






Multiple perceptions(different activations)
(datasets:Fashion-MNIST数据集2017)
1. 什么是激活函数?
在接触到深度学习(Deep Learning)后,特别是神经网络中,我们会发现在每一层的神经网络输出后都会使用一个函数(比如sigmoid,tanh,Relu等等)对结果进行运算,这个函数就是激活函数(Activation Function)。那么为什么需要添加激活函数呢?如果不添加又会产生什么问题呢?
首先,我们知道神经网络模拟了人类神经元的工作机理,激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。类似于人类大脑中基于神经元的模型,激活函数最终决定了是否传递信号以及要发射给下一个神经元的内容。在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。
激活函数可以分为线性激活函数(线性方程控制输入到输出的映射,如f(x)=x等)以及非线性激活函数(非线性方程控制输入到输出的映射,比如Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等)
这里来解释下为什么要使用激活函数?
因为神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,所以如果没有激活函数,那么无论你构造的神经网络多么复杂,有多少层,最后的输出都是输入的线性组合,纯粹的线性组合并不能够解决更为复杂的问题。而引入激活函数之后,我们会发现常见的激活函数都是非线性的,因此也会给神经元引入非线性元素,使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中。
在神经网络中,神经元的工作原理可以用下图进行表示:
上述过程的数学可视化过程如下图所示:
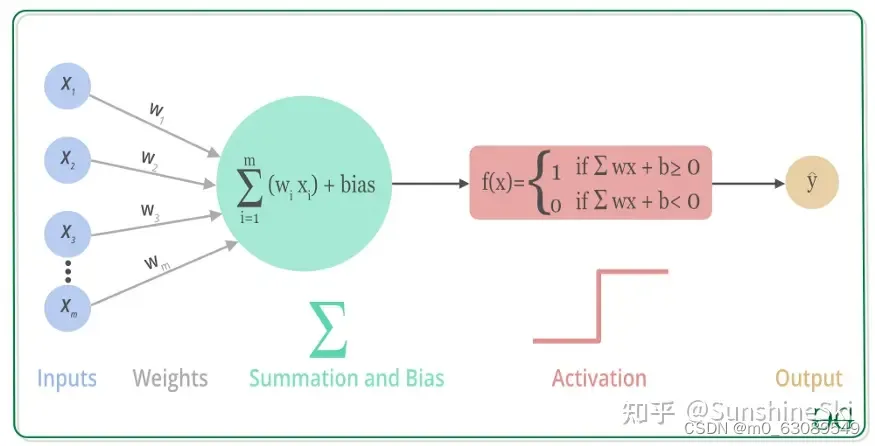
一般来说,在神经元中,激活函数是很重要的一部分,为了增强网络的表示能力和学习能力,神经网络的激活函数都是非线性的,通常具有以下几点性质:
- 连续并可导(允许少数点上不可导),可导的激活函数可以直接利用数值优化的方法来学习网络参数;
- 激活函数及其导数要尽可能简单一些,太复杂不利于提高网络计算率;
- 激活函数的导函数值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
2. ReLU激活函数(10轮训练)
ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题,在目前的深度神经网络中被广泛使用。ReLU函数本质上是一个斜坡(ramp)函数,图像如下:
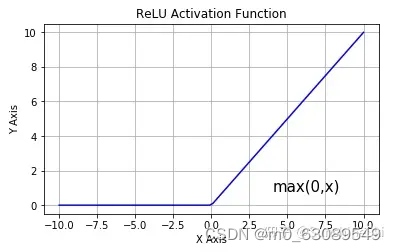
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是这几年的重要成果,有以下几大优点:
- 解决了gradient vanishing问题(在正区间上)。
- Sigmoid和tanh激活函数均需要计算指数,复杂度高,而ReLU只需要一个阈值即可得到激活值。ReLU函数中只存在线性关系,因此它的计算速度比Sigmoid和tanh更快。计算速度非常快,只需要判断输入是否大于0。
- 收敛速度远快于sigmoid和tanh。
- ReLU的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
- ReLU的单侧抑制提供了网络的稀疏表达能力。
同样的,ReLU也有几个需要特别注意的问题:
- ReLU函数的输出为0或正数,不是以0为中心。
- Dead ReLU Problem,指的是某些神经元可能永远都不会被激活,导致相应的参数永远不能被更新。这是由于函数f(x) = max(0,z),导致负梯度在经过ReLU单元时被设置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生影响。当输入为负时,ReLU完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度完全为0,sigmoid函数和tanh函数也具有相同的问题。
- 有两个主要原因可能导致这种情况产生:
- 非常不幸的参数初始化,这种情况比较少见
- learning rate太高导致在训练过程中参数更新太大,会导致超过一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或者使用adagrad等自动调节learning rate的算法。
尽管存在上述的问题,ReLU目前仍然是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
下面为10轮训练后绘制的示意图,展示了训练的损失函数,训练集上的正确率和测试集上的正确率随训练轮次的变化。
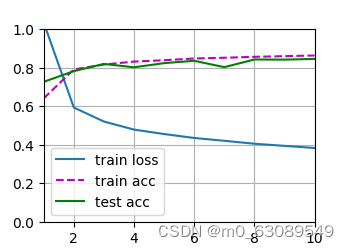
可以看到损失函数下降较快,测试集上准确率不稳定,但是大致都位于0.8以上。

展示的测试集上15个预测错了1个(sneaker和sandal较难区分)
3. Tanh激活函数(10轮训练)
Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。
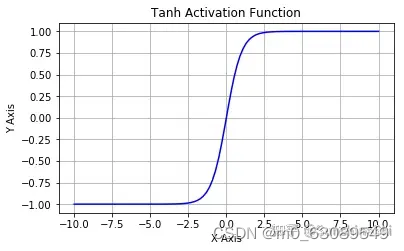
你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值:
- 当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
- 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
tanh存在的不足:
- 与sigmoid类似,Tanh 函数也会有梯度消失的问题,因此在饱和时(x很大或很小时)也会「杀死」梯度。
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
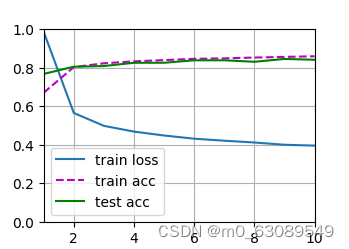
下面为10轮训练后绘制的示意图,展示了训练的损失函数,训练集上的正确率和测试集上的正确率随训练轮次的变化。
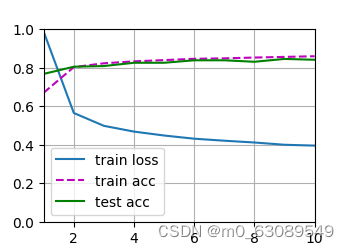
可以看到损失函数下降较快,但是到0.4就稳定,不再有明显下降,测试集上准确率稳定,都位于0.8以上。

展示的测试集上15个预测错了1个(sneaker和sandal较难区分)
4. Sigmoid激活函数(10轮训练)
Sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。sigmoid是一个十分常见的激活函数,激活函数如下图所示:

在什么情况下适合使用 Sigmoid 激活函数呢?
- Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到1,因此它对每个神经元的输出进行了归一化;
- 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
- 梯度平滑,避免「跳跃」的输出值;
- 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
- 明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数存在的不足:
- 梯度消失:注意:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,也就是说,Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元。因此,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失。因此,想象一下,如果一个大型神经网络包含 Sigmoid 神经元,而其中很多个都处于饱和状态,那么该网络无法执行反向传播。
- 不以零为中心:Sigmoid 输出不以零为中心的,,输出恒大于0,非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
- 计算成本高昂:exp() 函数与其他非线性激活函数相比,计算成本高昂,计算机运行起来速度较慢。
下面为10轮训练后绘制的示意图,展示了训练的损失函数,训练集上的正确率和测试集上的正确率随训练轮次的变化。
可以看到损失函数下降较慢,测试集上准确率随着轮次增加趋于稳定,但是到了0.8后不再有明显上升。

展示的测试集上15个预测错了1个(sneaker和sandal较难区分)
5. 三种损失函数训练10轮所需时间对比
下图为三种损失函数的10轮训练时长对比:

可以看出使用ReLU激活函数训练10轮所需时间与使用Sigmoid激活函数训练10轮时间相近,使用Tanh激活函数训练10轮所需时间较长。
综合训练时长与测试集上准确度,以及损失函数下降速度,这个在mnist-fashion数据集上完成的多层感知器神经网络的分类以ReLU函数作为损失函数最佳。
6. 源代码
main.py
import torch
from torch import nn
from d2l import torch as d2l
import util
import time
net1 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
net2 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.Tanh(),
nn.Linear(256, 10))
net3 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.Sigmoid(),
nn.Linear(256, 10))
def init_weights(m):
if type(m)==nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net1.apply(init_weights)
net2.apply(init_weights)
net3.apply(init_weights)
batch_size,lr,num_epochs=256,0.1,10
loss=nn.CrossEntropyLoss(reduction='none')
trainer1=torch.optim.SGD(net1.parameters(),lr=lr)
trainer2=torch.optim.SGD(net2.parameters(),lr=lr)
trainer3=torch.optim.SGD(net3.parameters(),lr=lr)
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)
start_time=time.time()
util.train_ch3(net1,train_iter,test_iter,loss,num_epochs,trainer1)
end_time=time.time()
traintime1=end_time-start_time
print("使用ReLU激活函数的训练所需时间为",traintime1,"秒")
util.predict_ch3(net1, test_iter)
util.train_ch3(net2,train_iter,test_iter,loss,num_epochs,trainer2)
end_time=time.time()
traintime2=end_time-start_time
print("使用Tanh激活函数的训练所需时间为",traintime2,"秒")
util.predict_ch3(net2, test_iter)
start_time=time.time()
util.train_ch3(net3,train_iter,test_iter,loss,num_epochs,trainer3)
end_time=time.time()
traintime3=end_time-start_time
print("使用ReLU激活函数的训练所需时间为",traintime1,"秒")
print("使用Tanh激活函数的训练所需时间为",traintime2,"秒")
print("使用Sigmoid激活函数的训练所需时间为",traintime3,"秒")
util.predict_ch3(net3, test_iter)
d2l.plt.show()util.py
import torch.nn
from d2l import torch as d2l
from IPython import display
class Accumulator:
"""
在n个变量上累加
"""
def __init__(self, n):
self.data = [0.0] * n # 创建一个长度为 n 的列表,初始化所有元素为0.0。
def add(self, *args): # 累加
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self): # 重置累加器的状态,将所有元素重置为0.0
self.data = [0.0] * len(self.data)
def __getitem__(self, idx): # 获取所有数据
return self.data[idx]
def accuracy(y_hat, y):
"""
计算正确的数量
:param y_hat:
:param y:
:return:
"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) # 在每行中找到最大值的索引,以确定每个样本的预测类别
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter):
"""
计算指定数据集的精度
:param net:
:param data_iter:
:return:
"""
if isinstance(net, torch.nn.Module):
net.eval() # 通常会关闭一些在训练时启用的行为
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
class Animator:
"""
在动画中绘制数据
"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量的绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend
)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
"""
向图表中添加多个数据点
:param x:
:param y:
:return:
"""
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def train_epoch_ch3(net, train_iter, loss, updater):
"""
训练模型一轮
:param net:是要训练的神经网络模型
:param train_iter:是训练数据的数据迭代器,用于遍历训练数据集
:param loss:是用于计算损失的损失函数
:param updater:是用于更新模型参数的优化器
:return:
"""
if isinstance(net, torch.nn.Module): # 用于检查一个对象是否属于指定的类(或类的子类)或数据类型。
net.train()
# 训练损失总和, 训练准确总和, 样本数
metric = Accumulator(3)
for X, y in train_iter: # 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer): # 用于检查一个对象是否属于指定的类(或类的子类)或数据类型。
# 使用pytorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward() # 方法用于计算损失的平均值
updater.step()
else:
# 使用定制(自定义)的优化器和损失函数
l.sum().backward()
updater(X.shape())
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""
训练模型()
:param net:
:param train_iter:
:param test_iter:
:param loss:
:param num_epochs:
:param updater:
:return:
"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
num=0
for epoch in range(num_epochs):
trans_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, trans_metrics + (test_acc,))
train_loss, train_acc = trans_metrics
print(trans_metrics)
num=num+1
print("本次训练为第%d次训练"%num)
print("训练损失为%f"%train_loss)
print("训练准确度为%f"%train_acc)
def predict_ch3(net, test_iter, n=15):
"""
进行预测
:param net:
:param test_iter:
:param n:
:return:
"""
global X, y
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = ["\n"+true + "\n" + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, 15, titles=titles[0:n]
)















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









