







目录
Scrapy —— 高层次信息爬取
- 运行流程
- 引擎从调度其中取出一个URL用于接下来的抓取。
- 引擎把URL封装成一个请求,传给下载器。
- 下载器将资源下载,并封装成一个响应。
- 爬虫解析响应。
- 解析出的是项目,则交给项目管道进行下一步处理。
- 解析出的是URL,则把URL交给调度器等待下一步的抓取。
Pyspider
- selenium
- Crawley —— 提取数据方式
- Portia —— 没有编程基础可视化
- Newspaper —— 新闻、文章、内容分析
实现方法
- 获取网址链接
- 用于重写获取的第三步子URL(编写子类)
- 获取排行内容
- 拿到排行的URL
- 在第三步基础上,对类进行重写操作
- 获取评价等信息
具体操作
-
丢弃
首先创建scrapy项目
scrapy startproject BigWork
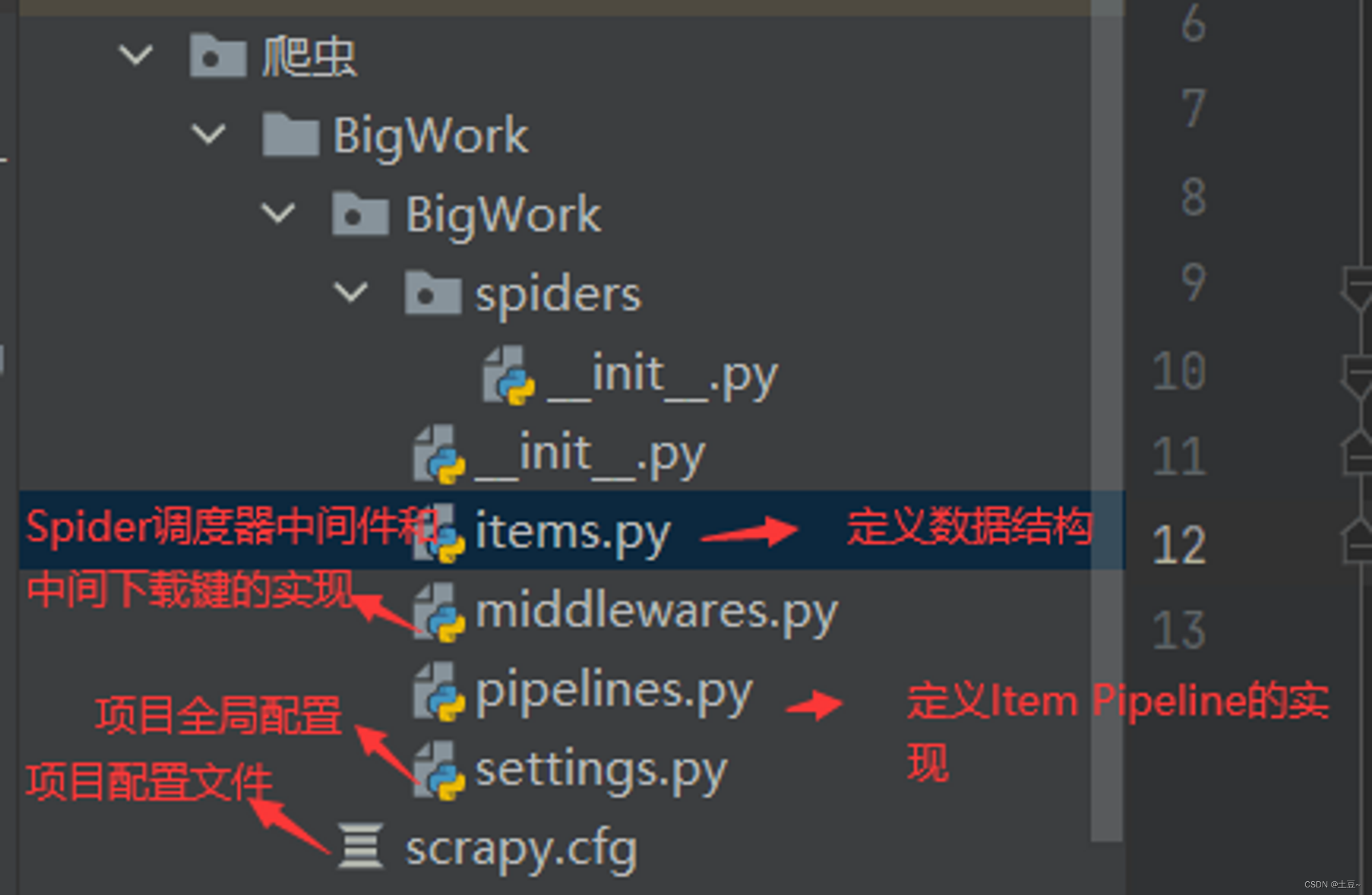
spiders文件夹用于编写文件夹规则
scrapy crawl BigWork
```bash
browsermob-proxy -port 9999
curl -X POST http://localhost:9999/proxy
```
- 反向
采集文档
一、数据采集目标
获取电影风云榜单前三十五名(自定义条数),获取内容如下:
影片信息
- 电影名
- 排行榜
- 影片简介
- 热度
- 影片URL
- 评分
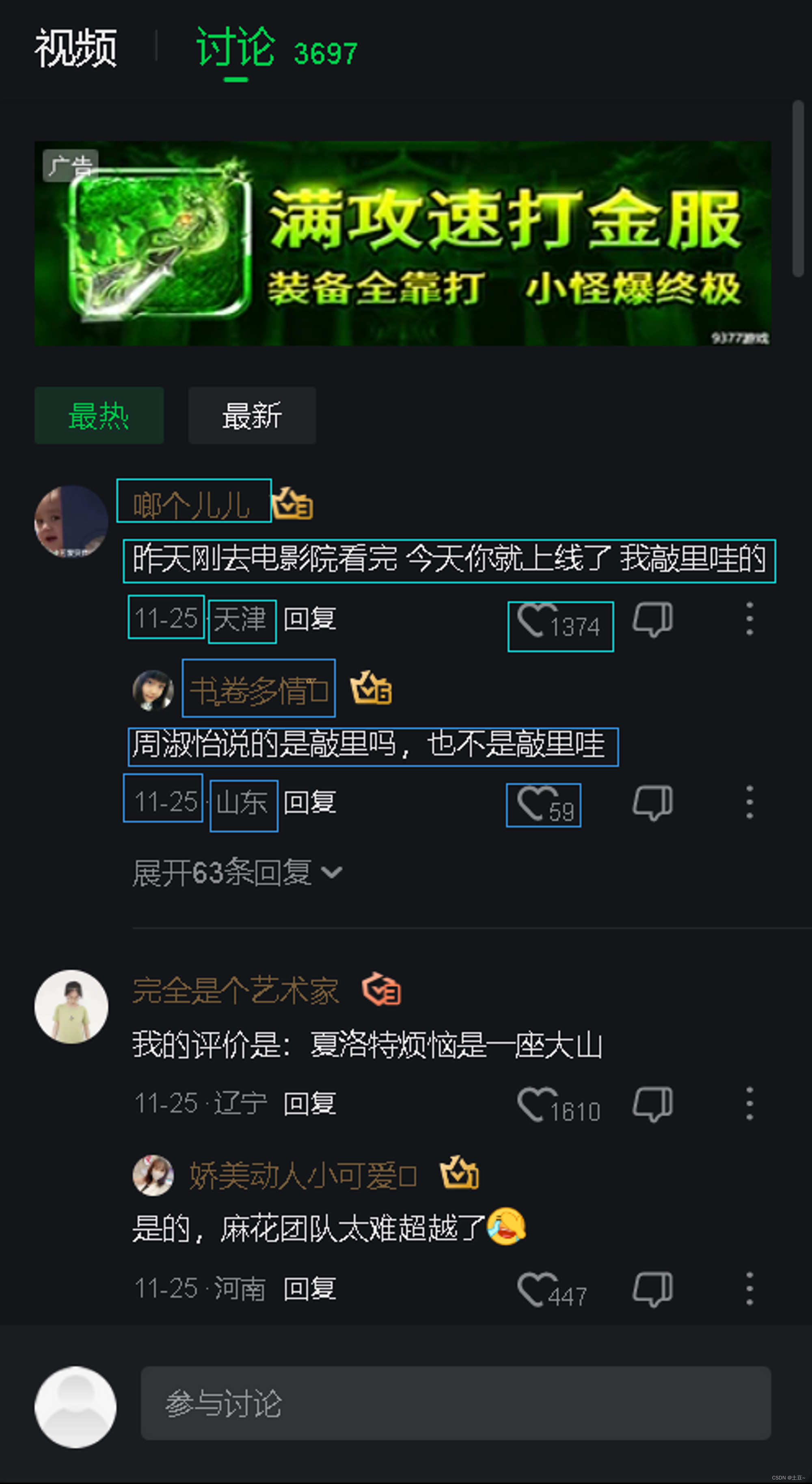
- 评论信息
- 图例
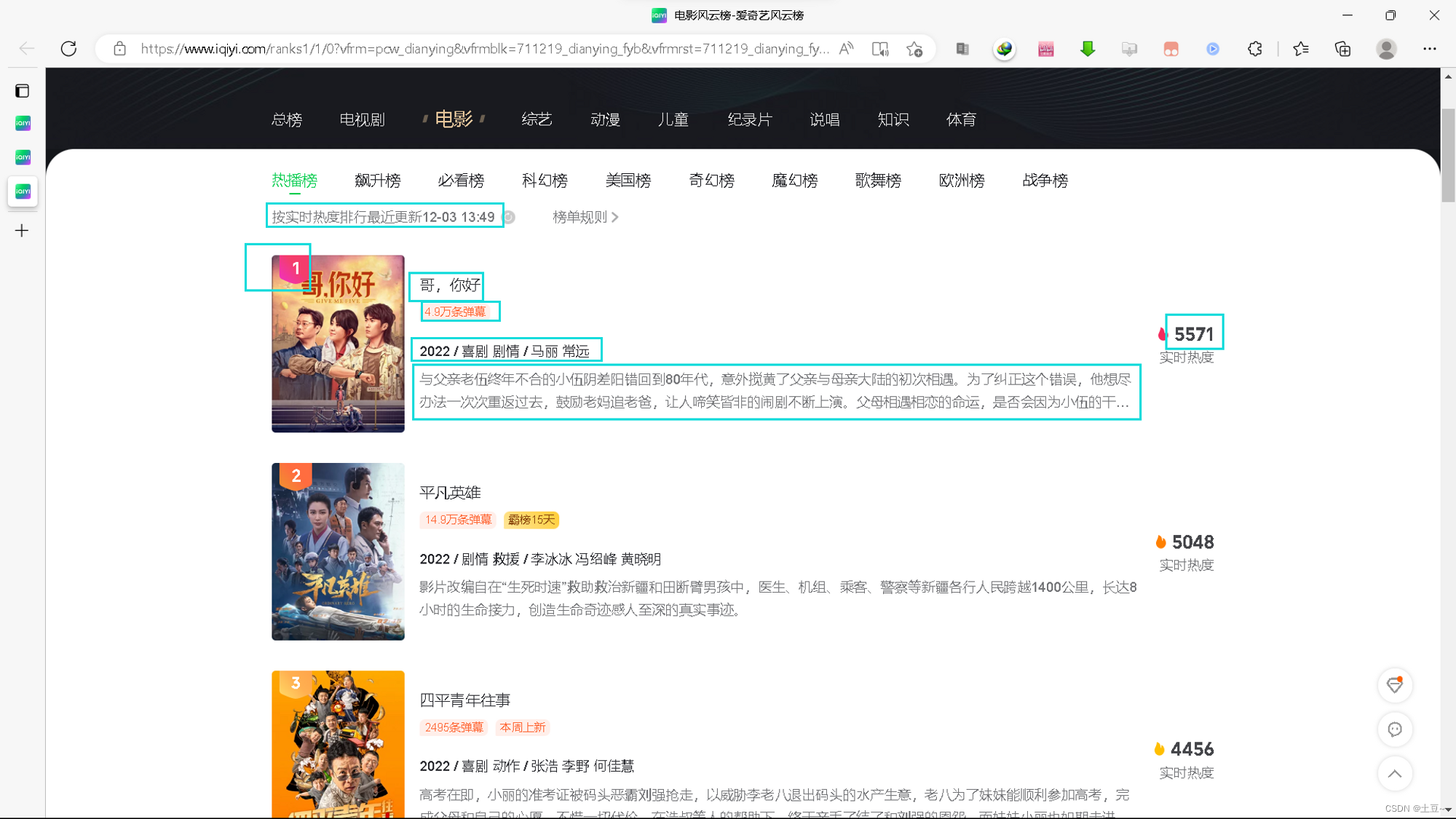
评论信息
- 用户名
- 评论时间
- IP地点
- 点赞数
- 评论回复
- 以及评论回复的1-4条的信息
- 图例
二、目标网站设计原理分析
初步采集,先了解该网页设计框架,获取内容区域:风云榜。如下:
进入电影风云榜
进入后样式
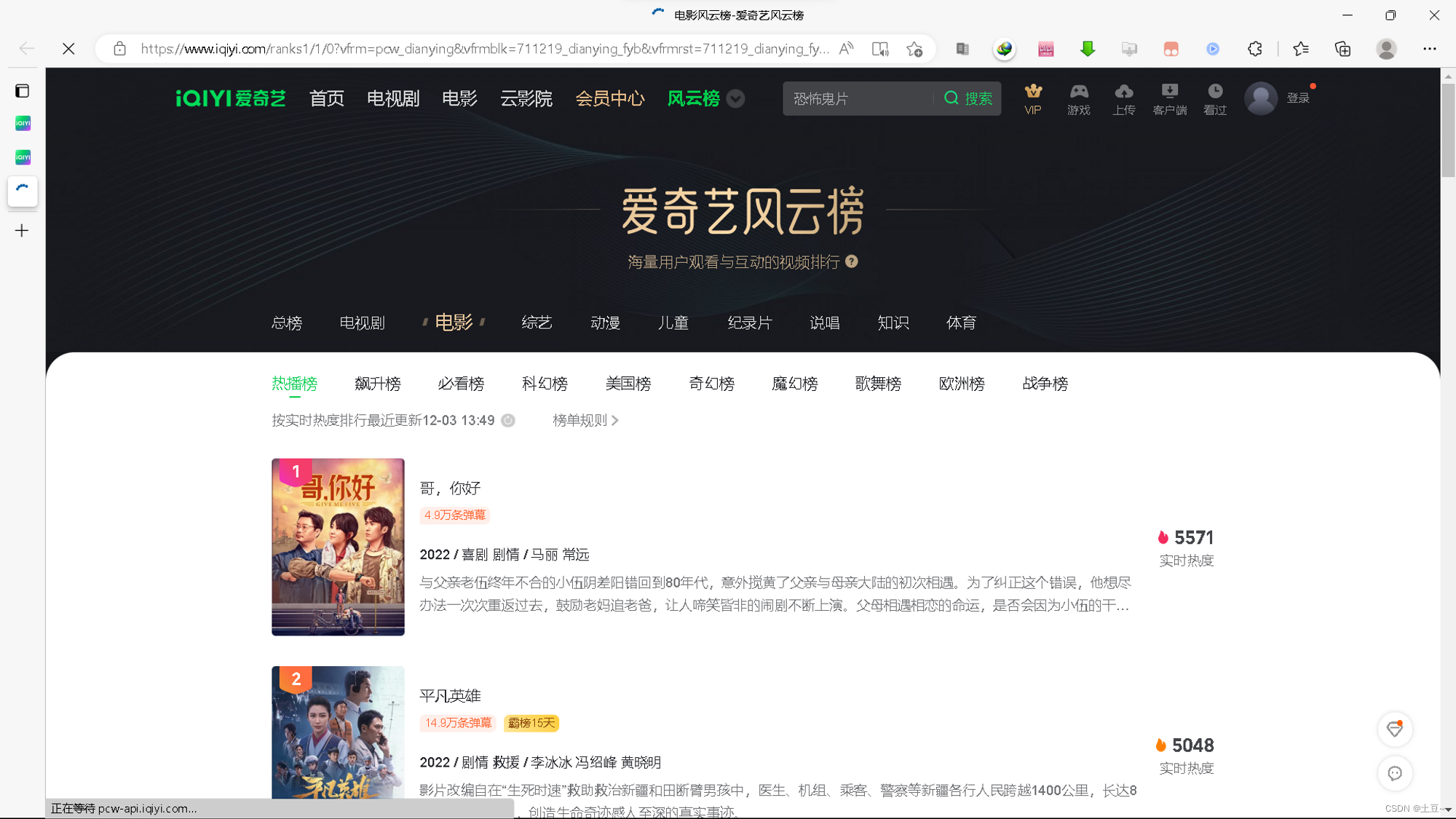
查看到入口后,分析界面采用的技术,Ctrl + u查看网络源代码。
发现直接可以获取源数据,接下来接着点击电影内部的评论是否采用同样技术。
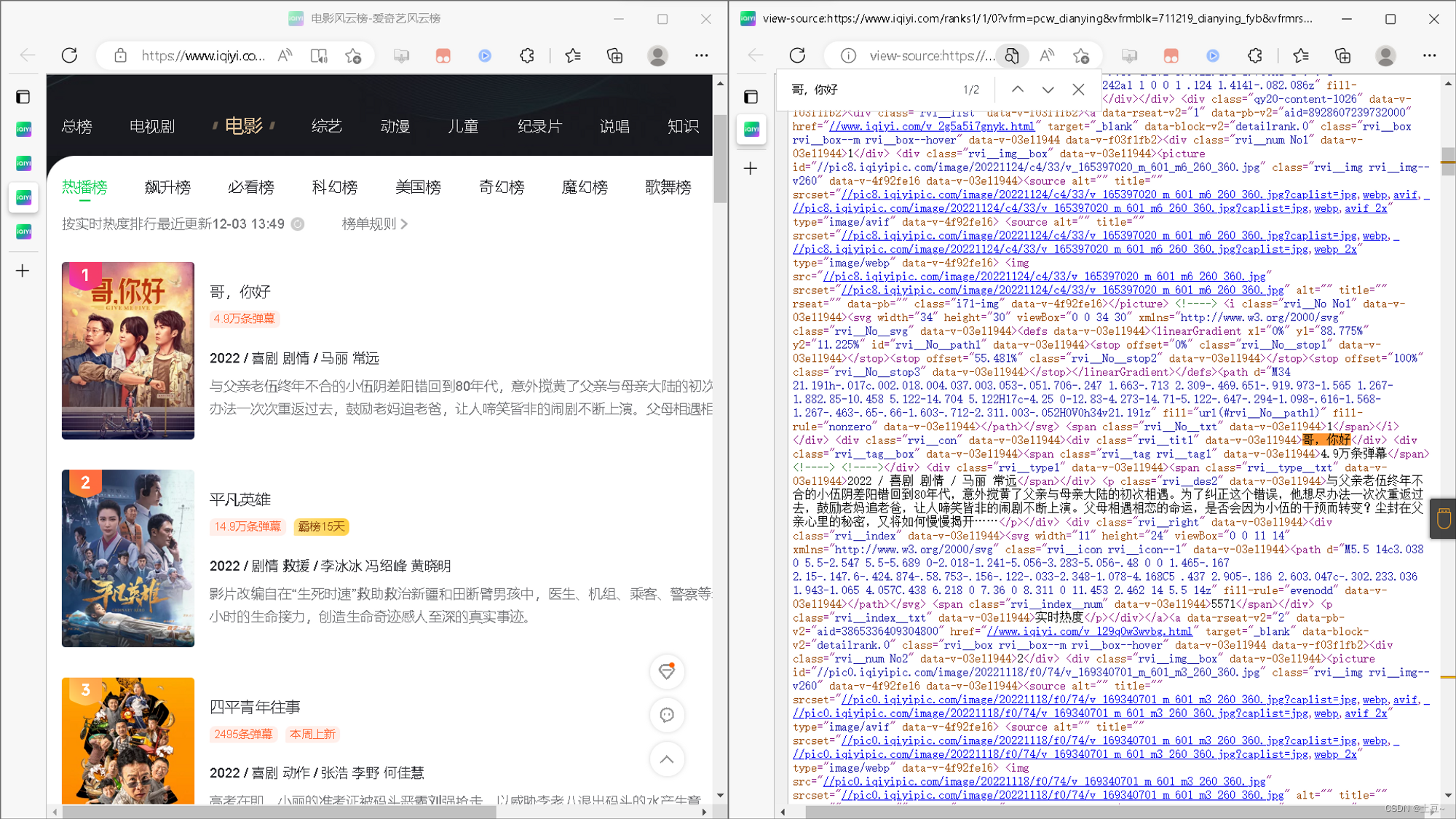
这时,查看电影内的元素发现没有左方蓝色区域呈现的源码,所以初步判断影片内采用的是JavaScript异步渲染和AJAX的动态网页。
初步使用selenium与Pyspider框架进行调试
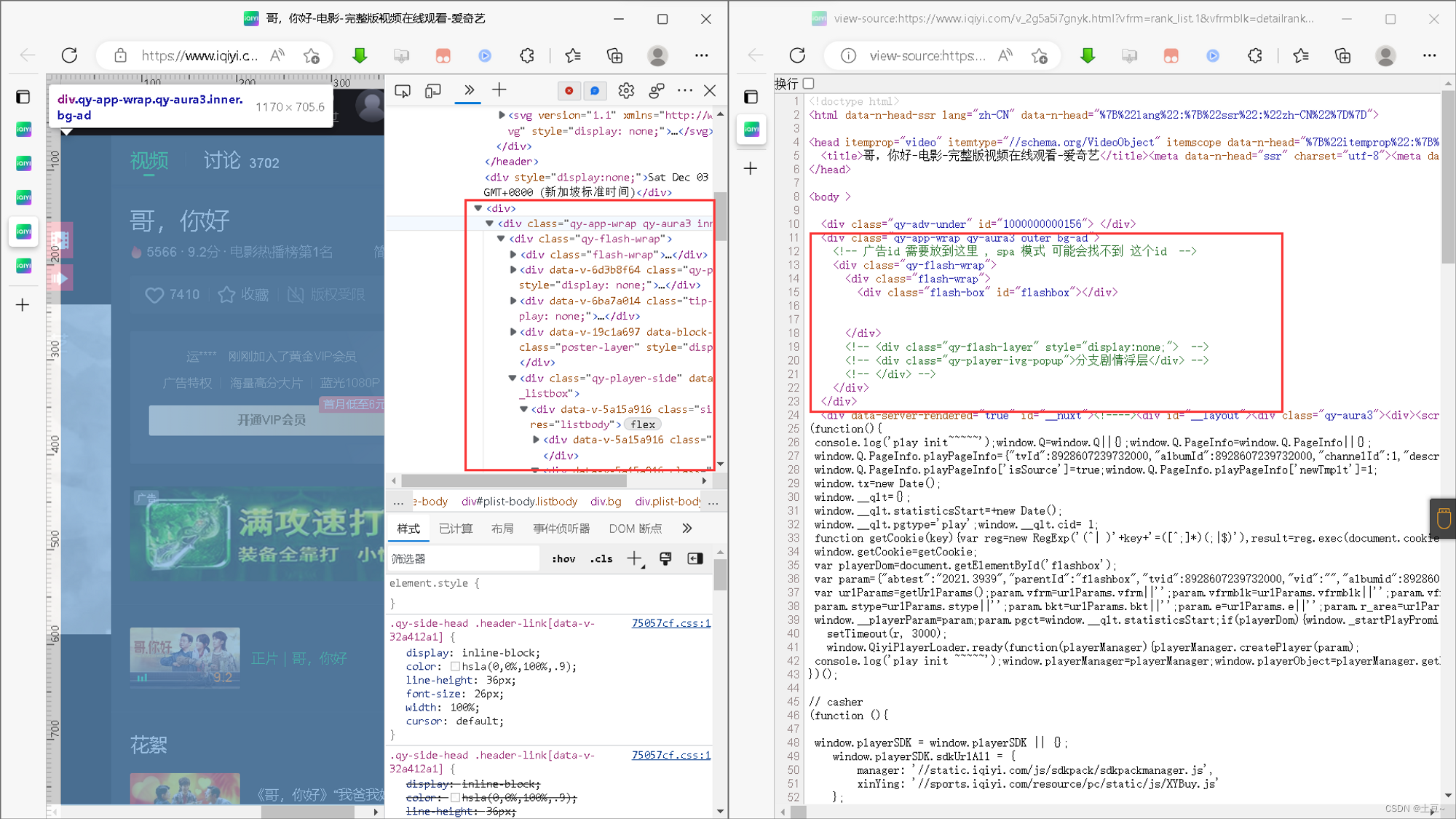
三、数据采集流程与步骤说明
但以上两个框架仅可获取到爱奇艺首页,无法获取风云榜内容(由于异步渲染,同时结合JavaScript方法)。
1、更换获取方式
经过以上两个框架调试无果,还不能放弃,此时查看爱奇艺是否存在API接口。
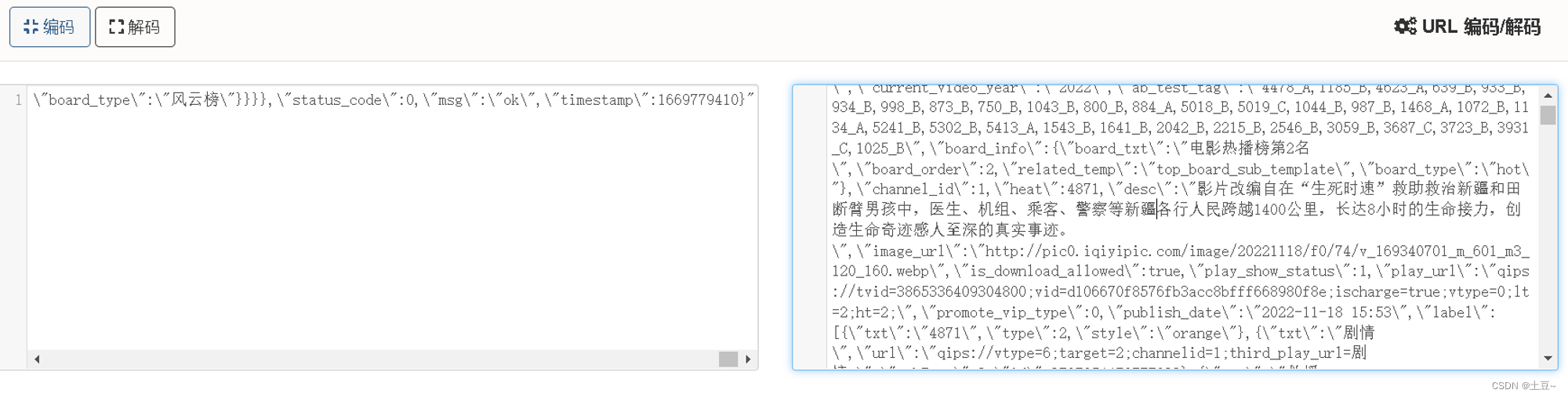
此时发现base_info……存有该影片的信息介绍,但最初风云榜源码已有相同的信息。
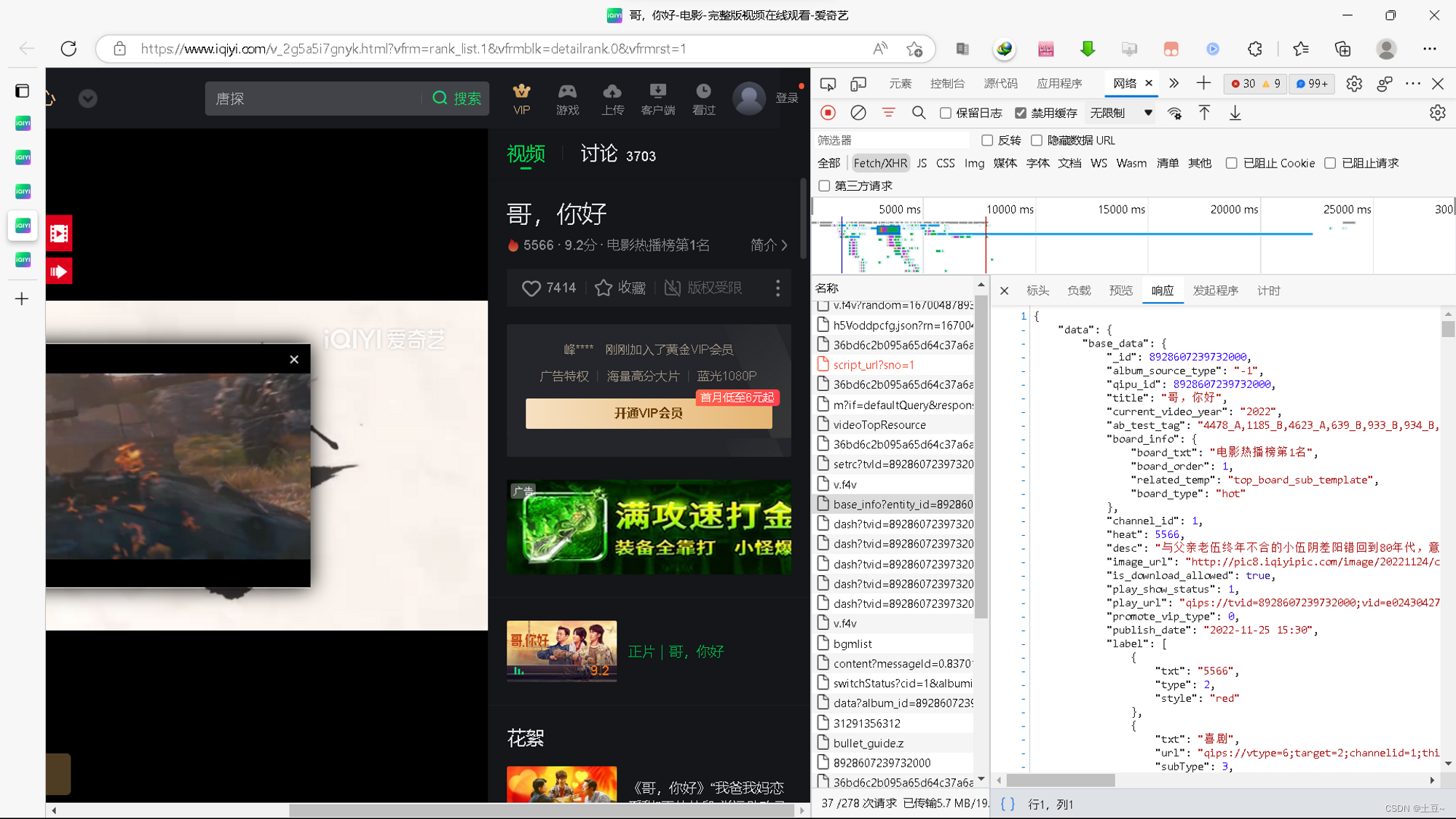
2、查找API接口
此时再找是否存在评论的API接口。
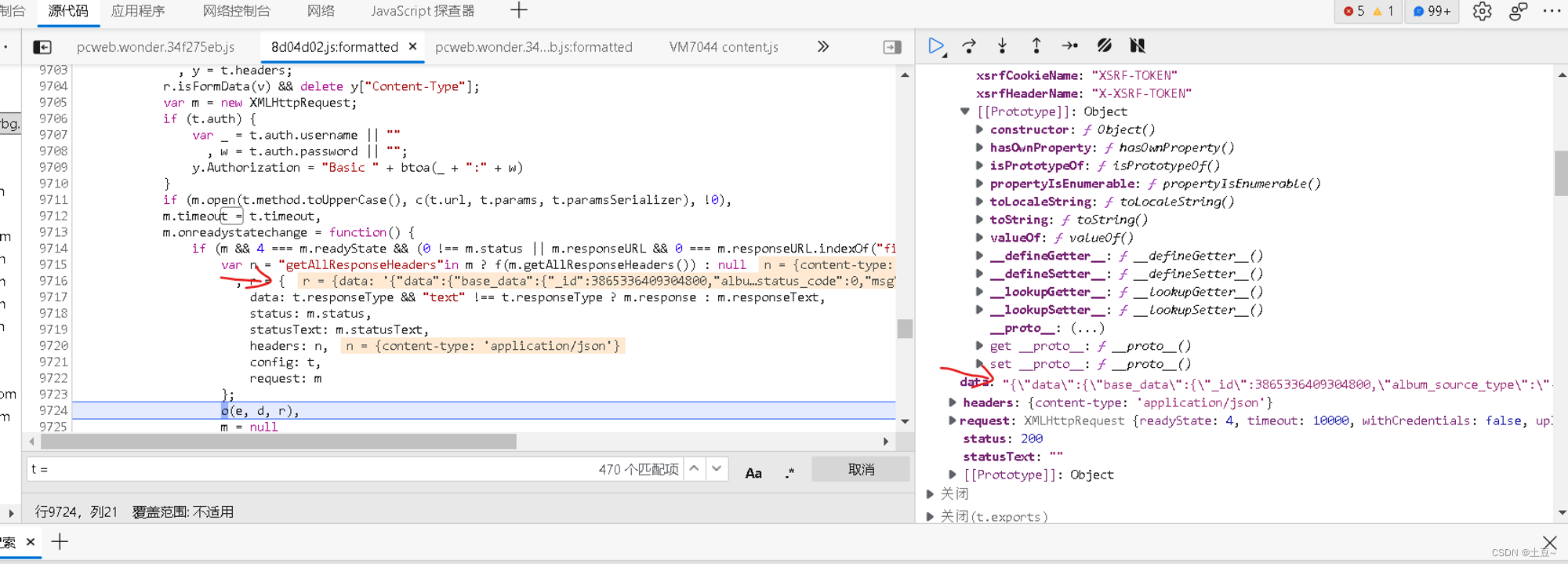
而评论也是使用JS点击才能出现内容,所以转换到JS数据查看,这时发现有一个get_base……与前面影片信息的base_info……有个相同单词,点开后惊奇发现,用户名和评论内容就在这里。
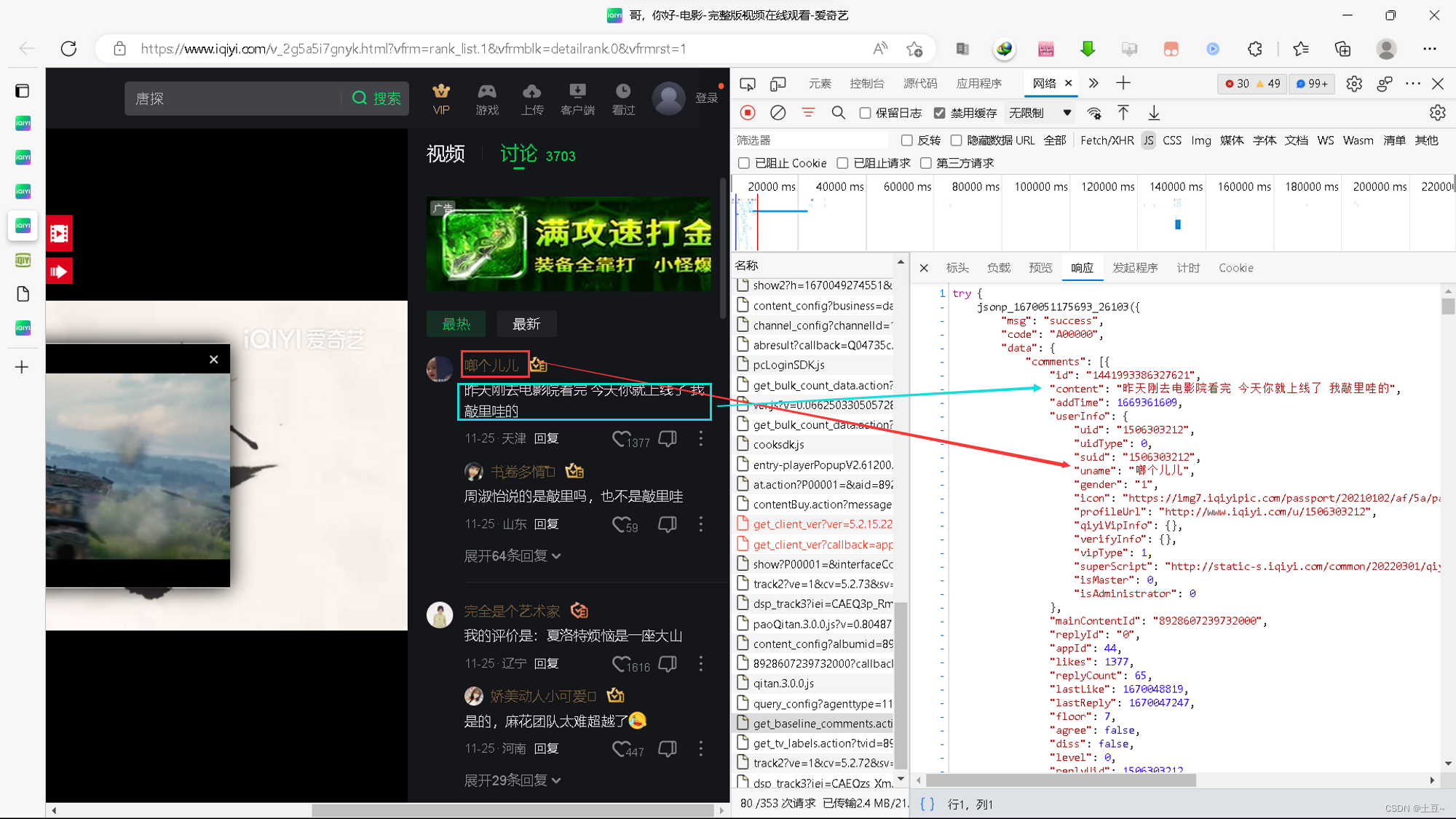
3、自动化
不过仅凭着两条还无法判断是否全部包含评论内容,不急,接着进入其链接查看
此时影片和评论信息均已找到对应API接口,但却要在程序上实现自动化。
查找评论API的参数在不同影片之间有什么变化。
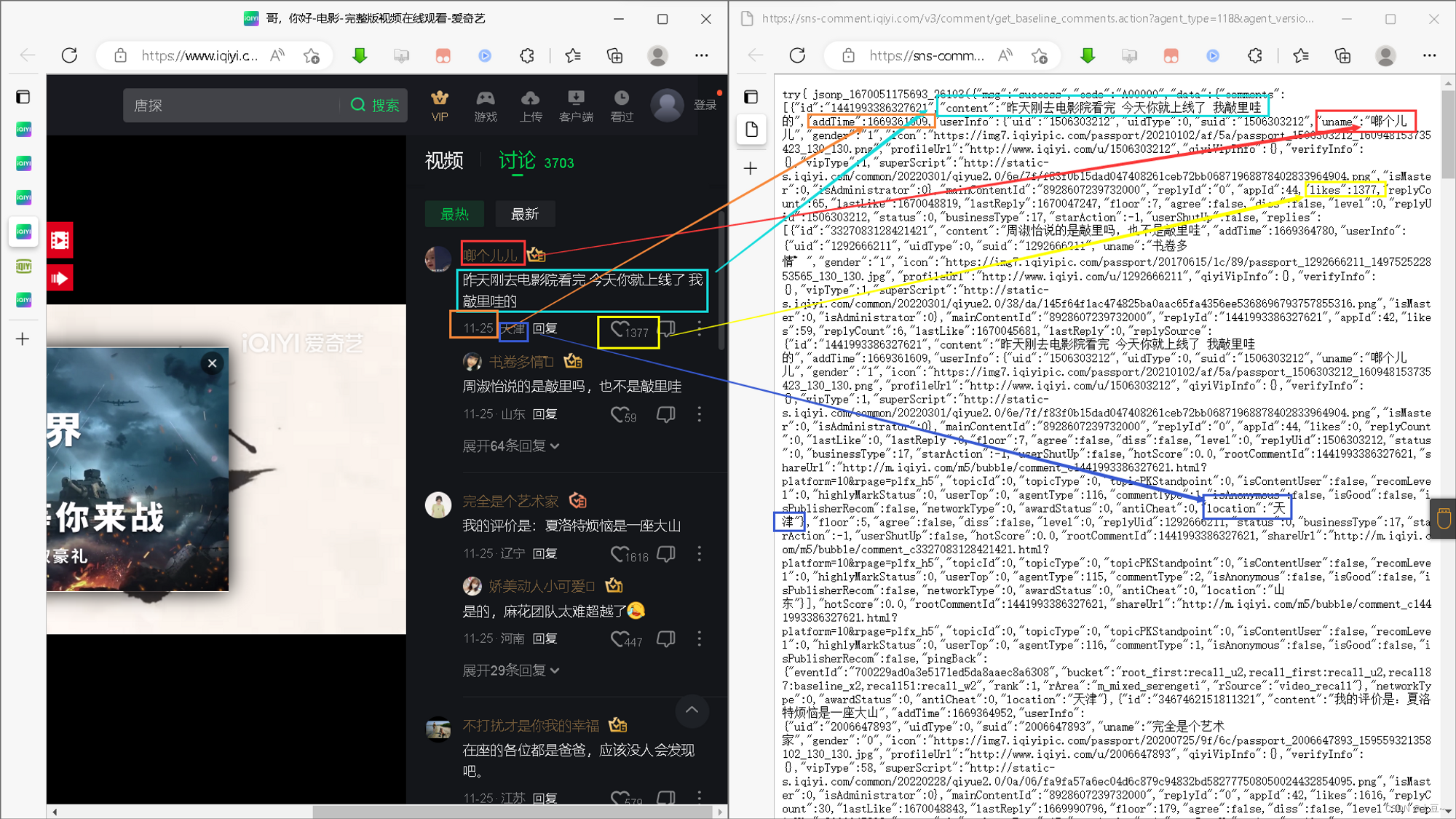
(1)、查看参数
两个链接经过对比发现,channel_id(具体是哪一个视频具有不相同性已查找不到)、callback和content_id是不同的参数,这里我先将最后一个callback参数移除发现也可以访问。
平凡英雄
https://sns-comment.iqiyi.com/v3/comment/get_baseline_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=3865336409304800&last_id=&need_vote=1&page_size=10&qyid=ae3660a6667720a508f88610df39e64b&sort=HOT&tail_num=1&callback=jsonp_1670052106799_2482
哥,你好
https://sns-comment.iqiyi.com/v3/comment/get_baseline_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&channel_id=1&content_id=8928607239732000&last_id=&need_vote=1&page_size=10&qyid=ae3660a6667720a508f88610df39e64b&sort=HOT&tail_num=1&callback=jsonp_1670050754038_83253
(2)、查找参数
查看完参数的不同后,接着就需要查找到评论API所需的对应电影参数。
此时想到前面获取影片内容的API中存在参数,那么此时跳回到这里,查看是否包含,如果包含,那就可以将其都利用API的方式实现。
进入API数据页面,查找content_id和channel_id内容
发现存有大量相同数据。
此时可以实现提取影片API数据,从而获得评论API。
但影片API如何查找?
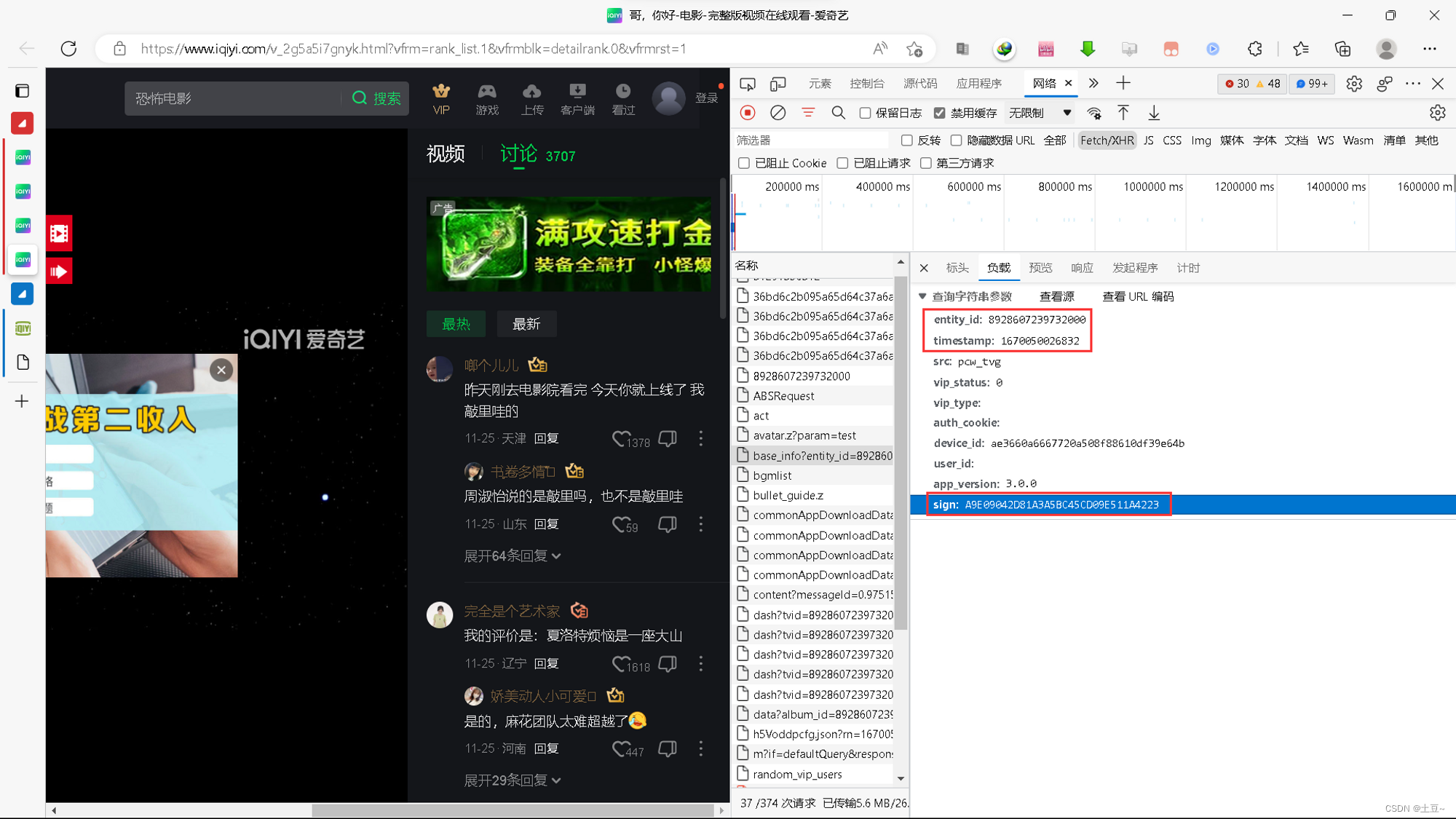
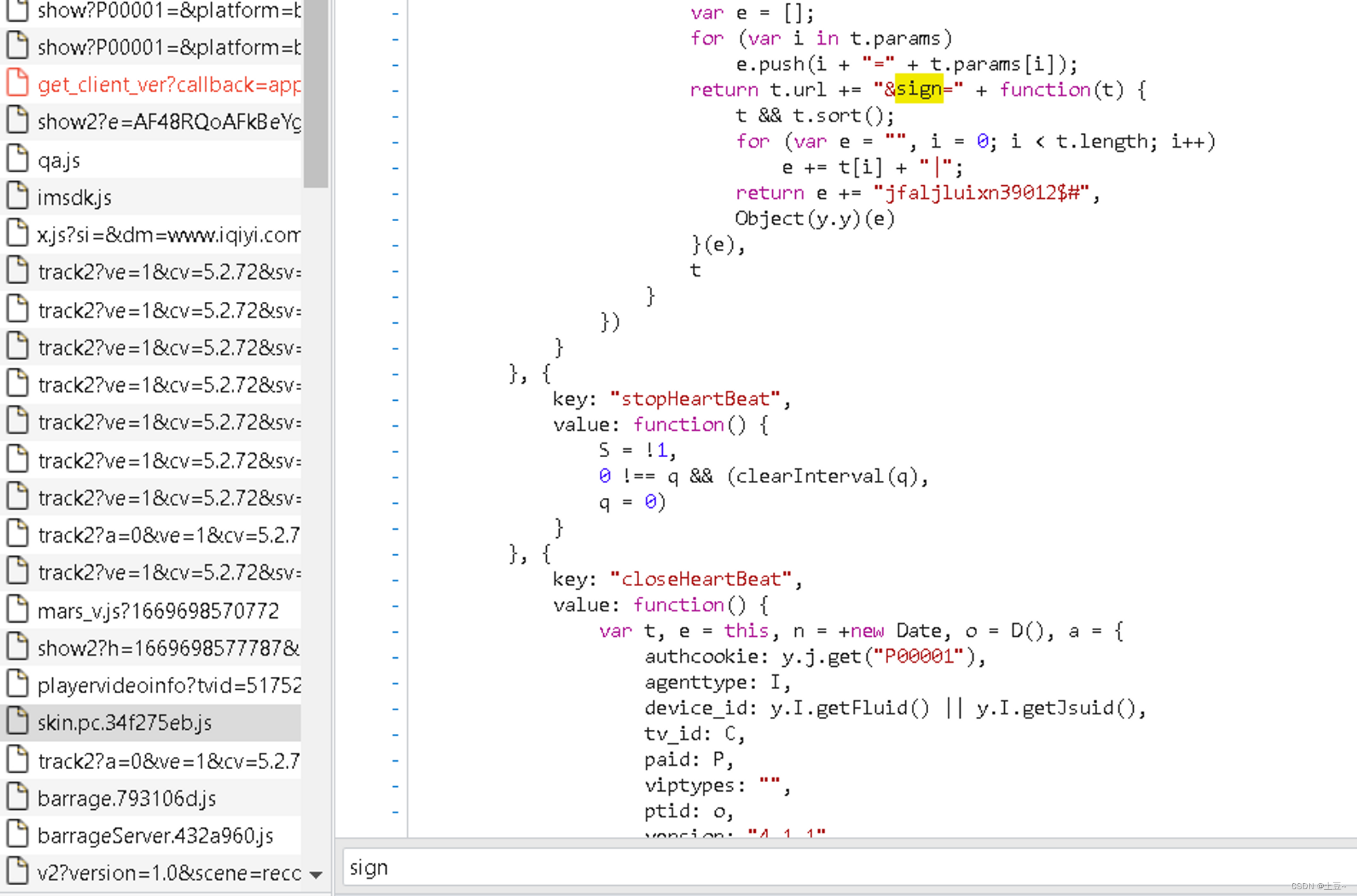
经过多个影片比对,发现三个决定性参数:
- entity_id —— 影片标识符
- timestamp —— 时间戳
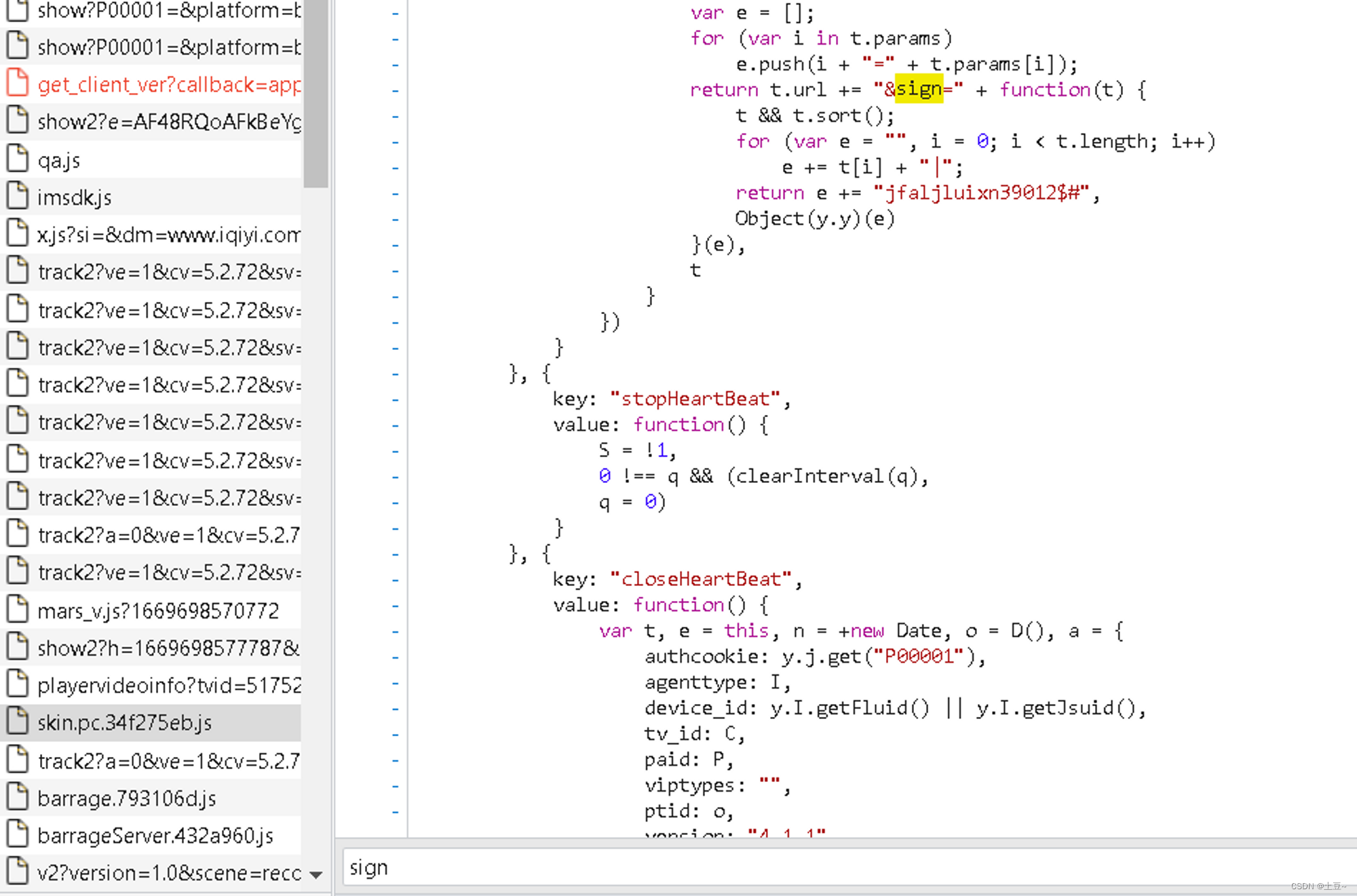
- sign —— 签名
原先想采用图灵图书系列作者所写:自动获取AJAX方法获取到每个影片的API,但发现无法获取到,那没办法了,只好手动将这三个决定性参数存放起来调用(原始方法)。
-
content_id
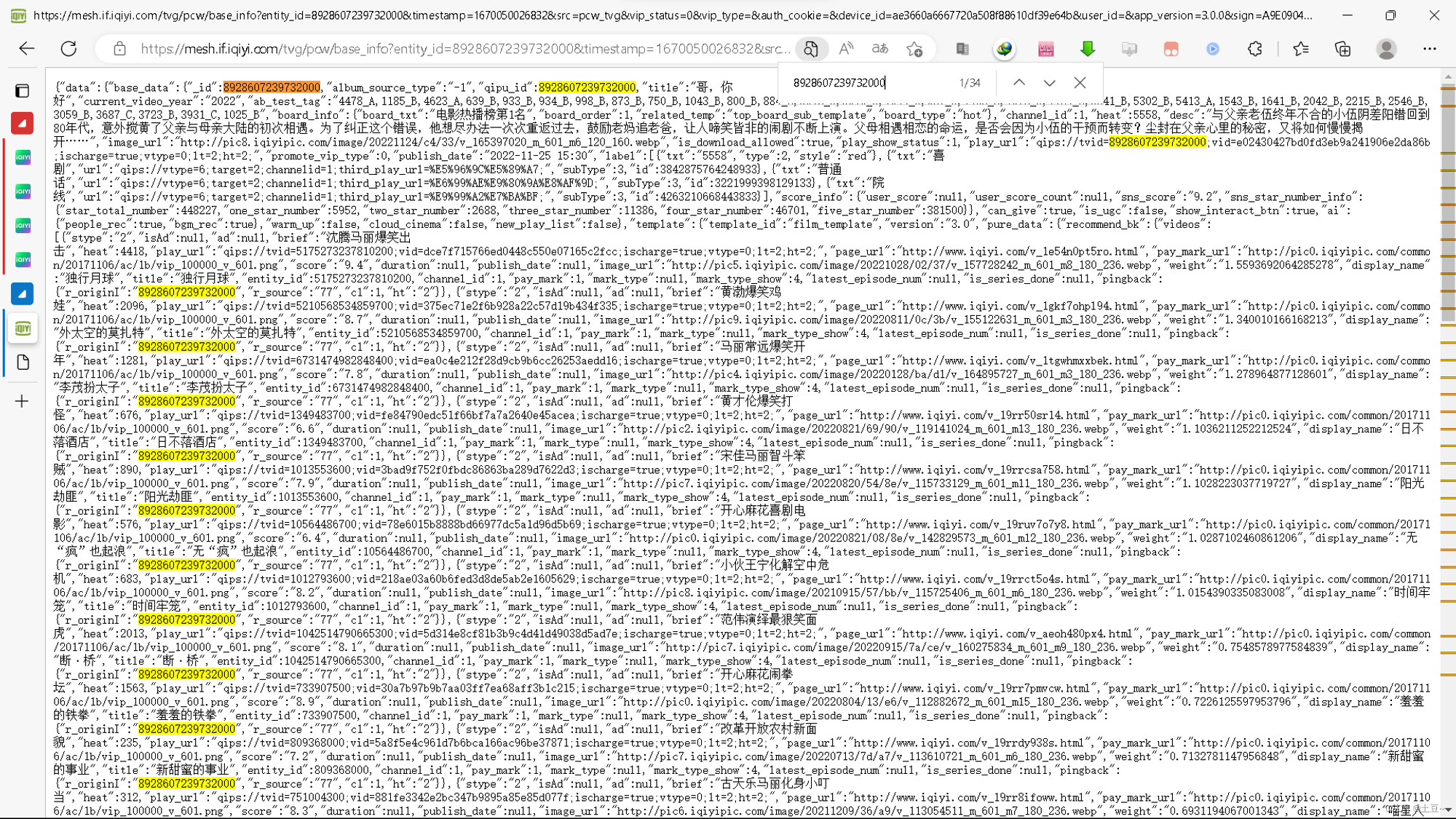
-
channel_id
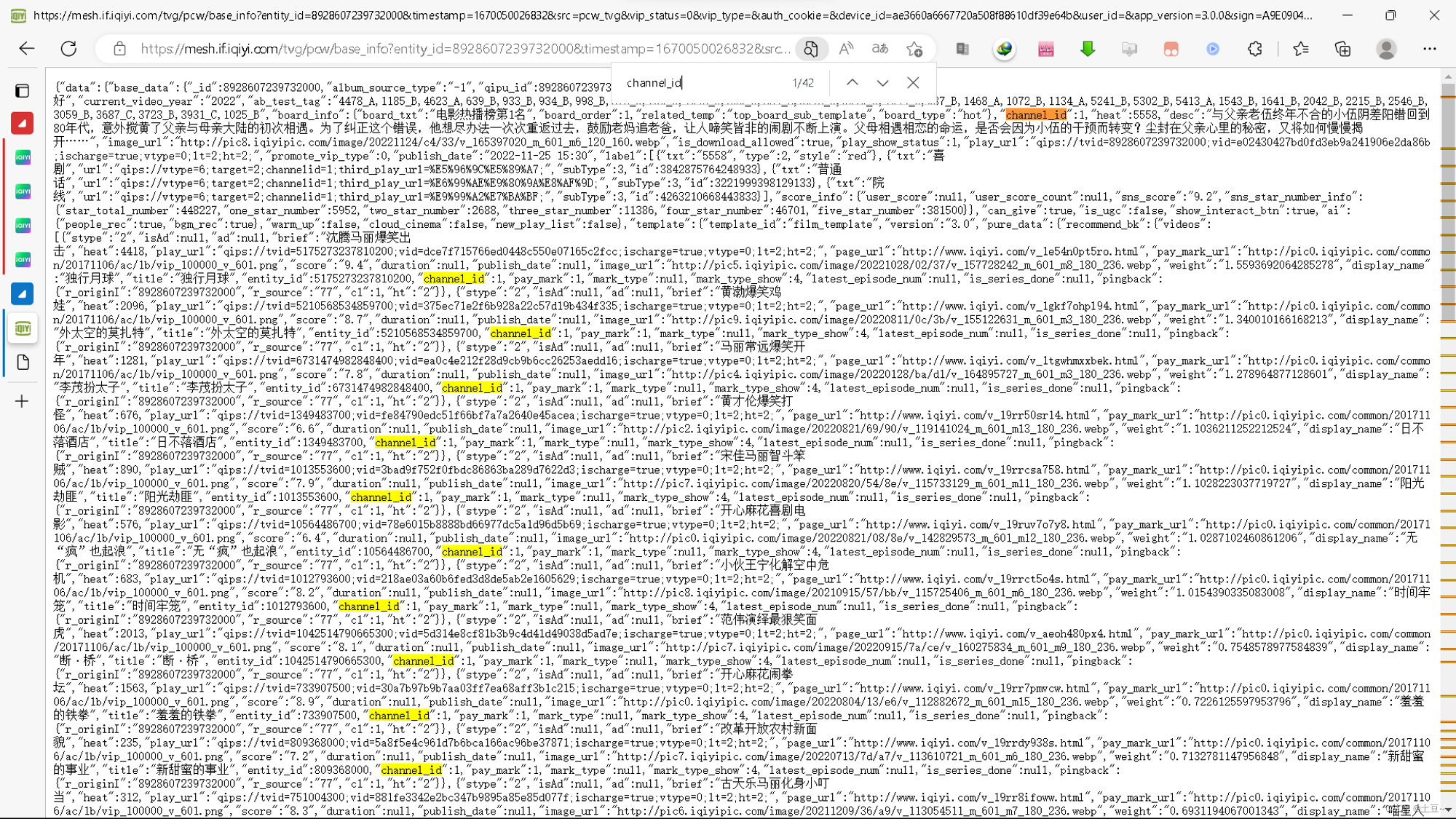
《哥,你好》影片API
https://mesh.if.iqiyi.com/tvg/pcw/base_info?entity_id=8928607239732000×tamp=1670050026832&src=pcw_tvg&vip_status=0&vip_type=&auth_cookie=&device_id=ae3660a6667720a508f88610df39e64b&user_id=&app_version=3.0.0&sign=A9E09042D81A3A5BC45CD09E511A4223
四、数据采集实现过程
1、实现思路
主方法调用函数实现所有功能,影片信息获取、评论信息获取以及其他方法的调用。故以上方式我分为5个py文件实现。
- main —— 主文件
- homePage —— 风云榜封面信息获取
- urlSource —— 视频链接API资源
- commentAPI —— 评论API调用
- item —— 方法调用
2、实现步骤
(1)、将影片API存储在JSON文件中
(2)、读取影片API
(3)、获取API数据
(4)、API数据转化为字典格式读取
(5)、将评论API所需两个必要参数传入
(6)、调用网页请求方法
(7)、调用API数据转化方法
(8)、循环获取影片中的十条评论
(9)、数据存储
五、采集数据结果说明
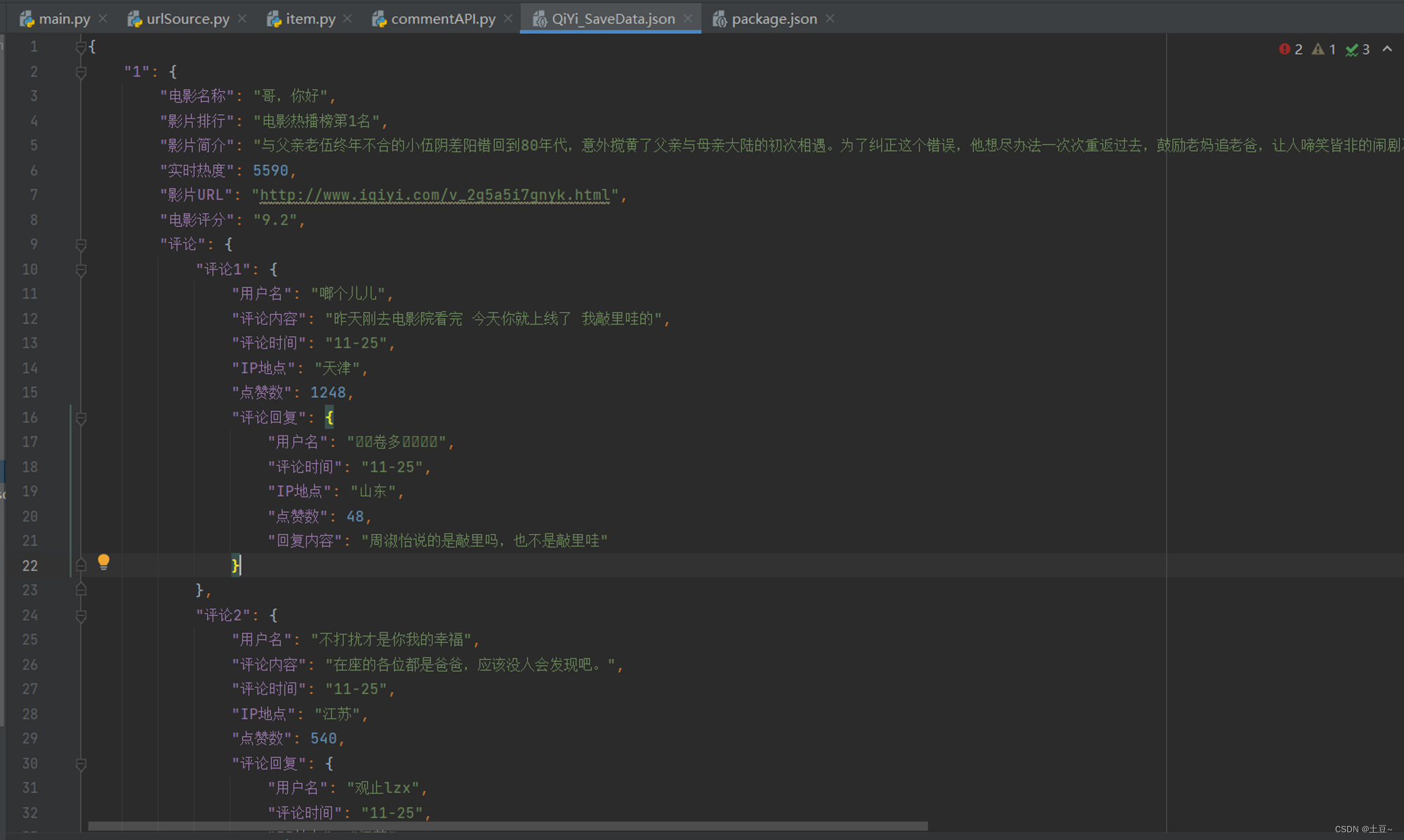
数据存储为JSON格式。
将每一部影片信息存储在对应序列下,紧接将对应影片的评论信息存储在该影片下。
即可保证数据可读性,也方便程序读取数据,进行数据分析。
已将所要的采集目标全部爬取出。
六、任务总结与个人心得
前后尝试过selenium、Scrapy和Pyspider但发现网页的JavaScript渲染技术实在太强大,接着通过反向JS技术实现影片API接口参数的实现,最终无法将其运行在Python中,最终放弃选择自行存储参数数据。
而在API参数分析过程中,时间戳的转化仅能精确到毫秒,而爱奇艺自动生成的则到了微秒。
有关爬虫,最重要的是相关性,让我将两个API联系在一起使用,就是因为在这两者之间的不同参数找相同,从而实现双通。

















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









