






 本文记录了在Pycharm中首次成功运行Scrapy框架的过程。以爬取https://quotes.toscrape.com/page/1/ 中10页数据为例,介绍了在Pycharm创建项目、下载Scrapy、创建项目和爬虫文件,以及编写程序和运行Scrapy生成csv文件的步骤。
本文记录了在Pycharm中首次成功运行Scrapy框架的过程。以爬取https://quotes.toscrape.com/page/1/ 中10页数据为例,介绍了在Pycharm创建项目、下载Scrapy、创建项目和爬虫文件,以及编写程序和运行Scrapy生成csv文件的步骤。
scrapy框架是一个爬虫的重要框架,需要成功运行还是需要学习一段时间,以此记录第一次运行成功scrapy
本文是以爬取了 https://quotes.toscrape.com/page/1/ 这一网址中10页的数据为例
1.在pycharm中新创建一个项目,下载scrapy,即在terminal中输入:pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
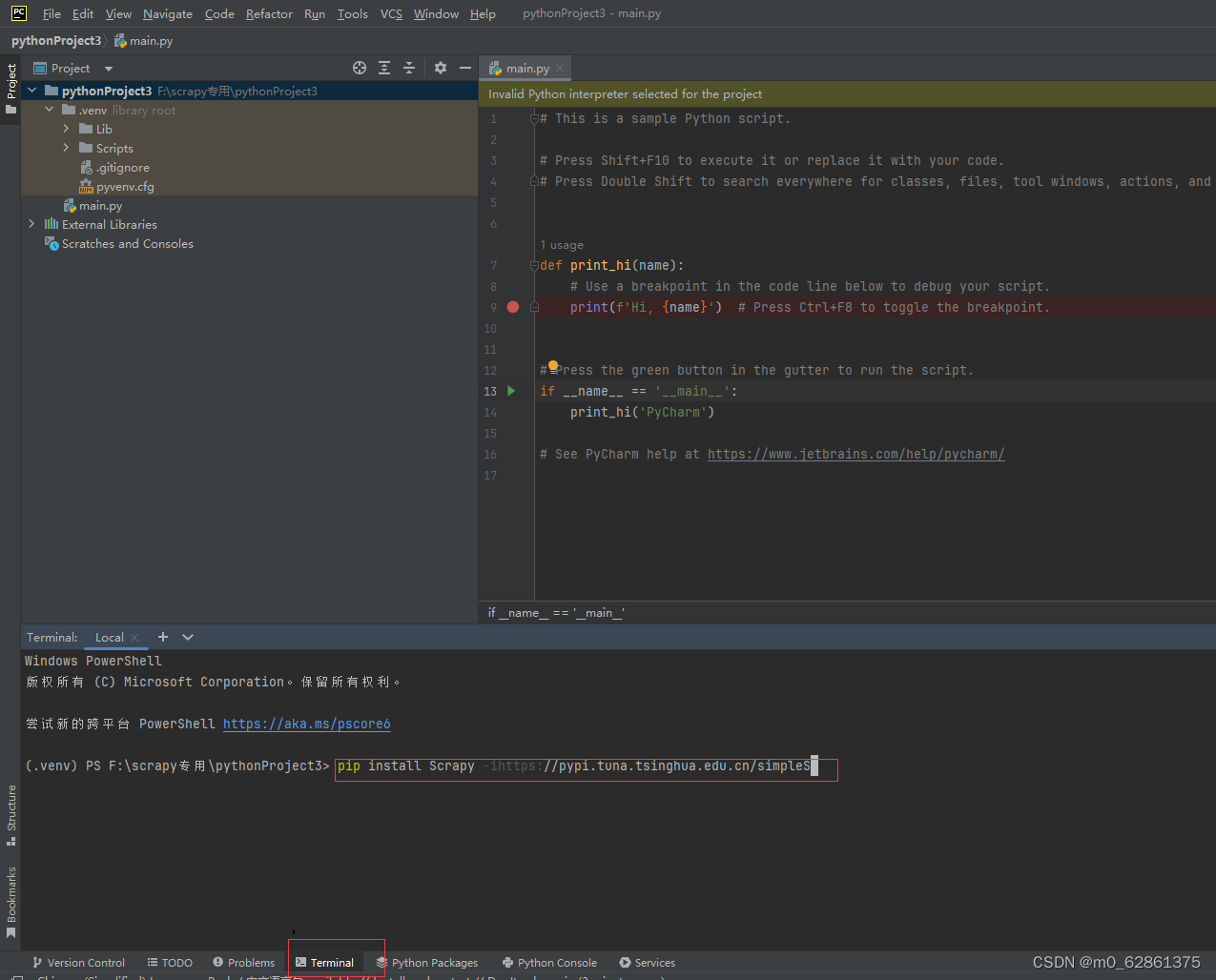
2.创建项目:输入scrapy startproject Toscrape,效果如下图
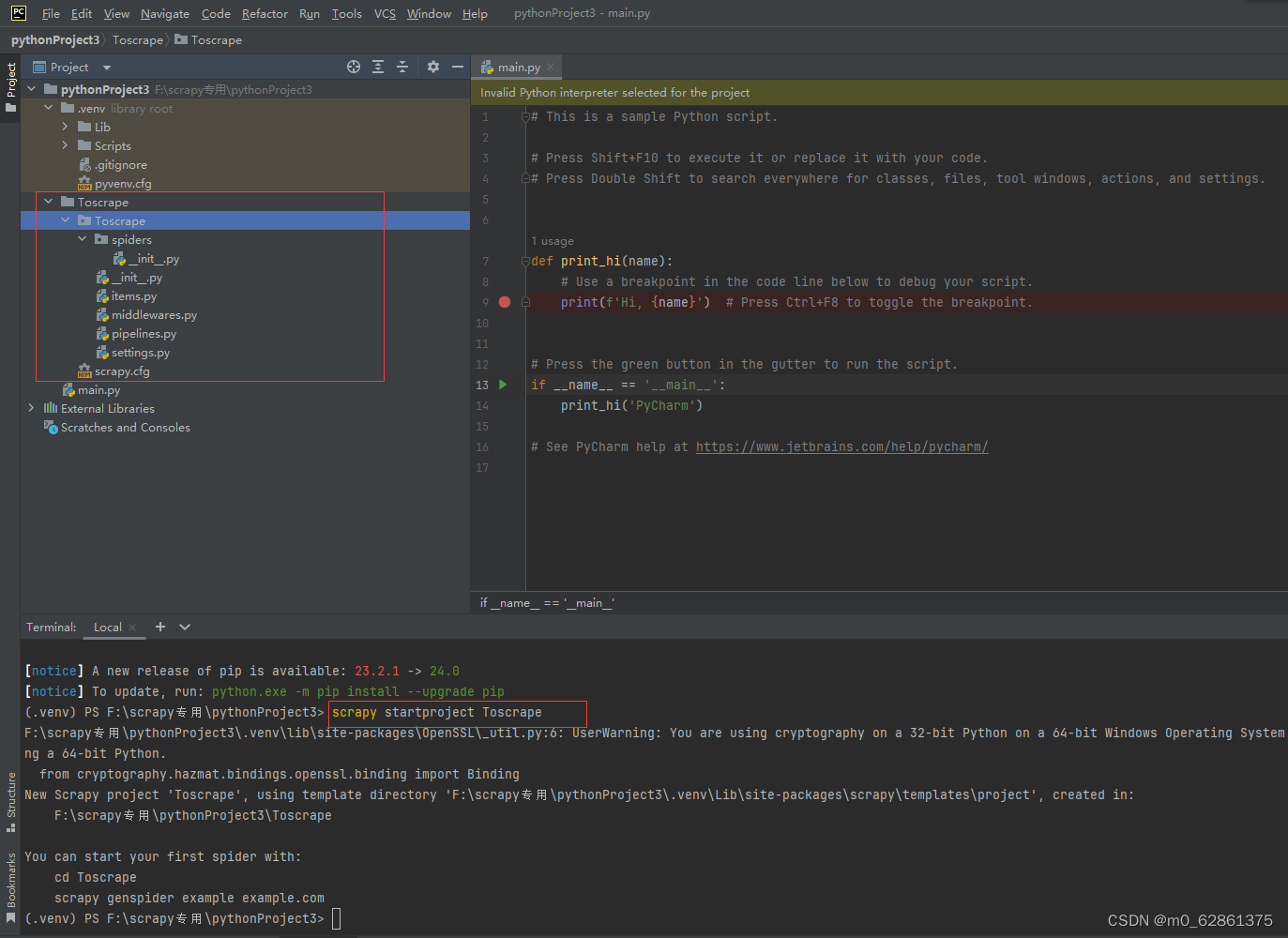
3.创建爬虫文件(很重要,注意必须要进入到spiders的目录下进行创建,这样才能成功运行,否则会报错no moudle crawl,进入方法:cd Toscrape\Toscrape\spiders ):scrapy genspider toscrape "quotes.toscrape.com"
(1)进入spiders目录
(2)创建爬虫文件,会在spiders后出现toscrape.py文件,在此项目就成功创建了,接下来进行实际程序的编写
scrapy genspider toscrape "quotes.toscrape.com"
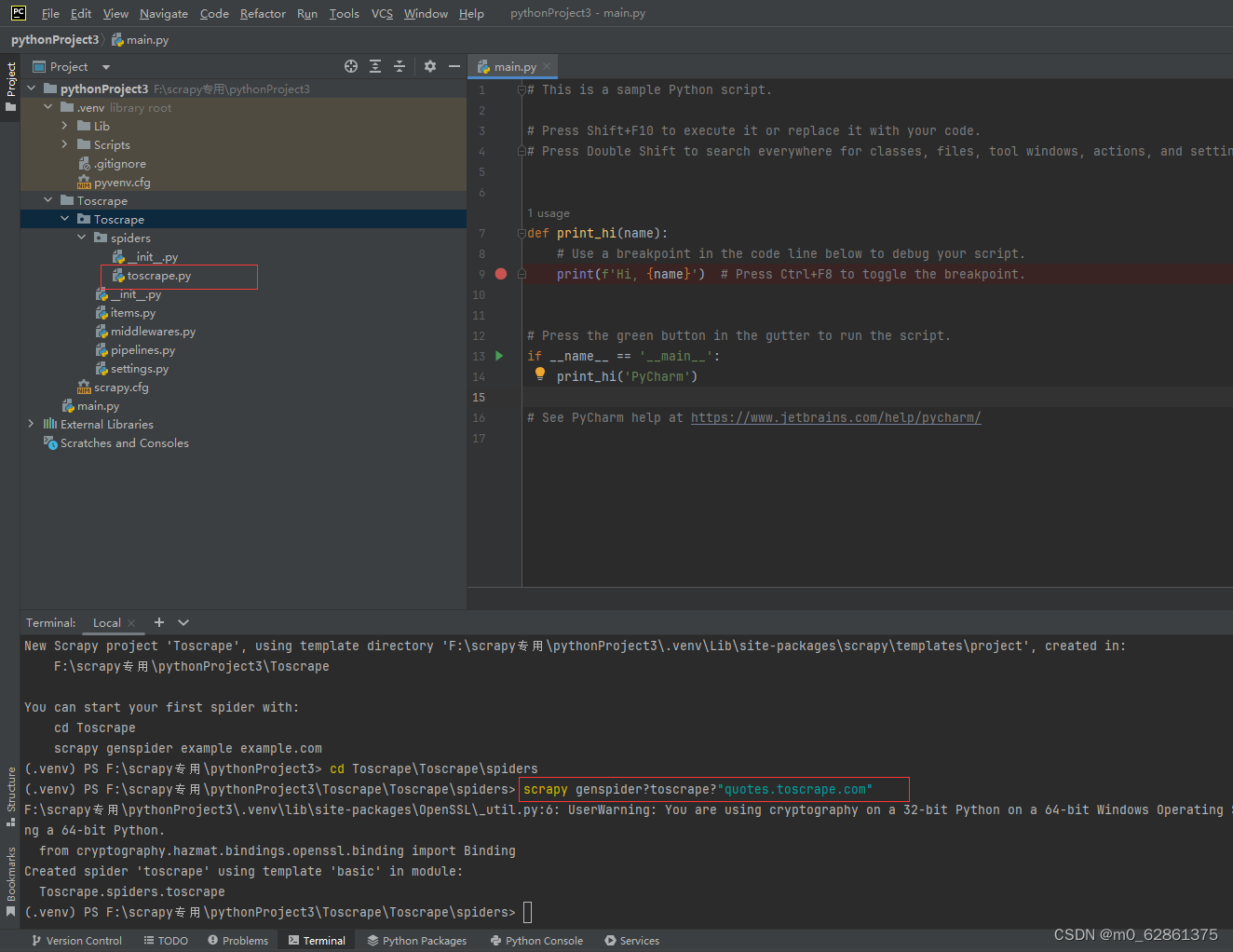
4.这些文件直接粘贴我的代码即可 (1)settings.py文件
BOT_NAME = "Toscrape"
SPIDER_MODULES = ["Toscrape.spiders"]
NEWSPIDER_MODULE = "Toscrape.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"Toscrape.pipelines.Pipiline_ToCSV": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"2.pipelines.py
import codecs, os, csv
class ToscrapePipeline:
def process_item(self, item, spider):
return item
# 保存为csv文件
class Pipiline_ToCSV(object):
def __init__(self):
#文件的位置
store_file = os.path.dirname(__file__) + '/spiders/wangzhan.csv'
#打开文件,并设置编码
self.file = codecs.open(filename= store_file, mode= 'wb', encoding='utf-8')
# 写入csv
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
line = (item['content'], item['author'], item['tags'])
# 逐行写入
self.writer.writerow(line)
return item
def close_spider(self, spider):
self.file.close()3.items.py
import scrapy
class ToscrapeItem(scrapy.Item):
# define the fields for your item here like:
content = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
pass4.toscrape.py
import scrapy
from Toscrape.items import ToscrapeItem
class ToscrapeSpider(scrapy.Spider):
name = "toscrape"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/page/1/"]
page_num = 1
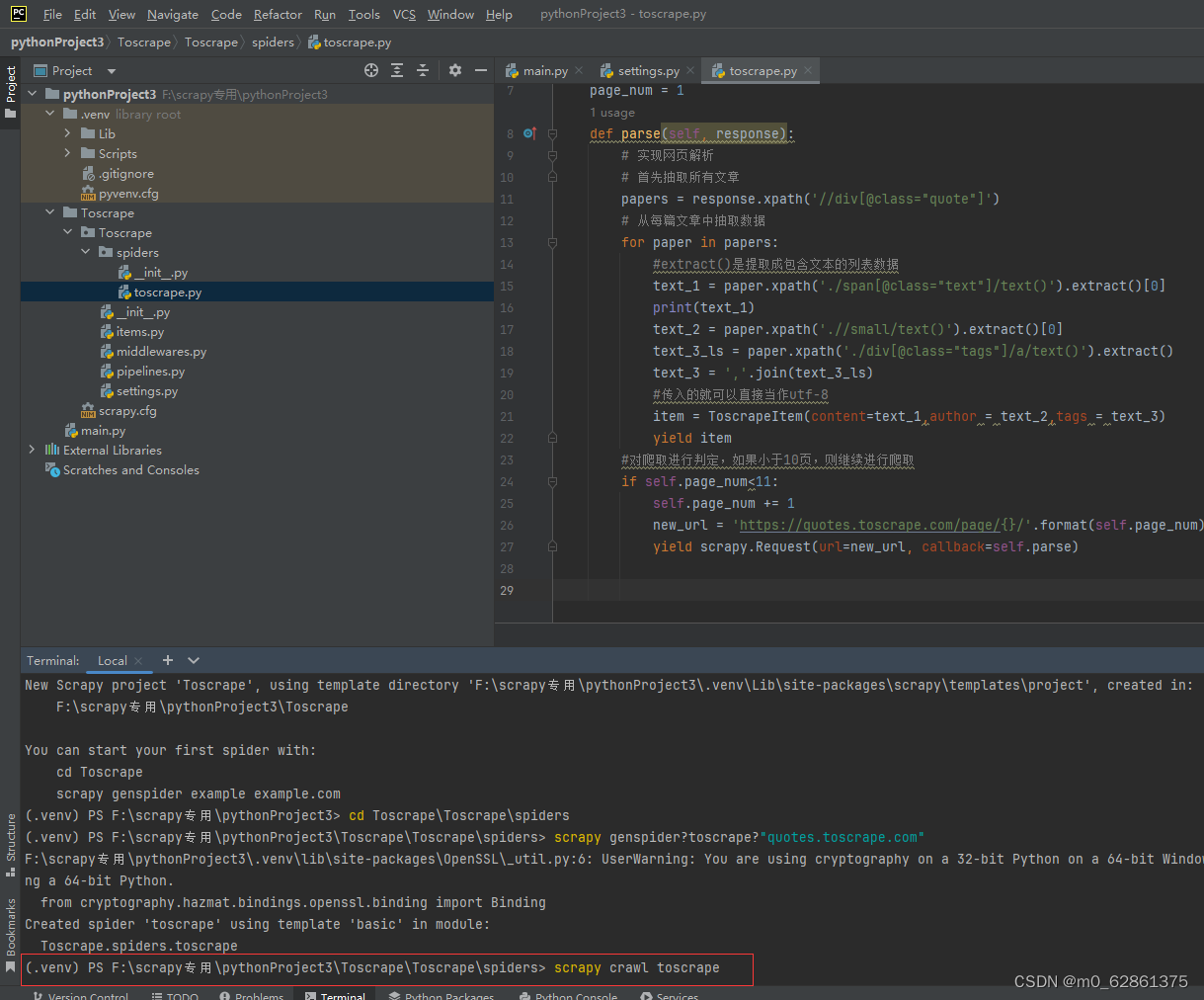
def parse(self, response):
# 实现网页解析
# 首先抽取所有文章
papers = response.xpath('//div[@class="quote"]')
# 从每篇文章中抽取数据
for paper in papers:
#extract()是提取成包含文本的列表数据
text_1 = paper.xpath('./span[@class="text"]/text()').extract()[0]
print(text_1)
text_2 = paper.xpath('.//small/text()').extract()[0]
text_3_ls = paper.xpath('./div[@class="tags"]/a/text()').extract()
text_3 = ','.join(text_3_ls)
#传入的就可以直接当作utf-8
item = ToscrapeItem(content=text_1,author = text_2,tags = text_3)
yield item
#对爬取进行判定,如果小于10页,则继续进行爬取
if self.page_num<11:
self.page_num += 1
new_url = 'https://quotes.toscrape.com/page/{}/'.format(self.page_num)
yield scrapy.Request(url=new_url, callback=self.parse)
5.在terminal中运行scrapy,即可出现csv文件,就全部完成了
scrapy crawl toscrape


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









