梯度下降可能会很慢,很多步才能到达局部最低点;
如果太大的话,梯度下降时可能会略过局部最低点,甚至可能无法收敛或发散
(3)导数项;
注意:如果参数已经在局部最优解,由于此处偏导数为0 ,所以下一次不会再发生改变;
随着越来越靠近局部最优解,移动的幅度会越来越小,因为偏导数的绝对值会越来越小,直到偏导数为0,找到局部最低点。
(4)Θ0,Θ1需要同步更新,不能得出temp0之后就更新Θ0,否则你带入第二个式子中的Θ0也是新的值,不符要求。
Batch梯度下降:每一次梯度下降都要使用整个训练集的数据















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









