




 本文探讨信贷风险管理中的规则引擎和风险模型,以某公司油品贷业务为例,利用决策树算法制定风险控制策略。通过对数据的预处理、特征衍生,训练出的决策树模型帮助识别低风险客户群体,降低坏账率。
本文探讨信贷风险管理中的规则引擎和风险模型,以某公司油品贷业务为例,利用决策树算法制定风险控制策略。通过对数据的预处理、特征衍生,训练出的决策树模型帮助识别低风险客户群体,降低坏账率。
在信贷风险管理领域,通常有两种主要的风险控制方法,即规则引擎和风险模型。规则引擎使用一组简单的规则进行客户分类,使得不同客户群体的期望风险存在显著差异,并能够快速进行风险划分。而风险模型则使用机器学习技术预测客户的违约风险,尽管精度相对较高,但建模和上线周期较长。因此,在需要快速进行客户划分或者精度要求不高的场景中,一般会采用规则挖掘和规则引擎快速上线的方式。对于精度要求较高的场景,则会采用规则引擎粗筛+模型精选相结合的方式进行风险决策。
本文以某公司的“油品贷”数据为例,使用决策树算法进行策略制定。
业务背景:某打车平台和某些加油站达成合作,联合推出油品贷业务,可以给打车平台的司机提供贷款等业务,但最近发现使用油品贷的人,坏账率很高,数据高达5%,否则项目会被砍掉。
来申请油品贷的司机本身本身已经通过了评分卡,并分为六个评分等级A-F。公司领导发现只有给等级A的客户放款才能不亏钱,现需要我们在现在的基础上制定有效的规则策略,控制坏账率。
滴滴是和很多加油站有合作的,加油站会给滴滴提供司机数据。
| 变量类型 | 最终基础变量名(还需要做上述变换) | 释义 |
| 数值统计型 | ||
| oil_amount | 加油升数 | |
| discount_amount | 折扣金额 | |
| sale_amount | 促销金额 | |
| amount | 总金额 | |
| pay_amount | 实际支付金额 | |
| coupon_amount | 优惠券金额 | |
| payment_coupon_amount | 支付优惠券金额 | |
| 分类型 | ||
| channel_code | 渠道 | |
| oil_code | 油品品类(规格) | |
| scene | 场景 | |
| source_app | 来源端口(1货车帮、2微信) | |
| call_source | 订单来源(1:中化扫描枪 2:pos 3:找油网 4:油掌柜5:司机自助加油 6 油站线) |
一,首先要导入所需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree二,导入所需要的数据
data = pd.read_csv(r"F:\rankingcard.csv",index_col = 0) ##导入数据三,数据预览
3.1 查看数据基本情况
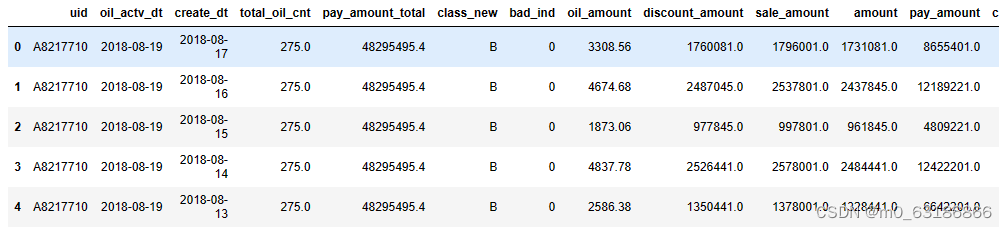
# 查看前5行数据详情
data. Head()数据部分展示:
3.2 查看数据基本情况
# 数据整体描述
data.describe()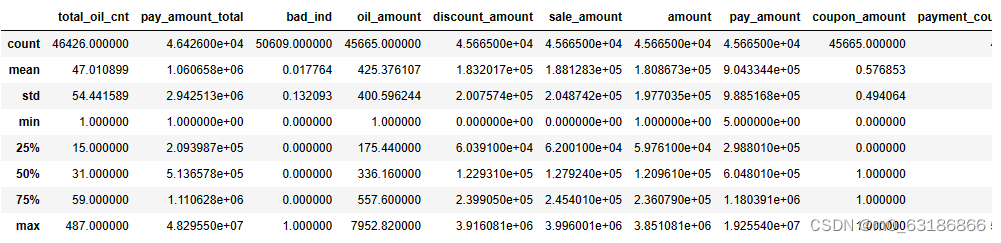
![]()
3.3查看数据维度
# 数据维度情况
data.shape数据一共有50609行,19列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









