






本文为大家剖析一个通过多智能体协作来完成的AI研究助理,可以用来帮助进行各种综合的在线研究任务并输出报告。该应用基于LangGraph以及开源的GPT-Researcher项目而构建,我们将为大家介绍与剖析这个应用,你可以在此基础上做简单改造(如修改分析数据源、提示词等),以适应自身需要。


业务场景

通常,如果需要从头开始一个主题(比如“生成式人工智能中的伦理偏见与公平性")的深入研究,我们最期望的是能够快速的获取多个来源的值得信赖的信息,这可能需要在多个网站之间不断点击与浏览,通过一系列检索、聚合、细化、整理等工作来完成任务。当然,现在你可以借助大模型,但是简单的模型输出或者RAG(检索增强生成)会面临这样的问题:
-
**大模型训练的信息过时,容易产生幻觉
** -
受限于上下文限制,不太适合输出长篇研究报告
-
网络搜索获得的参考资源不足,导致不全面与偏见
-
RAG系统更适合回答问题而不是编写长篇报告
所以期望有一个设计合理的AI智能体,能够自主的完成这样的研究任务:
-
对输入的研究主题进行细分,生成研究提纲与子课题
-
对子课题来获取相关的参考信息(本地或网络)
-
对获取的信息整理、汇总、分析,得出研究结论或报告
-
对报告进行自我反省与审核,并提出问题与指出不足
-
根据审核结果修订研究报告,并能获得人类反馈
-
结合研究的中间成果,输出最终的全面研究报告
架构设计

随着AI Agent理论与框架的演进,**多智能体系统(Multi-Agent System)**以其更灵活的架构,以及更接近人类社会组织与分工形式的设计而获得广泛关注。

多智能体系统相对单智能体展现出了一些独有的特点与优势:
-
通过多个相互独立但协作的智能体来完成复杂任务,每个智能体拥有不同的视角或能力,可以更全面地理解和处理复杂问题
-
任务可以被分解并分配给不同的智能体,并行处理后再综合结果。能够加速任务完成,并提高系统的整体效率和准确性
-
可以根据任务需求动态地调整各智能体的角色与职责,更好地适应变化的环境,通过调整智能体之间的互动模式,应对不同的挑战
**多智能体更适用于需要多角度、多角色参与,需要分工协作、任务分解的场景与复杂任务。**这个项目中设计的多智能体研究助理架构如下:
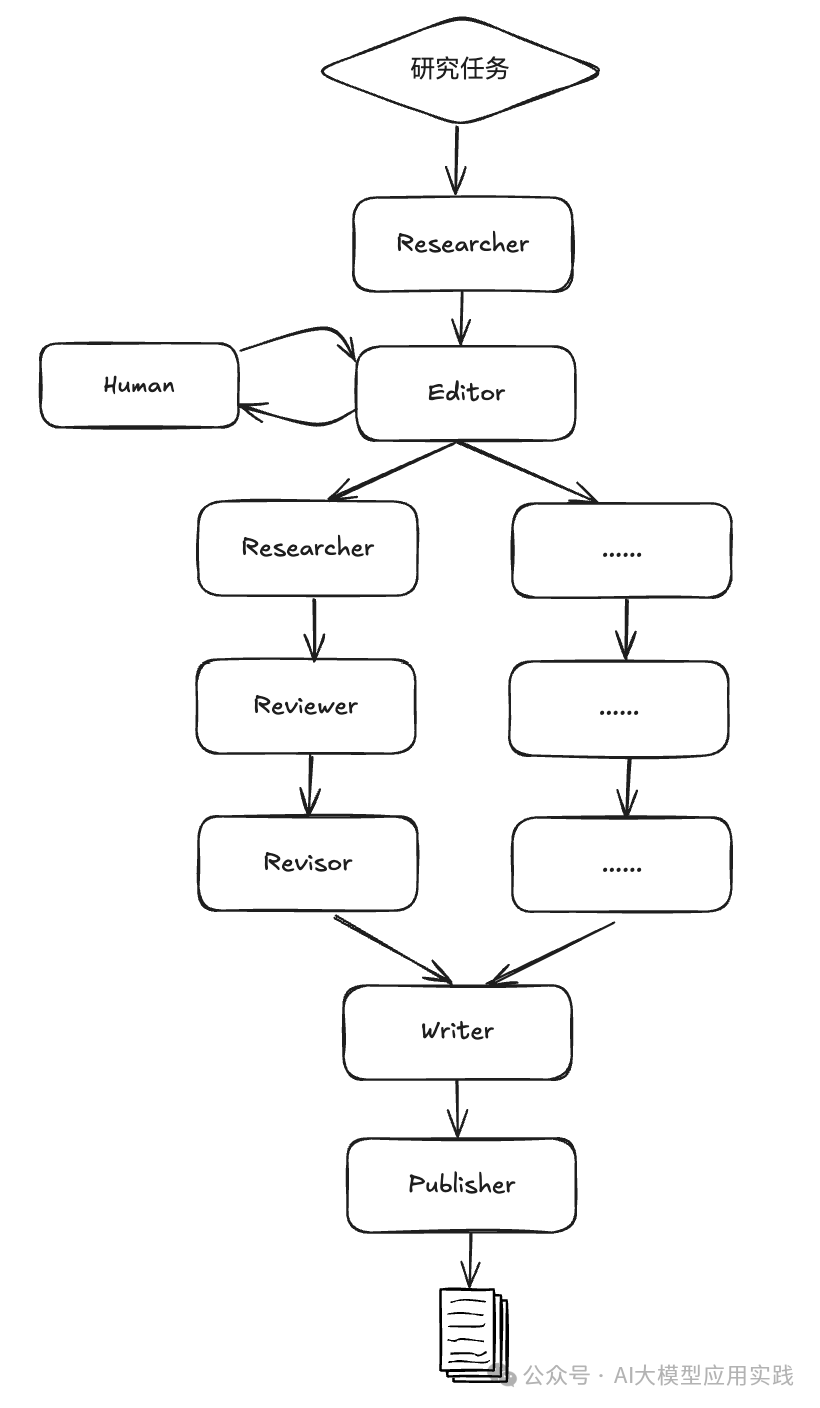
图中展示出涉及的角色(智能体)包括:
-
Researcher:研究员。针对研究主题采集网络资源,做自主研究
-
Editor:编辑。负责初期规划研究大纲和整体结构
-
Reviewer:审阅。根据设定的标准对研究结果进行检查验证
-
Revisor:修订。根据审阅结果对研究结果进行修订
-
Writer:撰写。根据研究输出撰写最终报告内容
-
Publisher:发布。负责用不同的格式发布最终研究报告
除了智能体以外,也支持人类(Human)角色参与到流程,并在适当的时机给出反馈。这在多智能体系统中也很常见,通常用于审核或给出额外任务指令。
这里的基本工作流程为:
-
根据给定的研究主题,参考互联网资源进行初步研究
-
根据初步研究结果制定报告提纲(子课题)
-
对每个子课题做深入研究、审阅与修改,直到满意为止
-
汇总子课题的研究结果撰写最终报告,并输出多格式文档er q
基于LangGraph的实现

LangGraph是大模型应用开发框架LangChain的扩展包。LangGraph通过把一个Single-Agent或Multi-Agent系统的工作流用Graph(图结构)来设计与表示,从而能够支持最复杂的任务节点与关系,以支持构建更强大、能支持循环流的Agent应用。
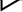
【Graph设计】
这里对上面的AI研究助理设计Graph图如下:
【State设计】
LangGraph中需要定义的State对象是用来保存在各个节点之间传递的必需信息,这样每个节点可以访问这个统一的数据对象实现数据共享。这个项目中的State的结构设计如下:
class ResearchState(TypedDict):
#研究任务
task: dict
initial_research: str
sections: List[str]
research_data: List[dict]
human_feedback: str #人类反馈
#输出的报告结构
title: str
headers: dict
date: str
table_of_contents: str
introduction: str
conclusion: str
sources: List[str]
report: str
State中的信息分成研究任务相关(比如任务内容、子课题、参考数据、人类反馈等)与输出报告相关(标题、简介、内容等)两个部分。
【基于LangGraph的主流程】
现在,假设已经准备好所有的Agent及其行为(比如研究、审核等),就可以根据上面的Graph图开发Workflow。步骤是:
-
**创建多个agent
** -
创建主workflow
-
增加workflow中的节点(agent及其动作)
-
增加workflow中的边(节点之间的关系)
......初始化研究团队(LangGraph)......
def init_research_team(self):
# 声明多个独立Agent
writer_agent = WriterAgent(self.websocket, self.stream_output, self.headers)
editor_agent = EditorAgent(self.websocket, self.stream_output, self.headers)
research_agent = ResearchAgent(self.websocket, self.stream_output, self.tone, self.headers)
publisher_agent = PublisherAgent(self.output_dir, self.websocket, self.stream_output, self.headers)
human_agent = HumanAgent(self.websocket, self.stream_output, self.headers)
# 创建一个LangGraph的workflow
workflow = StateGraph(ResearchState)
# 增加Graph中的节点(参考Graph设计图)
workflow.add_node("browser", research_agent.run_initial_research)
workflow.add_node("planner", editor_agent.plan_research)
workflow.add_node("researcher", editor_agent.run_parallel_research)
workflow.add_node("writer", writer_agent.run)
workflow.add_node("publisher", publisher_agent.run)
workflow.add_node("human", human_agent.review_plan)
# 增加Graph中的边
workflow.add_edge('browser', 'planner')
workflow.add_edge('planner', 'human')
workflow.add_edge('researcher', 'writer')
workflow.add_edge('writer', 'publisher')
# 设定开始和结束
workflow.set_entry_point("browser")
workflow.add_edge('publisher', END)
# 条件边:基于人类反馈决定是否要重新设计研究提纲
workflow.add_conditional_edges('human',
(lambda review: "accept" if review['human_feedback'] is None else "revise"),
{"accept": "researcher", "revise": "planner"})
return workflow
注意到这里有个条件边(conditional_edge),用来根据人类的不同反馈决定下一步的动作(继续还是重新做初步研究)。
【并行子流程:子课题研究】
在规划完任务研究提纲后,需要对提纲中的每个子课题进行深入研究。这可以通过并行的方式启动多个子研究任务来完成,以提升速度与效率。为了能够实现并行,需要设计并开发一个独立的子Workflow,且其运行时不会相互影响,也不会影响到主流程。这个子Workflow创建如下:
...并行运行的子workflow... ``async def run_parallel_research(self, research_state: dict): # 创建agent research_agent = ResearchAgent(self.websocket, self.stream_output, self.headers) reviewer_agent = ReviewerAgent(self.websocket, self.stream_output, self.headers) reviser_agent = ReviserAgent(self.websocket, self.stream_output, self.headers) # 创建子workflow workflow = StateGraph(DraftState) # 增加node workflow.add_node("researcher", research_agent.run_depth_research) workflow.add_node("reviewer", reviewer_agent.run) workflow.add_node("reviser", reviser_agent.run) # 增加边 workflow.set_entry_point("researcher") workflow.add_edge('researcher', 'reviewer') workflow.add_edge('reviser', 'reviewer') #条件边:根据审核结果决定是继续修订还是结束研究 workflow.add_conditional_edges('reviewer', (lambda draft: "accept" if draft['review'] is None else "revise"), {"accept": END, "revise": "reviser"}) chain = workflow.compile() ...
需要注意的是为了让每个子任务运行时具有独立的状态,必须设计一个用于子Workflow的State(即代码中的DraftState)对象,用来保存子任务运行过程中的子课题、草稿内容、审查结果、修订说明等。
【Agent设计】
在这个多智能体系统中,AI的职责被设计与分工到不同的Agent,因此单个Agent的功能其实是比较简单的,而且这里除了browser与researcher这两个Agent(这两个借助了现成的GPT-Researcher库),不需要借助外部的Tools,只需要借助大模型提示来完成即可。以上面的planner这个agent的实现为例,其动作提示词如下(翻译成中文):
...
prompt = [{
"role": "system",
"content": "你是一名研究编辑。你的目标是监督研究项目从开始到完成。你的主要任务是根据初步的研究总结来规划文章的章节布局。\n"
}, {
"role": "user",
"content": f"今天的日期是 {datetime.now().strftime('%d/%m/%Y')}\n."
f"研究总结报告: '{initial_research}'\n"
f"{f'人工反馈: {human_feedback}。你必须基于人工反馈规划章节。' if include_human_feedback else ''}\n"
f"你的任务是根据上述研究总结报告生成研究项目的章节标题大纲。\n"
f"你最多只能生成 {max_sections} 个章节标题。\n"
f"你必须只关注相关的研究主题作为子标题,并且不要包括引言、结论和参考文献。\n"
f"你必须仅返回一个包含以下字段的JSON:'title' (字符串类型的研究标题) 和 "
f"'sections' (最多 {max_sections} 个章节标题),结构如下:"
f"'{{title: string 研究标题, date: 今天的日期, "
f"sections: ['章节标题 1', '章节标题 2', '章节标题 3' ...]}}。\n"
}]
而对于“人类”这个特殊的角色,无需借助大模型,简单的获得人类反馈信息即可,并保存到State对象即可:
async def review_plan(self, research_state: dict):
layout = research_state.get("sections")
user_feedback = None
user_feedback = input(f"Any feedback on this plan? {layout}? If not, please reply with 'no'.\n>> ")
if user_feedback and "no" in user_feedback.lower():
user_feedback = None
return {"human_feedback": user_feedback}
其他的Agent可以参考项目的详细代码,这里不再做一一介绍。
最后,在完成Agent与Workflow的创建后,就可以运行已经创建好的Workflow,输入任务信息即可启动一个自主运行的AI研究助理,等待最终输出即可(中间需要给出人类的确认反馈)。
...
#创建主workflow
research_team = init_research_team()
chain = research_team.compile()
result = await chain.ainvoke({"task": "研究任务"})
以上介绍了一个基于LangGraph与GPT-Researcher项目构建的多智能体AI研究助理,用来根据输入的任务自主的借助互联网进行规划、研究、反思、修订并最终输出研究报告。这个项目很好地演示了多智能体系统的应用场景,以及LangGraph与GPT-Researcher项目的应用。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









