







本文章对CV深度学习的模型做简单的概述,主要目的是了解各模型的特点及模型与模型之间的区别。
模型概述顺序:(AlexNet) —— vgg —— ResNet —— DenseNet —— Res2Net —— Transformer —— VIT —— MAE —— CLIP —— SAM —— DINO
注意:AlexNet之前已经重点介绍过,因此在这篇文章中不再缀述,想了解的可以查看之前文章)
1 vgg模型
1.1 vgg概述及优点
- VGGNet突出贡献是证明了很小的卷积,通过增加网络深度可以有效提高性能;
- 小卷积核组:通过堆叠多个3*3的卷积核来替代大的卷积核,以减少所需参数;全部使用3x3卷积核,不仅会涉及到计算量,还影响到感受野。在VGG中,使用3个3x3卷积核来替代7x7卷积核,主要目的是保证在具有相同感受野的条件下,提高网络深度,一定程度上提升神经网络的效果。
那么什么是感受野呢?
感受野,简单理解是输出Feature Map上的一个神经元对应输入层的区域大小。
举例说明,如下图所示,最左边的图,使用三次3x3的卷积后,更改最后一层的节点将会影响第一层的所有节点;而最右边的图,同理,使用一次7x7的卷积后,更改最后一层的节点将会影响到第一层的所有节点。
因此:3个cov3与一个conv7最终得到结果的感受野相同
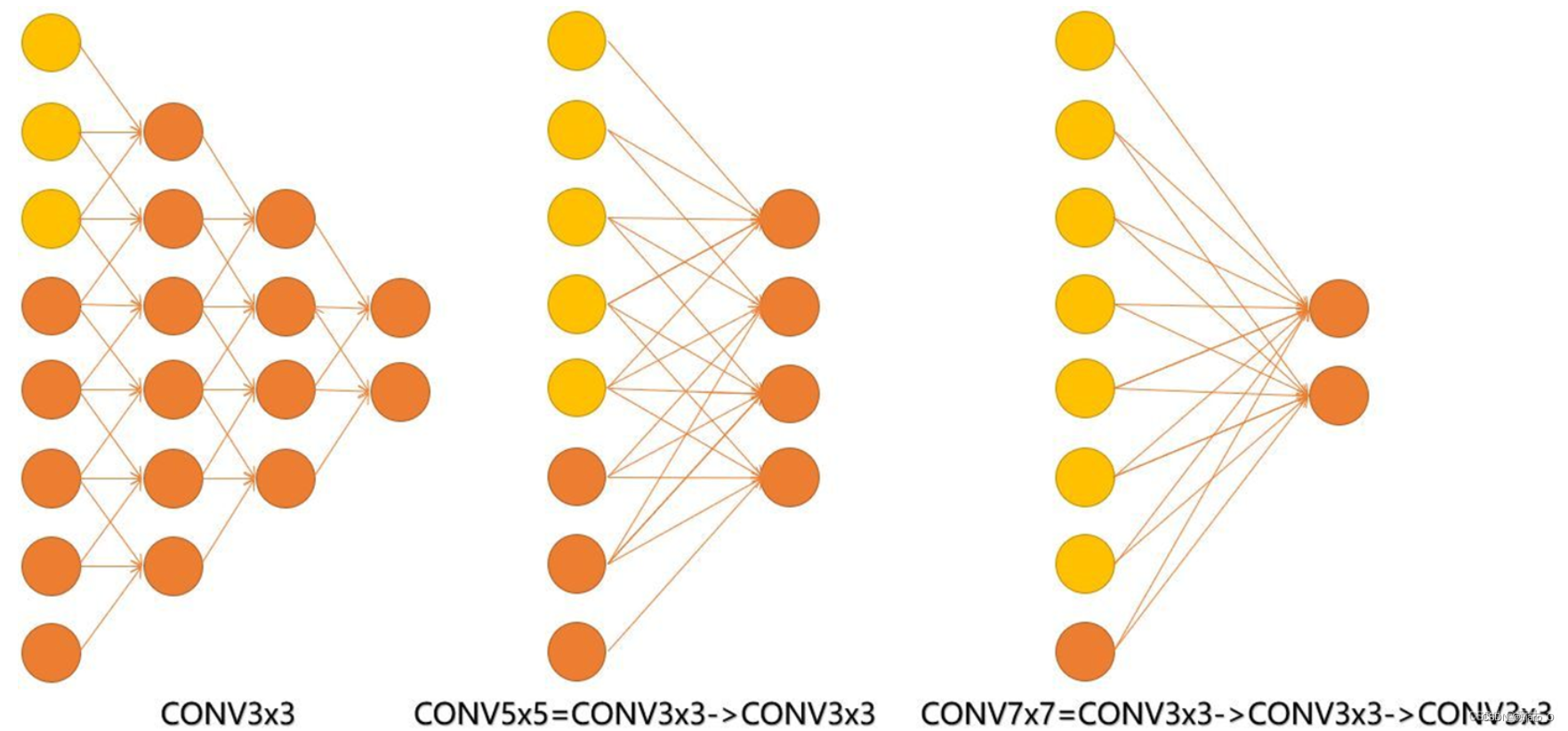
如何影响计算量、参数量的呢?
计算参数量的公式为:
params = (kernel_size kernel_size channel_in+1)* channel_out**
由于在实验中用三层3x3卷积代替一层7x7卷积。在输入通道数in和输出通道数out一致的情况下,参数量分别是(27in+3)out和(49 in+1) out。
-
小池化核:vgg使用的池化核大小为22,而在AlexNet中使用的是33的池化核;
-
去掉LRN层:在AlexNet中,加入了LRN(局部响应归一化)来优化模型,但在vgg中,作者发现LRN层作用不明显,因此去掉。
1.2 vgg缺点
- 全连接层神经元多,因此参数量大,计算量大,训练耗时;
- 占用内存大
1.3 vgg结构
- 作者利用控制变量的思想,进行了六次实验,最终得到了分类结果最好的两个模型——vgg16和vgg19
- 作者进行的六次实验如下图所示:

对于以上A、A-LRN、B、C、D、E六组实验,分析可得:
A-LRN组在A组基础上增加了LRN,结果发现增加LRN后并无明显变化,因此在VGG中去掉LRN;
B组在A组的基础上增加了2个cov3,即多加了两个3x3的卷积核
C组在B组的基础上增加了3个cov1;
D组将C组的cov1换成cov3,对比实验结果发现,使用cov3的分类结果要由于使用cov1;
E组在D组的基础上增加了3个cov3。
对于每个组对应的weight layers=,表示的是包含权重系数的层的总数量,即所有卷积层+全连接层之后。注意不包含池化层是因为池化层不包含权重系数。因此VGG16表示该模型中卷积层和全连接层之和为16.
2 ResNet模型
2.1 ResNet概述
- ResNet(残差神经网络)由微软研究院何恺明等人提出,并斩获2015年ImageNet竞赛中分类任务第一名、目标检测第一名
- 主要贡献是发现了==“退化现象(Degradation)”,并针对退化现象发明“直连边/短连接(Shortcut connection)”==,极大消除在vgg中出现的神经网络深度过大导致训练困难问题。在实验中,作者评测了一个深度152层(是vgg的八倍)的残差网络,结果获得了比vgg更低的复杂度。
什么是退化现象呢?
退化现象是指随着层数加深,首先训练准确率会逐渐趋于饱和;但若层数继续加深,反而训练准确率下降,效果降低。注意这种下降不是由于过拟合造成的(因为如果是过拟合的话,训练时误差应该很低而测试时很高)
2.2 ResNet优点
- 残差网络的机构更利于优化收敛
- 残差网络解决了退化问题
- 残差网络可以在拓展网络深度的同时,提高网络性能(相比于vgg的优点)
2.3 ResNet结构
- 在ResNet中,传递给下一层的输入变为H(x)= F(x)+ x,来拟合残差F(x)=H(x) - x。
为什么这样做呢?
假设一个网络A的训练误差为x,那么在A的基础上添加几个层来构建网络B的话,训练误差也为x。如果出现B的训练误差高于A的情况(退化现象),说明我们应该跳过这些层,从A构造恒等映射。因此可以在输入和输出中添加直连路径shortcut,这个过程只需要学习已有的输入特征。由于C只学习残差,该模块叫作残差模块。

- 对于shortcut connection,有两种方式:
① 当输入维度与输出维度相同时,直接使用恒等shortcuts,即将F(x)和x逐元素相加
② **当输入维度与输出维度不同时,可以考虑两个选项:(A)shortcut仍然使用恒等映射,在增加的维度上使用0来填充;(B) 通过1x1的卷积使得维度保持一致
2.4 ResNet实验结果
- 作者首先评估18层和34层的plain网络。实验结果产生的一种退化现象:在训练过程中34层的网络比18层的网络有着更高的训练错误率。
- 接着对18层和34层的残差网络进行评估。为了保证标量一致性,其基本框架和plain网络结构相同,只是在plain网络基础上加入了shortcuts连接
- 结果显示,
(1) 与plain网络相反,34层的resnet网络比18层的错误率更低,表明可以通过增加深度提高准确率,解决了退化问题。
(2) 与plain网络相比,层次相同的resnet网络上错误率更低,表明残差网络在深层次下仍然有效。
(3) 对于18层的plain网络,它和残差网络的准确率很接近,但是残差网络的收敛速度要更快。
3 DenseNet模型
3.1 DenseNet概述
- DenseNet的一大特点是通过特征在通道上的连接来实现特征重用,这个特点让DenseNet的参数量和计算成本更少,效果也更好。
- DenseNet的基本思路与ResNet一致,但它建立了前面所有层和后面层的密集连接,DenseNet也因此得名。
3.2 DenseNet结构
使用DenseBlock+Transition的结构
3.2.1 DenseBlock

由以上图可知,每个Dense Block包含五层,每个层的特征图大小相同。可以看出,对于每一个DenseBlock,每一层的输入都来自它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入。所以对于一个L层的DenseBlock,共包含L(1+L)/2个连接
注意:
- 假定输入层的特征图channel数为k0,DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k。由于每一层都要接受前面所有层的特征图,那么l层输入的channel数为k0+(l-1)l
- 在DenseBlock中,采用BN+ReLu+3x3Conv的结构(与平常所见的Conv+ReLu+BN不同)。这是因为,采用了特征重用后,如果先采用卷积层,会包含前面所有层的输出特征,数值分布差异比较大。所以,先采用BN层将数值进行标准化。
3.2.2 Transition
- 在两个相邻的DenseBlock之间,采用Transition层进行连接,主要作用是整合上一个DenseBlock的特征,缩小上一个DenseBlock的宽高,使得特征图宽高减半,压缩模型。
- Transition层结构为:BN+ReLu+1x1 Conv+2x2 AvgPooling
- 通过Pooling使特征图大小降低
3.3 DenseNet优缺点
-
优点:
(1) 相比ResNet使用更少参数数量,且计算效率更高,效果更好;
(2) 通过特征重用,可以同时利用高层次和低层次的特征;
(3) 缓解了梯度消失/爆炸和网络退化问题。 -
缺点:
(1) 由于特征重用,数据需要被复制多次,空间占用率高,显存增加较快。因此训练时间要比ResNet长
未完待续(持续更新 5.18)















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









