







一.字面量&&变量
1.定义
字面量: 在代码中,固定的值称为字面量
变 量: 在程序运行时,能储存计算结果或能表示值的抽象概念。简单的说,变量就是在程序运行时,记录数据用的
2.变量的语法
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
变量名称=值
# 声明两个变量,分别保存姓名和爱好
stu_name = '刘晓兰'
stu_hobby = "瑜伽"
print(stu_name, stu_hobby, end="")
3.给多个变量同时赋值
"""
给多个变量赋值
1.给多个变量赋相同的值
a = b = c = 1
2.给多个变量同时赋值,并且值不一样
"""
a = b = c = 1
print(a, b, c)
d, e, f = 1, 'a', 3.4
print(d, e, f)
二.数据类型
1.标准数据类型
- Number(数字)
- String(字符串)
- bool(布尔类型)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
2.可变/不可变数据类型
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
3.使用内置type()函数查看数据类型
说明:变量没有类型,变量存储的内容有数据类型类型
语法:
type(变量)
案例:
"""
使用type()函数检查变量的数据类型
"""
address = '北京'
print(type(address))
结果:
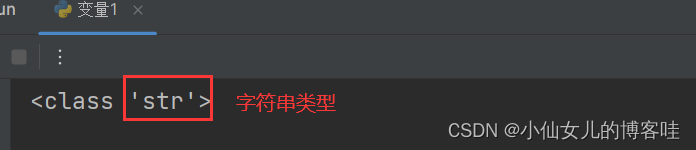
4.数据类型转换
int() 转换为整形
float() 转换为浮点型
str() 转换为字符串
complex(x,y) 转换为复数
三.运算符
1.什么是运算符
说明:
a+b=c
a,b称为操作数
+称为运算符
2.运算符分类
运算符分类
- 算数运算符
- 比较运算符(关系运算符)
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
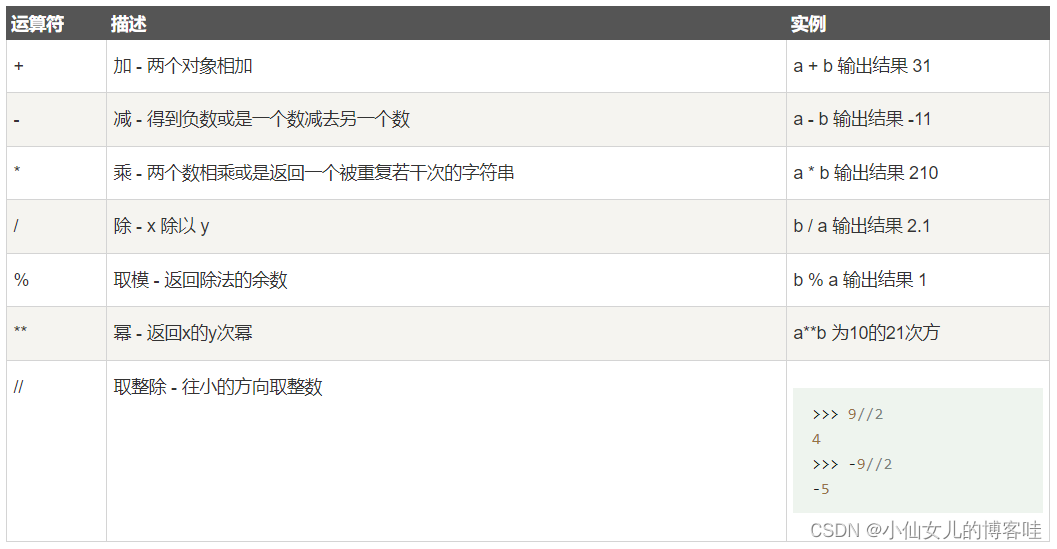
3.算数运算符
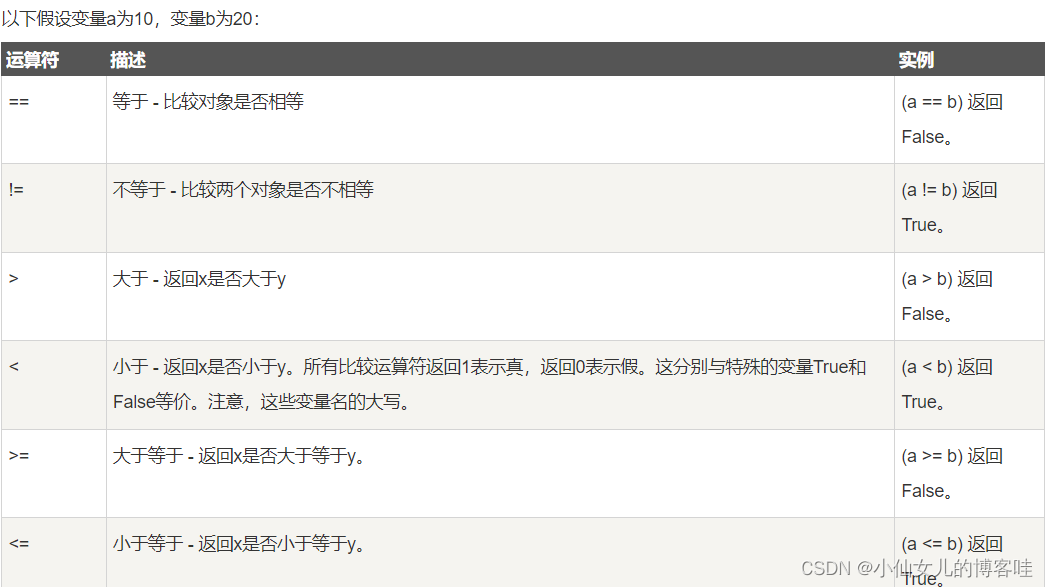
4.比较运算符
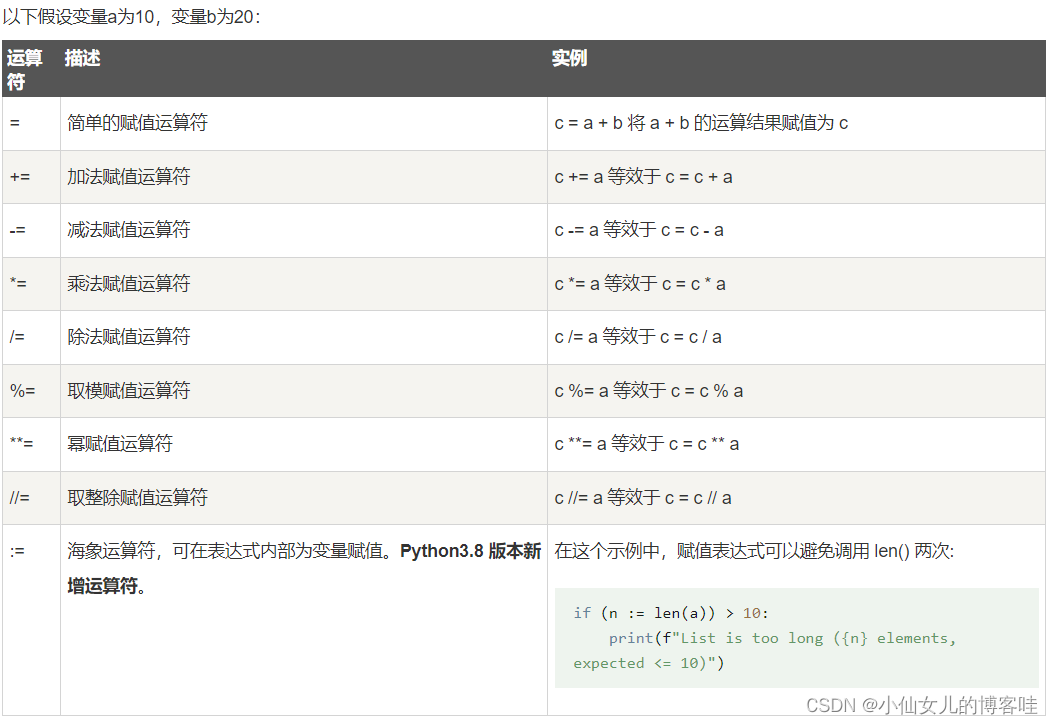
5. 赋值运算符&&复合赋值运算符
6.逻辑运算符
假设变量 a 为 10, b为 20:

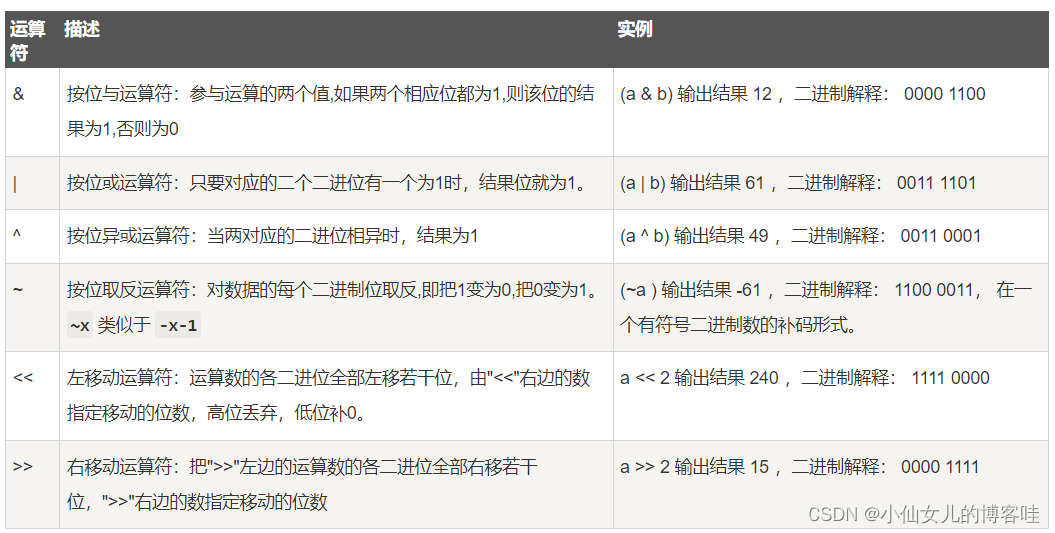
7.位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
8.成员运算符

9.身份运算符
身份运算符用于比较两个对象的存储单元

is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
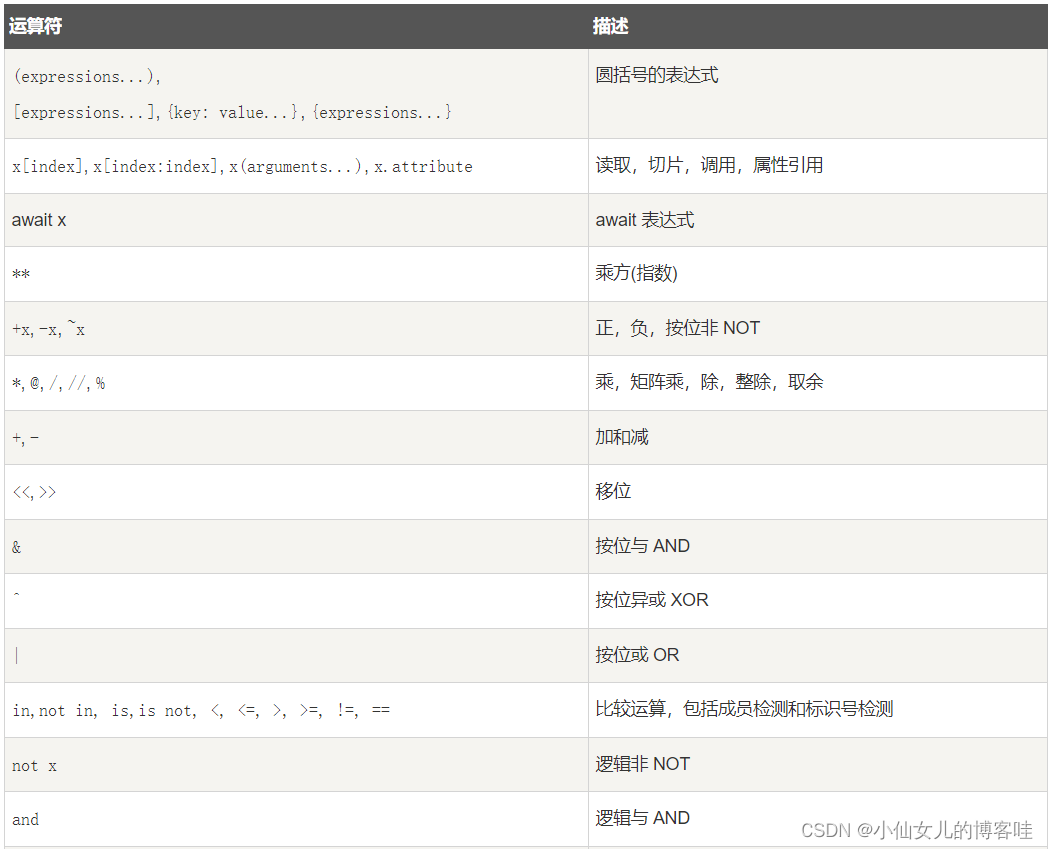
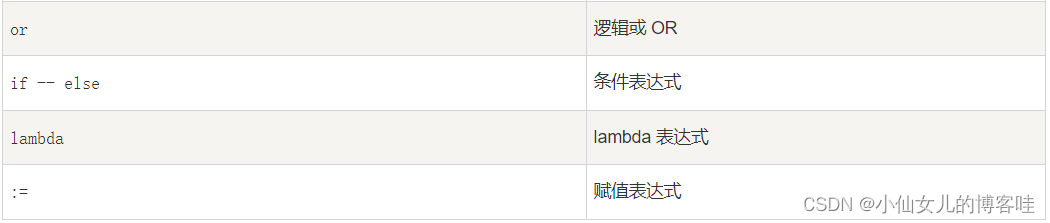
四.运算符的优先级
以下表格列出了从最高到最低优先级的所有运算符, 相同单元格内的运算符具有相同优先级。 运算符均指二元运算,除非特别指出。 相同单元格内的运算符从左至右分组(除了幂运算是从右至左分组):
五.Python3数据类型–Number(数字)
Python 支持三种不同的数值类型:
1. 整型(int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。布尔(bool)是整型的子类型。
2. 浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
3. 复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
案例1:描述学生信息:姓名:张三,年龄20,语文成绩:99.5,是否成年:True
# 描述学生信息:姓名:张三,年龄20,语文成绩:99.5,是否成年:True
stu_name = '张三'
stu_age = 20
stu_score = 99.5
stu_is_adult = True
# %.2f 保留两位小数
print("姓名:%s,年龄:%d,语文成绩:%.2f,是否成年:%s" % (stu_name, stu_age, stu_score, stu_is_adult))
六.Python3数据类型–字符串
1.定义
字符串的三种定义方式
1. 单引号 flower_name='玫瑰'
2. 双引号 flower_name="牡丹"
3. 三引号 flower_name="""牡丹雍容华贵,国色天香""" 或者 flower_name = '''Python中不支持单字符'''
三引号定义字符串和三引号注释一样,可以换行
如果有变量接收就是可换行字符串,没有变量接收就是注释
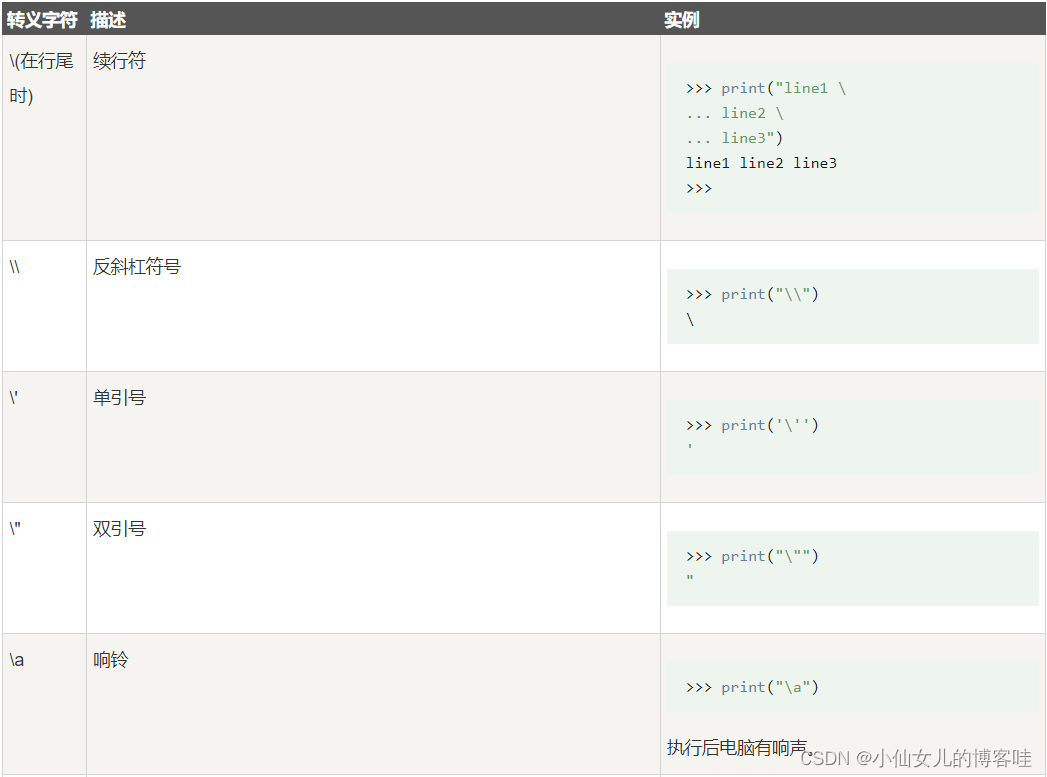
2.转义字符
在字符串中使用特殊字符时,需要使用反斜杠 \ 转义字符,就是让特殊字符不在特殊
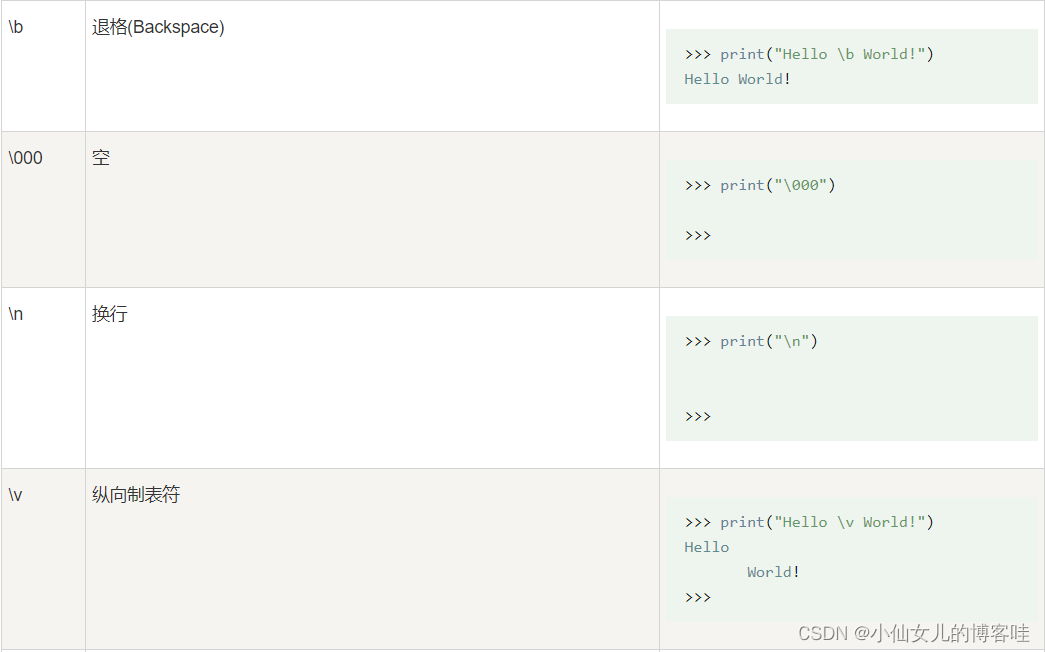
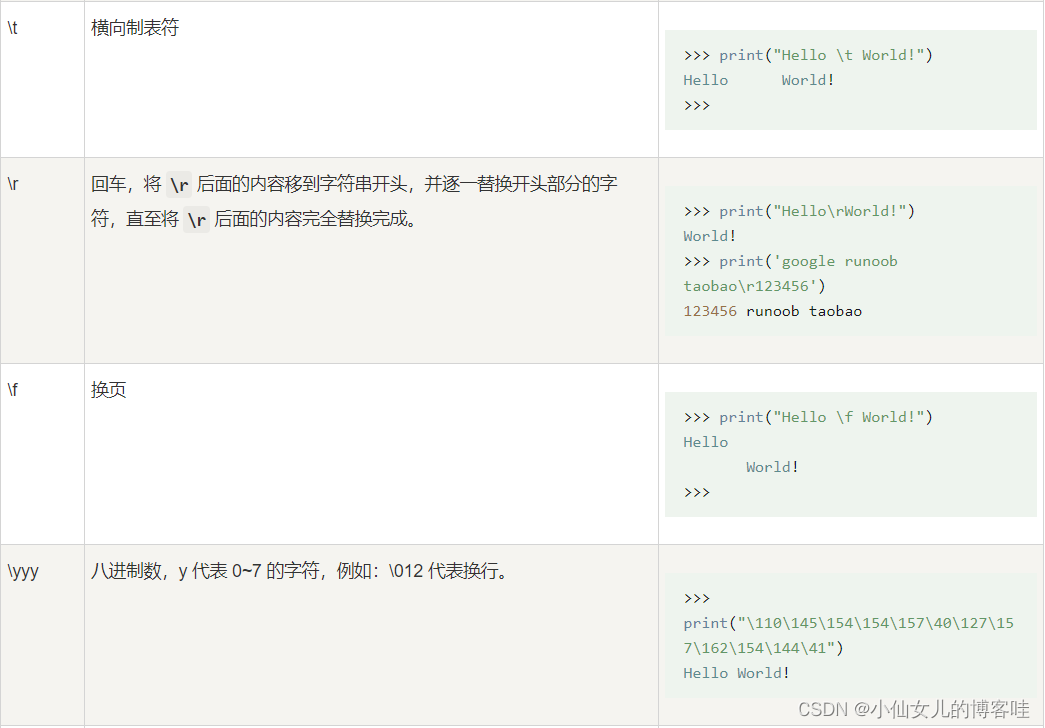

案例1:
# 转义字符
print("编号\t名称\t单价\t数量\t小计")
print("1\t'水杯'\t20\t2\t40")
3.字符串常用运算符
实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
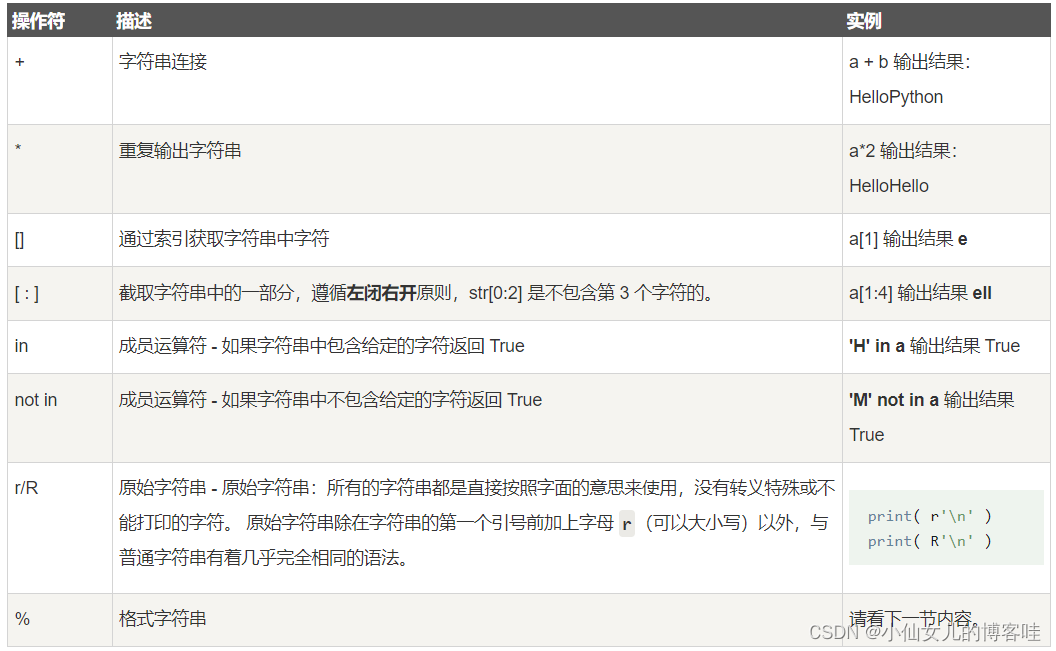
4.字符串常用的内置函数
1.len(string) 返回字符串的长度
str = "this is python!"
print(len(str)) # 结果为15
2.find(str,begin,end) 检查str字符串是否在原字符串中,如果在就返回首次出现的索引,不存在就返回-1,begin和end是查找范围
title = "what is wh?"
print(title.find('zzz')) # 结果为-1 不存在
print(title.find('wh')) # 结果为0 首次出现的索引
print(title.find('w',1,9)) # 结果为8 因为从1开始的也就是从h开始向右查找的
3.lower() 所有大写字母转换为小写字母
lower_str = "FGSDFSD"
print(lower_str.lower()) # 结果为:fgsdfsd
4.upper()所有小写字母转换为大写字母
upper_str = "dsdsd"
print(upper_str.upper()) # DSDSD
5.max(str) 返回字符串str中的最大值
max_str = "abc"
print(max(max_str)) # 返回结果为c
6.min(str)返回字符串str中的最小值
min_str = "abc"
print(min(min_str))
7.join(seq) 用指定分隔符把seq中的字符连接为一个字符串
seq = ['1', '2', '3']
print('-'.join(seq)) # 结果1-2-3
8.replace(oldstr,newstr,[,max]) 用newstr替换oldstr 如果max有值,则替换不超过max次
replace_str = "wawawa,hei,hello"
new_replace_str1 = replace_str.replace('wa', 'hi') # hihihi,hei,hello
print(new_replace_str1)
new_replace_str2 = replace_str.replace('wa', 'hi', 2) # hihiwa,hei,hello
print(new_replace_str2
9.strip([chars]) 删除掉字符串左右多余的空格或指定字符
strip_str = " 删除左右多余的空格 "
print(len(strip_str)) # 长度为17
print(len(strip_str.strip())) # 长度为9
10.isdecimal() 是否为十进制数字符,包括Unicode数字、双字节全角数字,不包括罗马数字、汉字数字、小数,返回值为True和False
decimal_str1 = "234234234"
decimal_str2 = "2342a34234"
print(decimal_str1.isdecimal()) # True
print(decimal_str2.isdecimal()) # False
11.isdigit()是否为数字字符,包括Unicode数字,单字节数字,双字节全角数字,不包括汉字数字,罗马数字、小数
12.isnumeric()是否所有字符均为数值字符,包括Unicode数字、双字节全角数字、罗马数字、汉字数字,不包括小数。
print("+++++++++++++++++汉字数字壹贰叁++++++++++++++")
str1 = "壹贰叁"
print(str1.isdecimal())
print(str1.isdigit())
print(str1.isnumeric())
print("+++++++++++++++++罗马数字++++++++++++++")
str2 = "Ⅱ"
print(str2.isdecimal())
print(str2.isdigit())
print(str2.isnumeric())
print("+++++++++++++++++全角数字++++++++++++++")
# 全角的2
str4 = "2"
print(str4.isdecimal())
print(str4.isdigit())
print(str4.isnumeric())
13.split(str,num)
str是分隔符默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等.
num -- 分割次数。默认为 -1, 即分隔所有。
split_str1 = "thisismydoghi!"
split_str2 = "this is my do ghi!"
print(split_str1.split())
print(split_str2.split(" "))
print(split_str2.split("i"))
print(split_str2.split("i", 1)) # 以i为分隔符,分成2部分
14.capitalize()将字符串的第一个字符转换为大写
capitalize_str = "zhang"
print(capitalize_str.capitalize()) # Zhang
15.count(str,begin,end) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数,否则就是整个字符串范围内查找
# count()
count_str = "my dog is very lovely,but my dog is very small!"
print(count_str.count("dog")) # 2
print(count_str.count("dog", 7, len(count_str))) # 1
print(count_str.count("dog", 7, 8)) # 0
5.字符串的格式化
5.1格式化分为三种方式
1. %s
2. format
3. f-字符串
5.2%s
5.2.1 Python常用字符串格式化符号
4. %s 格式化字符串
5. %d 格式化整数
6. %f 格式化浮点数字,可指定小数点后的精度
5.2.2 语法
stu_name = "王永胜"
print("大家好,我是%s" % stu_name) # 大家好,我是王永胜
stu_age = 20
stu_python_score = 99.5
# 大家好,我是王永胜,今年20,python成绩为99.500000分 这个分数的小数位数太多了
print("大家好,我是%s,今年%d,python成绩为%f分" % (stu_name, stu_age, stu_python_score))
5.2.3 Python格式化字符串的精度控制-格式化操作符辅助指令:
1. m.n
m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
n, 控制小数点精度,要求是数字,会进行小数的四舍五入
2.%
'%%'输出一个单一的'%'
# 格式化字符串的精度控制
stu_en_score = 88.8
print("英语成绩:%f" % stu_en_score) # 英语成绩:88.800000
print("英语成绩:%10f" % stu_en_score) # 英语成绩: 88.800000 输出的数字宽度为10
print("英语成绩:%.2f" % stu_en_score) # 英语成绩:88.80 输出的数字小数点保留2位数
print("英语成绩:%10.2f" % stu_en_score) # 英语成绩: 88.80 输出的数字小数点保留2位数,宽度为
5.3format()函数
5.3.1 语法
str.format()
str中可以写索引也可以写关键字
# 1.使用索引
# 水果:苹果,香蕉,大橙子
print("水果:{0},{1},{2}".format("苹果", "香蕉", "大橙子"))
# 水果:香蕉,苹果,大橙子 苹果对应的索引是0
print("水果:{1},{0},{2}".format("苹果", "香蕉", "大橙子"))
# 2.使用关键字
print("水果:{a},{b},{c}".format(a="香蕉", b="大橙子", c="苹果"))
print("水果:{0},{1},{c}".format("香蕉", "大橙子", c="苹果"))
5.4f-string
5.4.1 语法
在字符串前加前缀f或F,通过 {expression} 表达式,把Python表达式的值添加到字符串内
# Python格式化字符串 f-string
auto = "自动化办公"
web_dev = "web开发"
print(f"人工智能是一个行业名词,可以从事{auto}或者{web_dev}")
七.Python3数据类型–list(列表)
序列:内容连续、有序,可使用下标索引的一类数据容器
列表,元组,字符串的数据结构都是序列
1.定义
列表可以一次存储多个不同数据类型的元素
列表内的每一个数据,称之为元素
以[ ]作为标识
列表内每一个元素之间用,逗号隔开
列表可以存储一次存储多个数据,切可以为不同的数据类型,支持嵌套
2.语法
- 字面量
[元素1,元素2,元素3...]
- 定义变量
- 变量名称 = [元素1,元素2,元素3...]
- 定义空列表
变量名称 = []
变量名称 = list()
# 定义列表
name_list = ['张三', '李四', '王五']
age_list = []
address_list = list()
3.通过下标||索引访问列表中的值 || for循环遍历列表
列表中的每一个元素,都有其位置下标索引
从前向后的方向,从0开始,依次递增
反向索引:从-1开始,依次递减(-1,-2,-3,-4)
# 定义列表
name_list = ['张三', '李四', '王五']
age_list = []
address_list = list()
score_list = [[20, 30, 10], [50, 60, 90], [40, 60, 90]]
# 通过下标或者索引访问列表中的元素
print("索引为2的元素为:" + name_list[2]) # 索引为2的元素为:王五
print("索引为-1的元素为:" + name_list[-1]) # 索引为-1的元素为:王五
print("张三的各科成绩如下:\n\t语文:" + str(score_list[0][0]) + "\n\t数学:" + str(score_list[0][1]) + "\n\t英语:" + str(
score_list[0][2]))
使用for循环遍历列表
1.需要操作元素内容
2.需要获取元素的索引
3.既需要元素也需要下标/索引
1.需要操作元素内容
for a in list1:
print(a) # a是临时变量,代表列表中的元素
2.需要获取元素的索引
for i in range(len(list1)):
print(list1[i])
3.既需要元素也需要下标/索引
for index,value in enumerate(list1):
print(index,value)
4.列表常用的内置函数||方法
Python常用的函数:
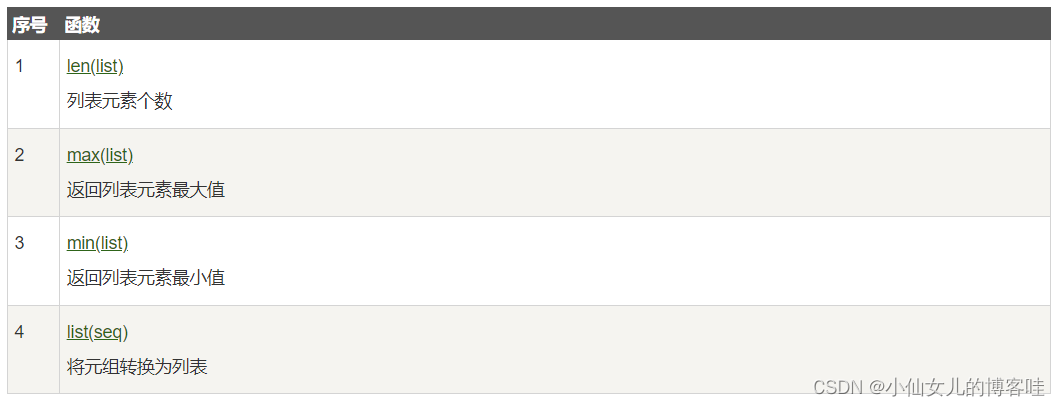
Python包含以下方法:
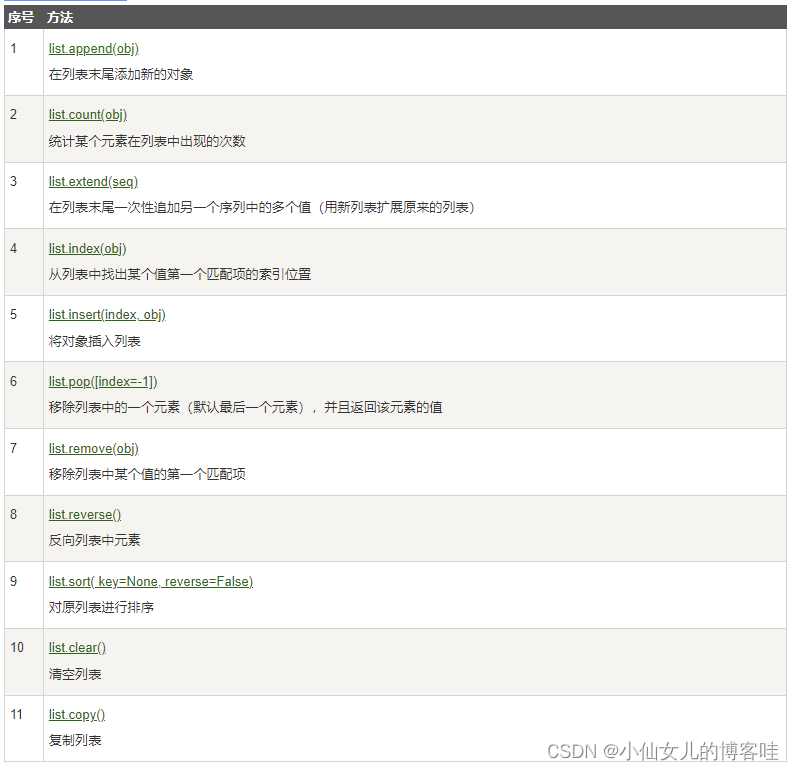
# 定义列表存储学生姓名
stu_list = ['王永胜', '卢锦乾', '杨帆', '王硕']
shu_list = [91, 78, 90, 60]
print("===================学生管理系统=======================\n")
# 1. len()
print("KBDE203共有" + str(len(stu_list)) + "名学生!")
# 2. max() min()
print("数学考试成绩最高分" + str(max(shu_list)) + "分,最低分:" + str(min(shu_list)) + "分")
# 常用方法
# 追加 向列表中添加小杜 成绩50
add_name = input("请输入学生姓名:")
add_shu_score = input("请输入学生数学成绩:")
# 3. append()
stu_list.append(add_name)
shu_list.append(add_shu_score)
print("KBDE203共有" + str(len(stu_list)) + "名学生!")
# 4.count() 班级有几个张三 list.count()
print("班级共有是否重复" + str(stu_list.count("张三")))
# 5. extend()
stu_list_1 = ['张三丰', '李胡兰', '罗桂英', '小海']
shu_list_1 = [67, 78, 32, 90]
stu_list.extend(stu_list_1)
shu_list.extend(shu_list_1)
print(stu_list)
print(shu_list)
# 6. index() 杨帆的学号 list.index() 首次出现的索引,不存在就抛出异常ValueError
print("杨帆的学号:%d" % stu_list.index("杨帆"))
# 7.insert() 把aa插入到1的位置 list.insert()
stu_list.insert(1, "aa")
shu_list.insert(1, 30)
print(stu_list)
print(shu_list)
# 8.pop() 删除列表中最有一个元素 pop()
stu_list.pop()
shu_list.pop()
print(stu_list)
print(shu_list)
# 删除列表中第一个元素 pop(索引)
stu_list.pop(0)
shu_list.pop(0)
print(stu_list)
print(shu_list)
# 9.remove() 移除首次出现的某个元素 remove()
flower_list = ['玫瑰花', '月季花', '牡丹', '桃花', '玫瑰花']
flower_list.remove('玫瑰花')
print(flower_list)
# 10.reverse() 反向列表中的元素 reverse()
flower_list.reverse()
print(flower_list)
# 11.sort() 默认情况下
# 排序sort() sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
# sort(key=None, reverse=False) reverse=True降序 reverse=False 升序
yuwen_list = [45, 12, 89, 34, 56]
yuwen_list.sort() # 默认升序[12, 34, 45, 56, 89]
print(yuwen_list)
yuwen_list.sort(reverse=True) # 降序[89, 56, 45, 34, 12]
print(yuwen_list)
# 自定义定义比较函数的情况下
# sort()函数可以实现按照元组中某个元素排序
grades = [('Charlie', 75), ('Bob', 85), ('Alice', 92), ('Eva', 79), ('David', 88)]
# 按照元祖中的第二个元素排序
# 自定义比较函数
def bj(element):
print(element[1])
return element[1]
# 按照元祖中的第二个元素进行升序排序 [('Charlie', 75), ('Eva', 79), ('Bob', 85), ('David', 88), ('Alice', 92)]
grades.sort(key=bj)
print(grades)
# 按照元祖中的第二个元素进行降序排序 [('Alice', 92), ('David', 88), ('Bob', 85), ('Eva', 79), ('Charlie', 75)]
grades.sort(key=bj, reverse=True)
print(grades)
# 使用lambda表达式
words = ['pear', 'banana', 'apple', 'kiwi', 'arange']
words.sort(key=lambda x: (len(x), x[0])) # 先按照长度再按照首字母 x指的是每一个元素
print(words)
# 12.sorted
string = 'python'
sorted_string = sorted(string)
print(string)
print(sorted_string)
# 13.clear()清空列表
goods_list = ['水杯', '鼠标']
print(goods_list)
goods_list.clear()
print(goods_list)
# 14.del 删除列表中的元素
goods_list1 = ['水杯', '鼠标']
print(goods_list1)
del goods_list1[0]
print(goods_list1)
5.list列表方法sort()和sorted()函数的讲解
5.1 排序函数–sort()
Python中的sort()函数,不仅用于对列表进行排序,还可以按照特定的规则进行序列排序。
1.sort函数的基本用户
seq.sort(key=None,reverse=False)
参数解释:
- seq表示一个序列
- key主要是用来进行比较的元素,只有一个参数。
- reverse为排序规则,默认升序(False),可以指定降序(True)
sort()函数使用的是Timsort算法,它是一种混合排序算法,结合了归并排序和插入排序。Python中的sort函数使用起来非常简单, 只需要调用序列对象的sort方法即可
案例一:将列表中的数字按升序排列
numbers = [3, 2, 8, 5, 1]
numbers.sort()
print(numbers)
案例二:按照某个key对序列进行排序
sort函数还可以接受一个关键字参数,用于指定一个自定义的排序规则。
按照字符串长度对这些单词进行排序
words = ["apple", "banana", "cat", "dog", "elephant"]
words.sort(key=len) # len()是内置函数 计算长度的
print(words)
排序后的输出结果:
[‘cat’, ‘dog’, ‘apple’, ‘banana’, ‘elephant’]
案例三:按照多个键进行排序
先按照元素长度排序,然后再按照首字母排序
words = ['pear', 'banana', 'apple', 'kiwi', 'orange']
words.sort(key=lambda x: (len(x), x[0]))
print(words)
排序后的输出结果:
[‘kiwi’, ‘pear’, ‘apple’, ‘banana’, ‘orange’]
5.3结合reverse参数实现倒序排序
使用sort()函数的reverse参数可以进行倒序排序。
numbers = [3, 5, 2, 8, 1, 9]
numbers.sort(reverse=True)
print(numbers)
排序后的输出结果;
[9, 8, 5, 3, 2, 1]
5.2 sort()和sorted()函数的区别
1.区别
这两个的排序方法基本相同,唯一不同的一点:
是list.sort()直接把原来的list进行了重新排序======(改变了原来的序列)
sorted()是返回一个重新排序后的副本,原list还是那样====(没有改变原来的序列)
2.对元组等不可变类型进行排序
对于Python内置的不可变类型(如字符串、元组等),sort()函数无法修改原对象,需要使用sorted()函数。
sorted()函数返回值为列表
string = 'python'
sorted_string = sorted(string)
print(string)
print(sorted_string)
输出结果:
python
[‘h’, ‘n’, ‘o’, ‘p’, ‘t’, ‘y’]
3.我们要处理的数据内的元素不是一维的,而是二维的甚至是多维的
sort()函数
grades = [('Alice', 75), ('Bob', 85), ('Charlie', 92), ('David', 79), ('Eva', 88)]
grades.sort(key=lambda x: x[1], reverse=True)
print(grades)
排序后的输出结果:
[(‘Charlie’, 92), (‘Eva’, 88), (‘Bob’, 85), (‘Alice’, 75), (‘David’, 79)]
sorted()函数
>>>l=[('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
>>>sorted(l, key=lambda x:x[0])
Out[39]: [('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
>>>sorted(l, key=lambda x:x[0], reverse=True)
Out[40]: [('e', 3), ('d', 4), ('c', 6), ('b', 2), ('a', 1)]
>>>sorted(l, key=lambda x:x[1])
Out[41]: [('a', 1), ('b', 2), ('e', 3), ('d', 4), ('c', 6)]
>>>sorted(l, key=lambda x:x[1], reverse=True)
Out[42]: [('c', 6), ('d', 4), ('e', 3), ('b', 2), ('a', 1)]
5.3查找序列中第K大的元素
我们可以利用sort()函数查找一个序列中的第K大的元素。
def kth_largest(seq, k):
seq.sort(reverse=True)
return seq[k-1]
使用sort()函数直接返回。当然,还可以使用其它算法来实现这个寻找第K大的元素过程,但sort()函数最方便不是吗?
5.4sort()和sorted()函数的总结
- list.sort()把原来的列表进行重排序,sorted()返回一个排序后的副本,不改变原列表
- 对于多元元素排序,可以用匿名函数的方法设置key的值,key是每个元组/列表/其他可索引的(词穷),的第几个元素就按照第几个元素来排序。
- 这两个函数都是默认升序排序。如果想逆(降)序排序,后面加个reverse=True即可
5.5 sort()函数的总结
- sort函数是Python中非常重要的一个函数,可以用于对列表进行排序,还可以按照特定的规则对序列进行排序
- sorted()函数基本用法 默认排序就是升序
- 按照某个key对序列进行排序
- 按照多个键进行排序
- 结合reverse参数实现倒序排序
- 对元组等不可变类型进行排序
- 查找序列中第K大的元素
6.更新列表
list = ['a', 'b', 1997, 2000]
list[1]='c'
print(list)
输出结果:
[‘a’, ‘c’, 1997, 2000]
7.截取列表
7.1使用[]截取
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4]) # [10, 20, 30, 40]
print(nums[1:-2]) # [20, 30, 40, 50, 60, 70]
print(nums[0:]) # [10, 20, 30, 40, 50, 60, 70, 80, 90]
8.Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
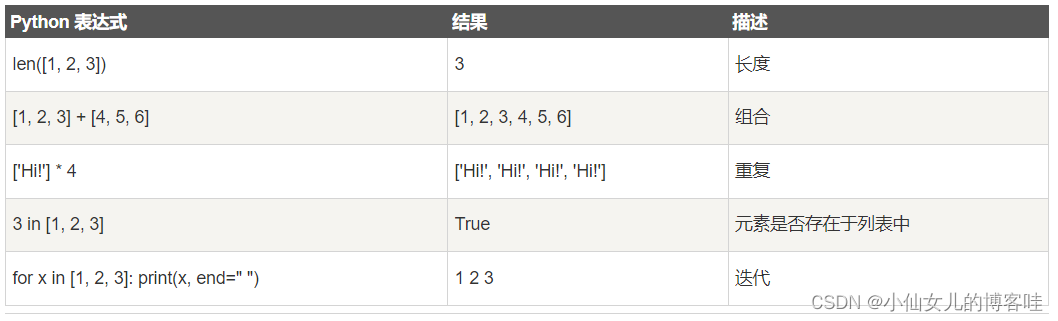
9.列表的比较
列表比较需要引入 operator 模块的 eq 方法
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
print("operator.eq(a,b): ", operator.eq(a, b)) # False
print("operator.eq(c,b): ", operator.eq(c, b)) # True
八.Python3数据类型–tuple(元祖)
1.定义
元组也是序列,和列表不同点是元组中的内容是不可变的,用()作为标记
元组中的元素用逗号分隔
元组中的元素数据类型可以不一致
2.语法
元组使用(),列表使用的是[]
1. 定义元组:t1 = (1, 2, 3, 4, 5 )
2. 定义空元组:t2=()或者t3=tuple()
3. 定义只有一个元素的元组:t4=(1,) 元素的后面必须有一个逗号,否则就不是元组了
4. 定义嵌套的元祖
# 定义元组
# 定义元组
t1 = (1, 2, 4, 5, 6)
t2 = ()
t3 = tuple()
print(t1)
print(t2)
print(t3)
t4 = (1)
t5 = (1,)
print(type(t4)) # <class 'int'> 整数
print(type(t5)) # <class 'tuple'> 元组
# 元组是可以嵌套的
t6 = ((1, 2, 3), (4, 5, 6))
print(t6)
3.访问元组
3.1通过下标||索引访问元组中的元素
# 访问元组中的元素
tt1 = (1, 2, 4, 5, 6)
print(tt1[1]) # 2
3.2 通过下标||索引截取元组中的元素
website = ('Google', 'Baidu', 'Taobao', 'Wiki', 'Weibo', 'Weixin')
print(website[1:-1]) # ('Baidu', 'Taobao', 'Wiki', 'Weibo')
print(website[-3]) # Wiki
print(website[0:3]) # ('Google', 'Baidu', 'Taobao')
4.删除元组
因为元组中的元素是不能改动的,所以元组中的元素无法删除,但是可以删除整个元组
# 删除元组
tt2 = (1, 2, 4, 5, 6)
print(tt2)
del tt2
print(tt2) # 报错 name 'tt2' is not defined. Did you mean: 't2'?
5.内置函数
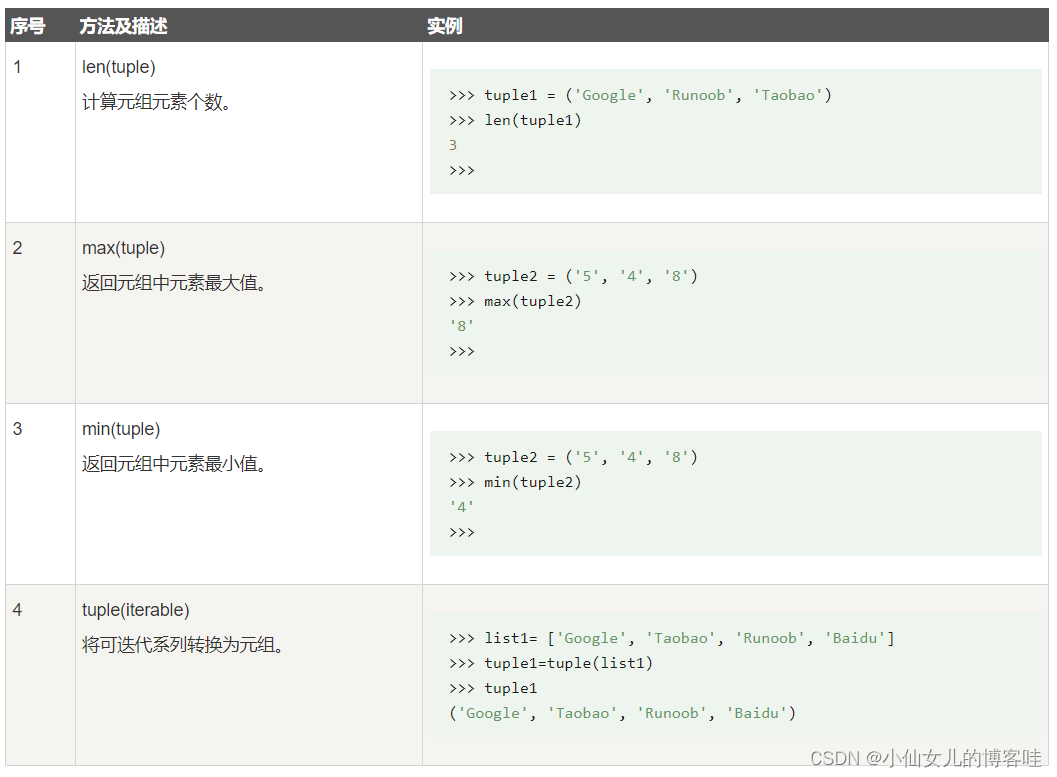
# 4.元组的内置函数
scores = (50, 32, 56, 12, 78)
print(f"共有{len(scores)}名同学考试")
print("最高分%d" % max(scores))
print("最低分{0}".format(min(scores)))
6.元组的运算符
1. + 加号
2. +=
3. *号
4. in 在
# 5.元组运算符
goods1 = ("蓝莓", "香蕉", "苹果")
goods2 = ("杯子", "咖啡", "牛奶")
# +
goods3 = goods1 + goods2
print(goods3) # ('蓝莓', '香蕉', '苹果', '杯子', '咖啡', '牛奶')
# +=
goods1 += goods2
print(goods1) # ('蓝莓', '香蕉', '苹果', '杯子', '咖啡', '牛奶')
# *
goods4 = ("蓝莓", "苹果")
print(goods4 * 2)
# in
print("大鸭梨" in goods4) # False
九.Python3数据类型—集合(Set)
我们目前学习了字符串,列表,元组,接下来要学习集合----set
1.定义
集合(set)是一个无序的不重复元素序列。
使用{}作为标记
因为集合中的元素是无序的,所以不支持下标索引访问
集合中的元素是可以修改的
2.字符串,列表,元组,集合之间的区别
列表:内容可修改,可重复
元组,字符串:内容不可修改,可重复,有序
集合:内容无序,不重复
3.语法
定义set集合:stu_no={1101,1102,22,33}
定义空set集合:只有一种方式 stu_no=set()
注意:{}不是定义空集合的,是用来定义空字典的
stu_no = {1101, 456, 32, 78, 1101}
ids = set()
print(stu_no) # {456, 32, 1101, 78}两个1101只剩下了一个
print(ids)
**4.**集合常用的方法
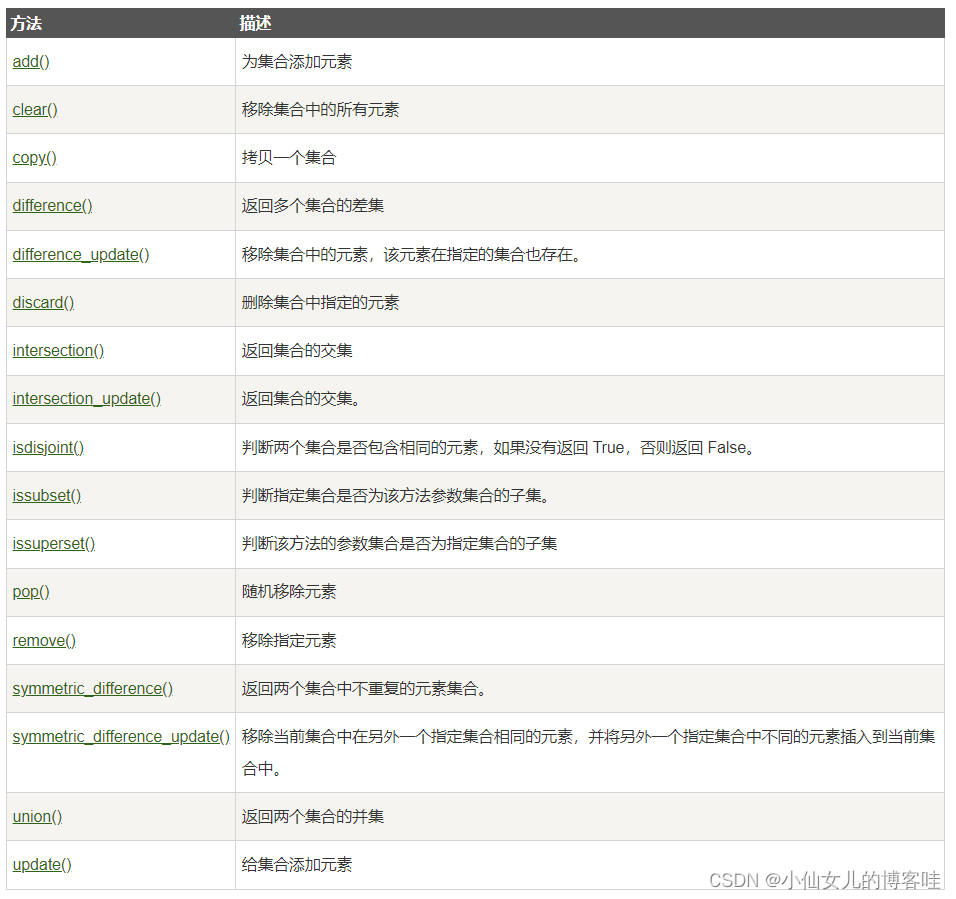
4.1添加元素 add() and update()
add()只可以添加不可变的元素,如数字,字符串,元组,否则报错;
add()把元素整体性的添加进去
update()可以添加字符串、列表、元组、字典等可迭代的元素,若添加数字类型会报错。
update()会把元素拆分再添加进去
wai_mai = {"美团", "饿了么", "闪送", "宅急送"}
# 1.add()
wai_mai.add("星巴克专送")
wai_mai.add((1, 2, 3))
print(wai_mai) # {'美团', '闪送', (1, 2, 3), '宅急送', '饿了么', '星巴克专送'}
# 2.update()
teacher = {"王艺彤", "何子龙", "刘晓兰"}
teacher.update("孟丹")
print(teacher) # {'孟', '王艺彤', '丹', '刘晓兰', '何子龙'} 孟和丹是拆分开的
teacher.update(["张远", "张慧"])
print(teacher) # {'刘晓兰', '何子龙', '丹', '张慧', '张远', '孟', '王艺彤'}
4.2 移除元素 remove()&&pop()&&discard()&&clear()
1.remove() 移除元素
移除的必须是集合中有的元素,否则报错KeyError
weather = {"晴天", "多云", "小雨", "大雨", "雷阵雨"}
weather.remove("小雨")
print(weather) # {'晴天', '雷阵雨', '大雨', '多云'}
# weather.remove(1) # KeyError: 1
2.pop()移除元素
随机移除集合中的元素
car = {"宝马", "奔驰", "大G", "路虎", "库里南"}
car.pop()
print(car) # {'大G', '库里南', '路虎', '奔驰'}
3.discard()移除元素
discard() 方法用于移除指定的集合元素。
该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
# discard()
watch = {"欧米茄", "天梭", "劳力士", "卡地亚", "浪琴"}
watch.discard("伯爵") # 不报错
print(watch) # {'劳力士', '卡地亚', '天梭', '欧米茄', '浪琴'}
watch.discard("天梭")
print(watch) # {'欧米茄', '卡地亚', '浪琴', '劳力士'}
4.clear()
清空元素
```python
shoes = {"nike", "adidas", "彪马", "百丽"}
print(shoes) # {'nike', 'adidas', '百丽', '彪马'}
shoes.clear()
print(shoes) # set()
4.3差集&&交集&&并集&&子集
1.差集
1.1差集
difference() 返回多个集合的差集
defference_update() 用于移除两个集合中都存在的元素
1.2.两个方法的区别
difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
1.3 案例
# difference()
gx = {"张三", "李四", "王五"}
nl = {"张三", "李四", "赵六"}
print(gx.difference(nl)) # 返回包含在gx集合中而不包含在nl中 {'王五'}
print(gx) # {'李四', '王五', '张三'}
print(nl.difference(gx)) # 返回包含在nl中而不包含在gx中 {'赵六'}
# difference_update()
kc1 = {"html", "css", "db", "java", "jvm"}
kc2 = {"html", "css", "db", "python", "django"}
kc1.difference_update(kc2)
print(kc1) # {'java', 'jvm'} 删除kc1中既在kc1也在kc2中的共同的元素删除
print(kc2) # {'css', 'python', 'db', 'django', 'html'}
2.交集
2.1交集
intersection()方法用于返回两个或更多集合中都包含的元素,即交集,
返回一个新的集合,该集合的元素既包含在集合 set1又包含在集合 set2中
intersection_update() 方法用于获取两个或更多集合中都重叠的元素,即计算交集
2.2 两者的区别
intersection() 方法是返回一个新的集合
intersection_update() 方法是在原始的集合上移除不重叠的元素。无返回值
2.3 案例
# 交集
# intersection()
set1 = {"广安门街道", "牛街", "五福堂"}
set2 = {"朝阳街道", "双井街道", "五福堂"}
print(set1.intersection(set2))
print(set1)
print(set2)
# intersection_update()
set11 = {"广安门街道", "牛街", "五福堂"}
set22 = {"朝阳街道", "双井街道", "五福堂"}
set1.intersection_update(set2) # 无返回值
print(set1) # {'五福堂'}
print(set2) # {'朝阳街道', '五福堂', '双井街道'}
3.并集
3.1并集
union()方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次
3.2案例
cat_set = {"虎斑", "美短", "布偶"}
dog_set = {"金毛", "杜宾", "哈士奇", "法斗"}
pet_set = cat_set.union(dog_set)
print(pet_set)
4.子集issubset()&&issuperset()
4.1子集
issubset() 方法用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。
issuperset() 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。
4.2两个方法的区别
issubset() 方法和issuperset() 方法功能一样,就是语法不一样而已
4.3案例
beauty1 = {"天气丹", "兰蔻", "欧惠"}
beauty2 = {"天气丹", "兰蔻", "欧惠", "圣罗兰", "雅诗兰黛"}
print(beauty1.issubset(beauty2)) # True
print(beauty2.issuperset(beauty1)) # True
5.isdisjoint() 两个集合是否包含相同的元素
5.1isdisjoint()方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False
5.1 案例
sport1 = {"李宁", "特步", "鸿星尔克"}
sport2 = {"乔丹", "特步", "361"}
sport3 = {"adidas", "nike", "lv"}
print(sport1.isdisjoint(sport2)) # 有就返回False
print(sport1.isdisjoint(sport3)) # 没有就返回True
十.Python3数据类型—字典(Dictionary)
0.为什么要学习字典
生活案例1:一个车牌号对应一辆车,如果用List列表存储车牌号和车,需要几个列表呢?
答案:至少需要两个,一个集合存储车牌号,一个存储车的信息,两个集合中的元素必须一一对应
缺点:集合太多不好维护,能否用一个集合就解决上面的问题呢?可以
1.定义
字典是一种可变的容器,可以存储任意的数据类型
存储数据的方式为k:v,即键值对的方式
2.语法
d1={key1 : value1, key2 : value2, key3 : value3 }
说明:
1.键和值之间用冒号
2.键值对之间用逗号
3.键必须是不可变类型,比如数字,字符串,且唯一
4.值可以是任意数据类型
定义字典:
car_dict={"1101":"张三的车","1102":"李四的车"}
定义空字典
使用大括号定义空字典:empty_dict1={}
使用内置函数dict()创建空字典:empty_dict2=dict()
3.访问字典中的元素
1.根据键取值 []
stu_dict = {1: "张三", 2: "李四", 3: "王五"}
print("键是1对应的值为:" + stu_dict[1]) # 键是1对应的值为:张三
2.根据键取值 get()可以设置默认值
stu_dict.get(4,"无内容")
4.修改字典中的内容
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
4.1 向字典中添加新的键值对
# 向字典中添加新的键值对以及根据键修改对应的值
position_dict = {1: "开发岗", 2: "销售岗"}
position_dict[3] = "测试岗" # {1: '开发岗', 2: '销售岗', 3: '测试岗'}
print(position_dict)
position_dict[1] = "python开发岗" # {1: 'python开发岗', 2: '销售岗', 3: '测试岗'}
print(position_dict)
5.删除字典中的内容&&清空字典中的内容&&删除整个字典
5.1根据键删除整个键值对
# 根据键删除整个键值对
goods_dict = {1: "水杯", 2: "花束", 3: "鼠标"}
del goods_dict[1]
print(goods_dict)
5.2清空字典中的内容
# 清空字典中的内容
goods_dict1 = {1: "水杯", 2: "花束", 3: "鼠标"}
goods_dict1.clear()
print(goods_dict1) # {}
5.2 删除整个字典
# 删除整个字典
order_dict = {1: "订单1", 2: "订单2"}
del order_dict
print(order_dict) # {}
6.字典内置的函数
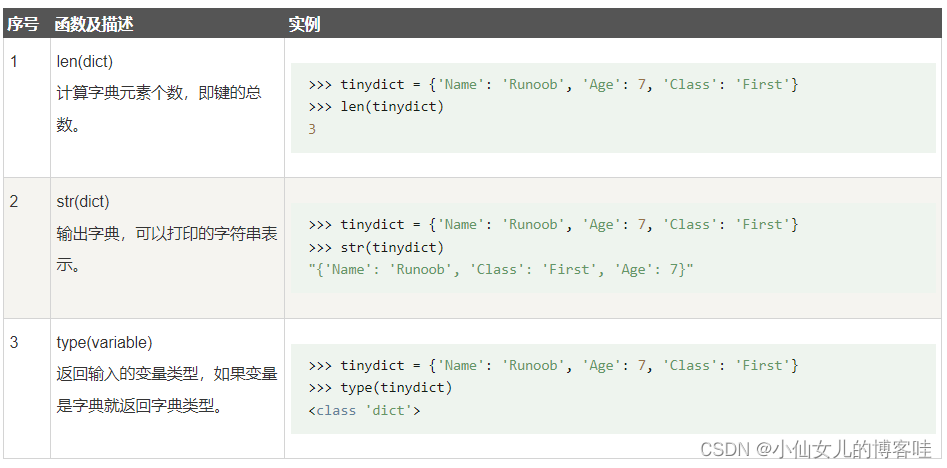
# 字典的内置函数
dict1 = {"A1": "奥迪A6", "A2": "奥迪A7"}
print("字典的长度:" + str(len(dict1))) # 字典的长度:2
print(str(dict1)) # 字符串的方式{'A1': '奥迪A6', 'A2': '奥迪A7'}
print(type(dict1)) # <class 'dict'>
7.字典内置方法
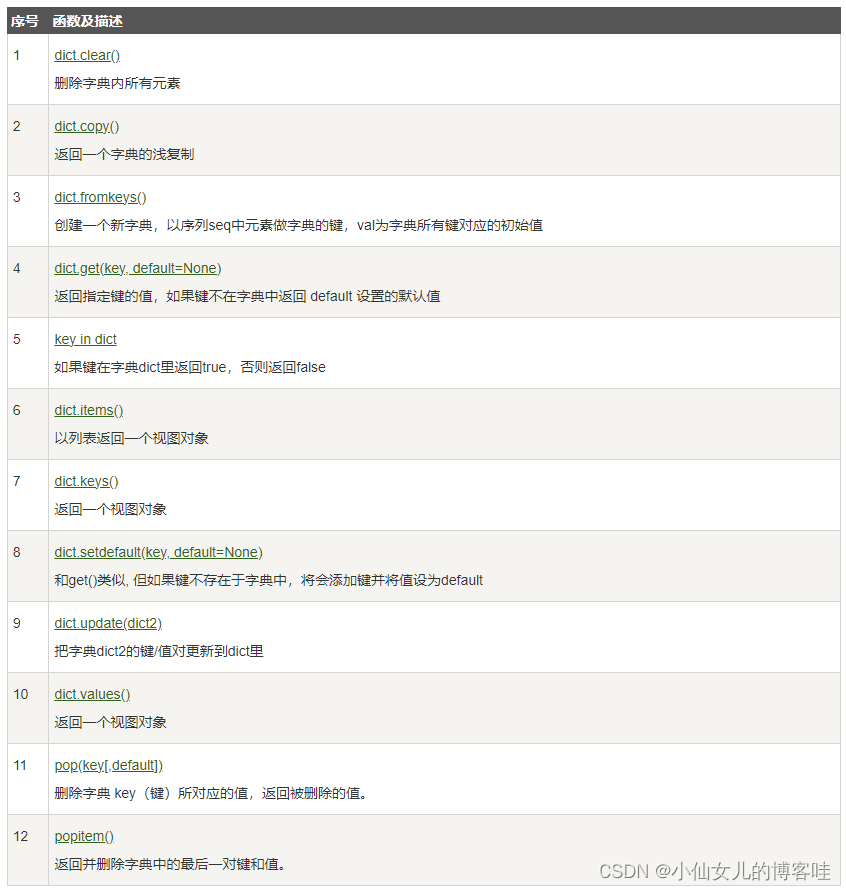
1.clear&&get&&in&&setdefault
clear()清空整个字典中内容
get() 根据键获取值,可以设置默认值,即如果键不存在值就使用默认值
in 判断键是否在指定的字典中
setdefault() 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
pet = {"a": "狗狗", "b": "猫咪", "c": "兔子"}
pet1 = {"a": "狗狗", "b": "猫咪", "c": "兔子"}
# 1.删除字典中的所有元素
pet.clear()
print(pet) # {}
# 2.get()
print(pet1.get("d", "羊")) # 羊
print(pet1.get("a")) # 狗狗
# 3.判断键在字典中是否存在
is_exists = "a" in pet1
print("键a在字典中是否存在?%s" % is_exists) # 键a在字典中是否存在?True
# 4.setdefault() 键不存在就把键和默认值添加到字典中
pet1.setdefault("d", "鸟")
print(pet1) # {'a': '狗狗', 'b': '猫咪', 'c': '兔子', 'd': '鸟'}
2.keys()&&values()&&items()
1.定义
keys() 方法返回一个视图对象。返回的是键的信息
values()返回的都是视图对象( view objects)
items() 方法以列表返回视图对象,是一个可遍历的key/value 对
2.说明
- dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
- 视图对象不是列表,不支持索引,可以使用 list() 来转换为列表
- 不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
3.案例
# keys() values() items()
pet2 = {"a": "狗狗", "b": "猫咪", "c": "兔子"}
# keys()
k = pet2.keys()
print(k) # dict_keys(['a', 'b', 'c'])
# print(k[0]) # TypeError: 'dict_keys' object is not subscriptable(可下标进行访问)
k = list(k)
print(k[0]) # a
# values()
v = pet2.values()
print(v) # dict_values(['狗狗', '猫咪', '兔子'])
# print(v[0]) # TypeError: 'dict_keys' object is not subscriptable(可下标进行访问)
v = list(v)
print(v[0]) # 狗狗
# items()
i = pet2.items()
print(i) # dict_items([('a', '狗狗'), ('b', '猫咪'), ('c', '兔子')])
i = list(i)
print(i[0]) # ('a', '狗狗')
print(i[0][0]) # a
3.pop()&&popitem()
1.定义
pop(key,[default]) 方法删除字典 key(键)所对应的值,返回被删除的值。
参数:
key - 要删除的键
default - 当键 key 不存在时返回的值
返回值:
如果 key 存在 - 删除字典中对应的元素
如果 key 不存在 - 返回设置指定的默认值 default
如果 key 不存在且默认值 default 没有指定 - 触发 KeyError 异常
popitem() 方法随机返回并删除字典中的最后一对键和值
返回最后插入键值对(key, value 形式),按照 LIFO(Last In First Out 后进先出法) 顺序规则,即最末尾的键值对
在 Python3.7 之前,popitem() 方法删除并返回任意插入字典的键值对
如果字典已经为空,却调用了此方法,就报出 KeyError 异常。
2.案例
# pop()
dict2 = {1: 1, 2: 2, 3: 3, 4: 4}
a = dict2.pop(2)
print(a) # 2
b = dict2.pop(5, "键不存在") # 键不存在
print(b)
# c = dict2.pop(6)
# print(c) # KeyError: 6
# popitem()
dict2[5] = 5
print(dict2)
d = dict2.popitem()
print(dict2)
print(d) # (5, 5)
4.直接赋值=&©()&&deepcopy()
1.定义
直接赋值:其实就是对象的引用(别名)。
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
2.案例–直接赋值
# 直接赋值
dict_3 = {1: 1, 2: 2, 3: 3}
dict_4 = dict_3
print(dict_3) # {1: 1, 2: 2, 3: 3}
print(dict_4) # {1: 1, 2: 2, 3: 3}
# 当dict_3发生变化的时候,dict_4是也随着dict_3发生变化,因为dict3和dict4指向内存的同一块地址
dict_3[4] = 4
print(dict_3) # {{1: 1, 2: 2, 3: 3, 4: 4}
print(dict_4) # {1: 1, 2: 2, 3: 3, 4: 4}
3.案例–copy()–浅拷贝
# copy()浅拷贝
a = {1: [1, 2, 3], 2: "李四"}
b = a.copy()
print(a) # {1: [1, 2, 3]}
print(b) # {1: [1, 2, 3]}
# 修改a中的2键值为"王五",我们看一下b是否发生变化
a[2] = "王五"
print(a) # {1: [1, 2, 3], 2: '王五'}
print(b) # {1: [1, 2, 3], 2: '李四'}
# 修改a中1键值追加4,我们看一下b是否发生变化 子对象没有被拷贝,b的键1会随着a的键1改变而改变
a[1].append(4)
print(a) # {1: [1, 2, 3, 4], 2: '王五'}
print(b) # {1: [1, 2, 3, 4], 2: '李四'}
4.案例–deepcopy()–深拷贝
# 深拷贝 deepcopy()
import copy
c = {1: [1, 2, 3, 4]}
d = copy.deepcopy(c)
print(c) # {1: [1, 2, 3, 4]}
print(d) # {1: [1, 2, 3, 4]}
# 将c的键1值追加5,看一下d是否发生改变,深拷贝,子对象也会被拷贝
c[1].append(5)
print(c) # {1: [1, 2, 3, 4, 5]}
print(d) # {1: [1, 2, 3, 4]}















 3953
3953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









