






一,支持向量机
1 最大间隔与分类
-
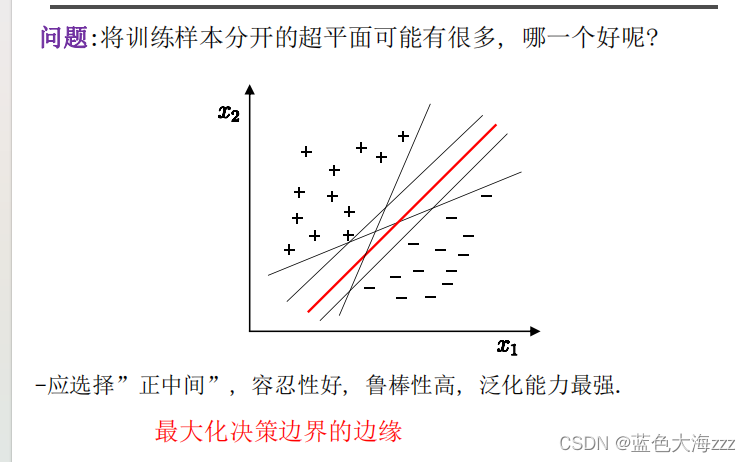
基本概念:最大间隔分类是一种基于支持向量机(SVM)的分类方法,其目标是通过在不同类别之间寻找最大间隔来实现分类。最大间隔是指,在一个线性可分的数据集中,将两个类别分开的最大距离。SVM 通过找到一个最佳的超平面来实现分类,该超平面使得不同类别之间的距离最大化,并且在分类过程中只考虑一小部分的关键样本点(称为支持向量)。这种方法能够在高维空间中进行分类,并且对于噪声较少的数据集具有良好的泛化能力。
-
最大决策边界的边缘

2 对偶问题
-
在 SVM 的优化问题中,常常使用对偶问题来替代原始问题,对偶问题的求解更加高效。对偶问题可以通过拉格朗日乘数法来导出,它将原始问题转化为一个约束最优化问题,其中每个约束条件对应一个拉格朗日乘子。通过对拉格朗日函数求导,我们可以得到一个对偶问题,该问题只涉及到拉格朗日乘子和内积。对偶问题的解等价于原始问题的解,但对于某些问题,对偶问题会更容易求解。
-
给定一个目标函数 f : R n → R ,希望找到 x R n ,在满足约束条件 g ( x )=0 的前提下,使得 f ( x ) 有最小值。该约束优化问题记为:
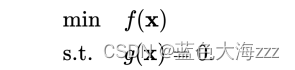
-
可建立拉格朗日函数:
-
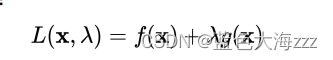 其中 λ 称为拉格朗日乘数。因此,可将原本的约束优化问题转换成等价的
无约束优化问题:分别对待求解参数求偏导,可得:
其中 λ 称为拉格朗日乘数。因此,可将原本的约束优化问题转换成等价的
无约束优化问题:分别对待求解参数求偏导,可得: -
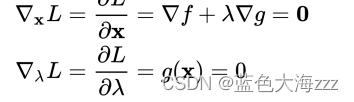 一般联立方程组可以得到相应的解
一般联立方程组可以得到相应的解
3 核函数

4 软间隔与正则化
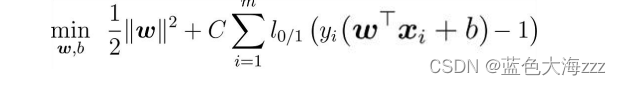
 不满足约束条件的样本
不满足约束条件的样本
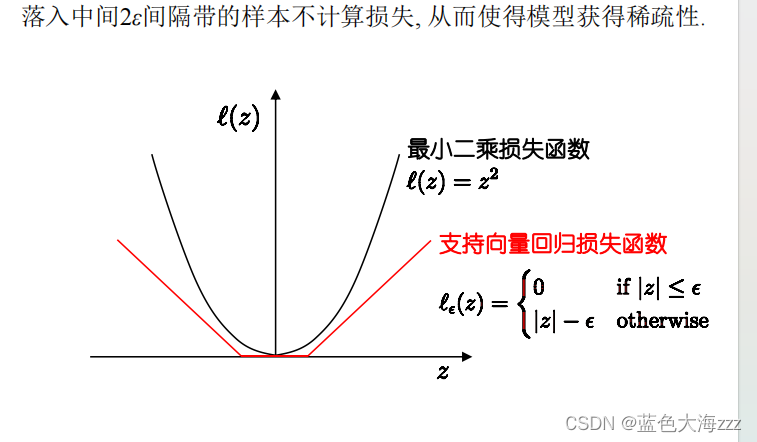
5 支持向量回归
二,代码简单实现
导入所需的库和模块:
python
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.io import loadmat
from sklearn import svm这些库和模块用于数据处理、可视化和支持向量机模型的构建。
加载数据:
raw_data = loadmat('data\ex6data1.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y'].flatten()使用loadmat函数加载MATLAB文件,并将数据存储在DataFrame中。其中,'X'对应数据的特征,'y'对应数据的标签。
数据可视化:
positive = data[data['y'] == 1]
negative = data[data['y'] == 0]
def plot_data(ax, X, y):
ax.scatter(positive['X1'], positive['X2'], s=30, marker='x', label='Positive', c='black')
ax.scatter(negative['X1'], negative['X2'], s=30, marker='o', label='Negative', c='y')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('Example Dataset 1')
ax.legend()根据标签的不同,将数据分为正例和负例,并定义了一个函数plot_data用于绘制散点图。
绘制超平面:
def plot_boundary(ax, clf, X):
x_min, x_max = X[:, 0].min() * 1.2, X[:, 0].max() * 1.1
y_min, y_max = X[:, 1].min() * 1.1, X[:, 1].max() * 1.1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500), np.linspace(y_min, y_max, 500))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contour(xx, yy, Z)定义了一个函数plot_boundary用于绘制超平面。通过生成网格点,使用训练好的SVM模型进行预测,并将预测结果可视化。
构建和训练模型:
X_np = data[['X1', 'X2']].values
y = data['y'].values
models = [svm.SVC(C=c, kernel='linear') for c in [1, 50, 100]]
clfs = [model.fit(X_np, y) for model in models]
titles = ['SVM Decision Boundary with C = {} (Example Dataset 1)'.format(c) for c in [1, 50, 100]]将特征和标签转换为NumPy数组,并创建不同惩罚参数C下的SVM模型。通过循环遍历,使用fit方法对模型进行训练,并将训练好的模型存储在列表clfs中。
可视化结果:
python
for model, title in zip(clfs, titles):
fig, ax = plt.subplots()
plot_data(ax, X_np, y)
plot_boundary(ax, model, X_np)
ax.set_title(title)
plt.show()通过循环遍历,对每个训练好的模型进行可视化。首先创建一个图形窗口,然后调用plot_data函数绘制数据集的散点图,接着调用plot_boundary函数绘制超平面,最后设置图的标题并显示图形。
结果是是为了展示不同惩罚参数C下SVM的决策边界对数据集的分类效果。如下:
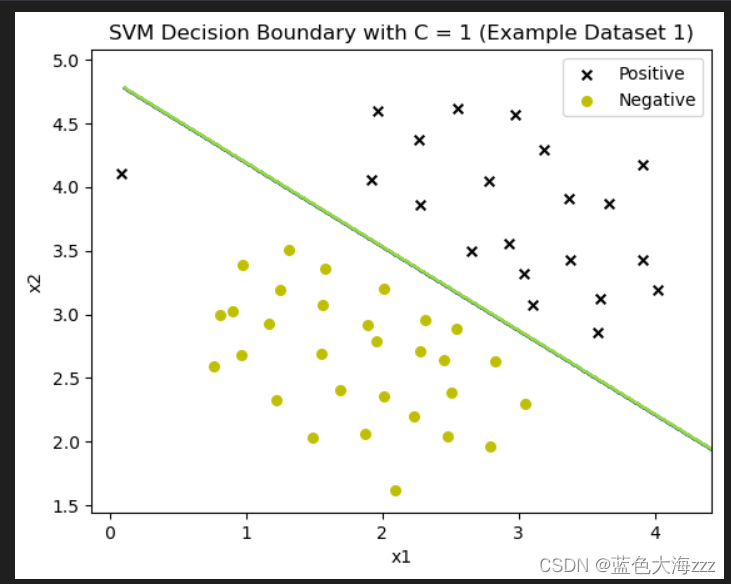
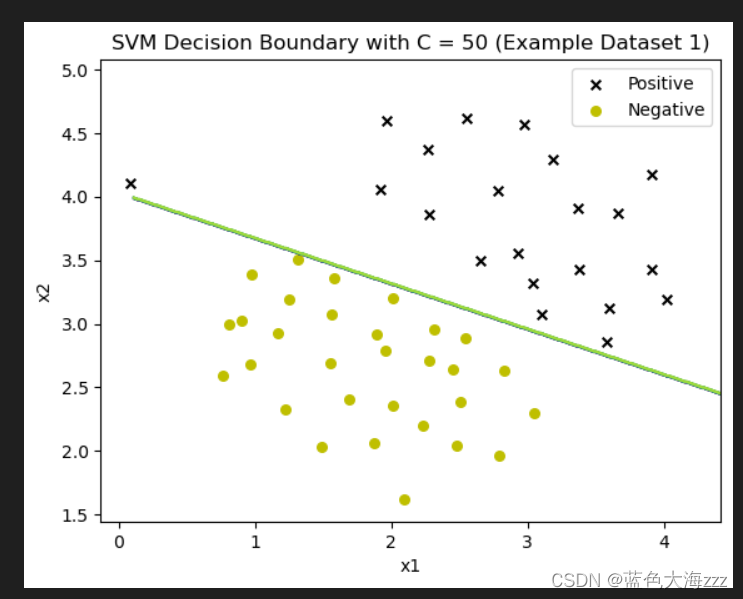

- C参数控制了错误分类训练示例的惩罚。C参数越大,则告诉SVM要对所有的例子进行正确的分类。
- 当C比较小时,模型对错误分类的惩罚较小,比较松弛,之间的间隔就比较大,可能会产生欠拟合的情况;
- 当C比较大时,模型对错误分类的惩罚就大,因此两组数据之间的间隔就小,容易产生过拟合的情况。
- C值越大,越不愿放弃那些离群点;c值越小,越不重视那些离群点。 根据上图结果看出,当C=100时,发现SVM现在对每个示例都进行了正确的分类,但是它绘制的决策边界并不适合数据。
总结与心得
使用SVM模型可以有效地对二分类问题进行建模和预测,在本例中,可以看到不同惩罚参数C下的SVM决策边界对数据集的分类效果。通过逐步调整C的取值,可以控制模型对训练样本的拟合程度和泛化能力。同时,可视化结果也直观地展示了SVM模型对数据集的分类效果。
总结改进
1.参数调优:
这段代码中使用了三个不同的惩罚参数C值(1, 50, 100),可以进一步尝试其他C值,以找到最佳的模型性能。可以通过网格搜索或交叉验证等方法来确定最优的C值。这是可以提升的地方。
2.其他SVM核函数:
这段代码中使用了线性核函数,但可以尝试其他非线性核函数,如多项式核函数或高斯核函数,以处理更复杂的分类问题。















 8010
8010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









