







代码上传至Github库:https://github.com/ChaoQiezi/CNN-LSTM-model-is-used-to-predict-NDVI
2024/7/4-Note:由于中途研究内容发生变化(但是这部分博客是一直在记录只是未公开可能前期部分内容产生一点误解特别是标题源标题为:《遥感&深度学习:CNN-LSTM模型用于NDVI的预测(Pytorch代码深度剖析)》),所以实际上本项目(我的工作部分)主要是借LSTM模型探究了各个特征因子对NDVI重要性/贡献率的研究,因此对于预测结果可能不如大家所想的一样可以进行直接生成预测的二维结果图像(但是经过对数据集代码划分和预测部分的代码部分修改也是可以实现的)。它是将二维影像的数据一维化,每个像元即是单个样本,至于CNN则是时间上进行一维卷积也就是说没有空间上所想的卷积核或者算子进行二维滑动卷积的卷积层。当然预测是肯定是做了的,但是预测的结果也是一维化的,但是由于我的输入样本是乱序的,因此预测的结果也是乱序的,因此需要在前面数据集划分那里做一部分改进等等,但是由于按我这部分的要求我所需要完成的内容是将预测的结果与实际结果进行比对即计算各种评估指标,接着继续将输入样本中的某一个特征值全部乱序排列打乱再次训练和预测计算评估指标,继续计算评估指标,以此来得到各个特征重要性或者对于ndvi的贡献率。给大家造成误解抱歉,但是代码部分无心修改,大家可以自行尝试。
具体内容见:https://www.frontiersin.org/journals/forests-and-global-change/articles/10.3389/ffgc.2024.1417737/full
《Quantifying nonlinear responses of vegetation to hydro-climatic changes in mountainous Southwest China》
(https://doi.org/10.3389/ffgc.2024.1417737)
01 前言
这是一次完整的关于时空遥感影像预测相关的深度学习项目,后续有时间更新后续部分。
通过这次项目,你可以了解:
- pytroch的模型的基本使用包括LSTM和Linear等的框架构建、训练评估和预测;
- 遥感影像如何传入模型中训练,包括数据加载和预输入的要求等,对于大型数据集如何解决内存不足问题(可能会更新);
- 遥感图像的处理例如裁剪掩膜,nc读取相关数据集并glt校正输出为tiff文件等诸多处理。
本次项目使用的数据集包括:
Landuse(年土地利用): 2001 - 2020
LST(月均地表温度): 200002 - 202210
NDVI(月均植被指数): 200002 - 202010
ET(月蒸散发量): 200204 - 202309
PRCP(月降水量): 200204 - 202309
Qs(地表径流量): 200204 - 202309
Qsb(地下径流量): 200204 - 202309
TWSC: 200204 - 202309
DEM: single
上述Landuse、LST、NDVI数据集通过MCD12Q1、MOD11A2、MOD13A2数据集处理得到,ET、PRCP、Qs、Qsb、TWSC是由Global GLDAS数据集处理得到,DEM不清楚(可能是美国调查局下载得到)。
实际上可能2002年及之前的数据集无法正常使用,一来是对于2001年部分数据集完全不存在例如GLDAS数据集得到的各个特征项,而对于2002年由于时间范围与后续年份不一致,2002年各个特征项的时间交集是2002年4月份之后,与其它年份不一致(实际上或许2023年数据集同样无法正常使用),无法使用的原因是因为模型构建考虑到了数据集的时间性,换句话说,传入的数据集是一个时间序列数据集,因此需要保证时间序列长度一致也就是时间范围的一致性。
注意:此处CNN-LSTM模型并非ConvLSTM即不涉及图像的卷积操作,此处的CNN为一维卷积且在时间维度上进行因果卷积,因此虽然本数据集使用到大量的影像数据,但是实际上并没有考虑到空间上各个像元的关联性,而仅仅是从时间关系和各个特征项入手解决ndvi的预测。
项目使用模块:
| 模块 | 版本 |
|---|---|
| numpy | 1.24.4 |
| pyhdf | 0.10.5 |
| gdal | 3.4.3 |
| xarray | 2023.1.0 |
| h5py | 3.9.0 |
| matplotlib | 3.7.2 |
| pytorch | 2.1.1+cu121 |
| torch-summary | 1.4.5 |
(注意torch-summary是torchsummary的增强版,是两个不同但相似的模块, 前者有更好的兼容性)
python相关信息: 3.8.9 (tags/v3.8.9:a743f81, Apr 6 2021, 14:02:34) [MSC v.1928 64 bit (AMD64)]
关于模型Note:需要注意的是,由于时间原因,我的定义的模型输入是利用对应年份的因子变量和对应年份的NDVI建立联系,虽然说是预测,但是由于项目其他部分我并没有涉及太深,我只知道我需要搭建一个模型去建立因子变量和NDVI的关系,但是我认为实际去预测时可能存在问题,特别是时间上,想一想,我假定需要知道今年的NDVI,但是今年还没有离去,我也无法拿到今年的因子数据,因此今年的NDVI我也永远要等到明年才可以预测,但是明年的我往往可以选择直接下载今年的NDVI,不是吗?当然,这个和研究有关系,在这个项目里,并没有涉及这个问题,因为我们更多的是想要探究NDVI与因子变量的关系,而非做预测。换言之,在项目负责人那里,我仅仅需要提交一份谁与NDVI关系更为密切,谁更冷漠。
至于其它,后面如有想起再补充。
02 模型的定义(理论阐述部分)
可以发现,目前的数据集其实分为两大类,第一类是动态特征例如LST、NDVI、ET这类与时间相关的特征项,第二类是静态特征即本项目中的DEM、Landuse。这里稍微存在疑惑就是Landuse,确实,Landuse随时间变化即使比较缓慢,但是将其划分为静态特征一来是其像元值没有可比较性也就是它的像元值仅仅作为类别存在,二来是我们的训练样本的时间步也就是时间范围即一年,在训练样本的所有时间步其Landuse实际上为定值,因此将其划分为静态特征。
但是,这有什么用呢?这涉及到我们CNN-LSTM模型的定义部分,其中的LSTM要求各个特征项具有相同的时间步,但是如果我们存在一些特征项它不随时间变化但是我们认为它对于目标项的预测也非常重要,那应该怎么解决呢?这就涉及到了两种特征的处理了。具体处理我们暂时不详细阐述,后续会说明,这里我们主要关注两部分特征是如何输入到模型中的,再输入之前,需要查看一下模型的框架结构:
In [37]: summary(model, input_data=[(12, 6), (2,)])
Out[37]:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Conv1d: 1-1 [-1, 64, 12] 1,216
├─LSTM: 1-2 [-1, 12, 128] 363,520
├─Linear: 1-3 [-1, 64] 192
├─Linear: 1-4 [-1, 12] 1,548
==========================================================================================
Total params: 366,476
Trainable params: 366,476
Non-trainable params: 0
Total mult-adds (M): 0.38
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.02
Params size (MB): 1.40
Estimated Total Size (MB): 1.42
==========================================================================================
这是模型的定义代码:
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.causal_conv1d = nn.Conv1d(input_size, 64, 3)
self.fc1 = nn.Linear(2, 64)
self.rnn = nn.LSTM(64, hidden_size, num_layers, batch_first=True)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, dynamic_x, static_x):
# 因果卷积
conv1d_out = self.causal_conv1d(F.pad(torch.transpose(dynamic_x, 1, 2), (2, 0)))
# LSTM层
lstm_out, _ = self.rnn(torch.transpose(conv1d_out, 1, 2))
# 只使用最后一个时间步的输出
lstm_out = lstm_out[:, -1, :] # (-1, 128)
static_out = self.fc1(static_x) # (-1, 2) ==> (-1, 64)
merged_out = torch.cat([lstm_out, static_out], dim=1)
# 全连接层
out = self.fc2(lstm_out)
return out
很简单的模型,暂时不考虑模型的复杂性和调参等,目前主要是把模型跑通,了解整个项目两个入门目标一是lstm的简单使用二是遥感图像的处理。
可以发现,我们需要输入两个特征项,分别是dynamic_x, static_x,其shape分别是(样本数,时间步,特征数),(样本数,特征数),可以发现,静态特征是通过嵌入的方式与动态特征输入LSTM层的输出张量进行拼接。
这里关于静态特诊和动态特诊的处理实际上参考:https://blog.csdn.net/yanghe4405/article/details/131036778
上述部分是整个项目的核心,一切以它为核心,至于其他都是关于遥感影像的处理以及输入和输出。
03 遥感影像预处理
3.1 检查下载影像的完整性
我一直认为这是非常之有必要的事情,这其实在一定程度上会影响后续的返工甚至由于忽略数据的缺失导致模型训练的失败。
目前我手上有下载的2001-2021年的MODIS产品,包括MCD12Q1(土地利用数据)、MOD11A2(地表温度数据)、MOD13A2(NDVI&EVI,本项目我们仅需要其中的NDVI数据)。
Note:如果不是为了简单查看数据、了解数据,而是希望借数据进行科学研究,并且涉及的时间序列比较长,那么建议不建议使用地理空间数据云。一是多次遇到数据不完整导致重新返工的情况;二是遇到大批量数据下载时没有提供批量下载的方式,而需要自己爬取链接下载不方便;(当然,我作为初学者时它确实为我提供了很大的便利,使我能够快速上手了解各种数据产品)
这是各个数据产品的样式:



# @Author : ChaoQiezi
# @Time : 2023/12/7 15:07
# @FileName : check_datasets.py
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 用于检查数据完整性, 包括MCD12Q1、MOD11A2、MOD13A2
-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-
拓展: MYD\MOD\MCD
MOD标识Terra卫星
MYD标识Aqua卫星
MCD标识Terra和Aqua卫星的结合
-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-·-
拓展: MCD12Q1\MOD11A2\MOD13A2
MCD12Q1为土地利用数据
MOD11A2为地表温度数据
MOD13A2为植被指数数据(包括NDVI\EVI)
"""
import os.path
import glob
from datetime import datetime, timedelta
# 准备
in_dir = r'F:\Cy_modis'
searching_ds_wildcard = ['MCD12Q1', 'MOD11A2', 'MOD13A2']
# 检查MCD12Q1数据集
error_txt = os.path.join(in_dir, 'MCD12Q1_check_error.txt')
ds_name_wildcard = 'MCD12Q1*'
region_wildcard = ['h26v05', 'h26v06', 'h27v05', 'h27v06']
with open(error_txt, 'w+') as f:
for year in range(2001, 2021):
for region in region_wildcard:
cur_ds_name_wildcard = ds_name_wildcard + 'A{}*'.format(year) + region + '*.hdf'
ds_path_wildcard = os.path.join(in_dir, '**', cur_ds_name_wildcard)
hdf_paths = glob.glob(ds_path_wildcard, recursive=True)
if len(hdf_paths) != 1:
f.write('{}: 文件数目(为: {})不正常\n'.format(cur_ds_name_wildcard, len(hdf_paths)))
if not f.read():
f.write('MCD12Q1数据集文件数正常')
# 检查MOD11A2数据集
error_txt = os.path.join(in_dir, 'MOD11A2_check_error.txt')
ds_name_wildcard = 'MOD11A2*'
region_wildcard = ['h26v05', 'h26v06', 'h27v05', 'h27v06']
start_date = datetime(2000, 1, 1) + timedelta(days=48)
end_date = datetime(2022, 1, 1) + timedelta(days=296)
with open(error_txt, 'w+') as f:
cur_date = start_date
while cur_date <= end_date:
cur_date_str = cur_date.strftime('%Y%j')
for region in region_wildcard:
cur_ds_name_wildcard = ds_name_wildcard + 'A{}*'.format(cur_date_str) + region + '*.hdf'
ds_path_wildcard = os.path.join(in_dir, '**', cur_ds_name_wildcard)
hdf_paths = glob.glob(ds_path_wildcard, recursive=True)
if len(hdf_paths) != 1:
f.write('{}: 文件数目(为: {})不正常\n'.format(cur_ds_name_wildcard, len(hdf_paths)))
if (cur_date + timedelta(days=8)).year != cur_date.year:
cur_date = datetime(cur_date.year + 1, 1, 1)
else:
cur_date += timedelta(days=8)
if not f.read():
f.write('MOD11A2数据集文件数正常')
# 检查MOD13A2数据集
error_txt = os.path.join(in_dir, 'MOD13A2_check_error.txt')
ds_name_wildcard = 'MOD13A2*'
region_wildcard = ['h26v05', 'h26v06', 'h27v05', 'h27v06']
start_date = datetime(2000, 1, 1) + timedelta(days=48)
end_date = datetime(2020, 1, 1) + timedelta(days=352)
with open(error_txt, 'w+') as f:
cur_date = start_date
while cur_date <= end_date:
cur_date_str = cur_date.strftime('%Y%j')
for region in region_wildcard:
cur_ds_name_wildcard = ds_name_wildcard + 'A{}*'.format(cur_date_str) + region + '*.hdf'
ds_path_wildcard = os.path.join(in_dir, '**', cur_ds_name_wildcard)
hdf_paths = glob.glob(ds_path_wildcard, recursive=True)
if len(hdf_paths) != 1:
f.write('{}: 文件数目(为: {})不正常\n'.format(cur_ds_name_wildcard, len(hdf_paths)))
if (cur_date + timedelta(days=16)).year != cur_date.year:
cur_date = datetime(cur_date.year + 1, 1, 1)
else:
cur_date += timedelta(days=16)
if not f.read():
f.write('MOD13A2数据集文件数正常')
3.2 处理MODIS产品
这部分内容在之前博客有提及,这里就不再详细说明了:https://blog.csdn.net/m0_63001937/article/details/134995867(可能存在收费,我也没法取消,请移至链接提及处看嘛)
# @Author : ChaoQiezi
# @Time : 2023/12/14 6:31
# @FileName : process_modis.py
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 对MODIS GRID产品(hdf4文件)进行批量镶嵌和重投影并输出为GeoTIFF文件
<说明>
# pyhdf模块相关
对于读取HDF4文件的pyhdf模块需要依据python版本安装指定的whl文件才可正常运行,
下载wheel文件见: https://www.lfd.uci.edu/~gohlke/pythonlibs/
安装: cmd ==> where python ==> 跳转指定python路径 ==> cd Scripts ==> pip install wheel文件的绝对路径
# 数据集
MCD12Q1为土地利用数据
MOD11A2为地表温度数据
MOD13A2为植被指数数据(包括NDVI\EVI)
# 相关链接
CSDN博客: https://blog.csdn.net/m0_63001937/article/details/134995867
微信博文: https://mp.weixin.qq.com/s/6oeUEdazz8FL1pRnQQFhMA
"""
import os
import re
import time
from glob import glob
from typing import Union
from datetime import datetime
from math import ceil, floor
from threading import Lock
from concurrent.futures import ThreadPoolExecutor # 线程池
import numpy as np
from pyhdf.SD import SD
from osgeo import gdal, osr
from scipy import stats
def img_mosaic(mosaic_paths: list, mosaic_ds_name: str, return_all: bool = True, img_nodata: Union[int, float] = -1,
img_type: Union[np.int32, np.float32, None] = None, unit_conversion: bool = False,
scale_factor_op: str = 'multiply', mosaic_mode: str = 'last'):
"""
该函数用于对列表中的所有HDF4文件进行镶嵌
:param mosaic_mode: 镶嵌模式, 默认是Last(即如果有存在像元重叠, mosaic_paths中靠后影像的像元将覆盖其),
可选: last, mean, max, min
:param scale_factor_op: 比例因子的运算符, 默认是乘以(可选: multiply, divide), 该参数尽在unit_conversion为True时生效
:param unit_conversion: 是否进行单位换算
:param mosaic_ds_name: 待镶嵌的数据集名称
:param mosaic_paths: 多个HDF4文件路径组成的字符串列表
:param return_all: 是否一同返回仿射变换、镶嵌数据集的坐标系等参数
:return: 默认返回镶嵌好的数据集
:param img_type: 待镶嵌影像的数据类型
:param img_nodata: 影像中的无效值设置
镶嵌策略是last模式,
"""
# 获取镶嵌范围
x_mins, x_maxs, y_mins, y_maxs = [], [], [], []
for mosaic_path in mosaic_paths:
hdf = SD(mosaic_path) # 默认只读
# 获取元数据
metadata = hdf.__getattr__('StructMetadata.0')
# 获取角点信息
ul_pt = [float(x) for x in re.findall(r'UpperLeftPointMtrs=\((.*)\)', metadata)[0].split(',')]
lr_pt = [float(x) for x in re.findall(r'LowerRightMtrs=\((.*)\)', metadata)[0].split(',')]
x_mins.append(ul_pt[0])
x_maxs.append(lr_pt[0])
y_mins.append(lr_pt[1])
y_maxs.append(ul_pt[1])
else:
# 计算分辨率
col = int(re.findall(r'XDim=(.*?)\n', metadata)[0])
row = int(re.findall(r'YDim=(.*?)\n', metadata)[0])
x_res = (lr_pt[0] - ul_pt[0]) / col
y_res = (ul_pt[1] - lr_pt[1]) / row
# 如果img_type没有指定, 那么数据类型默认为与输入相同
if img_type is None:
img_type = hdf.select(mosaic_ds_name)[:].dtype
# 获取数据集的坐标系参数并转化为proj4字符串格式
projection_param = [float(_param) for _param in re.findall(r'ProjParams=\((.*?)\)', metadata)[0].split(',')]
mosaic_img_proj4 = "+proj={} +R={:0.4f} +lon_0={:0.4f} +lat_0={:0.4f} +x_0={:0.4f} " \
"+y_0={:0.4f} ".format('sinu', projection_param[0], projection_param[4], projection_param[5],
projection_param[6], projection_param[7])
# 关闭文件, 释放资源
hdf.end()
x_min, x_max, y_min, y_max = min(x_mins), max(x_maxs), min(y_mins), max(y_maxs)
# 镶嵌
col = ceil((x_max - x_min) / x_res)
row = ceil((y_max - y_min) / y_res)
mosaic_imgs = [] # 用于存储各个影像
for ix, mosaic_path in enumerate(mosaic_paths):
mosaic_img = np.full((row, col), img_nodata, dtype=img_type) # 初始化
hdf = SD(mosaic_path)
target_ds = hdf.select(mosaic_ds_name)
# 读取数据集和预处理
target = target_ds.get().astype(img_type)
valid_range = target_ds.attributes()['valid_range']
target[(target < valid_range[0]) | (target > valid_range[1])] = img_nodata # 限定有效范围
if unit_conversion: # 进行单位换算
scale_factor = target_ds.attributes()['scale_factor']
add_offset = target_ds.attributes()['add_offset']
# 判断比例因子的运算符
if scale_factor_op == 'multiply':
target[target != img_nodata] = target[target != img_nodata] * scale_factor + add_offset
elif scale_factor_op == 'divide':
target[target != img_nodata] = target[target != img_nodata] / scale_factor + add_offset
# 计算当前镶嵌范围
start_row = floor((y_max - (y_maxs[ix] - x_res / 2)) / y_res)
start_col = floor(((x_mins[ix] + x_res / 2) - x_min) / x_res)
end_row = start_row + target.shape[0]
end_col = start_col + target.shape[1]
mosaic_img[start_row:end_row, start_col:end_col] = target
mosaic_imgs.append(mosaic_img)
# 释放资源
target_ds.endaccess()
hdf.end()
# 判断镶嵌模式
if mosaic_mode == 'last':
mosaic_img = mosaic_imgs[0].copy()
for img in mosaic_imgs:
mosaic_img[img != img_nodata] = img[img != img_nodata]
elif mosaic_mode == 'mean':
mosaic_imgs = np.asarray(mosaic_imgs) # mosaic_img.shape = (mosaic_num, rows, cols)
mask = mosaic_imgs == img_nodata
mosaic_img = np.ma.array(mosaic_imgs, mask=mask).mean(axis=0).filled(img_nodata)
elif mosaic_mode == 'max':
mosaic_imgs = np.asarray(mosaic_imgs) # mosaic_img.shape = (mosaic_num, rows, cols)
mask = mosaic_imgs == img_nodata
mosaic_img = np.ma.array(mosaic_imgs, mask=mask).max(axis=0).filled(img_nodata)
elif mosaic_mode == 'min':
mosaic_imgs = np.asarray(mosaic_imgs) # mosaic_img.shape = (mosaic_num, rows, cols)
mask = mosaic_imgs == img_nodata
mosaic_img = np.ma.array(mosaic_imgs, mask=mask).min(axis=0).filled(img_nodata)
else:
raise ValueError('不支持的镶嵌模式: {}'.format(mosaic_mode))
if return_all:
return mosaic_img, [x_min, x_res, 0, y_max, 0, -y_res], mosaic_img_proj4
return mosaic_img
def img_warp(src_img: np.ndarray, out_path: str, transform: list, src_proj4: str, out_res: float,
nodata: Union[int, float] = None, resample: str = 'nearest') -> None:
"""
该函数用于对正弦投影下的栅格矩阵进行重投影(GLT校正), 得到WGS84坐标系下的栅格矩阵并输出为TIFF文件
:param src_img: 待重投影的栅格矩阵
:param out_path: 输出路径
:param transform: 仿射变换参数([x_min, x_res, 0, y_max, 0, -y_res], 旋转参数为0是常规选项)
:param out_res: 输出的分辨率(栅格方形)
:param nodata: 设置为NoData的数值
:param out_type: 输出的数据类型
:param resample: 重采样方法(默认是最近邻, ['nearest', 'bilinear', 'cubic'])
:param src_proj4: 表达源数据集(src_img)的坐标系参数(以proj4字符串形式)
:return: None
"""
# 输出数据类型
if np.issubdtype(src_img.dtype, np.integer):
out_type = gdal.GDT_Int32
elif np.issubdtype(src_img.dtype, np.floating):
out_type = gdal.GDT_Float32
else:
raise ValueError("当前待校正数组类型为不支持的数据类型")
resamples = {'nearest': gdal.GRA_NearestNeighbour, 'bilinear': gdal.GRA_Bilinear, 'cubic': gdal.GRA_Cubic}
# 原始数据集创建(正弦投影)
driver = gdal.GetDriverByName('MEM') # 在内存中临时创建
src_ds = driver.Create("", src_img.shape[1], src_img.shape[0], 1, out_type) # 注意: 先传列数再传行数, 1表示单波段
srs = osr.SpatialReference()
srs.ImportFromProj4(src_proj4)
"""
对于src_proj4, 依据元数据StructMetadata.0知:
Projection=GCTP_SNSOID; ProjParams=(6371007.181000,0,0,0,0,0,0,0,0,0,0,0,0)
或数据集属性(MODIS_Grid_8Day_1km_LST/Data_Fields/Projection)知:
:grid_mapping_name = "sinusoidal";
:longitude_of_central_meridian = 0.0; // double
:earth_radius = 6371007.181; // double
"""
src_ds.SetProjection(srs.ExportToWkt()) # 设置投影信息
src_ds.SetGeoTransform(transform) # 设置仿射参数
src_ds.GetRasterBand(1).WriteArray(src_img) # 写入数据
src_ds.GetRasterBand(1).SetNoDataValue(nodata)
# 重投影信息(WGS84)
dst_srs = osr.SpatialReference()
dst_srs.ImportFromEPSG(4326)
# 重投影
dst_ds = gdal.Warp(out_path, src_ds, dstSRS=dst_srs, xRes=out_res, yRes=out_res, dstNodata=nodata,
outputType=out_type, multithread=True, format='GTiff', resampleAlg=resamples[resample])
if dst_ds: # 释放缓存和资源
dst_ds.FlushCache()
src_ds, dst_ds = None, None
def ydays2ym(file_path: str) -> str:
"""
获取路径中的年积日并转化为年月日
:param file_path: 文件路径
:return: 返回表达年月日的字符串
"""
file_name = os.path.basename(file_path)
ydays = file_name[9:16]
date = datetime.strptime(ydays, "%Y%j")
return date.strftime("%Y_%m")
# 闭包
def process_task(union_id, process_paths, ds_name, out_dir, description, nodata, out_res, resamlpe='nearest',
temperature=False, img_type=np.float32, unit_conversion=True, scale_factor_op='multiply',
mosaic_mode='last'):
print_lock = Lock() # 线程锁
# 处理
def process_id(id: any = None):
start_time = time.time()
cur_mosaic_ixs = [_ix for _ix, _id in enumerate(union_id) if _id == id]
# 镶嵌
mosaic_paths = [process_paths[_ix] for _ix in cur_mosaic_ixs]
mosaic_img, transform, mosaic_img_proj4 = img_mosaic(mosaic_paths, ds_name, img_nodata=nodata,
img_type=img_type, unit_conversion=unit_conversion,
scale_factor_op=scale_factor_op, mosaic_mode=mosaic_mode)
if temperature: # 若设置temperature, 则说明当前处理数据集为地表温度, 需要开尔文 ==> 摄氏度
mosaic_img[mosaic_img != nodata] -= 273.15
# 重投影
reproj_path = os.path.join(out_dir, description + '_' + id + '.tiff')
img_warp(mosaic_img, reproj_path, transform, mosaic_img_proj4, out_res, nodata, resample=resamlpe)
end_time = time.time()
with print_lock: # 避免打印混乱
print("{}-{} 处理完毕: {:0.2f}s".format(description, id, end_time - start_time))
return process_id
# 准备
in_dir = 'F:\DATA\Cy_modis' # F:\Cy_modis\MCD12Q1_2001_2020、F:\Cy_modis\MOD11A2_2000_2022、F:\Cy_modis\MOD13A2_2001_2020
out_dir = 'H:\Datasets\Objects\Veg'
landuse_name = 'LC_Type1' # Land Cover Type 1: Annual International Geosphere-Biosphere Programme (IGBP) classification
lst_name = 'LST_Day_1km'
ndvi_name = '1 km 16 days NDVI' # 注意panoply上显示为: 1_km_16_days_NDVI, 实际上是做了显示上的优化, 原始名称为当前
evi_name = '1 km 16 days EVI' # 注意panoply上显示为: 1_km_16_days_NDVI, 实际上是做了显示上的优化, 原始名称为当前
out_landuse_res = 0.0045 # 500m
out_lst_res = 0.009 # 1000m
out_ndvi_res = 0.009
out_evi_res = 0.009
# 预准备
out_landuse_dir = os.path.join(out_dir, 'Landuse')
out_lst_dir = os.path.join(out_dir, 'LST_MIN')
out_ndvi_dir = os.path.join(out_dir, 'NDVI_MIN')
out_evi_dir = os.path.join(out_dir, 'evi')
_ = [os.makedirs(_dir, exist_ok=True) for _dir in [out_landuse_dir, out_lst_dir, out_ndvi_dir, out_evi_dir]]
# # 对MCD12Q1数据集(土地利用数据集)进行镶嵌和重投影(GLT校正)
# landuse_paths = glob(os.path.join(in_dir, '**', 'MCD12Q1*.hdf'), recursive=True) # 迭代
# union_id = [os.path.basename(_path)[9:13] for _path in landuse_paths] # 基于年份进行合并镶嵌的字段(年份-此处)
# unique_id = set(union_id) # unique_id = np.unique(np.asarray(union_id)) # 不使用set是为保证原始顺序
# # 多线程处理
# with ThreadPoolExecutor() as executer:
# start_time = time.time()
# process_id = process_task(union_id, landuse_paths, landuse_name, out_landuse_dir, 'Landuse', 255, out_landuse_res,
# img_type=np.int32, unit_conversion=False)
# executer.map(process_id, unique_id)
# end_time = time.time()
# print('MCD12Q1(土地利用数据集)预处理完毕: {:0.2f}s '.format(end_time - start_time))
# # 常规处理
# for id in unique_id:
# start_time = time.time()
# cur_mosaic_ixs = [_ix for _ix, _id in enumerate(union_id) if _id == id]
# # 镶嵌
# mosaic_paths = [landuse_paths[_ix] for _ix in cur_mosaic_ixs]
# mosaic_img, transform, mosaic_img_proj4 = img_mosaic(mosaic_paths, landuse_name, img_nodata=255, img_type=np.int32)
# # 重投影
# reproj_path = os.path.join(out_landuse_dir, 'landuse_' + id + '.tiff')
# img_warp(mosaic_img, reproj_path, transform, mosaic_img_proj4, out_landuse_res, 255, resample='nearest')
#
# # 打印输出
# end_time = time.time()
# print("Landuse-{} 处理完毕: {:0.2f}s".format(id, end_time - start_time))
# 对MOD12A2数据集(地表温度数据集)进行镶嵌和重投影(GLT校正)
lst_paths = glob(os.path.join(in_dir, '**', 'MOD11A2*.hdf'), recursive=True)
union_id = [ydays2ym(_path) for _path in lst_paths]
unique_id = set(union_id)
# 多线程处理
with ThreadPoolExecutor() as executer:
start_time = time.time()
process_id = process_task(union_id, lst_paths, lst_name, out_lst_dir, 'LST_MIN', -65535, out_lst_res, resamlpe='cubic',
temperature=True, unit_conversion=True, mosaic_mode='min')
executer.map(process_id, unique_id)
end_time = time.time()
print('MOD11A2(地表温度数据集)预处理完毕: {:0.2f}s'.format(end_time - start_time))
# # 常规处理
# for id in unique_id:
# start_time = time.time()
# cur_mosaic_ixs = [_ix for _ix, _id in enumerate(union_id) if _id == id]
# # 镶嵌
# mosaic_paths = [lst_paths[_ix] for _ix in cur_mosaic_ixs]
# mosaic_img, transform, mosaic_img_proj4 = img_mosaic(mosaic_paths, lst_name, img_nodata=-65535,
# img_type=np.float32, unit_conversion=True)
# # 开尔文 ==> 摄氏度
# mosaic_img -= 273.15
# # 重投影
# reproj_path = os.path.join(out_lst_dir, 'lst_' + id + '.tiff')
# img_warp(mosaic_img, reproj_path, transform, mosaic_img_proj4, out_lst_res, -65535, resample='cubic')
#
# # 打印输出
# end_time = time.time()
# print("LST-{} 处理完毕: {:0.2f}s".format(id, end_time - start_time))
# 对MOD13A2数据集(NDVI数据集)进行镶嵌和重投影(GLT校正)
ndvi_paths = glob(os.path.join(in_dir, '**', 'MOD13A2*.hdf'), recursive=True)
union_id = [ydays2ym(_path) for _path in ndvi_paths]
unique_id = np.unique(np.asarray(union_id))
# 多线程处理
with ThreadPoolExecutor() as executer:
start_time = time.time()
process_id = process_task(union_id, ndvi_paths, ndvi_name, out_ndvi_dir, 'NDVI_MIN', -65535, out_ndvi_res,
resamlpe='cubic', unit_conversion=True, scale_factor_op='divide', mosaic_mode='min')
executer.map(process_id, unique_id)
# end_time = time.time()
# print('MCD13A2(NDVI数据集)预处理完毕: {:0.2f}s'.format(end_time - start_time))
# 常规处理
# for id in unique_id:
# start_time = time.time()
# cur_mosaic_ixs = [_ix for _ix, _id in enumerate(union_id) if _id == id]
# # 镶嵌
# mosaic_paths = [ndvi_paths[_ix] for _ix in cur_mosaic_ixs]
# mosaic_img, transform, mosaic_img_proj4 = img_mosaic(mosaic_paths, ndvi_name, img_nodata=-65535, img_type=np.float32,
# unit_conversion=True, scale_factor_op='divide')
# # 重投影
# reproj_path = os.path.join(out_ndvi_dir, 'ndvi_' + id + '.tiff')
# img_warp(mosaic_img, reproj_path, transform, mosaic_img_proj4, out_ndvi_res, -65535, resample='cubic')
#
# # 打印输出
# end_time = time.time()
# print("NDVI-{} 处理完毕: {:0.2f}s".format(id, end_time - start_time))
# 对MOD13A2数据集(EVI数据集)进行镶嵌和重投影(GLT校正)
evi_paths = glob(os.path.join(in_dir, '**', 'MOD13A2*.hdf'), recursive=True)
union_id = [ydays2ym(_path) for _path in evi_paths]
unique_id = np.unique(np.asarray(union_id))
# 多线程处理
with ThreadPoolExecutor() as executer:
start_time = time.time()
process_id = process_task(union_id, evi_paths, evi_name, out_evi_dir, 'EVI', -65535, out_evi_res,
resamlpe='cubic', unit_conversion=True, scale_factor_op='divide', mosaic_mode='max')
executer.map(process_id, unique_id)
end_time = time.time()
print('MOD13A2(EVI数据集)预处理完毕: {:0.2f}s '.format(end_time - start_time))
3.3 处理GLDAS产品
GLDAS产品样式如下:

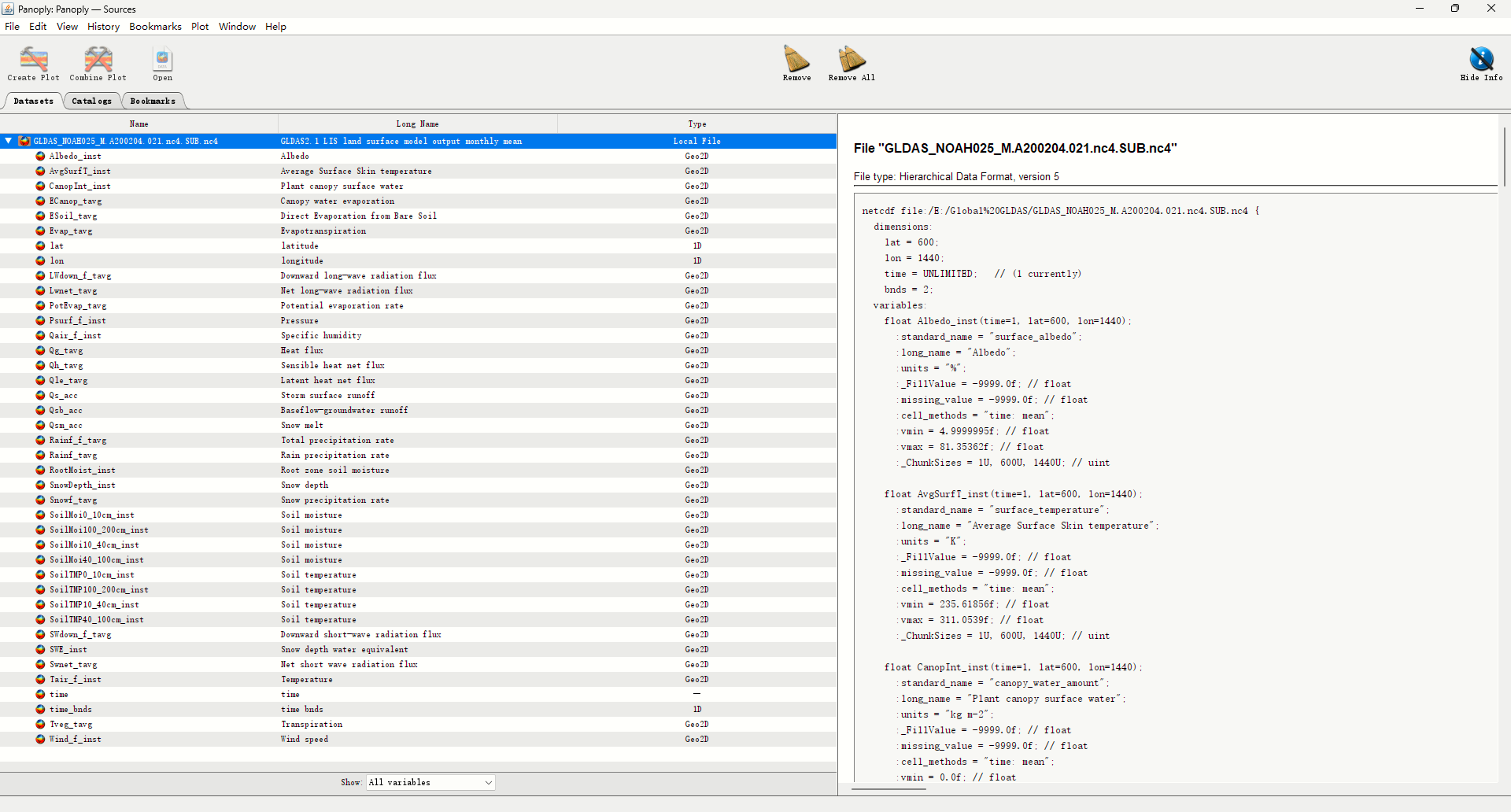
# @Author : ChaoQiezi
# @Time : 2024/1/17 12:41
# @FileName : process_gldas.py
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 预处理global gldas数据集
说明:
为确保简洁性和便捷性, 今后读取HDF5文件和NC文件均使用xarray模块而非h5py和NetCDF4模块
数据集介绍:
TWSC = 降水量(PRCP) - 蒸散发量(ET) - 径流量(即表面径流量Qs + 地下径流量Qsb) ==> 给定时间间隔内, 例如月
在gldas数据集中:
Rainf_f_tavg表示降水通量,即单位时间单位面积上的降水量(本数据集单位为kg/m2/s)
Evap_tavg表示蒸散发通量,即单位时间单位面积上的水蒸发量(本数据集单位为kg/m2/s)
Qs_acc表示表面径流量,即一定时间内通过地表流动进入河流、湖泊和水库的水量(本数据集单位为kg/m2)
Qsb_acc表示地下径流量,即一定时间内通过土壤层流动的水量,最终进入河流的水量,最终进入河流的水量(本数据集单位为kg/m2)
TWSC计算了由降水和蒸发引起的净水量变化,再减去地表和地下径流,其评估给定时间段内区域水资源变化的重要指标
存疑:
01 对于Qs和Qsb的计算, 由于数据集单位未包含/s, 是否已经是月累加值? --2024/01/18(已解决)
==> 由gldas_tws_eg.py知是: numbers of 3 hours in a month,
另外nc文件全局属性也提及:
:tavg_definision: = "past 3-hour average";
:acc_definision: = "past 3-hour accumulation";
"""
import os.path
from glob import glob
from calendar import monthrange
from datetime import datetime
import numpy as np
import xarray as xr
from osgeo import gdal, osr
# 准备
in_dir = r'E:\Global GLDAS' # 检索该文件夹及迭代其所有子文件夹满足要求的文件
out_dir = r'E:\FeaturesTargets\non_uniform'
target_names = ['Rainf_f_tavg', 'Evap_tavg', 'Qs_acc', 'Qsb_acc']
out_names = ['PRCP', 'ET', 'Qs', 'Qsb', 'TWSC']
out_res = 0.1 # default: 0.25°, base on default res of gldas
no_data_value = -65535.0 # 缺失值或者无效值的设置
# 预准备
[os.makedirs(os.path.join(out_dir, _name)) for _name in out_names if not os.path.exists(os.path.join(out_dir, _name))]
# 检索和循环
nc_paths = glob(os.path.join(in_dir, '**', 'GLDAS_NOAH025_M*.nc4'), recursive=True)
for nc_path in nc_paths:
# 获取当前月天数
cur_time = datetime.strptime(nc_path.split('.')[1], 'A%Y%m') # eg. 200204
_, cur_month_days = monthrange(cur_time.year, cur_time.month)
ds = xr.open_dataset(nc_path)
# 读取经纬度数据集和地理参数
lon = ds['lon'].values # (1440, )
lat = ds['lat'].values # (600, )
lon_res = ds.attrs['DX']
lat_res = ds.attrs['DY']
lon_min = min(lon) - lon_res / 2.0
lon_max = max(lon) + lon_res / 2.0
lat_min = min(lat) - lat_res / 2.0
lat_max = max(lat) + lat_res / 2.0
"""
注意: 经纬度数据集中的所有值均指代对应地理位置的像元的中心处的经纬度, 因此经纬度范围需要往外扩充0.5个分辨率
"""
geo_transform = [lon_min, lon_res, 0, lat_max, 0, -lat_res] # gdal要求样式
srs = osr.SpatialReference()
srs.ImportFromEPSG(4326) # WGS84
fluxs = {}
# 获取Rain_f_tavg, Evap_tavg, Qs_acc, Qsb_acc四个数据集
for target_name, out_name in zip(target_names, out_names): # 仅循环前四次
# 计算月累加值
flux = ds[target_name].values
vmin = ds[target_name].attrs['vmin']
vmax = ds[target_name].attrs['vmax']
flux[(flux < vmin) | (flux > vmax)] = np.nan # 将不在规定范围内的值设置为nan
flux = np.squeeze(flux) # 去掉多余维度
flux = np.flipud(flux) # 南北极颠倒(使之正常: 北极在上)
if target_name.endswith('acc'): # :acc_definision: = "past 3-hour accumulation";
flux *= cur_month_days * 8
elif target_name.endswith('tavg'): # :tavg_definision: = "past 3-hour average";
flux *= cur_month_days * 24 * 3600
fluxs[out_name] = flux
fluxs['TWSC'] = fluxs['PRCP'] - fluxs['ET'] - (fluxs['Qs'] + fluxs['Qsb']) # 计算TWSC
for out_name, flux in fluxs.items():
# 输出路径
cur_out_name = 'GLDAS_{}_{:04}{:02}.tiff'.format(out_name, cur_time.year, cur_time.month)
cur_out_path = os.path.join(out_dir, out_name, cur_out_name)
driver = gdal.GetDriverByName('MEM') # 在内存/TIFF中创建
temp_img = driver.Create('', flux.shape[1], flux.shape[0], 1, gdal.GDT_Float32)
temp_img.SetProjection(srs.ExportToWkt()) # 设置坐标系
temp_img.SetGeoTransform(geo_transform) # 设置仿射参数
flux = np.nan_to_num(flux, nan=no_data_value)
temp_img.GetRasterBand(1).WriteArray(flux) # 写入数据集
temp_img.GetRasterBand(1).SetNoDataValue(no_data_value) # 设置无效值
resample_img = gdal.Warp(cur_out_path, temp_img, xRes=out_res, yRes=out_res, resampleAlg=gdal.GRA_Cubic) # 重采样
# 去除由于重采样造成的数据集不符合实际意义例如降水为负值等情况
vmin = np.nanmin(flux)
vmax = np.nanmax(flux)
flux = resample_img.GetRasterBand(1).ReadAsArray()
resample_img_srs = resample_img.GetProjection()
resample_img_transform = resample_img.GetGeoTransform()
temp_img, resample_img = None, None # 释放资源
flux[flux < vmin] = vmin
flux[flux > vmax] = vmax
driver = gdal.GetDriverByName('GTiff')
final_img = driver.Create(cur_out_path, flux.shape[1], flux.shape[0], 1, gdal.GDT_Float32)
final_img.SetProjection(resample_img_srs)
final_img.SetGeoTransform(resample_img_transform)
final_img.GetRasterBand(1).WriteArray(flux)
final_img.GetRasterBand(1).SetNoDataValue(no_data_value)
final_img.FlushCache()
temp_img, final_img = None, None
print('当前处理: {}-{}'.format(out_name, cur_time.strftime('%Y%m')))
ds.close() # 关闭当前nc文件,释放资源
print('处理完成')
3.4 统一数据集
关于统一数据集,主要包括: 对modis(土地利用、ndvi、地表温度)、geo(DEM等)、gldas数据集进行重采样, 范围限定(裁剪至掩膜形状)
# @Author : ChaoQiezi
# @Time : 2024/1/3 16:51
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 对各个数据集进行统一,例如空间范围()
主要包括: 对modis(土地利用、ndvi、地表温度)、geo(DEM等)、gldas数据集进行重采样, 范围限定(裁剪至掩膜形状)
"""
import os.path
from glob import glob
from concurrent.futures import ThreadPoolExecutor # 线程池
from osgeo import gdal
# 准备
in_dir = r'E:\FeaturesTargets\non_uniform'
out_dir = r'E:\FeaturesTargets\uniform'
shp_path = r'E:\Basic\Region\sw5f\sw5_mask.shp'
dem_path = r'E:\GEO\cndem01.tif'
out_res = 0.1
def resample_clip_mask(in_dir: str, out_dir: str, shp_path: str, wildcard: str, out_res: float = 0.1,
resampleAlg=gdal.GRA_Cubic):
"""
该函数用于对指定文件夹内的影像进行批量重采样和裁剪、掩膜
:param in_dir: 待处理文件所在文件夹目录
:param out_dir: 输出文件的文件夹目录
:param shp_path: 掩膜裁剪的shp文件
:param wildcard: 检索输入文件夹内指定文件的通配符
:param out_res: 输出分辨率
:param resampleAlg: 重采样方法
:return: None
"""
if not os.path.exists(out_dir): os.makedirs(out_dir)
target_paths = glob(os.path.join(in_dir, wildcard))
for target_path in target_paths:
out_path = os.path.join(out_dir, os.path.basename(target_path))
img = gdal.Warp(
out_path, # 输出位置
target_path, # 源文件位置
cutlineDSName=shp_path, # 掩膜裁剪所需文件
cropToCutline=True, # 裁剪至掩膜形状
xRes=out_res, # X方向分辨率
yRes=out_res, # Y方向分辨率
resampleAlg=resampleAlg # 重采样方法
)
img = None
print('目前已处理: {}'.format(os.path.splitext(os.path.basename(target_path))[0]))
# # 处理土地利用数据集
# in_landuse_dir = os.path.join(in_dir, 'Landuse')
# out_landuse_dir = os.path.join(out_dir, 'Landuse')
# resample_clip_mask(in_landuse_dir, out_landuse_dir, shp_path, 'Landuse*.tiff', resampleAlg=gdal.GRA_NearestNeighbour)
# # 处理地表温度数据集
# in_lst_dir = os.path.join(in_dir, 'LST')
# out_lst_dir = os.path.join(out_dir, 'LST')
# resample_clip_mask(in_lst_dir, out_lst_dir, shp_path, 'LST*.tiff')
# # 处理NDVI数据集
# in_ndvi_dir = os.path.join(in_dir, 'NDVI')
# out_ndvi_dir = os.path.join(out_dir, 'NDVI')
# resample_clip_mask(in_ndvi_dir, out_ndvi_dir, shp_path, 'NDVI*.tiff')
# # 处理ET(蒸散发量)数据集
# in_et_dir = os.path.join(in_dir, 'ET')
# out_et_dir = os.path.join(out_dir, 'ET')
# resample_clip_mask(in_et_dir, out_et_dir, shp_path, 'GLDAS_ET*.tiff')
# # 处理降水数据集
# in_prcp_dir = os.path.join(in_dir, 'PRCP')
# out_prcp_dir = os.path.join(out_dir, 'PRCP')
# resample_clip_mask(in_prcp_dir, out_prcp_dir, shp_path, 'GLDAS_PRCP*.tiff')
# # 处理Qs(表面径流量)数据集
# in_qs_dir = os.path.join(in_dir, 'Qs')
# out_qs_dir = os.path.join(out_dir, 'Qs')
# resample_clip_mask(in_qs_dir, out_qs_dir, shp_path, 'GLDAS_Qs*.tiff')
# # 处理Qsb(地下径流量)数据集
# in_qsb_dir = os.path.join(in_dir, 'Qsb')
# out_qsb_dir = os.path.join(out_dir, 'Qsb')
# resample_clip_mask(in_qsb_dir, out_qsb_dir, shp_path, 'GLDAS_Qsb*.tiff')
# # 处理TWSC数据集
# in_twsc_dir = os.path.join(in_dir, 'TWSC')
# out_twsc_dir = os.path.join(out_dir, 'TWSC')
# resample_clip_mask(in_twsc_dir, out_twsc_dir, shp_path, 'GLDAS_TWSC*.tiff')
# 处理DEM数据集
# out_dem_path = os.path.join(out_dir, 'dem.tiff')
# img = gdal.Warp(
# out_dem_path,
# dem_path,
# cutlineDSName=shp_path,
# cropToCutline=True,
# xRes=out_res,
# yRes=out_res,
# resampleAlg=gdal.GRA_Cubic
# )
# img = None
# 并行处理(加快处理速度)
datasets_param = {
'Landuse': 'Landuse*.tiff',
'LST_MEAN': 'LST_MEAN*.tiff',
'LST_MAX': 'LST_MAX*.tiff',
'LST_MIN': 'LST_MIN*.tiff',
'NDVI_MEAN': 'NDVI_MEAN*.tiff',
'NDVI_MAX': 'NDVI_MAX*.tiff',
'NDVI_MIN': 'NDVI_MIN*.tiff',
'ET': 'GLDAS_ET*.tiff',
'PRCP': 'GLDAS_PRCP*.tiff',
'Qs': 'GLDAS_Qs*.tiff',
'Qsb': 'GLDAS_Qsb*.tiff',
'TWSC': 'GLDAS_TWSC*.tiff',
}
if __name__ == '__main__':
with ThreadPoolExecutor() as executor:
futures = []
for dataset_name, wildcard in datasets_param.items():
in_dataset_dir = os.path.join(in_dir, dataset_name)
out_dataset_dir = os.path.join(out_dir, dataset_name)
resampleAlg = gdal.GRA_NearestNeighbour if dataset_name == 'Landuse' else gdal.GRA_Cubic
futures.append(executor.submit(resample_clip_mask, in_dataset_dir, out_dataset_dir, shp_path,
wildcard, resampleAlg=resampleAlg))
# 处理DEM
out_dem_path = os.path.join(out_dir, 'dem.tiff')
futures.append(executor.submit(gdal.Warp, out_dem_path, dem_path, cutlineDSName=shp_path,
cropToCutline=True, xRes=out_res, yRes=out_res, resampleAlg=gdal.GRA_Cubic))
# 等待所有数据集处理完成
for future in futures:
future.result()
# 处理DEM数据集
"""
下述代码比较冗余, 简化为resample_clip_mask函数
----------------------------------------------------------------------
# 处理地表温度数据
lst_paths = glob(os.path.join(lst_dir, 'LST*.tiff'))
out_lst_dir = os.path.join(out_dir, lst_dir.split('\\')[-1])
if not os.path.exists(out_lst_dir): os.makedirs(out_lst_dir)
for lst_path in lst_paths:
out_path = os.path.join(out_lst_dir, os.path.basename(lst_path))
# 重采样、掩膜和裁剪
gdal.Warp(
out_path,
lst_path,
xRes=out_res,
yRes=out_res,
cutlineDSName=shp_path, # 设置掩膜 shp文件
cropToCutline=True, # 裁剪至掩膜形状
resampleAlg=gdal.GRA_Cubic # 重采样方法: 三次卷积
)
print('目前已处理: {}'.format(os.path.splitext(os.path.basename(lst_path))[0]))
# 处理ndvi数据集
ndvi_paths = glob(os.path.join(ndvi_dir, 'NDVI*.tiff'))
out_ndvi_dir = os.path.join(out_dir, ndvi_dir.split('\\')[-1])
if not os.path.exists(out_ndvi_dir): os.makedirs(out_ndvi_dir)
for ndvi_path in ndvi_paths:
out_path = os.path.join(out_ndvi_dir, os.path.basename(ndvi_path))
out_path = os.path.join(out_ndvi_dir, 'NDVI_temp.tiff')
gdal.Warp(
out_path,
ndvi_path,
cutlineDSName=shp_path, # 设置掩膜 shp文件
cropToCutline=True, # 是否裁剪至掩膜形状
xRes=out_res,
yRes=out_res,
resampleAlg=gdal.GRA_Cubic # 重采样方法: 三次卷积
)
"""
04 特征工程
特征工程,至少在在这里面我认为是比较难写的,因为我对于Pytorch的不了解以及输入输出的陌生,这里实际上折腾最多,做了很多版本的处理,这里其实开一个小视频细讲,因为迭代了多个版本,不过时间有限还是作罢。
# @Author : ChaoQiezi
# @Time : 2024/1/19 3:12
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 包括数据集的整合以支持输入到模型中训练,以及特征工程
各个数据集的时间范围:
Landuse: 2001 - 2020
LST(MEAN/MIN/MAX): 200002 - 202210
NDVI(MEAN/MIN/MAX): 200002 - 202010
ET: 200204 - 202309
PRCP: 200204 - 202309
Qs: 200204 - 202309
Qsb: 200204 - 202309
TWSC: 200204 - 202309
dem: single
输出的nc文件的数据格式:
- group(year)
- features1 -> (None, time_step, features_count) , eg. (184, 139, 12 or other, 6)
7: LST, PRCP, ET, Qs, Qsb, TWSC
- features2 -> (None, ), Landuse, (184 * 139)
- targets-> (Noner, time_step), NDVI, (184 * 139, 12)
- features3 -> dem
"""
from datetime import datetime
import os
import re
from glob import glob
import numpy as np
from osgeo import gdal
import h5py
import torch
from sklearn.preprocessing import MinMaxScaler, StandardScaler, scale
def read_img(img_path):
"""
读取栅格文件的波段数据集
:param img_path: 待读取栅格文件的路径
:return: 波段数据集
"""
img = gdal.Open(img_path)
band = np.float32(img.GetRasterBand(1).ReadAsArray())
no_data_value = img.GetRasterBand(1).GetNoDataValue()
band[band == no_data_value] = np.nan
return band
# 准备
in_dir = r'E:\FeaturesTargets\uniform'
h5_path = r'E:\FeaturesTargets\features_targets.h5'
dem_path = r'E:\FeaturesTargets\uniform\dem.tiff'
slope_path = r'E:\FeaturesTargets\uniform\slope.tif'
start_date = datetime(2003, 1, 1)
end_date = datetime(2019, 12, 1)
features1_params = {
'LST_MAX': 'LST_MAX_',
# 'LST_MIN': 'LST_MIN_',
# 'LST_MEAN': 'LST_MEAN_',
'PRCP': 'GLDAS_PRCP_',
'ET': 'GLDAS_ET_',
'Qs': 'GLDAS_Qs_',
'Qsb': 'GLDAS_Qsb_',
'TWSC': 'GLDAS_TWSC_'}
rows = 132
cols = 193
features1_size = len(features1_params)
# 特征处理和写入
h5 = h5py.File(h5_path, mode='w')
for year in range(start_date.year, end_date.year + 1):
start_month = start_date.month if year == start_date.year else 1
end_month = end_date.month if year == end_date.year else 12
features1 = []
targets = []
cur_group = h5.create_group(str(year))
for month in range(start_month, end_month + 1):
# 当前月份特征项的读取
cur_features = np.empty((rows, cols, features1_size))
for ix, (parent_folder_name, feature_wildcard) in enumerate(features1_params.items()):
cur_in_dir = os.path.join(in_dir, parent_folder_name)
pattern = re.compile(feature_wildcard + r'{:04}_?{:02}\.tiff'.format(year, month))
feature_paths = [_path for _path in os.listdir(cur_in_dir) if pattern.match(_path)]
if len(feature_paths) != 1:
raise NameError('文件名错误, 文件不存在或者指定文件存在多个')
feature_path = os.path.join(cur_in_dir, feature_paths[0])
cur_features[:, :, ix] = read_img(feature_path)
features1.append(cur_features.reshape(-1, features1_size))
# 当前月份目标项的读取
ndvi_paths = glob(os.path.join(in_dir, 'NDVI_MAX', 'NDVI_MAX_{:04}_{:02}.tiff'.format(year, month)))
if len(ndvi_paths) != 1:
raise NameError('文件名错误, 文件不存在或者指定文件存在多个')
ndvi_path = ndvi_paths[0]
cur_ndvi = read_img(ndvi_path)
targets.append(cur_ndvi.reshape(-1))
features1 = np.array(features1)
targets = np.array(targets)
"""这里不使用土地利用数据,改用slope数据"""
# landuse_paths = glob(os.path.join(in_dir, 'Landuse', 'Landuse_{}.tiff'.format(year)))
# if len(landuse_paths) != 1:
# raise NameError('文件名错误, 文件不存在或者指定文件存在多个')
# landuse_path = landuse_paths[0]
# features2 = read_img(landuse_path).reshape(-1)
cur_group['features1'] = features1
# cur_group['features2'] = features2
cur_group['targets'] = targets
print('目前已处理: {}'.format(year))
h5['dem'] = read_img(dem_path).reshape(-1)
h5['slope'] = read_img(slope_path).reshape(-1) # 添加slope数据作为特征项
h5.flush()
h5.close()
h5 = None
# 进一步处理,混合所有年份的数据(无需分组)
with h5py.File(h5_path, mode='a') as h5:
for year in range(2003, 2020):
year_features1 = h5[r'2003/features1']
# year_features2 = h5[r'2003/features2']
year_targets = h5[r'2003/targets']
year_dem = h5['dem']
year_slope = h5['slope']
mask = np.all(~np.isnan(year_features1), axis=(0, 2)) & \
~np.isnan(year_slope) & \
np.all(~np.isnan(year_targets), axis=0) & \
~np.isnan(year_dem)
h5['{}/mask'.format(year)] = mask
if year == 2003:
features1 = year_features1[:, mask, :]
slope = year_slope[mask]
targets = year_targets[:, mask]
dem = year_dem[mask]
else:
features1 = np.concatenate((features1, year_features1[:, mask, :]), axis=1)
slope = np.concatenate((slope, year_slope[mask]), axis=0)
targets = np.concatenate((targets, year_targets[:, mask]), axis=1)
dem = np.concatenate((dem, year_dem[mask]), axis=0)
# 归一化
scaler = StandardScaler()
for month in range(12):
features1[month, :, :] = scaler.fit_transform(features1[month, :, :])
dem = scaler.fit_transform(dem.reshape(-1, 1)).ravel()
slope = scaler.fit_transform(slope.reshape(-1, 1)).ravel()
sample_size = dem.shape[0]
train_amount = int(sample_size * 0.8)
eval_amount = sample_size - train_amount
# 创建数据集并存储训练数据
with h5py.File(r'E:\FeaturesTargets\train.h5', mode='w') as h5:
h5.create_dataset('dynamic_features', data=features1[:, :train_amount, :])
h5.create_dataset('static_features1', data=slope[:train_amount]) # 静态变量
h5.create_dataset('static_features2', data=dem[:train_amount]) # 静态变量
h5.create_dataset('targets', data=targets[:, :train_amount])
with h5py.File(r'E:\FeaturesTargets\eval.h5', mode='w') as h5:
# # # 创建数据集并存储评估数据
h5.create_dataset('dynamic_features', data=features1[:, train_amount:, :])
h5.create_dataset('static_features1', data=slope[train_amount:]) # 静态变量
h5.create_dataset('static_features2', data=dem[train_amount:]) # 静态变量
h5.create_dataset('targets', data=targets[:, train_amount:])
05 模型定义和训练、输入和输出、评估和预测
这是模型训练和评估以及特征重要性输出的相关代码:
# @Author : ChaoQiezi
# @Time : 2024/1/3 16:54
# @Email : chaoqiezi.one@qq.com
"""
This script is used to 构建lstm模型并训练
"""
import random
import glob
import os.path
import numpy as np
import pandas as pd
import torch
from torchsummary import summary
from torch.utils.data import DataLoader, random_split
from VEG.utils.utils import H5DatasetDecoder, cal_r2
from VEG.utils.models import LSTMModel
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # 如果使用多GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
# 准备
train_path = r'E:\FeaturesTargets\train.h5'
eval_path = r'E:\FeaturesTargets\eval.h5'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
out_model_dir = r'E:\Models'
dynamic_features_name = [
'LST_MAX',
'PRCP',
'ET',
'Qs',
'Qsb',
'TWSC'
]
static_feature_name = [
'Slope',
'DEM'
]
# 创建LSTM模型实例并移至GPU
model = LSTMModel(6, 256, 4, 12).to('cuda' if torch.cuda.is_available() else 'cpu')
summary(model, input_data=[(12, 6), (2,)])
batch_size = 256
# generator = torch.Generator().manual_seed(42) # 指定随机种子
# train_dataset, eval_dataset, sample_dataset = random_split(dataset, (0.8, 0.195, 0.005), generator=generator)
# train_dataset, eval_dataset = random_split(dataset, (0.8, 0.2), generator=generator)
# 创建数据加载器
train_dataset = H5DatasetDecoder(train_path) # 创建自定义数据集实例
eval_dataset = H5DatasetDecoder(eval_path)
train_data_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
eval_data_loader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=True)
# 训练参数
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.002) # 初始学习率设置为0.001
epochs_num = 30
model.train() # 切换为训练模式
def model_train(data_loader, feature_ix: int = None, epochs_num: int = 25, dynamic: bool = True,
save_path: str = None, device='cuda'):
# 创建新的模型实例
model = LSTMModel(6, 256, 4, 12).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005) # 初始学习率设置为0.001
epochs_loss = []
for epoch in range(epochs_num):
train_loss = []
for dynamic_inputs, static_inputs, targets in data_loader:
# if feature_ix is not None:
# if dynamic:
# batch_size, _, _ = dynamic_inputs.shape
# shuffled_indices = torch.randperm(batch_size)
# # dynamic_inputs[:, :, feature_ix] = torch.tensor(np.random.permutation(dynamic_inputs[:, :, feature_ix]))
# dynamic_inputs[:, :, feature_ix] = torch.tensor(dynamic_inputs[shuffled_indices, :, feature_ix])
# else:
# batch_size, _ = static_inputs.shape
# shuffled_indices = torch.randperm(batch_size)
# # static_inputs[:, feature_ix] = torch.tensor(np.random.permutation(static_inputs[shuffled_indices, feature_ix]))
# static_inputs[:, feature_ix] = torch.tensor(static_inputs[shuffled_indices, feature_ix])
dynamic_inputs, static_inputs, targets = dynamic_inputs.to(device), static_inputs.to(device), targets.to(
device)
"""正常"""
# 前向传播
outputs = model(dynamic_inputs, static_inputs)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和优化
loss.backward()
optimizer.step()
# scheduler.step() # 更新学习率
optimizer.zero_grad() # 清除梯度
train_loss.append(loss.item())
print(f'Epoch {epoch + 1}/{epochs_num}, Loss: {np.mean(train_loss)}')
epochs_loss.append(np.mean(train_loss))
if save_path:
torch.save(model.state_dict(), save_path)
return epochs_loss
def model_eval_whole(model_path: str, data_loader, device='cuda'):
# 加载模型
model = LSTMModel(6, 256, 4, 12).to(device)
model.load_state_dict(torch.load(model_path))
# 评估
model.eval() # 评估模式
all_outputs = []
all_targets = []
with torch.no_grad():
for dynamic_inputs, static_inputs, targets in data_loader:
dynamic_inputs, static_inputs, targets = dynamic_inputs.to(device), static_inputs.to(device), targets.to(
device)
outputs = model(dynamic_inputs, static_inputs)
all_outputs.append(outputs.cpu()) # outputs/targets: (batch_size, time_steps)
all_targets.append(targets.cpu())
all_outputs = np.concatenate(all_outputs, axis=0)
all_targets = np.concatenate(all_targets, axis=0)
# mse_per_step = []
# mae_per_step = []
# r2_per_step = []
# rmse_per_step = []
# for time_step in range(12):
# mse_step = mean_squared_error(all_targets[:, time_step], all_outputs[:, time_step])
# mae_step = mean_absolute_error(all_targets[:, time_step], all_outputs[:, time_step])
# r2_step = r2_score(all_targets[:, time_step], all_outputs[:, time_step])
# rmse_step = np.sqrt(mse_step)
#
# mse_per_step.append(mse_step)
# mae_per_step.append(mae_step)
# r2_per_step.append(r2_step)
# rmse_per_step.append(rmse_step)
# mse = np.mean(mse_per_step)
# mae = np.mean(mae_per_step)
# r2 = np.mean(r2_per_step)
# rmse = np.mean(rmse_per_step)
# 不区分月份求取指标(视为整体)
mse_step = mean_squared_error(all_targets.reshape(-1), all_outputs.reshape(-1))
mae_step = mean_absolute_error(all_targets.reshape(-1), all_outputs.reshape(-1))
r2_step = r2_score(all_targets.reshape(-1), all_outputs.reshape(-1))
rmse_step = np.sqrt(mse_step)
return mse_step, mae_step, r2_step, rmse_step
# return mse_per_step, mae_per_step, r2_per_step, rmse_per_step, all_outputs, all_targets
def model_eval(model_path: str, data_loader, device='cuda'):
# 加载模型
model = LSTMModel(6, 256, 4, 12).to(device)
model.load_state_dict(torch.load(model_path))
# 评估
model.eval() # 评估模式
all_outputs = []
all_targets = []
with torch.no_grad():
for dynamic_inputs, static_inputs, targets in data_loader:
dynamic_inputs, static_inputs, targets = dynamic_inputs.to(device), static_inputs.to(device), targets.to(
device)
outputs = model(dynamic_inputs, static_inputs)
all_outputs.append(outputs.cpu()) # outputs/targets: (batch_size, time_steps)
all_targets.append(targets.cpu())
all_outputs = np.concatenate(all_outputs, axis=0)
all_targets = np.concatenate(all_targets, axis=0)
mse_per_step = []
mae_per_step = []
r2_per_step = []
rmse_per_step = []
for time_step in range(12):
mse_step = mean_squared_error(all_targets[:, time_step], all_outputs[:, time_step])
mae_step = mean_absolute_error(all_targets[:, time_step], all_outputs[:, time_step])
r2_step = r2_score(all_targets[:, time_step], all_outputs[:, time_step])
rmse_step = np.sqrt(mse_step)
mse_per_step.append(mse_step)
mae_per_step.append(mae_step)
r2_per_step.append(r2_step)
rmse_per_step.append(rmse_step)
return mse_per_step, mae_per_step, r2_per_step, rmse_per_step, all_outputs, all_targets
if __name__ == '__main__':
# df = pd.DataFrame()
# # 常规训练
# df['normal_epochs_loss'] = model_train(train_data_loader, save_path=os.path.join(out_model_dir, 'normal_model.pth'))
# print('>>> 常规训练结束')
# # 特征重要性训练
# # 动态特征
# for feature_ix in range(6):
# train_dataset = H5DatasetDecoder(train_path, shuffle_feature_ix=feature_ix, dynamic=True) # 创建自定义数据集实例
# train_data_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
#
# cur_feature_name = dynamic_features_name[feature_ix]
# save_path = os.path.join(out_model_dir, cur_feature_name + '_model.pth')
# df[cur_feature_name + '_epochs_loss'] = \
# model_train(train_data_loader, feature_ix, dynamic=True, save_path=save_path)
# print('>>> {}乱序排列 训练结束'.format(cur_feature_name))
# # 静态特征
# for feature_ix in range(2):
# train_dataset = H5DatasetDecoder(train_path, shuffle_feature_ix=feature_ix, dynamic=False) # 创建自定义数据集实例
# train_data_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
#
# cur_feature_name = static_feature_name[feature_ix]
# save_path = os.path.join(out_model_dir, cur_feature_name + '_model.pth')
# df[cur_feature_name + '_epochs_loss'] = \
# model_train(train_data_loader, feature_ix, dynamic=False, save_path=save_path)
# print('>>> {}乱序排列 训练结束'.format(cur_feature_name))
# df.to_excel(r'E:\Models\training_eval_results\training_loss.xlsx')
# 评估
indicator_whole = pd.DataFrame()
indicator = pd.DataFrame()
model_paths = glob.glob(os.path.join(out_model_dir, '*.pth'))
for model_path in model_paths:
cur_model_name = os.path.basename(model_path).rsplit('_model')[0]
mse_step, mae_step, r2_step, rmse_step = model_eval_whole(model_path, eval_data_loader)
indicator_whole[cur_model_name + '_evaluate_mse'] = [mse_step]
indicator_whole[cur_model_name + '_evaluate_mae'] = [mae_step]
indicator_whole[cur_model_name + '_evaluate_r2'] = [r2_step]
indicator_whole[cur_model_name + '_evaluate_rmse'] = [rmse_step]
mse_per_step, mae_per_step, r2_per_step, rmse_per_step, all_outputs, all_targets = model_eval(model_path, eval_data_loader)
all_outputs_targets = np.concatenate((all_outputs, all_targets), axis=1)
columns = [*['outputs_{:02}'.format(month) for month in range(1, 13)], *['targets_{:02}'.format(month) for month in range(1, 13)]]
outputs_targets = pd.DataFrame(all_outputs_targets, columns=columns)
indicator[cur_model_name + '_evaluate_mse'] = mse_per_step
indicator[cur_model_name + '_evaluate_mae'] = mae_per_step
indicator[cur_model_name + '_evaluate_r2'] = r2_per_step
indicator[cur_model_name + '_evaluate_rmse'] = rmse_per_step
outputs_targets.to_excel(r'E:\Models\training_eval_results\{}_outputs_targets.xlsx'.format(cur_model_name))
print('>>> {} 重要性评估完毕'.format(cur_model_name))
indicator.loc['均值指标'] = np.mean(indicator, axis=0)
indicator.to_excel(r'E:\Models\training_eval_results\eval_indicators_整体.xlsx')
indicator_whole.to_excel(r'E:\Models\training_eval_results\eval_indicators_整体.xlsx')
# model.eval()
# eval_loss = []
# with torch.no_grad():
# for dynamic_inputs, static_inputs, targets in data_loader:
# dynamic_inputs = dynamic_inputs.to('cuda' if torch.cuda.is_available() else 'cpu')
# static_inputs = static_inputs.to('cuda' if torch.cuda.is_available() else 'cpu')
# targets = targets.to('cuda' if torch.cuda.is_available() else 'cpu')
# # 前向传播
# outputs = model(dynamic_inputs, static_inputs)
# # 计算损失
# loss = criterion(outputs, targets)
# r2 = cal_r2(outputs, targets)
# print('预测项:', outputs)
# print('目标项:', targets)
# print(f'MSE Loss: {loss.item()}')
# break
# eval_loss.append(loss.item())
# print(f'Loss: {np.mean(eval_loss)}')
# print(f'R2:', r2)
# # 取
# with h5py.File(r'E:\FeaturesTargets\features_targets.h5', 'r') as h5:
# features = np.transpose(h5['2003/features1'][:], (1, 0, 2)) # shape=(样本数, 时间步, 特征项)
# targets = np.transpose(h5['2003/targets'][:], (1, 0)) # shape=(样本数, 时间步)
# static_features = np.column_stack((h5['2003/features2'][:], h5['dem'][:]))
# mask1 = ~np.any(np.isnan(features), axis=(1, 2))
# mask2 = ~np.any(np.isnan(targets), axis=(1,))
# mask3 = ~np.any(np.isnan(static_features), axis=(1, ))
# mask = (mask1 & mask2 & mask3)
# features = features[mask, :, :]
# targets = targets[mask, :]
# static_features = static_features[mask, :]
# print(features.shape)
# print(targets.shape)
# for ix in range(6):
# feature = features[:, :, ix]
# features[:, :, ix] = (feature - feature.mean()) / feature.std()
# if ix <= 1:
# feature = static_features[:, ix]
# static_features[:, ix] = (feature - feature.mean()) / feature.std()
#
# features_tensor = torch.tensor(features, dtype=torch.float32)
# targets_tensor = torch.tensor(targets, dtype=torch.float32)
# static_features_tensor = torch.tensor(static_features, dtype=torch.float32)
#
# # 创建包含动态特征、静态特征和目标的数据集
# dataset = TensorDataset(features_tensor, static_features_tensor, targets_tensor)
# train_dataset, eval_dataset = random_split(dataset, [8000, 10238 - 8000])
这里时间原因,就不细讲其中的一些细节了,另外部分说明在代码中也有提及,在博客中就不一一重复说明了。



















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











