






import matplotlib.pyplot as plt
from sklearn.cluster import KMeans #聚类库
from sklearn.datasets._samples_generator import make_blobs #聚类数据生成器
from sklearn import metrics #聚类计算精度库
#n_samples是待生成的样本的总数。
#n_features是每个样本的特征数。
#centers表示类别数。
#cluster_std表示每个类别的方差
x, y = make_blobs(n_samples=500, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.3, 0.1, 0.2])
Mc = list()
for i in range(2,11):
y_predict = KMeans(n_clusters=i).fit_predict(x)
CH = metrics.calinski_harabasz_score(x, y_predict)
Mc.append(CH)
print(Mc)
k = list(range(2,11))
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('不同的K值')
plt.ylabel('Calinski-Harabasz值')
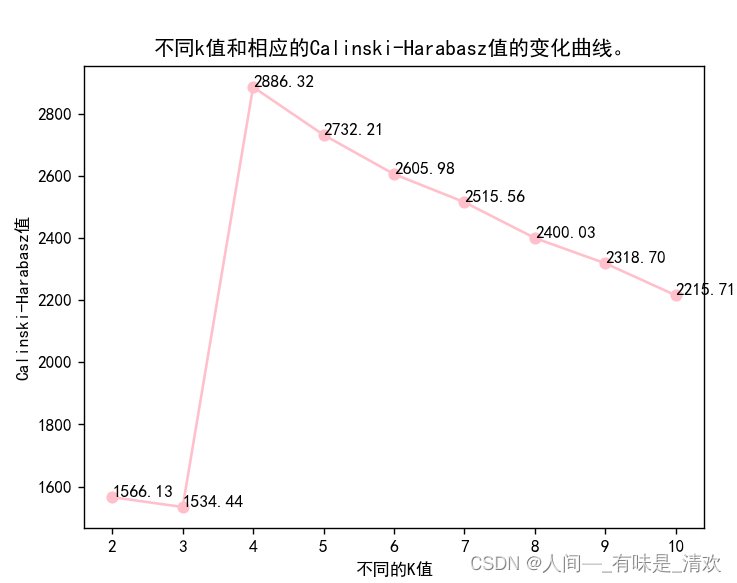
plt.title('不同k值和相应的Calinski-Harabasz值的变化曲线。')
plt.plot(k,Mc,marker='o',linestyle='-',c='pink')
for j in range(len(k)):
plt.text(k[j], Mc[j],format(Mc[j], '.2f'))
plt.show()
#"=========================================================================================="
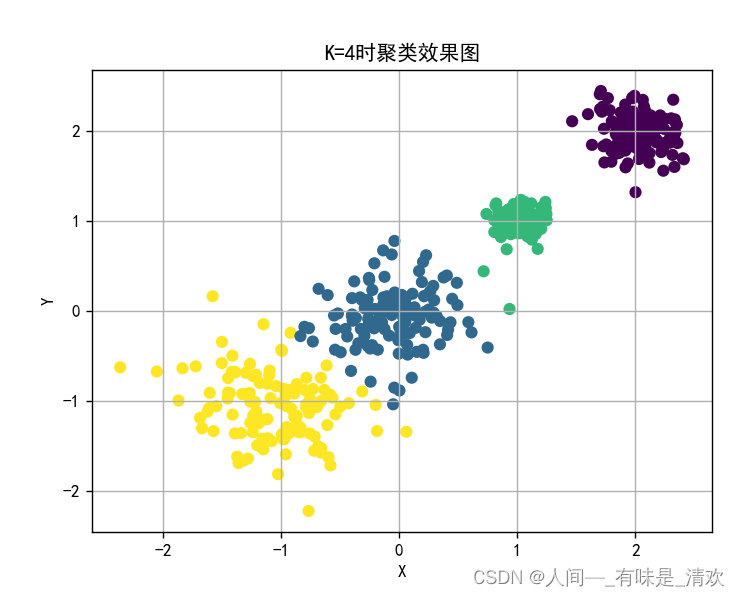
#画出K=4时聚类效果图。
y_predict = KMeans(n_clusters=4).fit_predict(x)
CH = metrics.calinski_harabasz_score(x,y_predict)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('X')
plt.ylabel('Y')
plt.title('K=4时聚类效果图')
plt.scatter(x[:,0],x[:,1],c=y_predict)
plt.grid(True)
plt.show()K-Means聚类——机器学习
最新推荐文章于 2024-07-10 09:15:55 发布
















 6985
6985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









