







以下是银行信用评分卡建模分析下篇的内容,包括采用两种方法进行数据分箱,然后构建模型,进行模型评估,最后评分卡建立这四部分。其中如果有一些地方分析的不正确,希望大家多多指正!
上篇文章链接数据挖掘项目:金融银行风控信用评分卡模型(上篇)
首先在分箱之前分训练集和测试集。
3 分训练集和测试集
from sklearn.model_selection import train_test_split
X = pd.DataFrame(X)
y = pd.DataFrame(y)
X_train,X_vali,Y_train,Y_vali = train_test_split(X,y,test_size = 0.3,random_state = 420)model_data = pd.concat([Y_train,X_train],axis = 1)
这样合并出来的数据序号是有问题的,所以对数据序号进行重新排列
model_data.index = range(model_data.shape[0])
model_data.columns = data.columns
## 测试集
vali_data = pd.concat([Y_vali,X_vali],axis = 1)
vali_data.index = range(vali_data.shape[0])
vali_data.columns = data.columns4.1使用toad数据分箱
我们要制作评分卡,是要给各个特征进行分档,以便业务人员能够根据新客户填写的信息为客户打
分。因此在评分卡制作过程中,一个重要的步骤就是分箱。分箱的目的是对连续变量进行分段离散化,或者对多状态的离散变量进行合并,减少离散变量的状态数。
有监督分箱:主要为卡方分箱和Split分箱等。
无监督分箱:等宽分箱,等频分箱,聚类分箱等
用来制作评分卡,最好能在
4~5
个为最佳。我们知道,离散化连续变量必然伴随着信息的损失,并且箱子越少,
信息损失越大。为了衡量特征上的信息量以及特征对预测函数的贡献,银行业定义了概念
Information value(IV)
:

其中
N
是这个特征上箱子的个数,
i
代表每个箱子, good%是这个箱内的优质客户(标签为0
的客户)占整个特征中所有优质客户的比例,bad%是这个箱子里的坏客户(就是那些会违约,标签为1
的那些客户)占整个特征中所有坏客户的比例,而WOEi则写作:
![]()
这是我们在银行业中用来衡量违约概率的指标,中文叫做证据权重
(weight of Evidence)
,本质其实就是优质客户比上坏客户的比例的对数。WOE
是对一个箱子来说的,
WOE
越大,代表了这个箱子里的优质客户越多。而
IV
是对整个特征来说的,IV
代表的意义是我们特征上的信息量以及这个特征对模型的贡献,由下表来控制:
| IV | 特征对预测函数的贡献 |
| <0.03 |
特征几乎不带有效信息,对模型没有贡献,这种特征可以被删除
|
| 0.03~0.09 |
有效信息很少,对模型的贡献度低
|
| 0.1~0.29 |
有效信息一般,对模型的贡献度中等
|
| 0.3~0.49 |
有效信息较多,对模型的贡献度较高
|
| >=0.5 |
有效信息非常多,对模型的贡献超高并且可疑
|
可见,
IV
并非越大越好,我们想要找到
IV
的大小和箱子个数的平衡点。箱子越多,IV必然越小,因为信息损失会非常多,所以,我们会对特征进行分箱,然后计算每个特征在每个箱子数目下的WOE
值,利用
IV
值的曲线,找出合适的分箱个数。
在做评分卡的时候,会使用iv值对特征进行筛选,toad库中集成了这样的函数。
在了解完WOE和IV值之后,在分箱的时候往往会看每个箱子WOE值的单调性,这里就有一个问题,为什么需要看WOE值的单调性?
使用toad库
## 首先对特征进行特征筛选,删除IV值小于0.02,并且相关性大于0.7的特征
import toad
train_selected, dropped = toad.selection.select(data,target = 'SeriousDlqin2yrs', empty = 0.5, iv = 0.02, corr = 0.7, return_drop=True, exclude=[])
print(train_selected.shape)(149165, 12) 可以看出没有被删除的特征
# WOE编码
combiner = toad.transform.Combiner()
# 训练数据并指定分箱方法
combiner.fit(pd.concat([Y_train,X_train], axis=1), y='SeriousDlqin2yrs',method= 'chi',min_samples = 0.05,exclude=[])
train_adj = combiner.transform(pd.concat([Y_train,X_train], axis=1))使用toad这个库进行分库时间用了很久,因为之前为解决数据不平衡我对数据使用了SMOTE算法,训练集有195008行,12列。
# 以字典形式保存分箱结果
bins = combiner. Export()
bins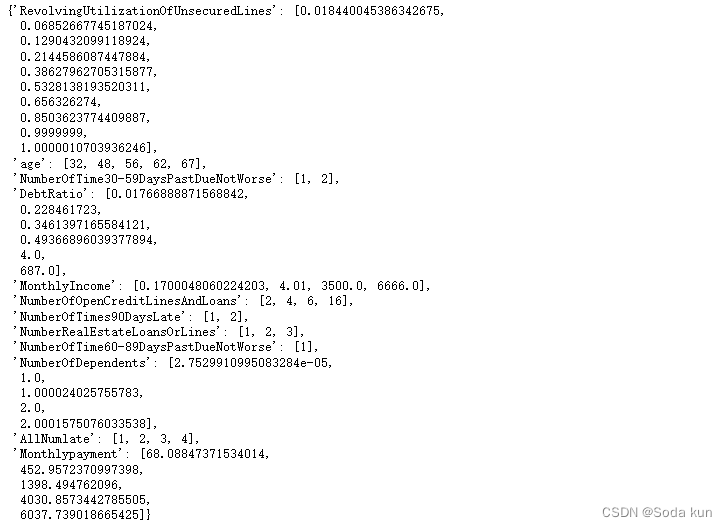
可以看出使用toad的分箱,他的有些结果很奇怪。比如Revol中0.99999还要单独分出来,60-89天逾期特征只分了一箱等等,使用toad帮我们分好的箱子检查一下woe单调性,之后再结合业务知识手动调整。
分完箱之后计算woe(检查单调性)
hand_bins = {k:[-np.inf,*v[:-1],v[-1],np.inf] for k,v in bins.items()}
hand_bins{'RevolvingUtilizationOfUnsecuredLines': [-inf,
0.018440045386342675,
0.06852667745187024,
0.1290432099118924,
0.2144586087447884,
0.38627962705315877,
0.5328138193520311,
0.656326274,
0.8503623774409887,
0.9999999,
1.0000010703936
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3702
3702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









