







本文基于下面的文章进行在探索,请最好先阅读下面文章。
超详细VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客
一、模型选择和下载
modelscope download --model Qwen/Qwen3-8B --local_dir /root/lanyun-tmp/modle/Qwen3-8B
modelscope download --model Qwen/Qwen3-4B --local_dir /root/lanyun-tmp/modle/Qwen3-4B
modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir /root/lanyun-tmp/modle/Qwen3-8B-FP8
我的云服务器
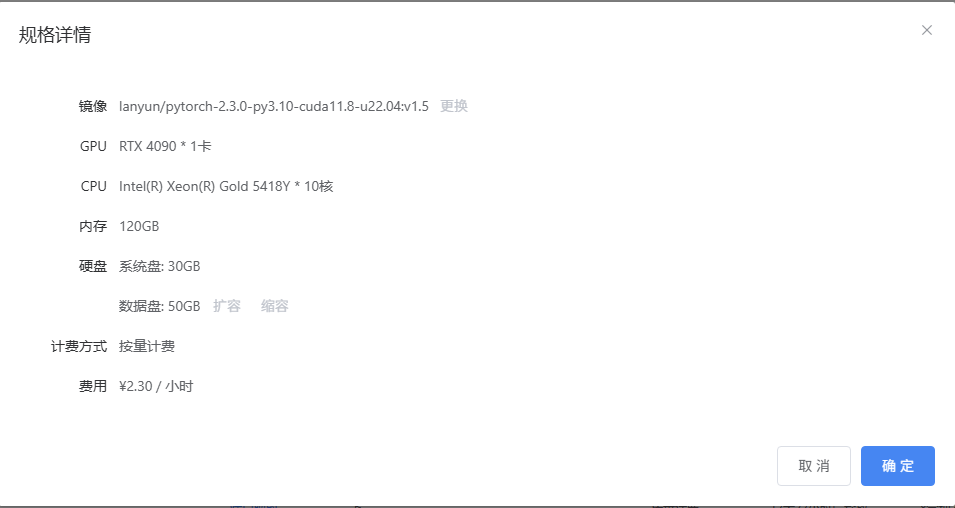
二、模型的说明
2.1 这三个模型有什么区别?
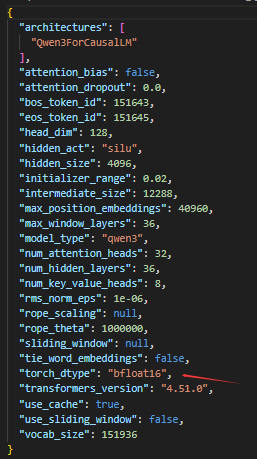
这里就需要知道大模型是什么?大模型本质上是一堆浮点数数字组成的矩阵,可以在模型的配置中看到。比如Qwen3-8B的8B是指,这个矩阵的浮点数字有80亿个,而每个参数(浮点数字)又是bfloat16的。可以简单理解成,模型的能力 = 模型参数量 * 模型的精度,但是模型的精度的影响较小,比如参数圆周率,精度是16位小数还是8位小数,对于我们计算圆的面积来说,误差是差不多的。但是16位的参数圆周率,我们计算的难度就会更大(显存消耗大),但是精度也会更精确。
所以Qwen3-8B等价于Qwen3-8B-FP16,Qwen3-4B等价于Qwen3-4B-FP16,我们把模型的每个参数的精度都从16位变成8位的过程就叫模型量化,我们一方面可以用模型微调框架LLama-factory进行模型量化,另一方面也可以直接在魔塔社区下载别人已经量化压缩好的模型Qwen3-8B-FP8
三、VLLM框架推理三个模型的显存消耗情况
显存怎么计算看一看前面的博客如何计算VLLM本地部署Qwen3-4B的GPU最小配置应该是多少?多人并发访问本地大模型的GPU配置应该怎么分配?-CSDN博客
情况一:Qwen3-8B-FP8:8.8GB+2.8GB = 11.6GB显存
vllm serve /root/lanyun-tmp/modle/Qwen3-8B-FP8 --max-model-len 10000

情况二: Qwen3-8B:15.2GB+1.3GB = 16.5GB显存
vllm serve /root/lanyun-tmp/modle/Qwen3-8B --max-model-len 10000
![]()
情况二: Qwen3-4B:7.55GB+1.3GB = 8.85GB显存
vllm serve /root/lanyun-tmp/modle/Qwen3-4B --max-model-len 10000
![]()
基于上述显存消耗情况,我们可以手动分配显存给到VLLM服务,比如我要部署推理 Qwen3-8B-FP8,我已经知道了模型推理的显存消耗是11.6GB,那我给12GB就够用了,我们服务器是24GB的,所以分配0.55的GPU(13.2GB)就可以。
vllm serve /root/lanyun-tmp/modle/Qwen3-8B-FP8 --max-model-len 10000 --gpu-memory-utilization 0.55
四、小结
基于企业的预算,还有模型的能力。
1.我们可以用16GB显存的显卡来部署推理,Qwen3-8B-FP8和Qwen3-4B模型,如果后续涉及到模型的微调训练,这个16GB就不够用,但是可以单独组几天的显卡来专门微调大模型,如果涉及到多人并发的话导致推理响应太慢,可以添加显卡的方法或者像VLLM框架一样做好访问列队的设计。这个方案性价比最高。
2.如果企业追求回答效果好的话选择Qwen3-8B-FP8好一点,但是后面的模型微调就比Qwen3-4B模型更难微调。
3.后续要考虑到词嵌入模型也要消耗GPU资源的话,最好还是部署一个24GB的显卡(控制利用率在0.9)差不多21.6GB,然后词嵌入的模型还有5GB用。


















 8318
8318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











