cross-lingual transfer learning:跨语言迁移学习
cross-lingual retrieval 跨语言检索
cross-lingual embedding 跨语言嵌入
leverage 利用
Our proposed WenetSpeech-Pipe framework, as illustrated in Figure 1, comprises six modules: (A) Audio Collection, 音频采集(B) Speaker Attributes Annotation, 说话人属性标注(C) Speech Quality Annotation, 语音质量标注 D) Automatic Speech Recognition, 自动语音识别(E) Text Postprocessing文本后处理, and (F) Recognizer Output Voting 识别输出投票
说话人级别的元数据:是指与每位说话人相关的附加信息,用于描述、分析或处理语音数据时提供更丰富的上下文。在语音识别,说话人识别、语音合成、语言学研究等领域非常重要
元数据就是关于数据的数据,比如有一段语音,语音本身是数据。这是谁说的、在哪说的、说话者的性别等就是元数据。(比如图像 的属性、来源、拍摄条件、内容标签这也是元数据)
complement 补充物、互补、使完整
ensemble 集合、组合
optimization 优化,最优化
多系统·集成策略:使用三个语音识别模型,每个语音得到三个不同的转录结果,这三个转录结果会送到Recognizer Output Voting(识别结果投票)。
在这个识别结果投票阶段首先会对三个结果进行对齐。然后进行选择:例如:三个系统中有两个输出“你好”,就采纳“你好”。对分歧部分,可能结合置信度或语言模型重打分
discrepancy 差异,不一致
transcription转录,抄写
consistency一致性
inconsistency不一致性
文本后处理。为确保跨系统对齐的可靠性及多源转录的有效整合,必须统一不同自动语音识别系统(ASR)的输出格式。现有ASR系统的转录文本存在显著差异:字符集(繁体与简体)、非词汇标签(如[笑声])以及数字和代码转换文本的格式不统一。这些差异可能阻碍后续处理阶段的准确融合与共识形成。为此,我们为所有转录流构建了文本后处理流程。该流程通过OpenCC2工具将繁体中文转换为简体,移除标点符号与特殊字符,采用规则重写统一数字表达和日期格式,并在粤英双语词汇间插入空格以促进双语建模。通过依次执行这些步骤,我们生成了跨三个系统一致的标准化转录文本。这些标准化输出作为ROVER模块的可靠输入表征,确保表面形式差异不会干扰融合过程中的音素或词汇对齐。
繁体转化为简体、去掉标点符号和特殊字符、统一数字表达式和日期建模,在粤英双语词汇间插入空格以促进双语建模
文本后处理之后开始进行投票。首先使用动态规划算法进行对齐(emm)。
识别器输出投票机制。尽管文本后处理技术统一了多个自动语音识别系统中的表面转写形式,但在词汇选择、词段划分和音素表示方面仍存在持续差异。为生成统一且高精度的参考转写,我们采用基于多系统投票融合策略的Fiscus框架[1997],该框架通过识别器输出投票误差缩减(rover)机制提升转写准确性。(在文本后处理阶段之后进行这一步)
在我们的实现方案中,我们对标准漫游者处理流程进行了扩展,以更好地应对粤语的语言特性。首先,通过动态规划算法对上述自动语音识别系统文本规范化后的转写结果进行对齐(DTW、编辑距离、词图融合)。为确保对异常假设的鲁棒性,我们引入了候选过滤模块,该模块通过计算各系统输出与另外两个系统的平均转写结果之间的编辑距离来筛选候选。超过预设阈值的输出将被排除在投票环节之外。(对于A的输出,计算它与B,C的平均结果之间的编辑距离,如果A的结果差太多,被排除)(被排除是B,C很权威吗?,超过阈值的输出将被排除在投票环节之外)
在每个对齐位置,我们会选取出现频率最高的词汇,并将所有位置的平均投票频率记录为语句级文本置信度评分。
我们通过引入发音特异性置信度度量,将投票机制扩展到粤语拼音领域,该机制与字符级投票并行运作,从而强化音素一致性。
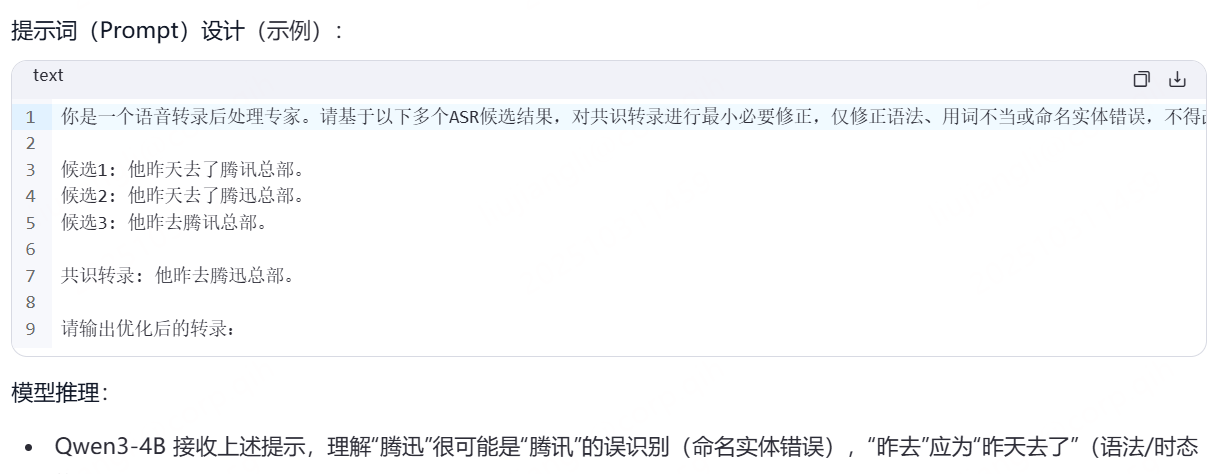
为提升转录精度,我们采用大模型Qwen3-4B对共识输出进行精简且具备上下文感知的优化。该模型将所有原始语音识别假设作为上下文参考,仅对语法、词汇选择或命名实体进行必要修正,完整保留语音内容的原貌。
最后,我们使用预训练声学模型对精炼转录文本与原始音频进行字符级强制对齐,从而为每个字符生成精确时间戳,支持细粒度语音处理及下游任务。
LLM纠错的位置与目的
在 多ASR系统投票融合(ROVER)之后,对生成的“共识转录”(consensus output)进行轻量级、上下文感知的精细化修正。
目标:仅修正语法、词汇选择、命名实体等语言层面错误,不改变语音内容原意,避免LLM“幻觉”或过度改写。
使用的模型
- 采用 Qwen3-4B(Yang et al., 2025),一个40亿参数的大语言模型。
- 该模型被专门提示(prompted)作为 “粤语ASR纠错专家”
输入上下文
LLM不仅看到ROVER输出的共识文本,还同时参考三个原始ASR系统的输出(SenseVoice、Whisper、TeleASR)作为上下文。
这使得模型能判断哪些词是多个系统一致认可的(高置信),哪些是冲突的(需谨慎修正)
给出的提示要求是这个:
You are a Cantonese ASR correction expert. Follow these rules:
Only correct proper nouns (names, brands, places)
Never rephrase if the original is correct
Rate corrections 0–100 based on ASR consistency and logic
你是一名粤语语音识别(ASR)纠错专家。请遵守以下规则:
仅修正专有名词(如人名、品牌名、地名);
如果原文正确,切勿改写或调整语序;
根据ASR结果的一致性与逻辑性,对修正给出0–100的置信度评分。
LLM输出包含三部分:
Result: 修正后的文本
Score: 置信度评分(0–100)
Analysis: 简短的修改理由(如“‘杭世龍’是‘项少龍’的同音错误”)






















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









