






学习python有感,故作.望能帮助自己加深印象,也帮助大家!
阅读对象:了解python基础语法的读者即可
问题:假使需要你在一段文本中寻找出所有形似121-432-8650的电话号码,用人力固然可行,但是学会正则表达式,你可以学会设计程序自动寻找电话号码,以及电子邮件地址.
目录
12.组合使用 re.IGNOREC ASE、re.DOTALL 和 re.VERBOSE
1.用正则表达式查找文本模式
1.1创建正则表达式对象
Python的所有正则表达式的函数都需要用到re模块。交互环境导入该模块。
import rere模块中有很多函数,这里我们选择re模块中的compile函数
往re.compile()函数传入一个字符串值,表示正则表达式,它将返回一个Regex对象(现在不懂没关系,往后看就清楚许多)
这里传入的字符串根据你要找的特殊文本来决定,问题中我们需要寻找的三个数-三个数-四个数
样式的电话号码,那么传入的字符串中应该是这个样子:
re.compile('\d\d\d-\d\d\d-\d\d\d\d')括号内\d代表一个阿拉伯数字(0~9中任意一个数字),这样的正则表达式满足寻找的所有电话号码的可能.
另外

前面我们说re.compile('\d\d\d-\d\d\d-\d\d\d\d')会返回一个Regex对象,那么我们需要用一个变量来=它(我不知道如何表述..)
phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')1.2匹配Regex对象
Regex对象中有方法search(),它的作用是将传入给方法search()的字符串与Regex对象的正则表达式(此处是\d\d\d-\d\d\d-\d\d\d\d形式)进行比对,如果在传入的字符串中找到该正则表达式模式,那么将第一次满足的正则表达式模式作为Match对象返回,如果没有找到,那么返回None.
# 上述所有代码
import re
phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phoneRegex.search('My phone number is 233-522-4359!')
# 将找到的符合正则表达式模式赋值给变量mo
"""
这里补个坑
如果你没有将re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')赋值给phoneRegex
那么search()处得这么写
"""
re.compile(r'\d\d\d-\d\d\d-\d\d\d\d').search('My phone number is 233-522-4359!')
# 如果每一次这么写,很累,所以将其赋值phoneRegex
假使我们输出变量mo,那么返回233-522-4359(看下图,输出match对象为'233-522-4359')

2.用正则表达式匹配更多模式
2.1 利用括号分组
假使想要将第一个-前面的的三个数(这里是233)单独拿出来,该怎么办?
添加括号将在正则表达式(re.compile()括号内的字符串就是正则表达式,我好像忘讲了,像正则表达式样子的字符串就是正则表达式模式,这里就是233-522-4359)中创建“分组”:
phoneRegex = re.compile(r'(\d\d\d)-\d\d\d-\d\d\d\d')特别注意的是:我们只用了一个括号,所以只有一个分组,它是第一组,假使我们给后面那一部分也括号上,那么后面那个括号括起来的就是第二组:
phoneRegex = re.compile(r'(\d\d\d)-(\d\d\d-\d\d\d\d)')那么接下来我们可以调用group()方法,往里面传入参数,就可以获取第一组的内容,或者第二组的内容:
mo.group(1) # 那么这里在互动式环境中理应输出第一组内容即233
mo.group(2) # 这里在环境中输出第二组内容即522-4359如果我们往group()方法里面不传入参数或者传入参数0,那么输出整个匹配的文本内容:
mo.group()
mo.group(0)
# 上述两种等价,均输出233-522-4359如果需要获取所有分组内容,使用groups()方法
mo.groups()

很明显,mo.groups()输出的是一个元组,其中为各个分组文本内容
2.2 用管道匹配多个分组
字符 | 称为“管道”。
希望匹配许多表达式中的一个时,就可以使用它
譬如:我们的正则表达式是r'hello|world',那么它意味着匹配hello或者world
import re
greetRegex = re.compile(r'hello|world') # 这里变量不是一定要加Regex,只要符合标识符规则就可
mo = greetRegex.search('hello, Zhang. Nice to meet you!')
mo = greetRegex.search('world is on my heart.')

这里我们可以发现,到底先匹配的是hello还是world,我们就是按照文本从左往右依次数过去,谁先匹配就返回谁,search()传入文本中'hello, world!', hello在前面且满足正则表达式,就返回hello;传入文本中'world, hello!',world在前面且满足正则表达式,就返回world
如果你想要找到满足bat_up, bat_on, bat_under(满足其中一个即可)的特殊文本,在这里也许你会完整输入:
charRegex = re.compile(r'bat_up|bat_on|bat_under')但是发现后我知道,他们都有共同的部分bat_,那么你可以这样子输入:
charRegex = re.compile(r'bat(_up|on|under)')这里你可能觉得大可不必,我觉得你说的对...
2.3 用问号实现可选匹配
有时候,想匹配的模式是可选的。就是说,不论这段文本在不在,正则表达式 都会认为匹配。字符?表明它前面的分组在这个模式中是可选的。
譬如:
girlRegex = re.compile(r'girl(friend)?')
# 问号?前面的分组是(friend) 说明这个分组是可选的
正则表达式中的(friend)?部分表明,模式 friend 是可选的分组。该正则表达式匹配的文本 中,friend将出现零次或一次
正则表达式r'girl(friend)?' 等价于 r'girl|girlfriend'
也许你会说,大可不必!那我觉得你说的对!
再拿前面的电话号码举例子,有的人会懒的写第一个横线前面的三个数字(我瞎编的),那么我们就需要做好两手准备
phoneRegex = re.compile(r'(\d\d\d)?-\d\d\d-\d\d\d\d')
如果需要匹配真正的问号字符,就使用转义字符\?。
2.4 用星号匹配零次或多次
*(称为星号)意味着“匹配零次或多次”,即星号之前的分组,可以在文本中出 Python 编程快速上手——让繁琐工作自动化 现任意次。它可以完全不存在,或一次又一次地重复。
譬如:
# 全部写一下吧
import re
laughRegex = re.compile(r'AhOo(ha)*') # * 前面的分组为(ha),它可以出现零次或多次
laugh = laughRegex.search('haaaa, you sliped, AhOohahahahaha!!!!!')
one

two
从上面两种情况你应能触类旁通,明白*的用法,这里不再赘述
如果需要匹配真正的星号字符,就在正则表达式的星号字符前加上倒斜杠,即\*。
2.5 用加号匹配一次或多次
*意味着“匹配零次或多次”,+(加号)则意味着“匹配一次或多次”。星号不要求 分组出现在匹配的字符串中,但加号不同,加号前面的分组必须“至少出现一次”。这不 是可选的。
譬如
import re
passwordRegex = re.compile(r'(\d)+')
# 虽然不严谨,我们将但凡出现过数字的一串数字(即便只有一个)作为我们需要寻找的密码
mo1 = passwordRegex.search('我是密码!') # 理应返回None
mo2 = passwordRegex.search('我的密码是1314!') # 返回1314

感觉说的不清楚,再来一个吧
import re
greetRegex = re.compile(r'(hello)+Zhang')
greet = greetRegex.search('Zhang, nice to meet you!')
2.6 用花括号匹配特定次数
如果想要一个分组重复特定次数,就在正则表达式中该分组的后面,跟上花括号包围的数字。
一个正则表达式你可以这样子写r'lovelovelove' 也许你也会这样子写r'(love){3}'
你也许会说大可不必,那么我觉得你说得对
譬如:
import re
loveRegex = re.compile(r'(love){3}')
love = loverRegex.search('you are my lovelovelovelove!')
# 虽然这里重复出现四次love,但是{3}限定了它只能返回前三个love
另外,你也可以取定区间(或者范围) 即在花括号中写下一个最小值、一个逗号和 一个最大值来写正则表达式
譬如:
import re
loveRegex = re.compile(r'(love){3,5}')
# 格外注意:这里区间其包括3,也包括5,而且逗号两边只能是最大值和最小值,不能留有空格
love = loveRegex.search('you are my lovelovelovelove')
上面r'(love){3,5}' 等价于 r'lovelovelove|lovelovelovelove|lovelovelovelovelove'
你不屑一顾,继续用着老套的方法...
3.贪心和非贪心匹配
从上一个代码我们知道,虽然(love){3,5},但是如果search()传入的字符串中有四个love,那么它就不会返回三个love,这就是正则表达式的'贪心'之处
Python 的正则表达式默认是“贪心”的,这表示在有二义的情况下,它们会尽可能匹配最长的字符串。花括号的“非贪心”版本匹配尽可能最短的字符串,即在 结束的花括号后跟着一个问号。
譬如:拿上面的代码稍作修改
import re
loveRegex = re.compile(r'(love){3,5}?')
# 格外注意:这里区间其包括3,也包括5,而且逗号两边只能是最大值和最小值,不能留有空格
love = loveRegex.search('you are my lovelovelovelove') 
这样子就是'不贪心'版本,即尽可能匹配最短的字符串
4.findall()方法
前面的search()方法我们知道,是取第一个满足正则表达式的正则表达式模式,那么我们要是想寻找所有满足正则表达式的正则表达式模式该怎么办呢?
这里就要用到Regex对象的第二个方法--findall() 也挺好记忆,find all 找到所有
另外另一方面,findall()不是返回一个 Match 对象,而是返回一个字符串列表,只要 在正则表达式中没有分组。
譬如:
import re
# 假使你要寻找所有电话号码,那么必然需要用到findall()方法,search()方法显然心有余而力不足
phoneRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phoneRegex.findall('My number is 233-411-4567, your number is 789-567-3124')

那么我们不禁要问,如果正则表达式分组又会怎么样呢?
如果在正则表达式中有分组,那么 findall 将返回元组的列表。每个元组表示一个找到的匹配,其中的项就是正则表达式中每个分组的匹配字符串
譬如:上述代码稍作修改
import re
phoneRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') # 分组
mo = phoneRegex.findall('My number is 233-411-4567, your number is 789-567-3124')
5. 字符分类
之前的学习我们已经知道\d代表一个任意数字(\d 是正则表达式(0|1|2|3|4|5|6|7|8|9)的缩写), 那么接下来我们会了解更多这类知识
\d 0 到 9 的任何数字
\D 除 0 到 9 的数字以外的任何字符
\w 任何字母、数字或下划线字符(可以认为是匹配“单词”字符)
\W 除字母、数字和下划线以外的任何字符
\s 空格、制表符或换行符(可以认为是匹配“空白”字符)
\S 除空格、制表符和换行符以外的任何字符
假使我们得到一份菜单文本,那么我们可以提取里面有用的信息
import re
foodRegex = re.compile(r'\w+\s\d+\W')
# 我们模拟的是形如 baicai 12¥
# 尽管这十分不严谨,但已经初具模型
food = foodRegex.findall('家人们,朋友们,本店新推出菜品: baicai 12¥,
... qincai 8¥, baocai 9¥, huanghuacai 5¥, youcai 7¥')
6. 建立自己的字符分类
显然,我们依旧觉得上述字符分类不够清晰, 因为\d, \w, \s的范围太过宽泛了。
当然我们可 以用方括号定义自己的字符分类
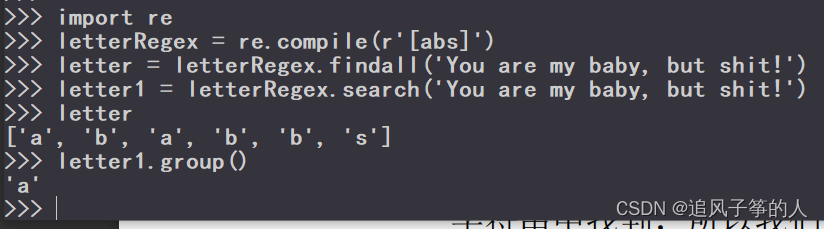
譬如:字符分类[abs] 将匹配的a,b,s字母
import re
letterRegex = re.compile(r'[abs]')
letter = letterRegex.findall('You are my baby, but shit!')
letter1 = letterRegex.search('You are my baby, but shit!')
也可以使用短横表示字母或数字的范围
譬如:字符分类[a-zA-Z0-9]将匹配所 有小写字母、大写字母和数字
请注意,在方括号内,普通的正则表达式符号不会被解释。这意味着,你不需 要前面加上倒斜杠转义.、*、?或()字符。例如,字符分类将匹配数字 0 到 5 和一个 句点。你不需要将它写成[0-5\.]。
通过在字符分类的左方括号后加上一个插入字符(^),就可以得到“非字符类”。 非字符类将匹配不在这个字符类中的所有字符。
譬如:[^abs]匹配的是除a, b, s之外的其它字符
7. 插入字符和美元字符
可以在正则表达式的开始处使用插入符号(^),表明匹配必须发生在被查找文本开始处。
譬如:正则表达式为r'^hello' 意思就是在方法search()中传入字符串,如果该字符串在一开头处就是hello,那么它符合正则表达式,它将作为match对象被返回(此处返回给了greet和greet1变量);但是如果有一个hello在字符串中间某一位置,虽然它也是hello,但是它不满足位置关系,^决定了只有在字符串开头且为hello才满足该正则表达式
import re
greetRegex = re.compile(r'^hello')
greet = greetRegex.search('hello, nice to meet you!')
greet1 = greetRegex.search('nice tp meet you, hello')

类似地,可以再正则表达式的末尾加上美元符号($),表示该字符串必须以这个正则表达式的模式结束。
譬如: 正则表达式为r'hello$' 意思为在方法search()传入的字符串, 如果该字符串在结尾处以hello结尾,那么这个hello将作为match()被返回(此处返回给了greet和greet1变量);那如果,在传入的字符串中开头处或者中间有hello出现,它不会被返回,虽然它也是hello, 但是它的位置不在字符串的结尾处,所以不满足正则表达式。
import re
greetRegex = ree.compile(r'hello$')
greet = greetRegex.search('woooo, hello, nice to meet you')
greet1 = greetRegex.search('woooo, nice to meet you, hello')

8. 通配字符
在正则表达式中,.(句点)字符称为“通配符”。它匹配除了换行之外的所有字符。
譬如:
import re
btRegex = re.compile(r'.bt')
bt = btRegex.search('i dont know meaning of abt, sbt, -bt, ~bt, )bt!')
bt1 = btRegex.findall('i dont know meaning of abt, sbt, -bt, ~bt, )bt!')

8.1 用点-星匹配所有字符
如果你想找这样子的内容:姓名:张雨婷 年级:大一
这里面姓名: 年级: 是固定的, 其他的内容则是完全不知道, 这个时候我们就需要用到点-星来匹配所有字符
讲解一下点星(.*)是什么吧,它表示任意文本
我们知道,.(句点)可以代表任意字符(换行除外), *表示出现零次或者多次
那么两个字符合起来的意思就是表示任意文本内容,这样子就可以满足我们上面寻找姓名,年级的要求了
import re
stuRegex = re.compile(r'姓名:.* 年级:.*')
stu = stuRegex.findall('姓名:张雨婷 年级:大一, 姓名:何泽煌 年级:大一')

点-星(.*)默认使用贪心模式:即尽可能多的匹配文本;若要要用非贪心模式尽可能匹配更短的字符,那么就需要在点-星后加上问号(.*?) 。
譬如:
import re
jkRegex = re.compile(r'<.*>')
jk = jkRegex.search('<girl is so beautiful> but not my friend>') 
import re
jkRegex = re.compile(r'<.*?>')
jk = jkRegex.search('<girl is so beautiful> but not my friend>')
两个正则表达式都可以翻译成“匹配一个左尖括号,接下来是任意字符,接下 来是一个右尖括号”。
不同的是一个是贪心一个不贪心模式
字符串<girl is so beautiful> but not my friend>有两种可能的匹配
贪心模式是<girl is so beautiful> but not my friend>
非贪心模式是<girl is so beautiful>
8.2 用句点字符匹配换行
之前我们知道,.(句点)可以代表任意字符(换行除外)。
但是很多情况下,我们遇到的字符串文本不只有一行,那么由于每行的结尾处有隐藏的换行符,这里可能对我们的匹配造成影响,所以我们有必要学习如何用句点字符匹配换行。
通过传入 re.DOTALL 作为 re.compile()的第 二个参数,可以让句点字符匹配所有字符,包括换行字符。
譬如:
import re
jkRegex = re.compile(r'.*')
jk = jkRegex.search('girl is good.\n but not mine')
jkRegex1 = re.compile(r'.*', re.DOTALL)
jk1 = jkRegex1.search('girl is good.\n but not mine')

jkRegex创建时没有向re.compile()传入第二个参数re.DOTALL,所以jkRege使用方法search()时将匹配一直到换行为止
jkRegex1创建时向re.compile()传入了第二个参数re.DOTALL,所以jkRegex使用方法search()时将一直匹配所有的字符串(包括换行符\n),直到没有为止
9. 不区分大小写的匹配
有时候我们希望匹配的时候不需要区分大小写。譬如用户在写一些单词时可能会不区分大小写(譬如涉及一些地名,专有名称等),那么只要她输入正确,我们仍然认为她输入正确,这个时候就需要程序忽略大小写
要让正则表达式 不区分大小写,可以向 re.compile()传入 re.IGNORECASE 或 re.I,作为第二个参数。
import re
wordRegex = re.compile('Love', re.I)
word = wordRegex.search('you are my LOVE')
word1 = wordRegex.search('you are my LovE')
10. 用 sub()方法替换字符串
正则表达式不仅能找到文本模式,而且能够用新的文本替换掉这些模式
Regex 对象的 sub()方法需要传入两个参数。第一个参数是一个字符串,用于取代发现的匹配。第二个参数是一个字符串,即正则表达式。sub()方法返回替换完成后的字符串。
譬如:
import re
girlRegex = re.compile(r'girl')
girl = girlRegex.sub('张玉婷', 'that girl is my Lover')
有时候,你可能需要使用匹配的文本本身,作为替换的一部分。在 sub()的第一 个参数中,可以输入\1、\2、\3……。表示“在替换中输入分组 1、2、3……的文本”
也就是说
import re
girlRegex = re.compile(r'(girl-).{3}')
girl = girlRegex.sub(r'\1***', 'that girl-张雨婷 is my Lover') 
11. 管理复杂的正则表达式
管理复杂的正则表达式 如果要匹配的文本模式很简单,正则表达式就很好。但匹配复杂的文本模式, 可能需要长的、费解的正则表达式。你可以告诉 re.compile(),忽略正则表达式字符串中的空白符和注释,从而缓解这一点。要实现这种详细模式,可以向 re.compile() 传入变量 re.VERBOSE,作为第二个参数。
import re
phoneRegex = re.compile(r'''
(\d{3})? # 电话号码前三个数字
(\s|-|\.)? # 电话号码分隔符
# 问号表示前面的整个括号内的内容是可选的,这里两个都标上问号,是因为有的电话号码会忽略前三个数字
(\d{3}) # 电话号码中间三个数字
(\s|-|\.) # 电话号码分隔符
(\d{4}) # 电话号码最后四个数字
''', re.VERBOSE)
请注意,前面的例子使用了三重引号('"),创建了一个多行字符串。这样就可以 将正则表达式定义放在多行中,让它更可读。
正则表达式字符串中的注释规则,与普通的 Python 代码一样:#符号和它后面直 到行末的内容,都被忽略。而且,表示正则表达式的多行字符串中,多余的空白字符 也不认为是要匹配的文本模式的一部分。这让你能够组织正则表达式,让它更可读。
12.组合使用 re.IGNOREC ASE、re.DOTALL 和 re.VERBOSE
如果你希望在正则表达式中使用 re.VERBOSE 来编写注释,还希望使用 re.IGNORECASE 来忽略大小写,该怎么办?遗憾的是,re.compile()函数只接受一 个值作为它的第二参数。可以使用管道字符(|)将变量组合起来,从而绕过这个限 制。管道字符在这里称为“按位或”操作符。
所以,如果希望正则表达式不区分大小写,并且需要在正则表达式内注释,以及句点字符匹配换行:
import re
someRegex = re.compile(r'Love', re.DOTALL | re.IGNORECASE |re.VERBOSE)看到了这里,相信我已经将正则表达式的基本知识掌握了,加油!
真累啊!!!!!!!!!!!!!!!!!!!!!!!!!!!















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











