






股票市场预测因高波动性和低信息噪声比而极具挑战性,现有基于机器学习的单一模型难以捕捉不同股票风格的差异。本文提出MIGA框架,通过动态切换不同风格专家生成专业化预测,提升预测准确性。
实验表明,MIGA在CSI300、CSI500和CSI1000等中国股票指数基准上显著优于其他模型,MIGA-Conv在CSI300基准上实现24%超额年回报,超越前沿模型8%。

论文地址:https://arxiv.org/pdf/2410.02241
【 扫描文末二维码加入星球获取论文 】
摘要
股票市场预测因高波动性和低信息噪声比而极具挑战性,现有基于机器学习的单一模型难以捕捉不同股票风格的差异。本文提出MIGA框架,通过动态切换不同风格专家生成专业化预测,提升预测准确性。MIGA采用新型内部组注意力架构,促进同组专家间的信息共享,增强整体性能。MIGA在CSI300、CSI500和CSI1000等中国股票指数基准上显著优于其他模型,MIGA-Conv在CSI300基准上实现24%超额年回报,超越前沿模型8%。进行混合专家在股票市场预测中的综合分析,为未来研究提供有价值的见解。
简介
股票市场因其固有的波动性和噪声特性,使得准确预测股价和做出盈利投资决策极具挑战性。预测难点源于多种因素的相互作用,包括市场参与者行为、宏观经济变量和信息流动。
近年来,机器学习(ML)和深度学习(DL)方法在股票市场预测中表现出色,利用多种股票因素的数据集进行端到端学习。现有的ML和DL方法多基于LSTM和Transformer等网络架构,采用监督学习方式,将历史股票因素视为特征,收益率作为目标。不同风格的股票在特征上存在显著差异,例如大盘股相对稳定。
MIGA是一种新颖的专家混合与组聚合框架,旨在为不同风格的股票生成专业化预测。该框架采用两阶段设计:第一阶段通过专家路由器将原始股票数据编码为向量表示,并生成专家分配权重;第二阶段引入专家聚合结构,利用内部组注意机制促进专家间的知识共享与协作。MIGA能够动态切换专门的专家,克服传统端到端模型在捕捉股票特征差异方面的不足。采用三种特征编码器(卷积、递归、注意力)和线性层作为专家,验证MIGA模型,命名为MIGA-Conv、MIGA-Rec和MIGA-Attn。
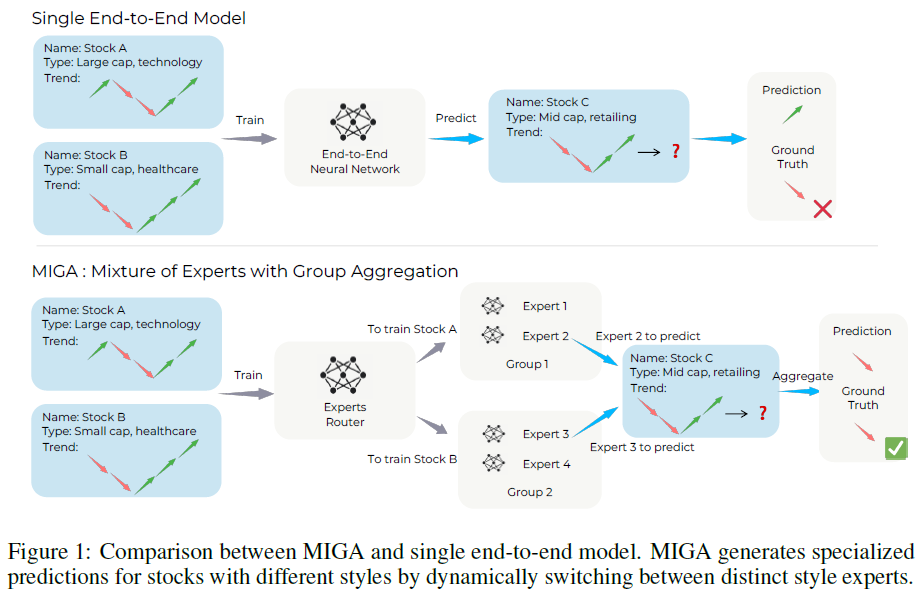
在CSI300、CSI500和CSI1000三个中国股票指数上评估MIGA模型的表现,使用长多头和长短头寸组合。MIGA模型表现优越,尤其是MIGA-Conv在CSI300基准上实现24%的超额年回报。提供对股票预测中专家混合模型的深入分析,为未来研究提供见解。
相关工作
股市预测。股票市场预测的最新进展得益于端到端方法,如时间卷积网络(TCN)、LSTM和Transformer,这些模型在该领域的有效性已被验证,促使提出MIGA模型进行研究。
混合专家。混合专家(MoE)方法自引入以来被广泛应用于计算机视觉和自然语言处理等领域,但在量化投资和随机金融市场的MoE框架开发上存在明显空白,激励进一步探索并提出MIGA。
MIGA:具有组聚合的MOE
Mixture of Experts (MoE)架构包含路由器和专家,路由器为每个数据点分配权重,专家生成预测,最终输出为专家预测的加权聚合。本文将股市预测视为监督学习任务,通过每日股票价格生成交易策略。考虑一个大小为N的股票池,每只股票i在交易日t有对应的平均价格p_it和特征向量x_it ∈ RN ×T × D,D为特征数量,T为股票的天数范围。特征向量x_it的训练标签为股票的未来收益率,计算方法将用于模型学习的监督。
问题建模
我们通过生成基于每日横截面股票价格的交易策略,将股市预测制定为监督学习任务。考虑一个规模为N的股票池,其中每只股票i在交易日t都有一个相应的平均价格坑和一个特征向量x^i_t,其中D是特征的数量,t是股票的天数范围。对于每个特征向量xit,我们使用股票的未来收益率作为训练标签来监督模型学习:
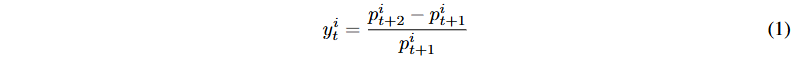
跨组专家路由
路由
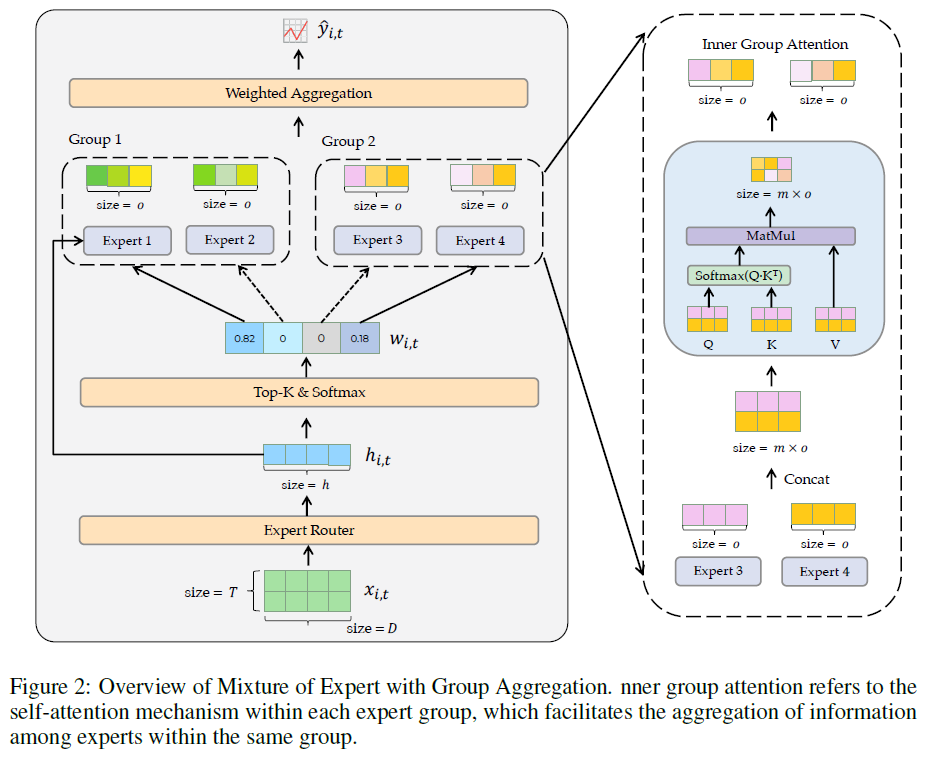
处理流程开始于使用可训练的路由器对股票集进行交叉编码,以捕捉股票间复杂关系并生成路由权重。采用top-k选择策略识别最重要的k个专家,并对选定子集进行softmax归一化,得到最终的归一化权重,反映每个专家的相对重要性。
![]()
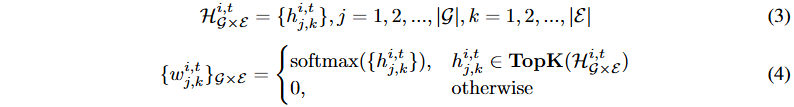
专家
MIGA模型中,所有专家使用相同的隐藏表示作为输入,生成各自的预测。为防止模型复杂性,所有专家设为线性层。通过内部组注意力机制聚合专家预测,促进专家间的信息共享,丰富每个专家的输出表示。
![]()
组聚合
通过连接所有专家的输出,形成统一的输入表示。生成查询Q、键K和值V矩阵,以实现组内注意力机制。专家输出通过注意力机制交互,得到混合输出O¯,聚合所有专家的知识。计算加权复合预测,以推导MIGA对股票未来盈利的预测。
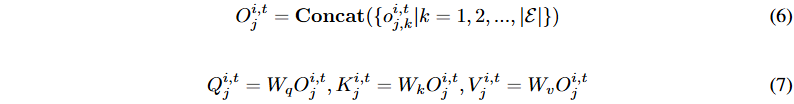
![]()
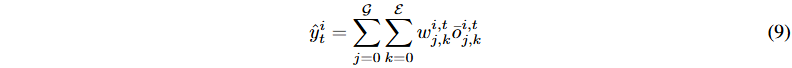
训练
专家损失。训练过程中采用信息系数(IC)作为损失函数,而非传统的均方误差(MSE),以增强标签与预测之间的相关性。实际股票横截面收益Y label和预测收益Y pred分别表示为{y t i}和{ ˆ y t}。计算L Expert的公式涉及复杂的三角函数和参数,旨在优化模型性能。
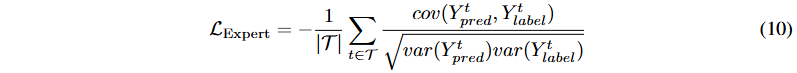
负载平衡考虑。自动学习的路由策略易导致负载不均衡,可能引发路由崩溃现象。现有的MoE架构通过辅助损失确保专家间的负载均衡,但在股票市场预测中不适用。为减少不平衡,优化路由输出与均值之间的距离。最终损失函数结合了预测收益与实际收益的相关性优化和路由损失的减小。
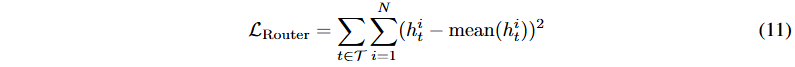
![]()
实验
实现细节
使用PyTorch实现MoE架构,训练在NVIDIA A100-80GB GPU上进行。最大训练轮数设为60,采用早停策略以防止过拟合。初始学习率为5e-4,LMIGA中的超参数α设为2e-3,β设为1。历史股票序列长度T设为5(一周交易日)。
实验设置
数据集包含626个每日特征,涵盖中国股市,时间范围为2014年1月1日至2024年7月25日,分为训练集、验证集和测试集。
MIGA模型的基线包括MIGA-Conv(TCN卷积)、MIGA-Rec(LSTM编码器)和MIGA-Attn(Transformer编码器),与TCN、LSTM、Transformer及三种最新SoTA模型进行比较。
评估MIGA模型的基准为CSI300、CSI500和CSI1000指数,分别代表大盘股、中盘股和小盘股,全面反映中国A股市场表现。
评估指标
评估模型性能使用排名指标和投资组合指标,包括信息系数(IC)、排名信息系数(RankIC)、信息比率IC(ICIR)和排名信息比率(RankICIR)。IC和RankIC为日频率下的皮尔逊和斯皮尔曼相关系数,ICIR和RankICIR为其标准化版本。
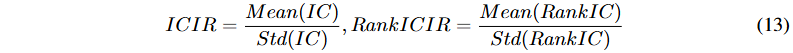
采用长短仓策略,选择每日预测收益率前5%股票进行多头,后5%进行空头,形成长短投资组合。报告超额年化收益(AR)和信息比率(IR),AR衡量年预期超额收益,IR评估风险调整后的表现。
结果
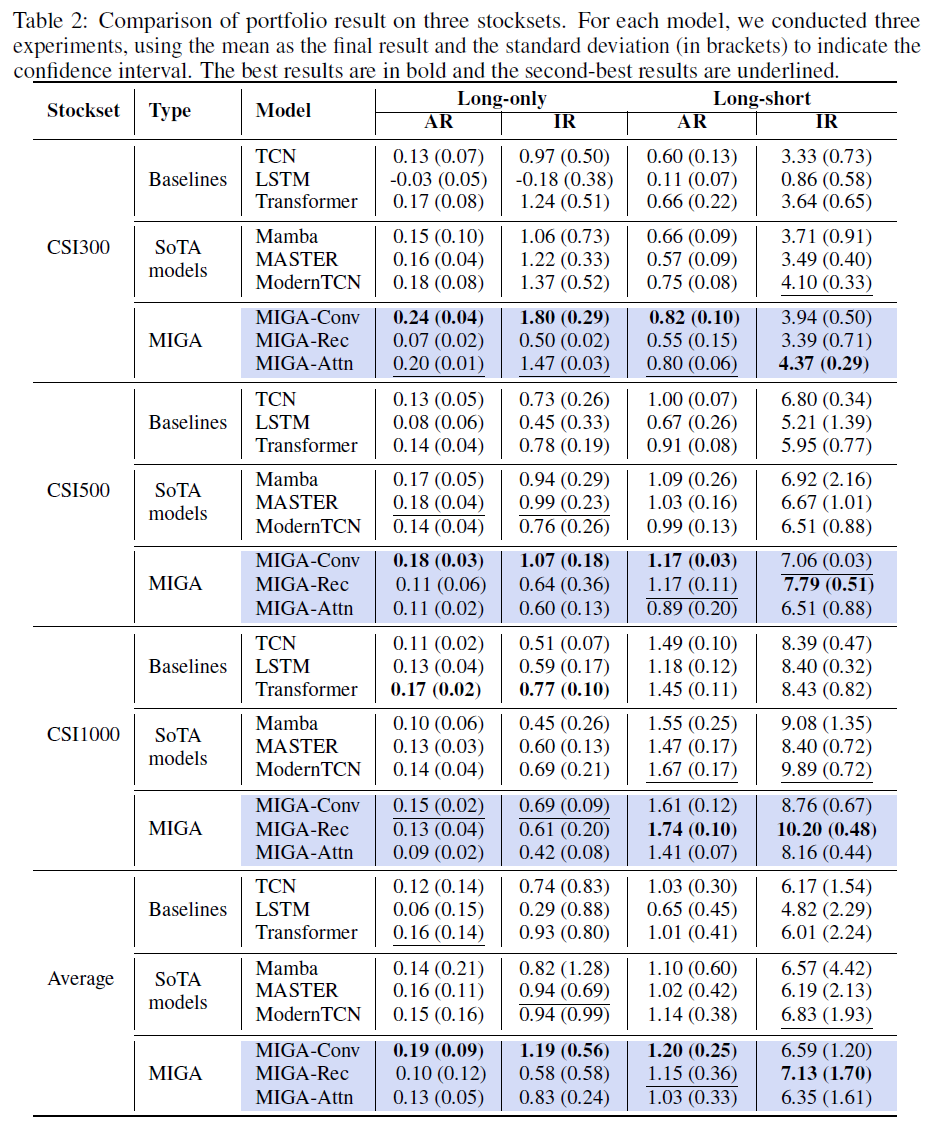
MIGA在CSI300、CSI500和CSI1000基准上超越了之前的SoTA模型,15/16排名指标和14/16投资组合指标表现最佳。
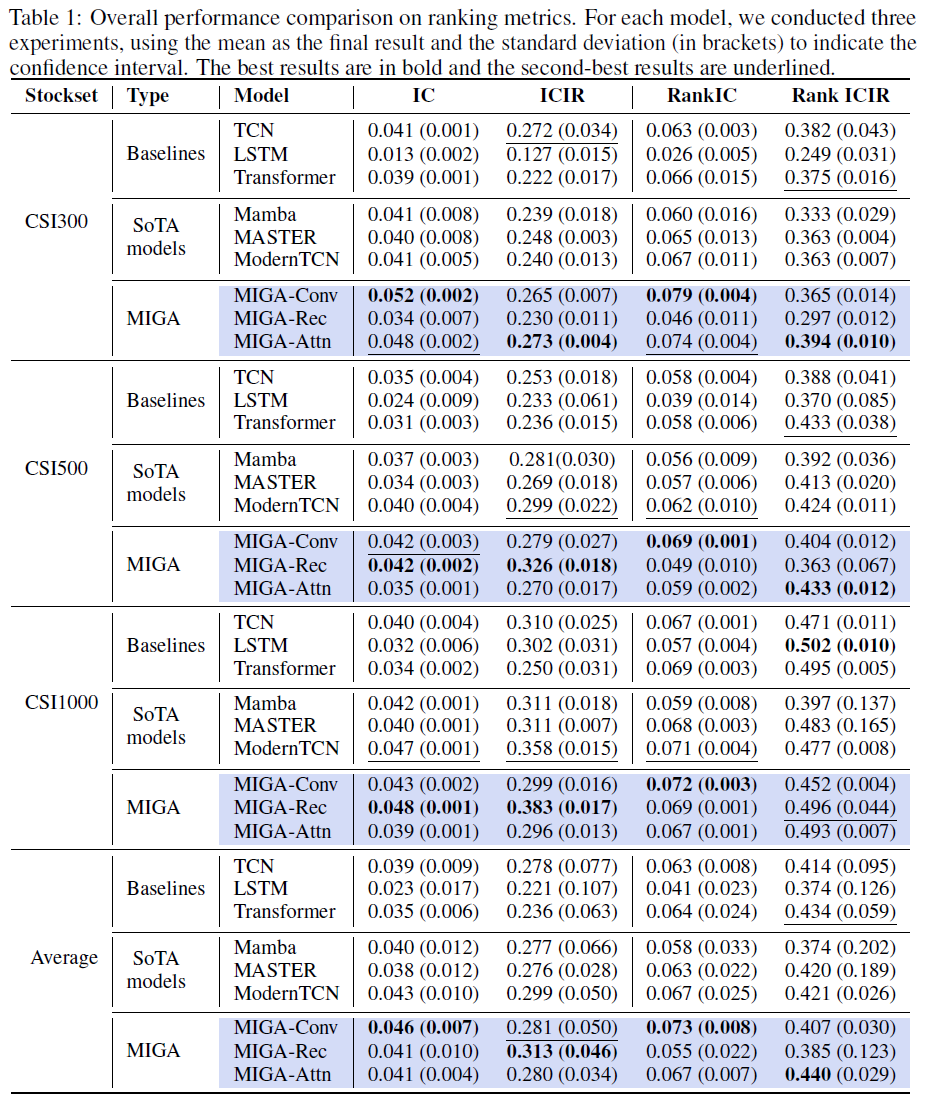
MIGA-Conv在CSI300基准上实现了24%的长仓投资组合指标提升,年回报率(AR)为0.24,信息比率(IR)为1.80,优于ModernTCN。MIGA显著提升了单一端到端模型的表现,MIGA-Conv在所有CSI基准上均优于TCN。
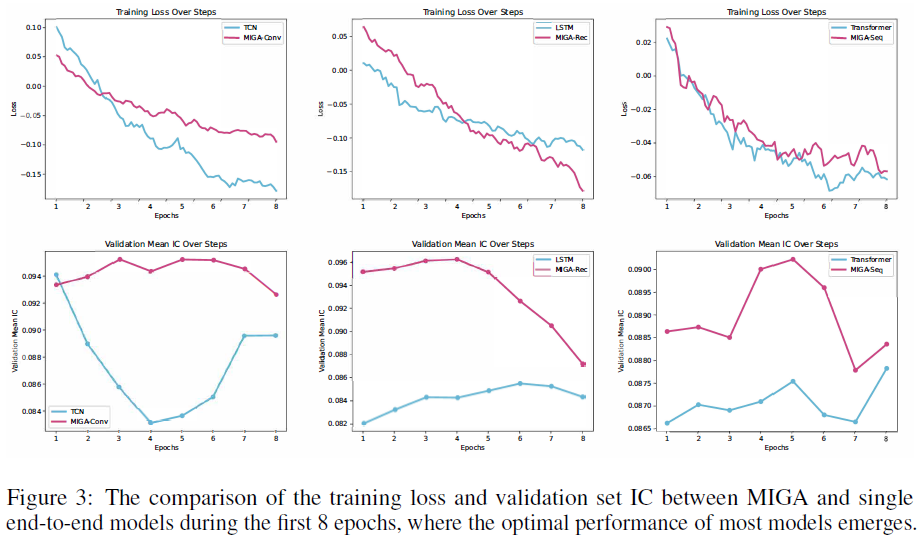
MIGA通过聚合不同专家,适应CSI300、CSI500和CSI1000的不同特征,展现出良好的市场适应性。MIGA在未见数据集上的预测能力优于单一端到端模型,验证集信息相关性(IC)更高。
增加专家数量可提升模型的ICIR和RankICIR,增强预测稳定性,本文分析了选取的8个专家的表现。
消融分析
专家数量的增加导致ICIR和rankicir得分的提高,这表明这种方法可以大大提高模型预测的稳定性。为了进一步探索模型潜力的上限,我们从63位路由专家(分为7组,每组9位专家)中选择了8位进行深入分析。
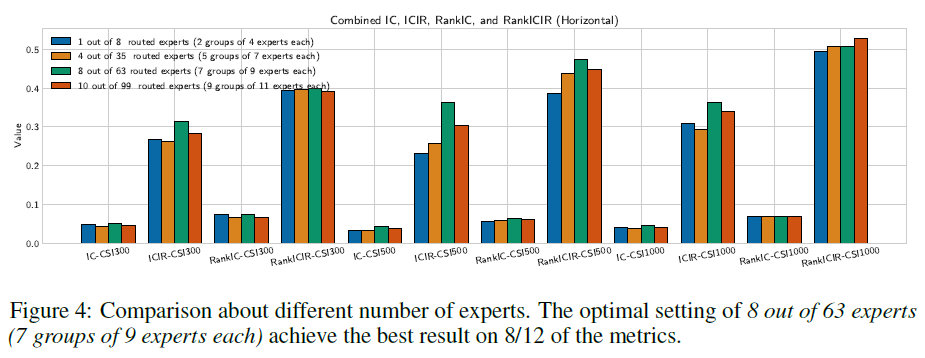
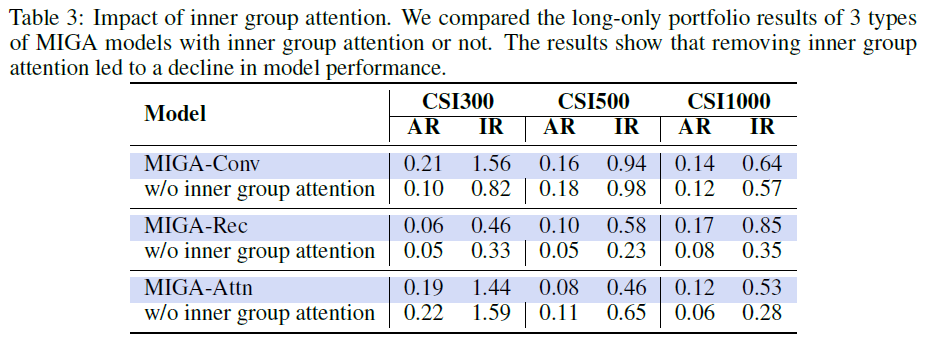
MIGA在CSI300、CSI500和CSI1000基准上优于孤立专家混合模型。内部组注意力提升了专家的整体水平,促进了知识共享。内部组注意力在混合专家系统中有效提高了效率和效果。
专家专业化分析
MIGA-Conv中的63位专家中,只有7位未能产生超额收益,表明大多数专家具备良好的预测能力。不同专家在不同股票类型上的表现差异明显,例如,专家3在CSI300上获得近30%的超额收益,但在CSI500和CSI1000上表现不佳。专家39在CSI500上表现较好,但在CSI300和CSI1000上的结果一般,显示出专家的专业化特征。在股票的涨跌预测中,专家37在多头头寸上表现优异,而专家4在空头头寸上表现更佳。
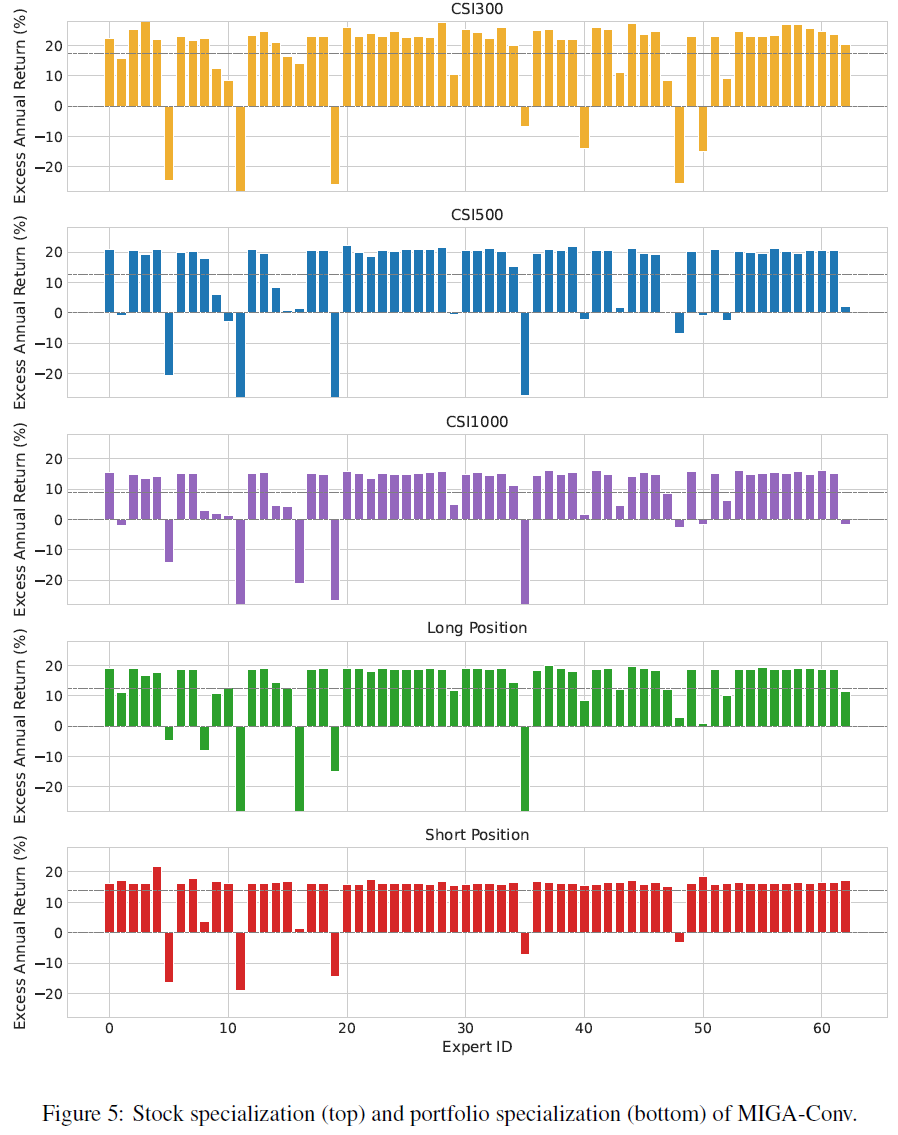
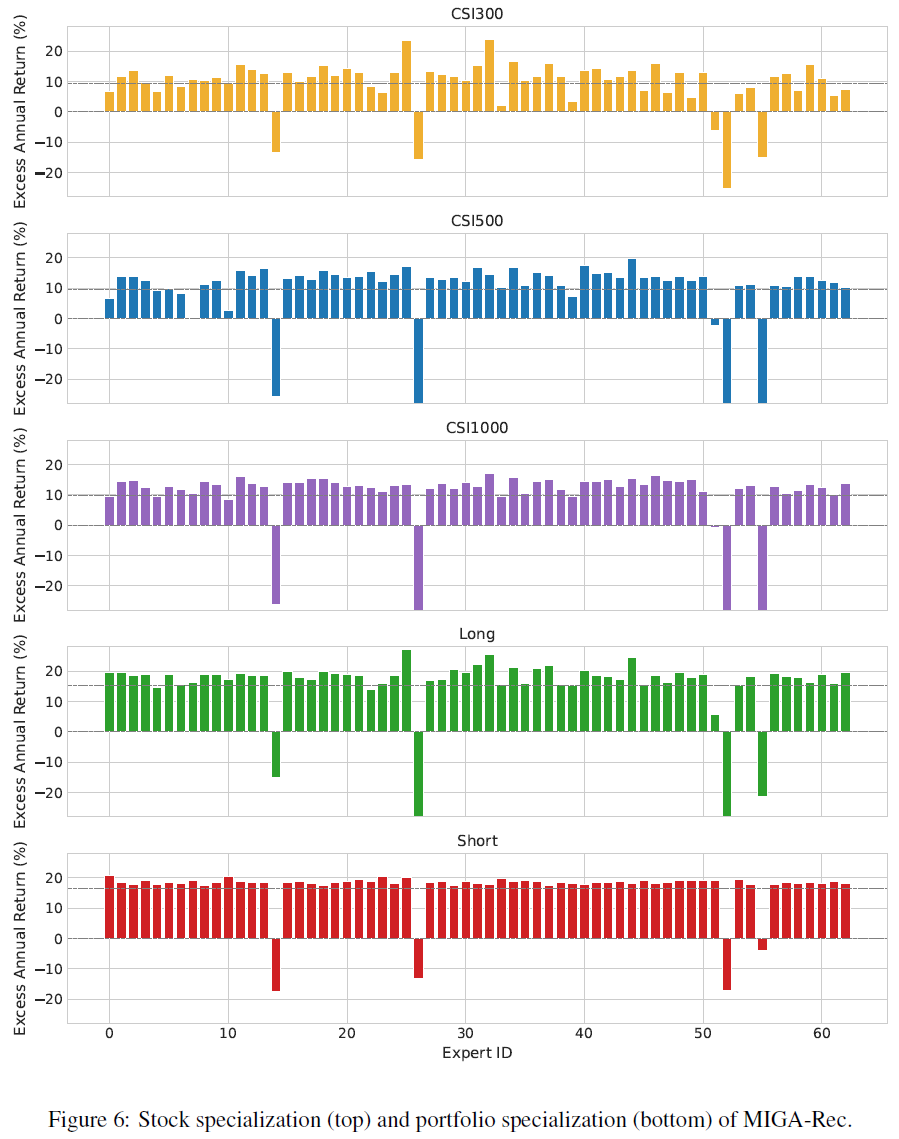
总结
本文提出MIGA模型,结合多种专家进行股票市场预测。该方法展示了在量化投资中整合专家混合框架的潜力,适用于随机股票市场。MIGA在3个中国股票指数基准上实现了最先进的性能,显著优于现有的端到端预测方法。进行了系统分析,旨在为未来研究提供有价值的见解,推动更先进的市场解决方案发展。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









