







基础概念1:分词
分词是指将文本数据转换为一个一个的单词,是NLP自然语言处理 过程中的基础;因为对于文本信息来讲,我们可以认为文本中的单词可以体 现文本的特征信息,所以在进行自然语言相关任务的时候,第一步操作就是 需要将文本信息转换为单词序列,使用单词序列来表达文本的特征信息。
对于英文来说,一个单词一般会代表一个实体,所以将空格作为划分即可。但是对于中文来说,一个实体很有可能是有两个或多个字组成。例如“面包”由面和包两个完全不同意思的词组成。因此我们需要一个工具来进行中文词语的划分:jieba
jieba
Jieba常用的一种Python语言的中文分词和词性标注工具;算法基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图,然后采用动态规划查找最大概率路径,找出基于词频的最大切分组合
基础功能:
1.分词
>前缀词典匹配 、HMM(隐马尔可夫)模型Viterbi算法
2.自定义词典添加
3.关键词抽取
>TF-IDF、TextRank
4.词性标注
>HMM模型Viterbi算法
5.并行分词(当前Windows不支持)
分词
jieba的分词有三种模式:
精确模式 jieba.cut(str):
>试图将句子最精确地切开,适合文本分析;
全模式 jieba.cut(str,cut_all=True):
>把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式 jieba.cut_for_search(str):
>在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
-
jieba.cut():返回一个迭代器对象
# 导入包 import jieba word_list = jieba.cut('我来到湖南国防科技大学', cut_all=True) print("【全模式】: {}".format(" /".join(word_list))) word_list = jieba.cut('我来到湖南国防科技大学') print("【精确模式】: {}".format(" /".join(word_list))) word_list = jieba.cut_for_search('我来到湖南国防科技大学') print("【搜索引擎模式】: {}".format(" /".join(word_list))) word_list = jieba.cut("我在台电大厦上班", HMM=False) print("【仅词典模式】: {}".format(" /".join(word_list))) word_list = jieba.cut("我在台电大厦上班", HMM=True) print("【HMM新词发现模式】: {}".format(" /".join(word_list)))【全模式】: 我 /来到 /湖南 /南国 /国防 /国防科 /国防科技 /国防科技大学 /科技 /大学 【精确模式】: 我 /来到 /湖南 /国防科技大学 【搜索引擎模式】: 我 /来到 /湖南 /国防 /科技 /大学 /国防科 /国防科技大学 【仅词典模式】: 我 /在 /台 /电 /大厦 /上班 【HMM新词发现模式】: 我 /在 /台电 /大厦 /上班
jieba.lcut():返回一个list集合
同jieba.cut()
自定义词典添加
jieba.load_userdict(./''):加载给定文件filename中定义的单词
#自定义词典:一词占一行,每行分三个部分:词语,词频(可忽略),词性(可忽略) 饿了么 2 nt 美团 2 nr#加载词典 jieba.load_userdict('./word_dict.txt') word_list = jieba.cut('饿了么是你值得信赖的选择', HMM=True) print("【载入词典后<有HMM>】: {}".format('/'.join(word_list)))【载入词典后<有HMM>】: 饿了么/是/你/值得/信赖/的/选择
add_word(word, freq=None, tag=None)、del_word(word)
可以在程序中动态修改词典
#例如分词为 徐 狰狞 时,可以做以下操作 jieba.add_word('徐狰狞', 2, 'nr')结果输出:徐狰狞
suggest_freq(segment, tune=True)
可以调节单个词语的词频,使其能或者不能被分出来
word_list = jieba.cut('如果放到post中将出错。', HMM=False) print("【未使用freq】: {}".format('/'.join(word_list)))【未使用freq】: 如果/放到/post/中将/出错/。jieba.suggest_freq('中', tune=False)243192jieba.suggest_freq(('中', '将'), tune=True)494word_list = jieba.cut('如果放到post中将出错。', HMM=False) print("【使用freq】: {}".format('/'.join(word_list)))【使用freq】: 如果/放到/post/中/将/出错/。我们可以看到成功分词
关键词提取
基于TF_IDF
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence:待提取的文本
- topK:返回多少个TF/IDF权重最大的关键词,默认为20个
- withWeight:是否返回关键词的权重值,默认为False,表示不返回
- allowPOS: 仅提取制定词性的词,默认为空,表示不筛选
基于TextRank
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False)
- sentence:待提取的文本
- topK:返回多少个TF/IDF权重最大的关键词,默认为20个
- withWeight:是否返回关键词的权重值,默认为False,表示不返回
- allowPOS: 仅提取制定词性的词,默认不为空,表示进行筛选
- withFlag:是否返回单词的词性值,默认为False,表示不返回(仅返回单词)
词性标注
jieba.posseg.cut()
import jieba.posseg as pseg sentence = "姚明的职业是什么" # 分词+词性标注 words = pseg.cut(sentence) # 输出 print("%8s\t%8s" % ("【单词】", "【词性】")) for word, flag in words: print("%8s\t%8s" % (word, flag))【单词】 【词性】 姚明 nr 的 uj 职业 n 是 v 什么 r
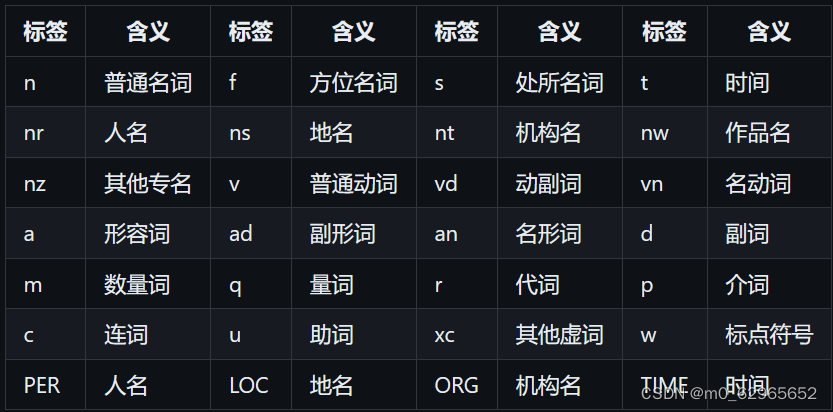
词性标注对应表















 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









