







文章目录
前言
在嵌入式软件开发的世界里,传统的开发流程往往受到物理硬件的限制,这导致了产品开发周期长、成本高以及团队协作困难等问题。然而,随着技术的不断进步,这些问题正在逐渐得到解决。Arm虚拟硬件平台(AVH)的推出,为嵌入式软件开发者带来了全新的开发体验,开启了嵌入式软件开发的新篇章。
Arm虚拟硬件平台(AVH)是ARM公司推出的一款基于云的解决方案,它允许嵌入式软件开发者在无需物理硬件的情况下进行软件开发。AVH通过模拟实际的硬件环境,为开发者提供了一个高度可配置、可扩展的虚拟开发平台。这种创新的方式不仅缩短了产品开发周期,还降低了成本,提高了团队协作的效率。
Arm虚拟硬件平台(AVH)的推出为嵌入式软件开发者带来了前所未有的便利和机遇。它打破了物理硬件的限制,让开发者可以在虚拟环境中进行高效、灵活的软件开发和测试。随着物联网技术的不断发展和应用,AVH将会发挥更加重要的作用,推动嵌入式软件开发的创新和进步。对于嵌入式软件开发者来说,掌握AVH的使用技巧将成为他们未来职业发展的重要能力之一。今天我们就基于百度智能云的arm虚拟硬件平台来进行一个AI图像分类的应用案例开发。
Arm虚拟硬件平台的主要特点包括:
虚拟化模型:Arm虚拟硬件提供基于云的Arm处理器和系统的虚拟化模型,包括流行的IoT开发套件。这些模型不仅包括处理器,还涵盖了外围设备、传感器和其他板级组件。软件开发便利性:虚拟硬件使用成熟的、指令准确的、可扩展的建模引擎来替代物理硬件,使得开发者能够采用现代软件开发的最佳实践来开发IoT和端点AI应用程序。可扩展性:Arm虚拟硬件允许在云中轻松运行和扩展CI基础设施,可以在几秒钟内启动成千上万的虚拟板,快速实验和测试复杂的多设备配置。加速开发:开发者可以使用敏捷的软件开发实践,如CI/CD(DevOps)和MLOps工作流程,在Arm技术上快速开始开发和测试软件。
一、准备工作
1、 购买Arm虚拟硬件镜像云服务器
购买Arm虚拟硬件镜像云服务器的过程,其实就是在主流的云服务器平台购买一个云服务器,这里推荐使用百度智能云平台。
在百度云平台上创建 Arm 虚拟硬件云服务器 BCC 实例的具体步骤如下所示。
(1)注册百度智能云账号
首先注册百度智能云账号(或百度账号),如果已经拥有就不需要再注册,直接登录即可。
(2)登录百度智能云账号
然后访问并登录百度智能云百度智能云-登录 (baidu.com),选择云账号登录,输入注册时填的账号和密码即可完成登录:

在这里需要区分一下,是否为 百度智能云的新用户,这里定义新用户,指的是 未购买过 百度智能云的任何一款云服务器产品,包括 从未注册过百度智能云账号的用户、以及已注册过百度智能云账号但未有发生过购买行为的用户。
(3)点击进入个人中心 百度智能云控制台 (baidu.com),参考下图进入个人认证(实名制认证)界面:
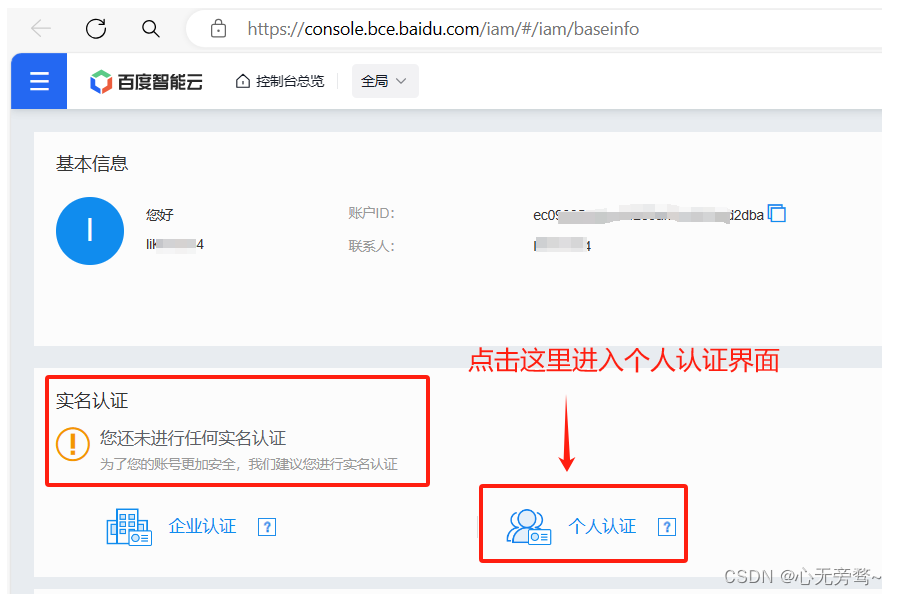
(4)进行个人实名制认证
参考下面的步骤进行:
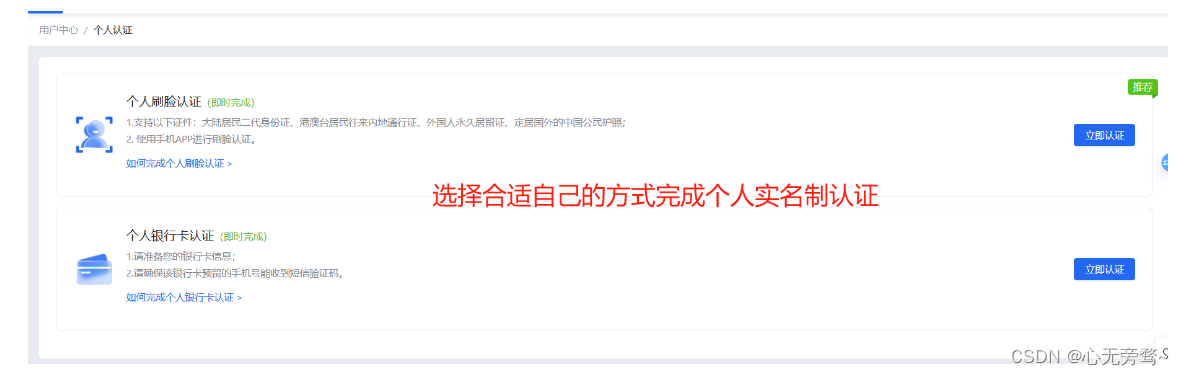
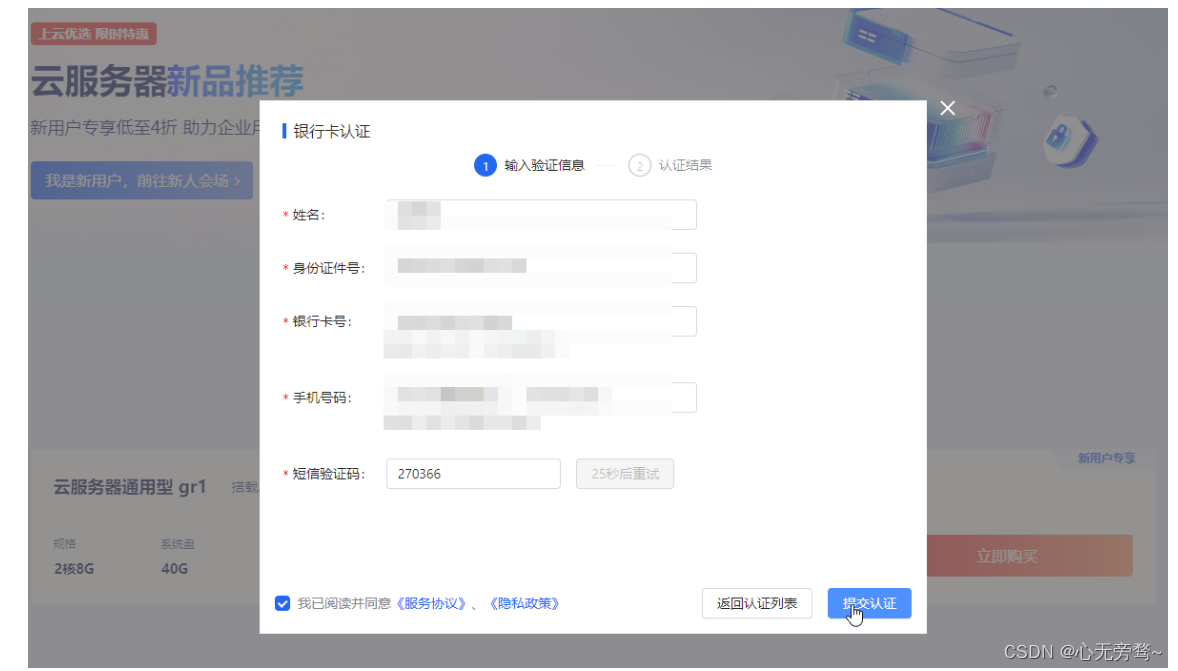

(5)购买云服务器:访问并登录百度智能云 云市场,主页产品搜索框检索“Arm虚拟硬件”进入产品详情页面。
直达链接:Arm 虚拟硬件(Arm Virtual Hardware)购买链接
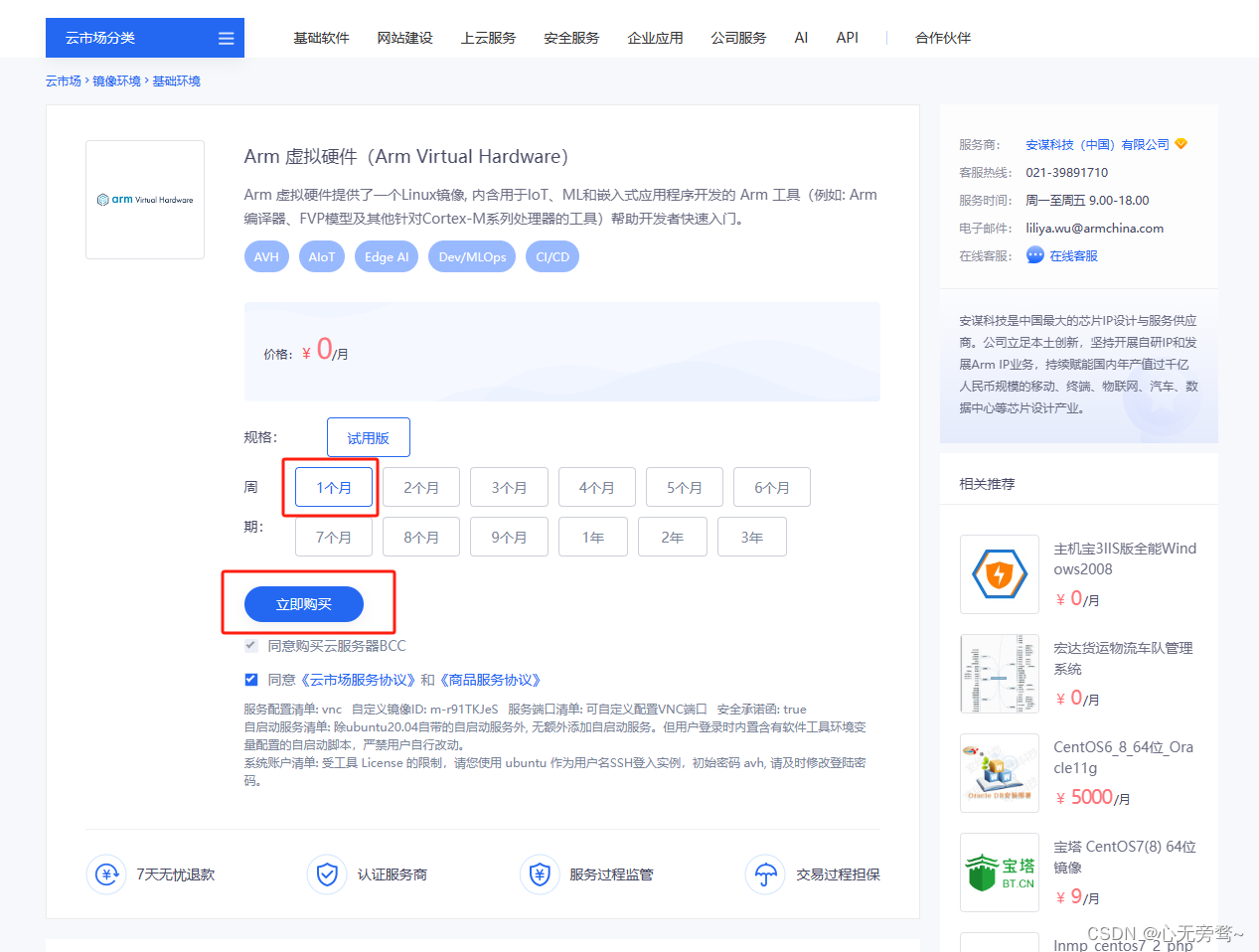
我们可以先购买一个月试用一下,具体配置要求如下:
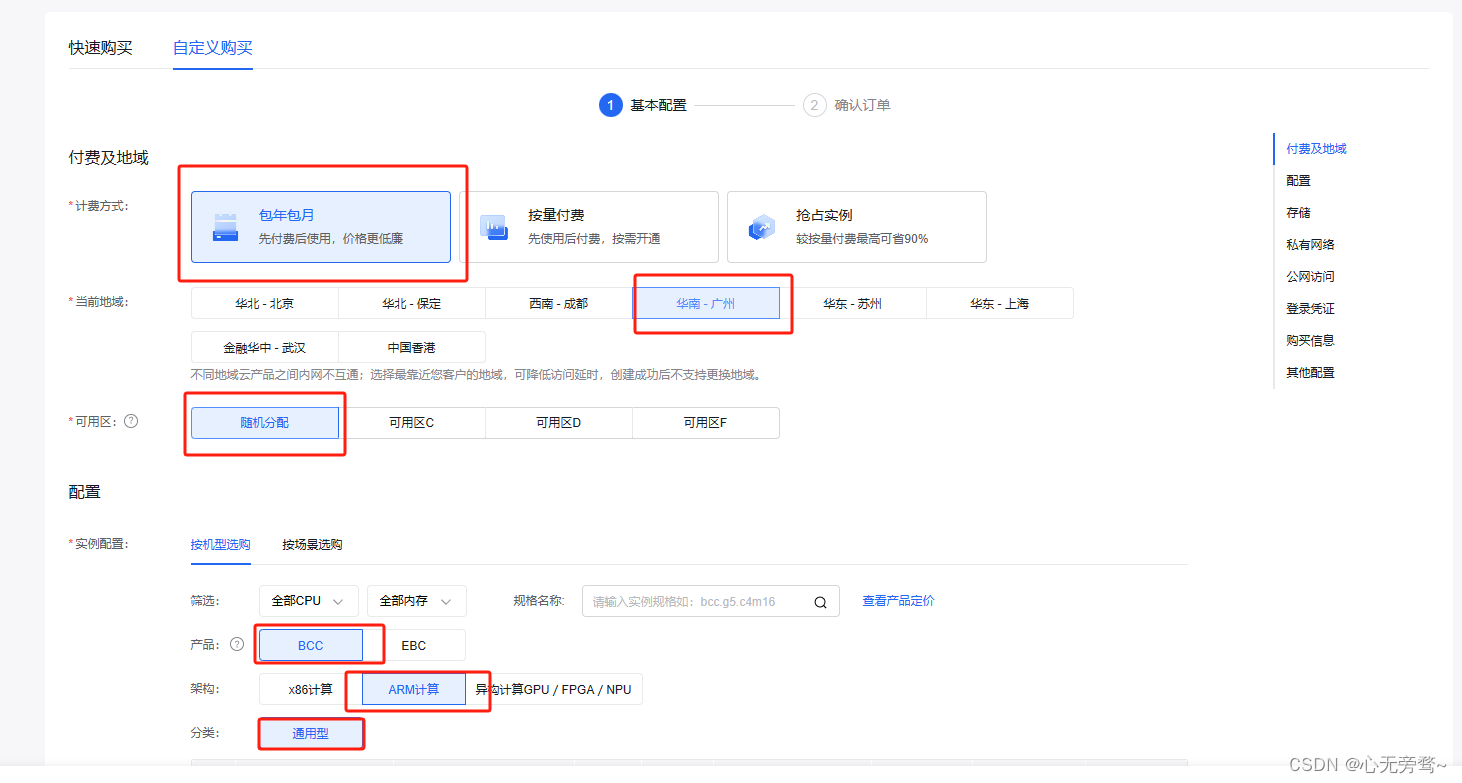
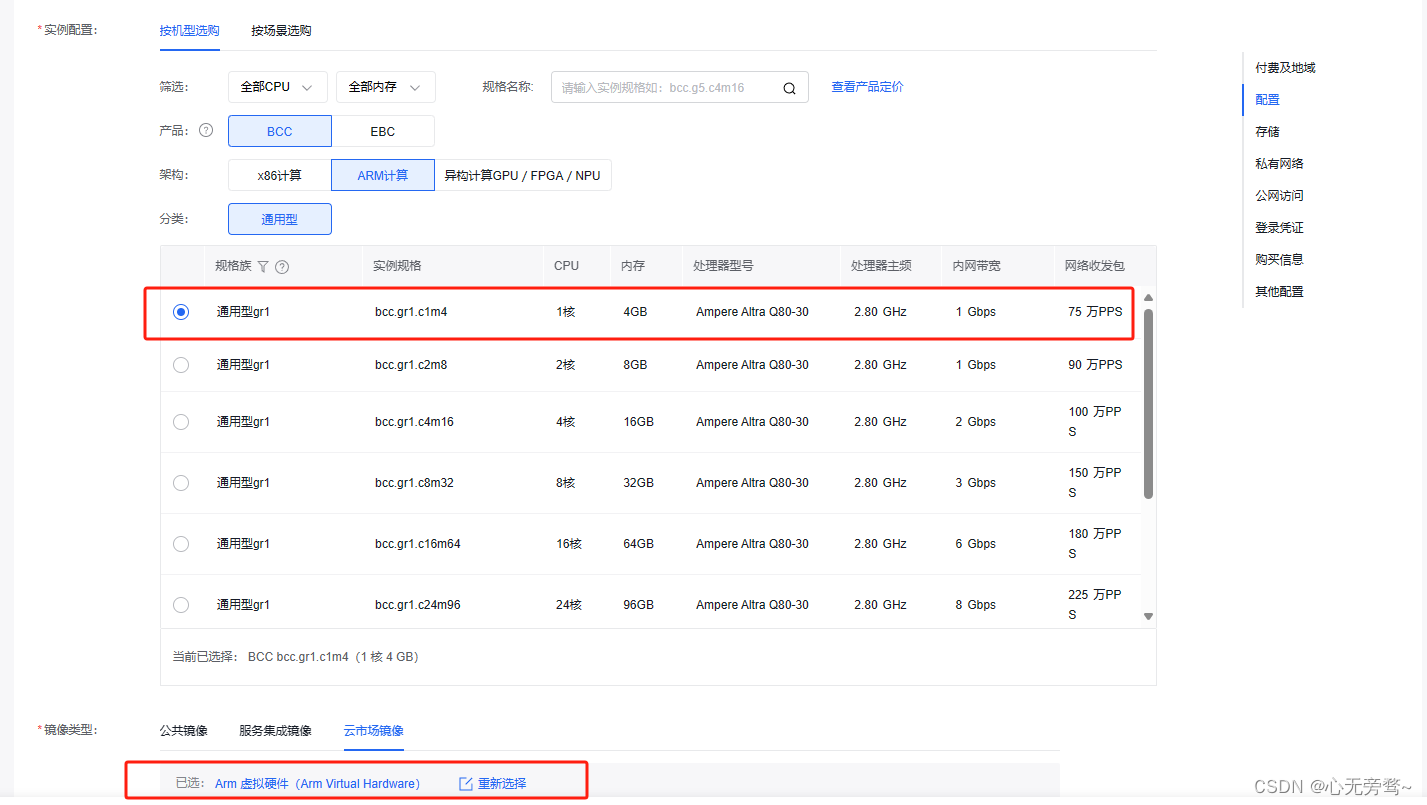
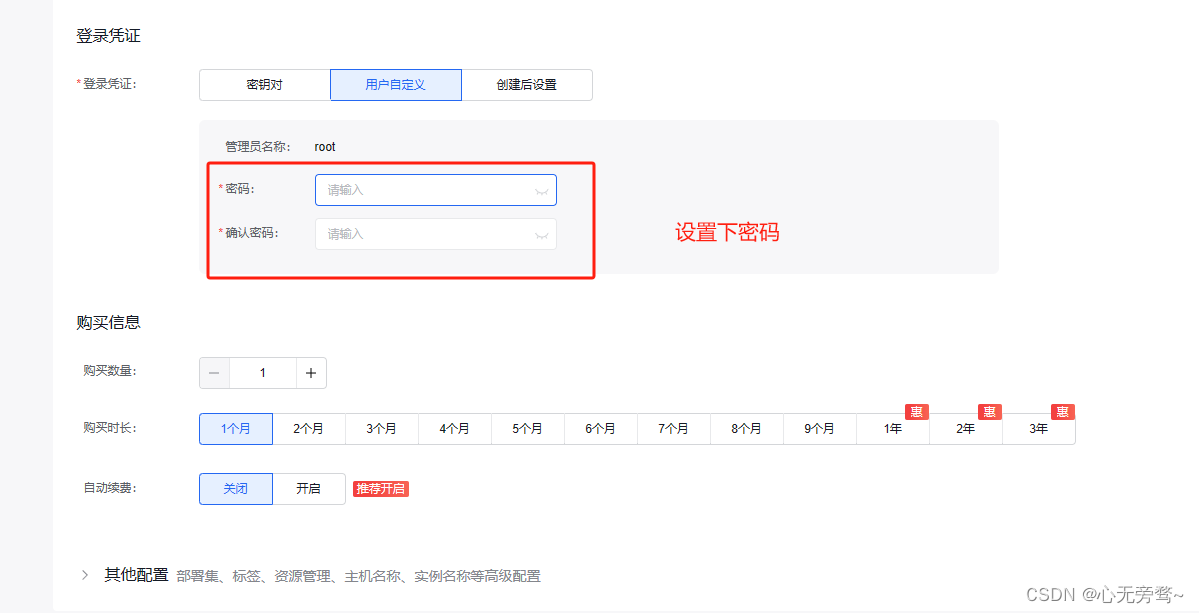
其它都不需要修改直接点击确认购买即可。
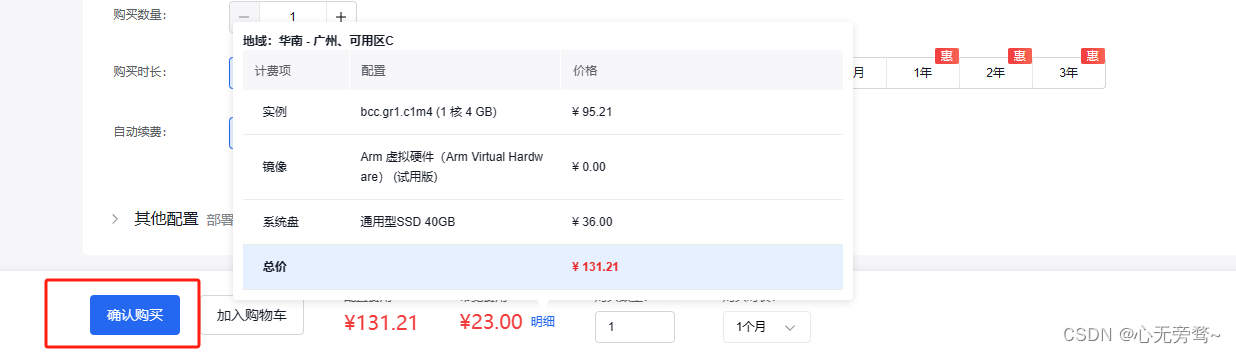
后续只需要进行支付操作即可。
2、查看已购买的Arm虚拟硬件镜像云服务器(BCC实例)
首先进入百度智能云控制台,然后点击云服务器BCC。
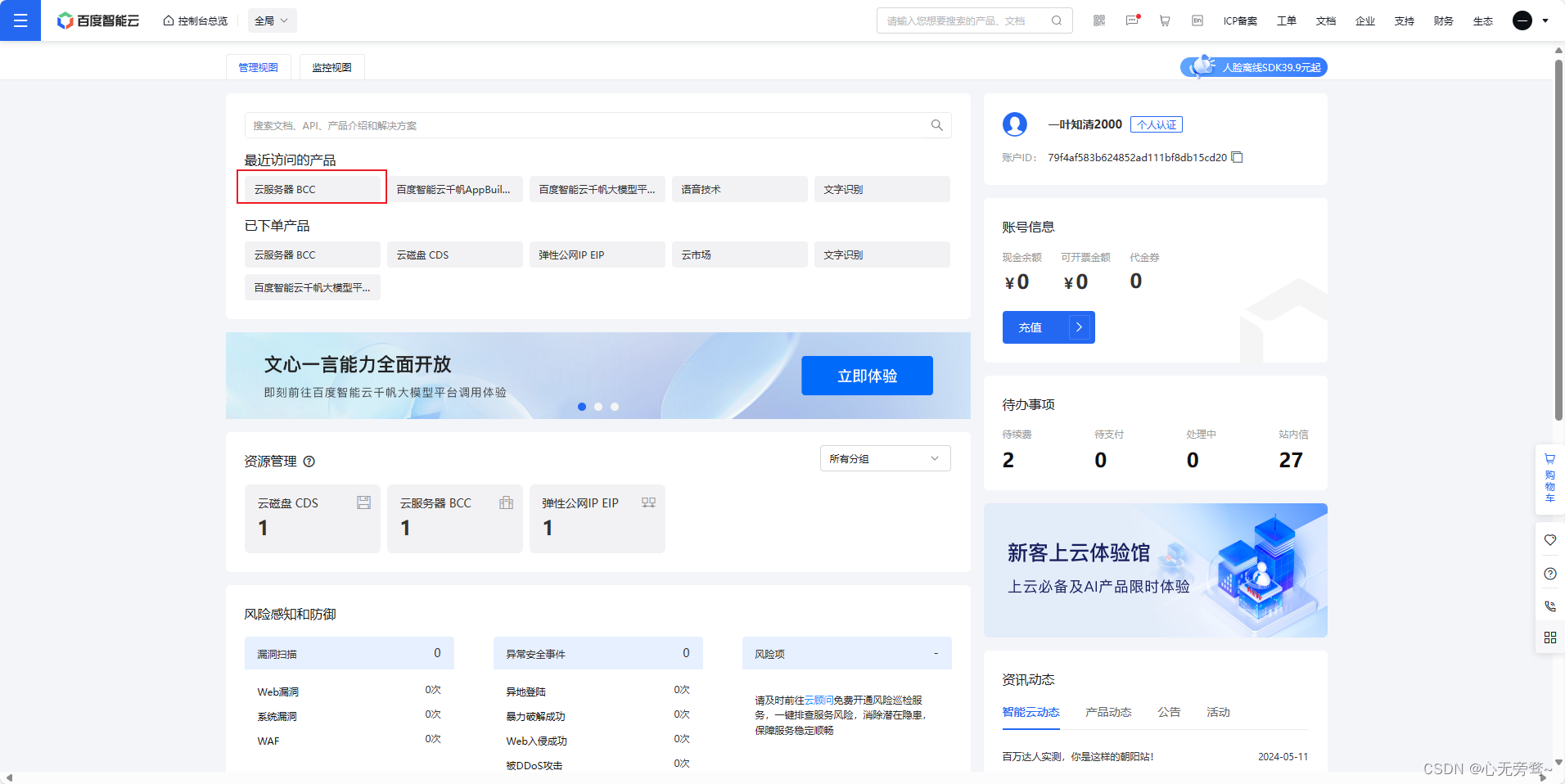
然后点击远程登录。
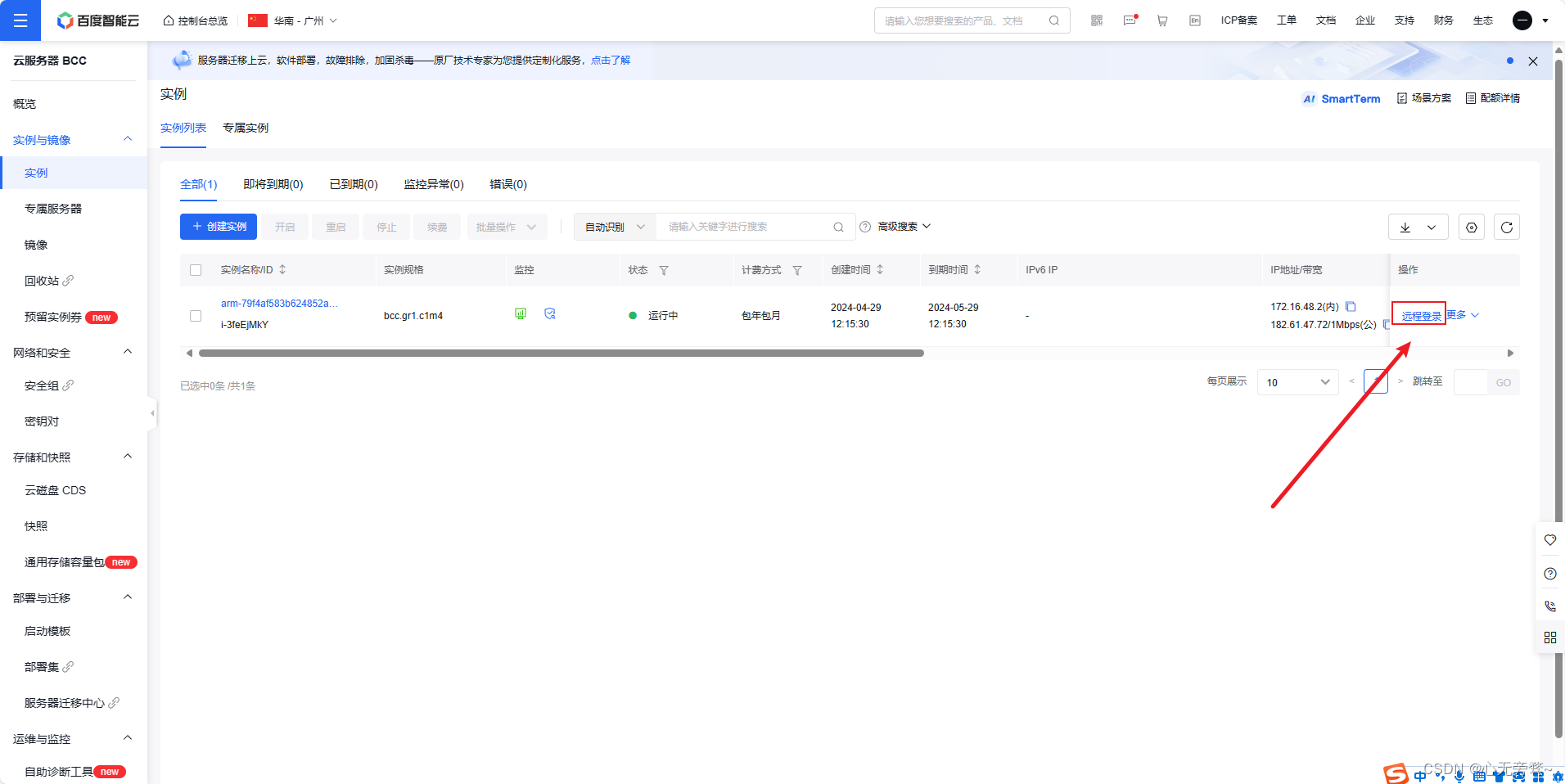
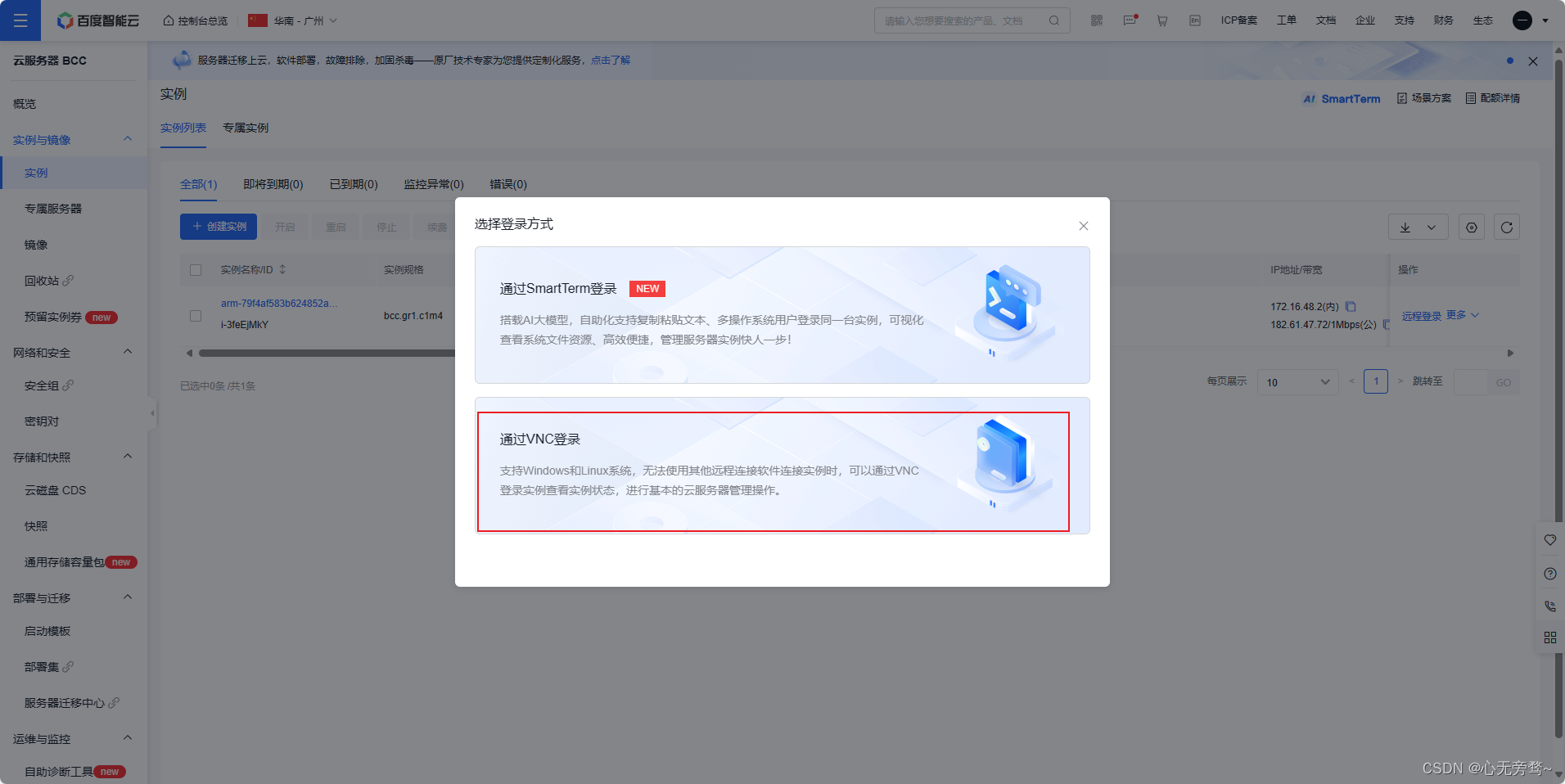
选择通过VNC登录即可跳转到arm虚拟硬件服务器,刚进来需要输入密码,然后输入y回车即可。
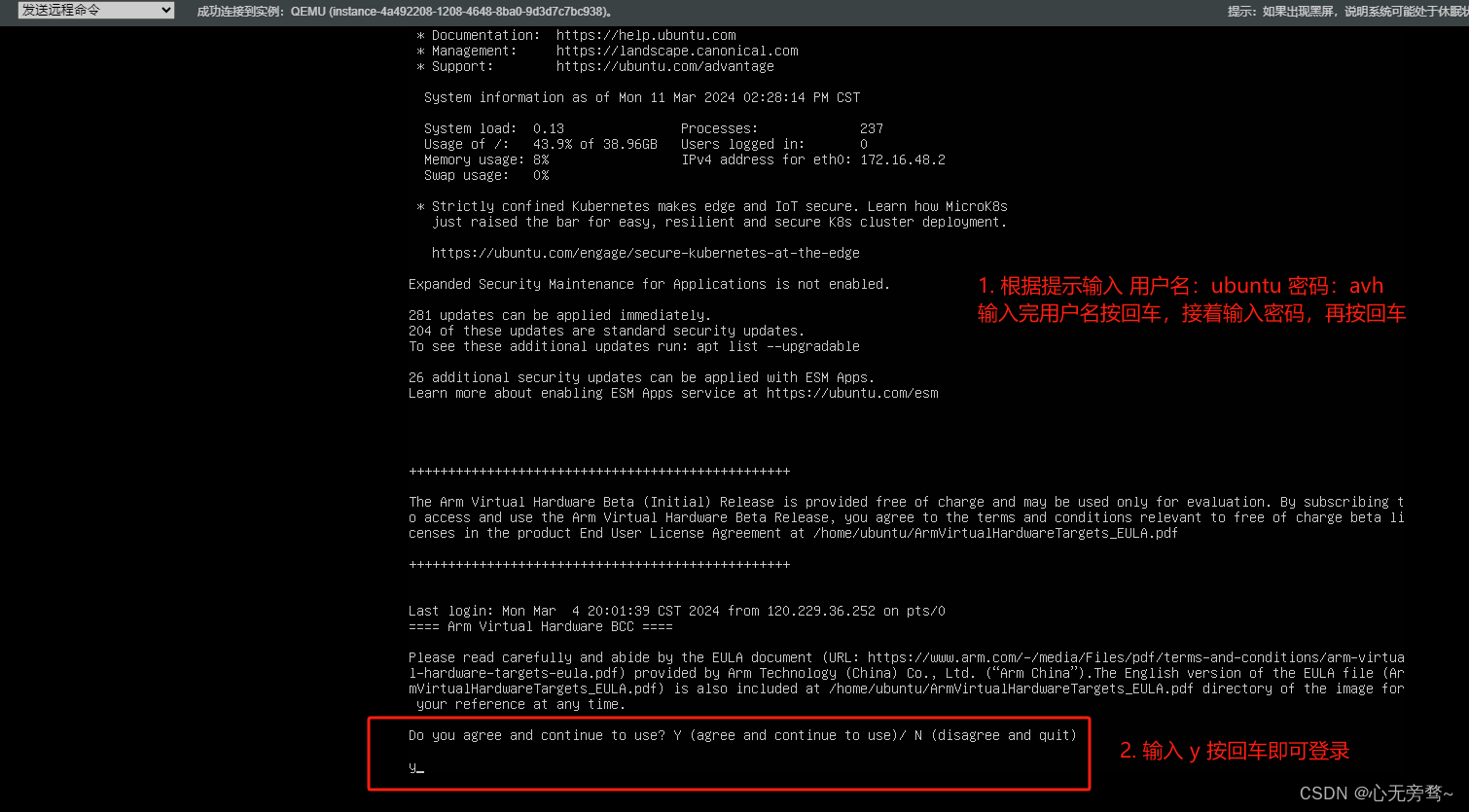
现在我们就已经完成了所有的准备步骤,下面我们将进行安装本次案例所需的一些环境以及工具包。
3、arm虚拟硬件环境安装
登录Arm虚拟硬件镜像云服务器后,第一步我们要做的就是配置好我们的开发环境。
由于我们整个开发调试是基于MDK开发环境,所以我们需要先把一些必备的软件包下载好,以免在下面的开发步骤中需要再次去下载。
为了减少大家去搜索和查找pack包的时间,这里提供了一个相对比较完整的pack包汇总的文件包,只要把这个文件下载下来,并传输到云服务器指定位置,即可自动识别,完成pack包的安装。
详细步骤如下所示:
(1)下载对应的软件包
我们可以使用以下命令行,直接在Arm虚拟硬件镜像中完成对软件包文件的下载,注意:本命令在 /home/ubuntu/ 目录下执行即可。
wget https://Arm-workshop.bj.bcebos.com/packs.tar.bz2
有时候网速不好下载有点慢,耐心等待即可~

2)执行对 packs.tar.bz2 文件的解压
这个操作就在 /home/ubuntu 目录对软件包文件进行解压即可,由于文件比较大,解压过程大概需要1分钟,请耐心等待。
参考执行命令如下:
tar -xvjf packs.tar.bz2
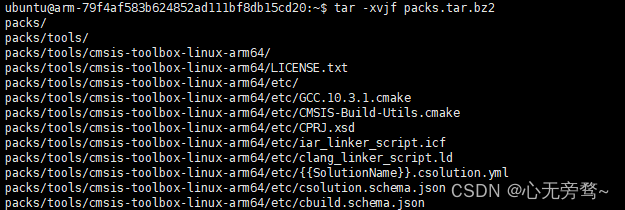
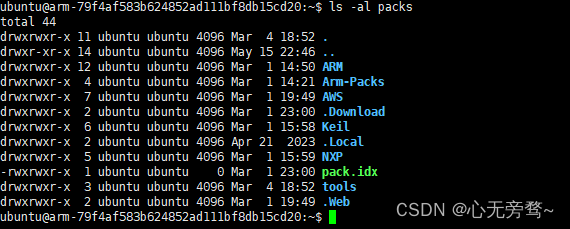
解压完成后,可使用下面的指令查看一下解压好的文件,参考执行命令为:
ls -al packs
(3)安装make工具
由于在代码构建、编译过程中,我们会用到make工具,而默认的Arm虚拟硬件镜像中并没有安装这个工具,所以我们需要在正式开始做实验前,使用下面的命令安装好make工具。
参考执行命令为:
sudo apt-get install make
至此,通过以上步骤的操作,我们就完成了所有基本的开发环境安装,也就可以进行下面的开发工作了。
我们本次案例需要用到FVP模型,可以通过以下命令査看Arm虚拟硬件镜像支持的 Arm 固定虚拟平台(Fixed Virtual Platform,FVP)模型的清单:
ls /opt/VHT/bin/FVP_*

二、模型训练以及导出
本次案例我们使用的深度学习框架是百度推出的PaddlePaddle,飞桨框架。
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。目前,飞桨累计开发者1070万,服务企业23.5万家,基于飞桨开源深度学习平台产生了86万个模型。飞桨助力开发者快速实现AI想法,快速上线AI业务。帮助越来越多的行业完成AI赋能,实现产业智能化升级。
在这里,我们可以借助百度飞桨星河社区,该社区有每天4个小时的V100算力支持我们进行模型的训练。


2.1 数据预处理
首先,我们先在网上寻找一下我们需要的数据集,比如我这次做的项目是垃圾识别,那么我就上网找了一个垃圾分类数据集,该数据集总共有6个类别,分别是'纸板,玻璃,金属,纸张,塑料和垃圾。


在训练之前,我们需要将数据集挂载到飞桨的服务器上面,然后使用以下命令解压数据集:
!unzip /home/aistudio/data/data108025/垃圾分类.zip -d /home/aistudio/work
然后使用以下代码将数据集进行处理,生成train_list.txt 和 val_list.txt文件。
dirpath = "/home/aistudio/work/garbageclassification/Garbageclassification"
# 先得到总的txt后续再进行划分,因为要划分出验证集,所以要先打乱,因为原本是有序的
def get_all_txt():
all_list = []
i = 0
for root,dirs,files in os.walk(dirpath): # 分别代表根目录、文件夹、文件
for file in files:
i = i + 1
if("cardboard" in root):
all_list.append(os.path.join(root,file)+" 0\n")
if("glass" in root):
all_list.append(os.path.join(root,file)+" 1\n")
if("metal" in root):
all_list.append(os.path.join(root,file)+" 2\n")
if("trash" in root):
all_list.append(os.path.join(root,file)+" 3\n")
if("plastic" in root):
all_list.append(os.path.join(root,file)+" 4\n")
if("trash" in root):
all_list.append(os.path.join(root,file)+" 5\n")
allstr = ''.join(all_list)
f = open('/home/aistudio/work/all_list.txt','w',encoding='utf-8')
f.write(allstr)
return all_list , i
all_list,all_lenth = get_all_txt()
print(all_lenth-1) # 有意者是预测的图片,得减去
然后将数据集打乱:
import random
random.shuffle(all_list)
random.shuffle(all_list)
最后生成:
train_size = int(all_lenth * 0.7)
train_list = all_list[:train_size]
val_list = all_list[train_size:]
print(len(train_list))
print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











