










为什么要引入多元线性回归?
之前的单元线性回归方程,只有一个特征量,例如,我们希望用单一特征量x房屋面积来预测y房屋价格,但我们知道这是不现实的。
在现实生活中,显然,处理房屋面积外,房屋的年龄、卧室的数量等特征都可以帮助预测房屋价格y。
线性回归假设的形式(4-1)
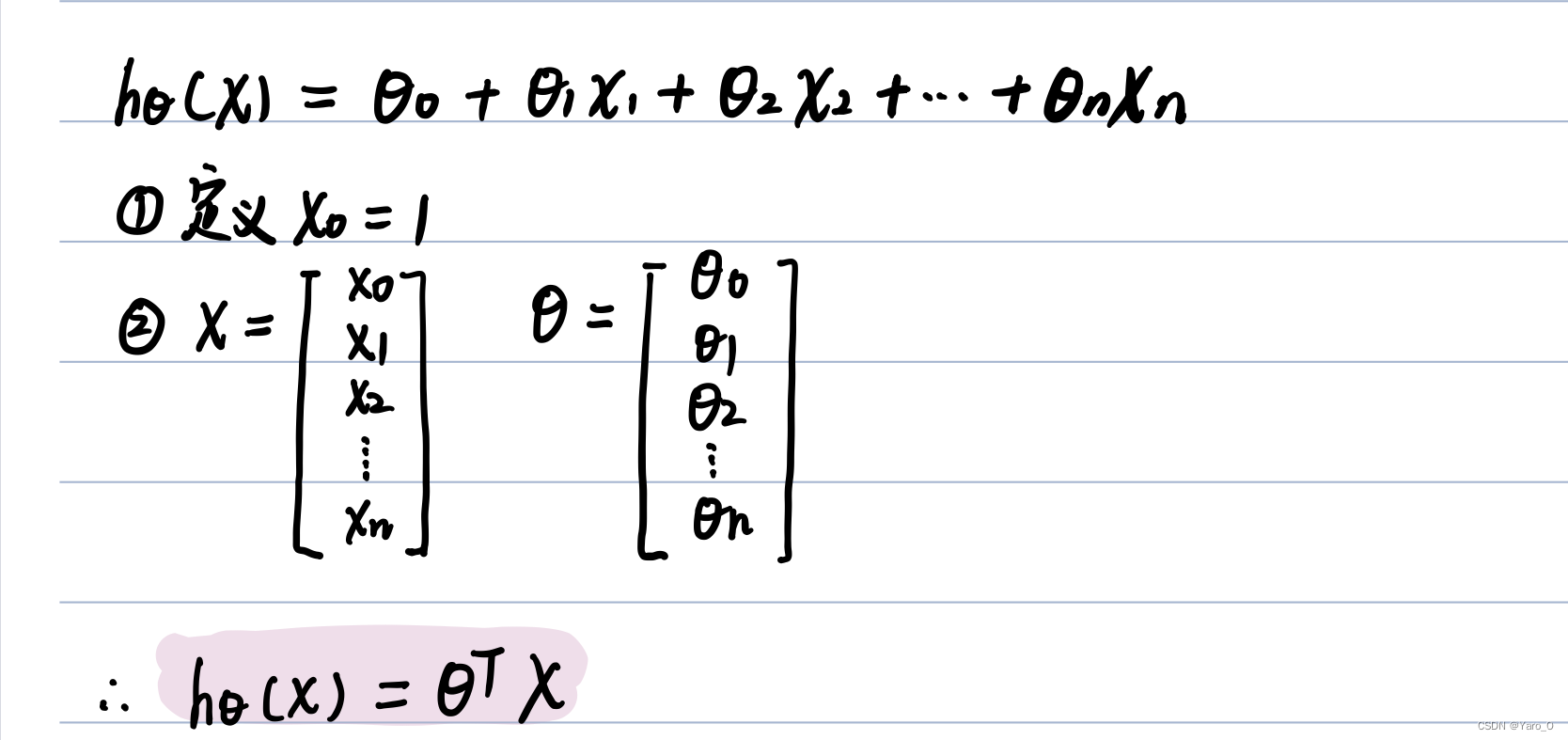
如何设定该假设的参数(4-2)
——如何利用梯度下降来处理多元线性回归

至于为什么深蓝色框所代表的和J(θ)的偏导数一致呢?
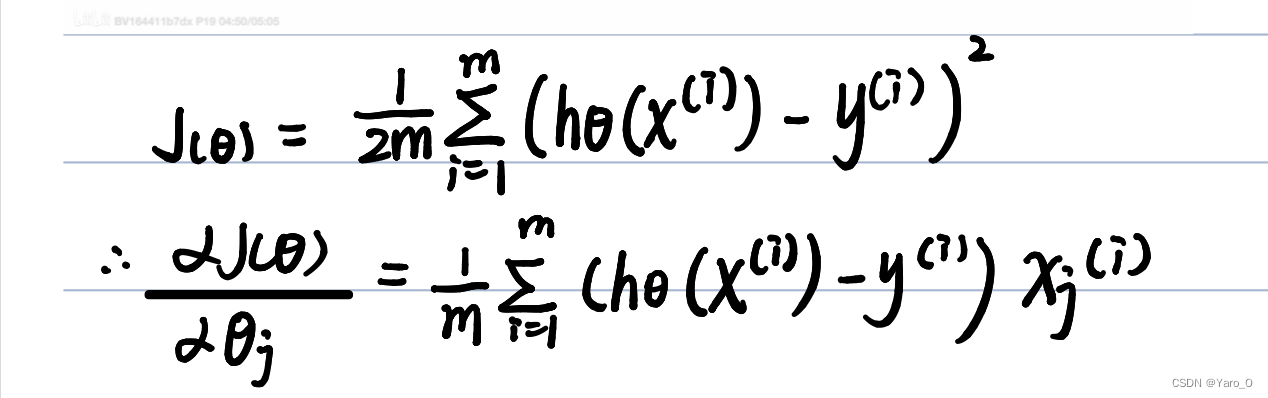
特征缩放(4-3)
目的:确保每个特征值都在相近的范围内,一般是将特征的取值约束到-1到+1范围内,使得梯度下降运行得更快。
如果特征值的范围相差较大,进行梯度下降时,可能会花费很长时间才收敛到全局最小值
方法:
①通过除以不同的数,是特征值处于[-1,1]范围,但这个范围不是很重要,只需要靠近这个范围就好
②均值归一化
特征值 x1 = (x1-u1)/s1,其中u1等于x1的平均值,s1表示x1的最大值减去最小值
注意:特征缩放并不要求十分准确,只需要能保证梯度下降运行得更快就好了
学习率α(4-4)
首先,我们如何判定梯度下降是否在正常工作呢?

(1)横坐标表示迭代次数,纵坐标表示代价函数的值,如果梯度下降正常工作的话,每一次迭代,J(θ)都应该下降;
(2)当曲线趋于平滑时,梯度下降函数基本收敛。
如果图像中J(θ)在不断上升,意味着你可能要选一个更小的α
总而言之,如果α过小,收敛速度会很慢;
如果α过大,J(θ)可能不会每次都降低
正规方程(4-6)
- 提供了一种求θ的解法,可以一次性求解θ的最优值
- 使用正规方程,不需要做特征缩放,不需要计算α
- 如果特征变量n较大(n>10000),计算量过大,速度会变慢,这种情况下建议使用梯度下降
计算方法:
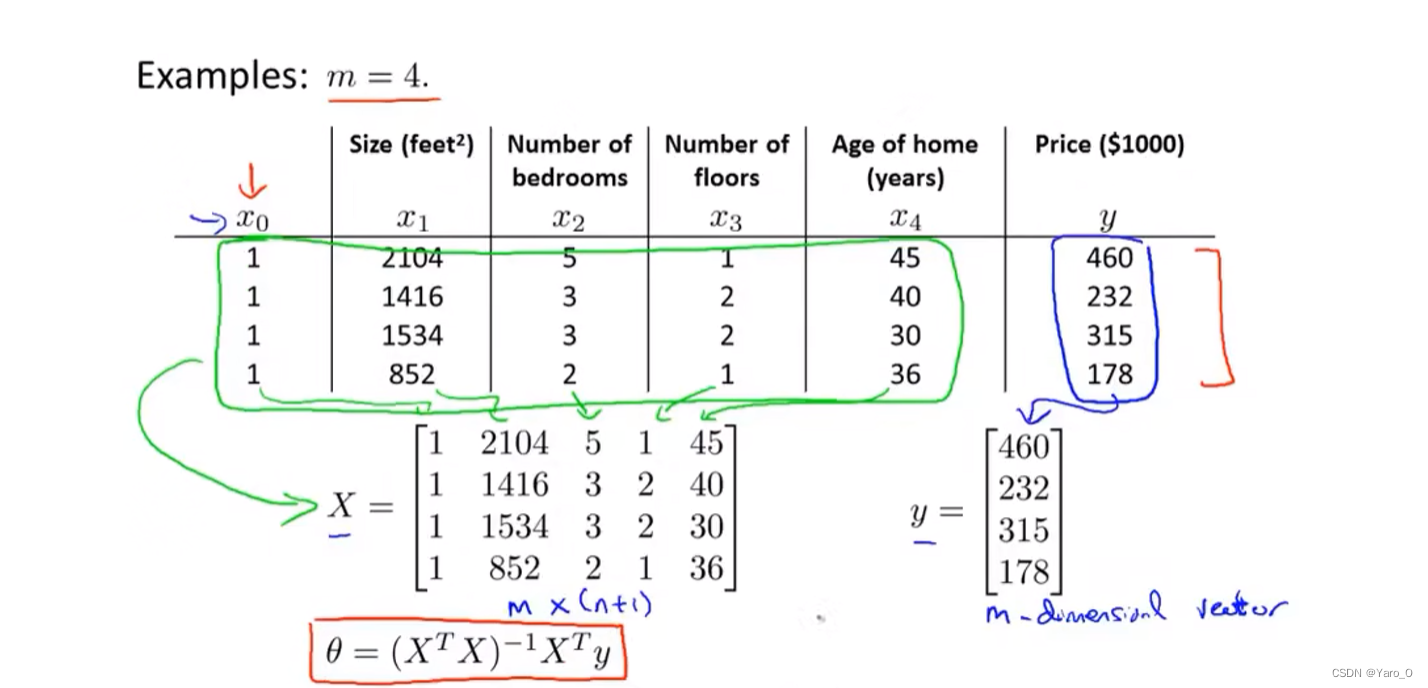
X是mx(n+1)维矩阵,其中m为训练样本数量,n是特征变量数
关于
- 使用这个方程,可以得到最优θ;
- 不需要特征缩放
- 不需要选择学习率α
如果矩阵不可逆,正规方程如何解决?(4-7)
什么情况下X的转置乘以X不可逆呢?
- 当某些特征值之间存在线性关系时;→删除多余特征
- 特征n太多而训练样本m太少。→①删除多余特征;②使用正规化(regularization)方法















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









