







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
##产生的数据个数
n_samples=3000
##生产数据
X, lables_true = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.6,
random_state =0)
##变换成矩阵,输入必须是对称矩阵
metrics_metrix = (-1 * metrics.pairwise.pairwise_distances(X)).astype(np.int32)
metrics_metrix += -1 * metrics_metrix.min()
##设置谱聚类函数
n_clusters_= 4
lables = spectral_clustering(metrics_metrix,n_clusters=n_clusters_)
##绘图
plt.figure(1)
plt.clf()
colors = cycle(‘bgrcmykbgrcmykbgrcmykbgrcmyk’)
for k, col in zip(range(n_clusters_), colors):
##根据lables中的值是否等于k,重新组成一个True、False的数组
my_members = lables == k
##X[my_members, 0] 取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1], col + ‘.’)
plt.title(‘Estimated number of clusters: %d’ % n_clusters_)
plt.show()

e)效果图
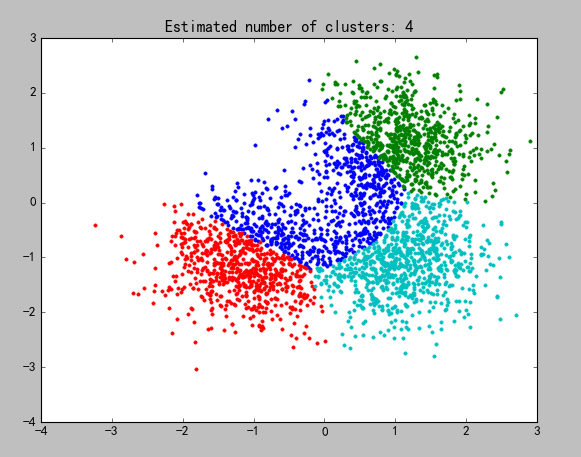
图5
5.Hierarchical Clustering
1)概述
Hierarchical Clustering(层次聚类):就是按照某种方法进行层次分类,直到满足某种条件为止。
主要分成两类:
a)凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









