






Qwen2.5-Omni-3B是阿里云推出的全能AI模型。它能同时处理视频、音频、图像和文本。只有3B参数,却能在本地运行强大的多模态功能。
近日,已经在Hugging Face上发布。它是小型多模态AI系统的重要突破。
特点

Qwen2.5-Omni-3B与普通语言模型不同。它是真正的多模态系统,可以同时理解四种内容类型。
-
Qwen2.5-Omni-3B处理文本,能理解和生成全面的语言内容。
-
Qwen2.5-Omni-3B分析图像,能识别物体和场景,回答关于视觉内容的问题。
-
Qwen2.5-Omni-3B理解音频,能进行语音识别和转录,分析声音内容。
-
Qwen2.5-Omni-3B处理视频,能描述动作和场景变化,进行时间推理。
这个模型最大的特点是在仅有3B参数的情况下实现了这些功能。这使它可以在计算资源有限的环境中使用。
技术架构
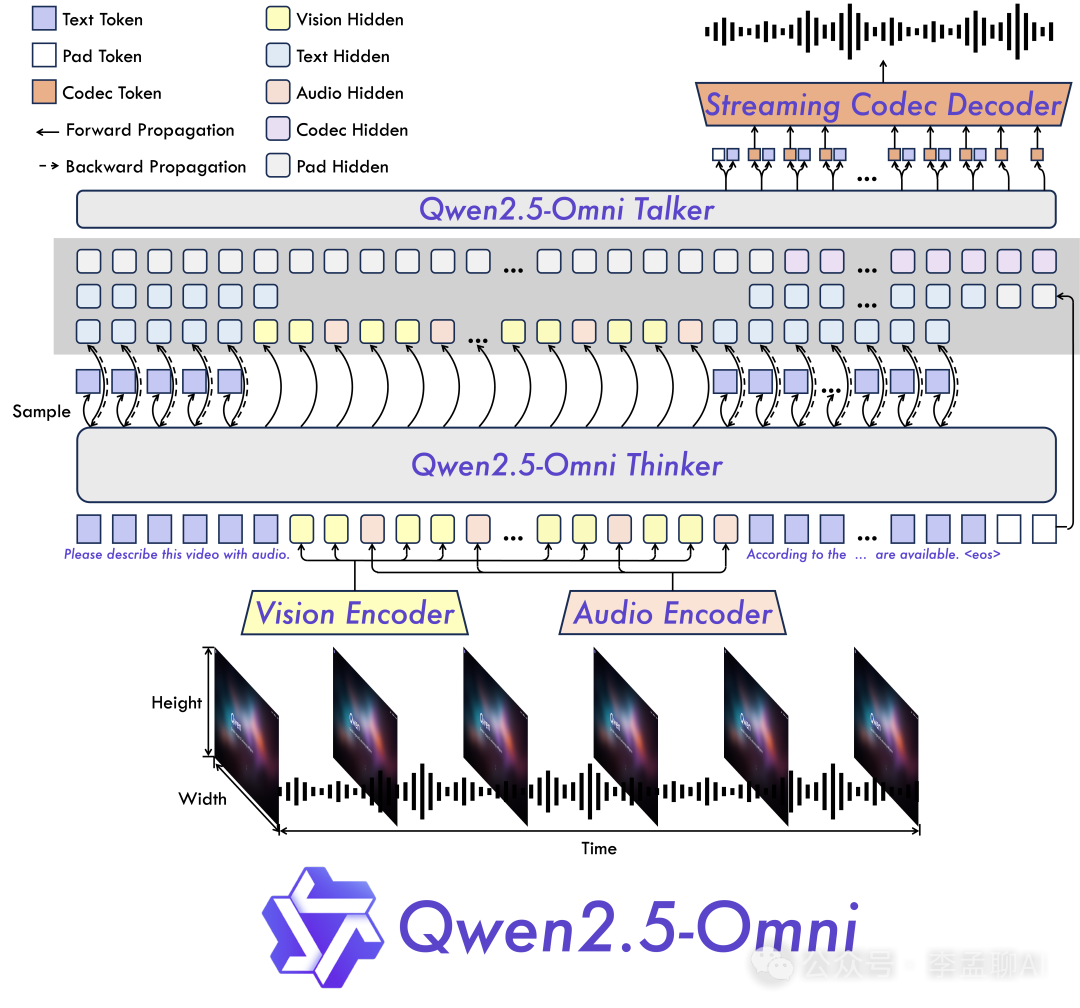
技术架构上,它基于Qwen 2.5模型系列,增加了专门的多模态处理组件。
-
Qwen2.5-Omni-3B有统一的Transformer骨干网络,作为基础文本处理管道。
-
Qwen2.5-Omni-3B有视觉处理模块,用于提取和理解图像与视频帧的特征。
-
Qwen2.5-Omni-3B有音频处理管道,将声波转换为可处理的嵌入向量。
-
Qwen2.5-Omni-3B有跨模态注意力机制,建立不同模态之间的连接。
技术创新点包括高效的参数共享,将所有输入作为序列处理,以及使用投影层将不同模态特征映射到共享的嵌入空间。
功能
-
在视频理解方面,它可以描述视频内容,识别动作,检测场景变化,进行时间推理,并回答关于视频的问题。
-
在音频处理方面,它可以进行语音识别和转录,识别说话者,理解音频场景,检测声音事件,回答基于音频的问题。
-
在图像理解方面,它提供详细的图像描述,物体检测和识别,场景理解,视觉问答和基于图像的推理。
-
在文本处理方面,它保持了强大的语言理解能力,可以生成内容,做摘要,回答问题,进行翻译。
Qwen2.5-Omni-3B的真正力量在于整合多模态信息的能力。它可以回答关于带音频的视频的问题,描述文本与图像的关系,基于多模态输入生成文本,从混合媒体内容创建连贯的叙述。
测试
性能测试显示,它在多个基准测试中表现出色,效率高,有时甚至超过了参数量更大的模型。
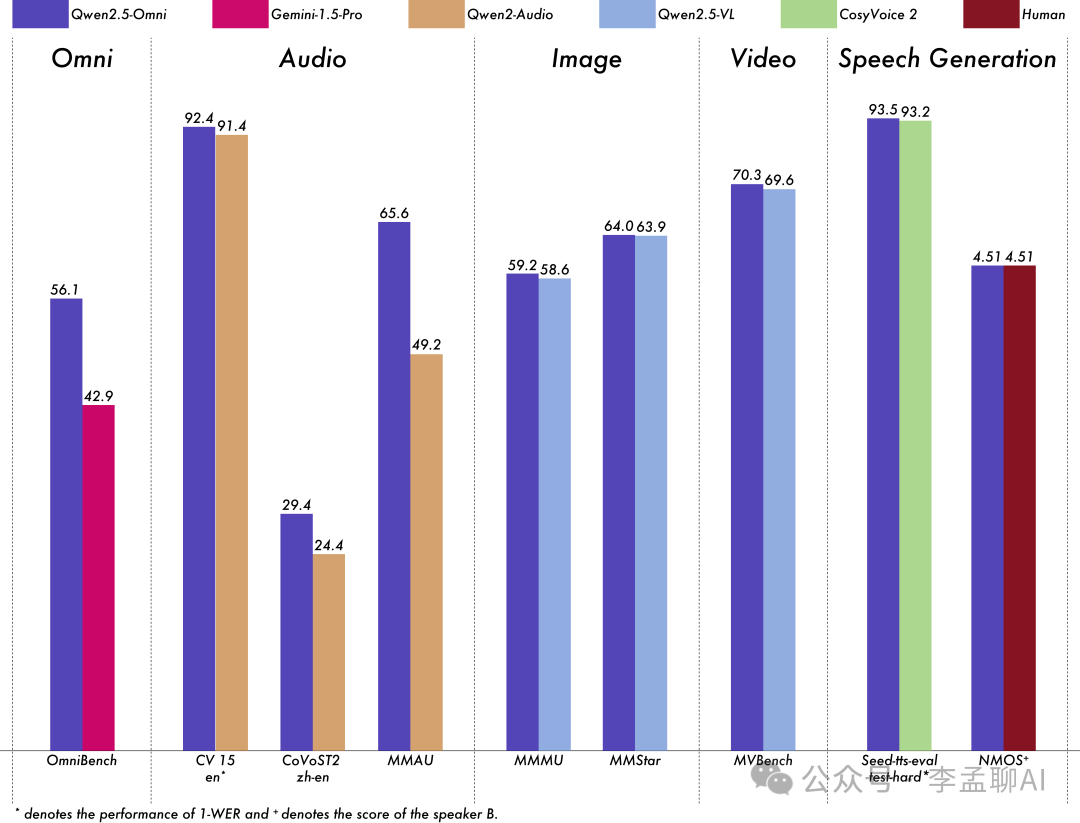
本地部署
以下是如何使用Python在本地运行模型的方法,不需要任何云端GPU!
第一步:安装必要依赖
运行以下命令设置环境:
pip install torch torchvision torchaudio einops timm pillow
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
pip install git+https://github.com/huggingface/diffusers
pip install huggingface_hub
pip install sentencepiece bitsandbytes protobuf decord numpy av
pip install qwen-omni-utils[decord] -U
第二步:导入模块并加载模型
import soundfile as sf
import torch
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-3B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2", # Boost performance
)
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-3B")
第三步:准备多模态对话
以下是如何输入包含音频的视频和系统上下文:
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
第四步:处理并运行推理
USE_AUDIO_IN_VIDEO = True
# Convert chat template and extract inputs
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
# Tokenize & format input tensors
inputs = processor(
text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO
)
inputs = inputs.to(model.device).to(model.dtype)
# Generate text and audio response
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
# Decode text
response_text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(response_text)
第五步:保存音频输出(可选)
🎧 现在你可以听到模型从多模态输入生成的语音响应!
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
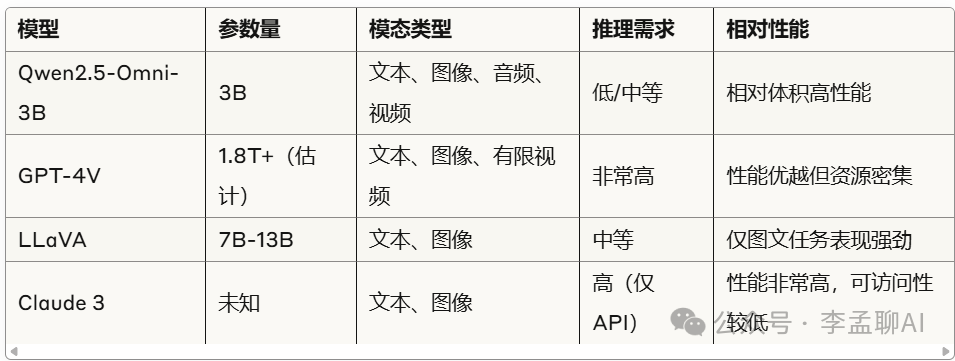
与其他多模态模型对比
结语
Qwen2.5-Omni-3B代表了多模态AI普及化的重要一步。它将视频、音频、图像和文本处理打包到一个紧凑的3B参数模型中,平衡了功能和实用性。
对于开发者、研究人员和组织来说,这是一个不需要大量计算资源就能实现多模态AI的解决方案。在Hugging Face上的可用性进一步降低了使用门槛。
随着多模态AI的发展,像Qwen2.5-Omni-3B这样紧凑而功能强大的模型将在日常应用中发挥关键作用。无论是构建内容审核系统、教育平台还是辅助工具,这个模型都提供了一个有力的基础。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









