







数据来自Kaggle的Give Me Some Credit,有15万条的样本数据,网上的分析说明有很多,本人结合其他大佬的方法,对数据进行细致的分析,主要分析在EDA环节,之后尝试使用toad这个评分卡的库,以及使用quct结合卡方检验分箱的方法,使用AUC和KS,结合交叉验证对比分析哪个效果更好。
目录
由于整篇文章的篇幅过长,因此分为上下两部分。
- 上篇
- 理解数据
- 探索性数据分析
- 数据预处理
- 特征工程
- 下篇
- 使用toad进行woe分箱,并进行模型评估
- 手写卡方分箱,并进行模型评估
- 评分卡建立
1.1背景介绍
银行领域评分卡一般分为四种,A、B、C、F卡:
A卡表示为贷前评分卡。
B卡表示为贷中评分卡。
C卡表示为贷后评分卡。
F卡表示为反欺诈评分卡。
1.2基本的项目流程
典型的信用评分模型主要的开发流程如下所示:
(1)数据获取,包括获取存量客户及潜在客户的数据。存量客户是指已经在证劵公司开展相关融资业务的客户,包括个人客户和机构客户;潜在客户是指
(2)数据预处理,主要工作包括数据清洗,缺失值处理,异常值处理,主要是为了将获取的原始数据转化为可用作模型开发的数据。
(3)EDA探索性数据分析,该步骤主要是获取样本总体的大概情况,描述样本总体情况的指标主要有直方图和箱线图等等。
(4)变量选择,主要是通过统计学的方法,筛选出对违约状态影响最显著的指标。常见的特征筛选方法,一般分为三种:过滤法、嵌入法、包装法。过滤法一般采用sklearn当中的方差过滤和卡方过滤。嵌入法是一种让算法自己决定使用哪些特征的方法。包装法和嵌入法很像,但包装法需要使用一个目标函数作为黑盒来帮助选择特征。一般来说对于评分卡模型,还会使用woe值和IV值筛选特征。
(5)模型开发,该步骤主要包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三部分。
(6)模型评估,一般评分卡中常用的评估方法,有Accuracy计算准确性、画出ROC曲线、计算AUC数值、还有KS值、最后做一个交叉验证看模型的稳定性。
(7)最后一步就是形成评分卡
2.1数据获取
## 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression as LR ##调用sklearn逻辑回归
from imblearn.over_sampling import SMOTE ## 处理数据不平衡问题
import seaborn as sns
# 画图显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedata = pd.read_csv(r"rankingcard.csv",index_col = 0) ##首先导入训练集数据
test = pd.read_csv(r"cs-test.csv",index_col = 0) ##导入测试集数据2.2探索数据
#观察数据类型
data.head()
## 查看训练集数据
test.head()
# 观察数据维度
print(data.shape)
print(test.shape)
(150000, 11)
(101503, 11)data.info() ##查看里面的基本情况,字符类型以及缺失值情况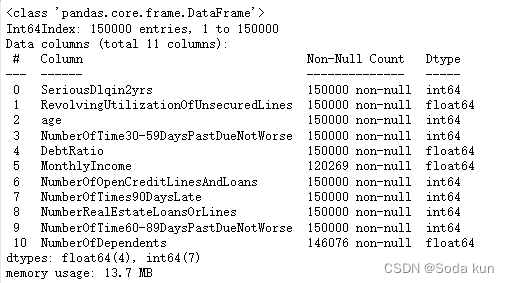
下面可以看到数据的大致情况。数据属于个人消费类贷款,只考虑信用评分最终实施能够使用到的数据应从如下一些方面获取数据:
基本属性:包括借款人当时的年龄。
偿债能力:包括了借款人的月收入、负债比率。
信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90天或以上的逾期次数
财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量
贷款属性:暂无
其他因素:包括了借款人的家属数量(不包括本人在内)
时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年。
标签如下所示:
SeriousDlqin2yrs:指在过去两年中至少有一次逾期90天或更长时间的信用违约情况。是本数据集的目标变量。
RevolvingUtilizationOfUnsecuredLines:指信用卡和个人信贷余额与可用信贷额度之比。
age:指借款人的年龄。
NumberOfTime30-59DaysPastDueNotWorse:指在过去两年中出现了30-59天的逾期但没有更严重的逾期情况的次数。
DebtRatio:指负债比率,即每月债务支付、赡养费用和生活费用除以每月总收入。
MonthlyIncome:指借款人的月收入。
NumberOfOpenCreditLinesAndLoans:指借款人未偿还的信用额度。
NumberOfTimes90DaysLate:指在过去两年中出现了90天或更长时间的逾期情况的次数。
NumberRealEstateLoansOrLines:指不包括家庭住房在内的房地产贷款和额外的抵押贷款次数。
NumberOfTime60-89DaysPastDueNotWorse:指在过去两年中出现了60-89天的逾期但没有更严重的逾期情况的次数。
NumberOfDependents:指借款人在家庭中需要抚养的家属人数。
##去除重复值,注意去除的是重复的行,因为对于150000行的数据,
##存在两组完全一样的数据几乎不太可能,有可能是录入错误
data.drop_duplicates(inplace = True) ##删除重复值,并且替换
data.info() 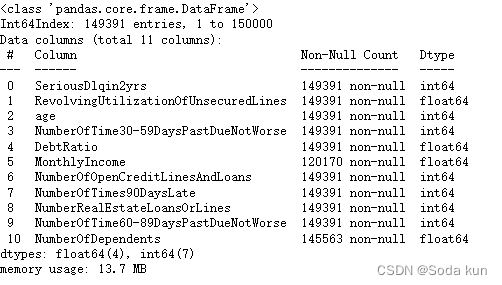
##删除后一定要记得恢复索引!
data.index = range(data.shape[0])2.3 EDA 探索性数据分析
2.3.1 缺失值分析
##探索一下模型的缺失值
data.isnull().sum() ##用isnull语句+sum语句,返回布尔值相加,得到每列缺失值的数目data.isnull().sum()/len(data) ##判断每一列缺失值所占的比值2.3.2 数据平衡性
## 画饼图
figure,ax = plt.subplots(figsize = (12,4))
data.SeriousDlqin2yrs.value_counts().plot.pie(autopct = '%1.1f%%')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









