






最近为了完成作业,做了一个小旅游网站
其中我希望能在展示景区介绍的时候,顺便展示景区的评论,这就需要找到捷程或是其他旅游网站的api。但是找了许久没能如愿。这下不得不爬了(bushi)
在找api的过程中发现了一篇文章python爬取携程景点评论信息 - 知乎 (zhihu.com)
其中有一个神秘的接口
postUrl = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
按照他的请求方法,可以获得如下这么一坨
{'ResponseStatus': {'Timestamp': '/Date(1697024577621+0800)/', 'Ack': 'Success', 'Errors': [], 'Build': None, 'Version': None, 'Extension': [{'Id': 'CLOGGING_TRACE_ID', 'Version': None, 'ContentType': None, 'Value': '6433706856160040933'}, {'Id': 'RootMessageId', 'Version': None, 'ContentType': None, 'Value': '100025527-0a70c344-471395-1620854'}]}, 'head': {'auth': '', 'errcode': 0, 'errmsg': ''}, 'data': {'cmtquantity': 31945, 'cmtscore': 4.5, 'totalpage': 624, 'recompct': '96%推荐', 'stscs': [{'tagid': -21, 'count': 0, 'desc': '带图', 'moodtype': 0, 'location': 'tab'}, {'tagid': -12, 'count': 1121, 'desc': '低分', 'moodtype': 0, 'location': 'tab'}, {'tagid': -250, 'count': 31195, 'desc': '最近出行', 'moodtype': 0, 'location': 'tab'}, {'tagid': -22, 'count': 17392, 'desc': '消费后评价', 'moodtype': 0, 'location': 'tag'}], 'comments': [{'id': 177804171, 'uid': '芳菲旅游达人', 'userImage': 'https://dimg04.c-ctrip.com/images/0Z84412000bqxlgsx5457_C_180_180.jpg', 'title': '', 'content': '羊城广州,既是岭南文化的发源地,也是美食天堂。在这座城市,你将感受到独特的南国风情,品味各种地道的美食。\n第一天:感受广州历史文化\n从广州白云国际机场或广州火车站出发,乘坐地铁或出租车前往市区。\n首先游览广州地标建筑——广州塔。在此欣赏到广州全景,领略珠江两岸风光。\n门票攻略:广州塔观景台,150元/人。\n中午,品尝广州特色美食——点心,如虾饺、烧卖、肠粉等,尽享广州的美食盛宴。\n下午,游览陈家祠,感受岭南建筑的魅力,欣赏精美的石雕、木雕、砖雕。门票攻略:陈家祠,15元/人。\n晚餐,品尝地道的广州烧烤,享受美味的夜宵。\n入住市区的酒店,广州的住宿选择丰富,有五星级酒店、经济型酒店、民宿等,总有一款适合你。\n第二天:探访岭南文化与自然景观\n上午,游览白云山,领略自然风光。漫步山间小道,欣赏蓝天白云,清新空气。门票攻略:白云山,5元/人。。', 'date': '2023-07-29 22:35', 'score': '5', 'isselect': False, 'simgs': [], 'videos': [], 'replyeditor': None, 'reply': None, 'usecount': 18, 'sourcetype': 0, 'playdate': '', 'keywordlist': None, 'cmttype': 'others', 'commentOrderInfo': '', 'commenter': False, 'memberLevel': 0, 'memberName': '普通会员', 'sightStar': 5, 'interestStar': 5, 'costPerformanceStar': 5},], 'abtests': []}}
分析response发现里面有content和uid,足够我们的景区评论功能使用了,接下来就是把这个接口用在我们的代码里。
首先,原文章的景区id是直接在网页里找的,如下
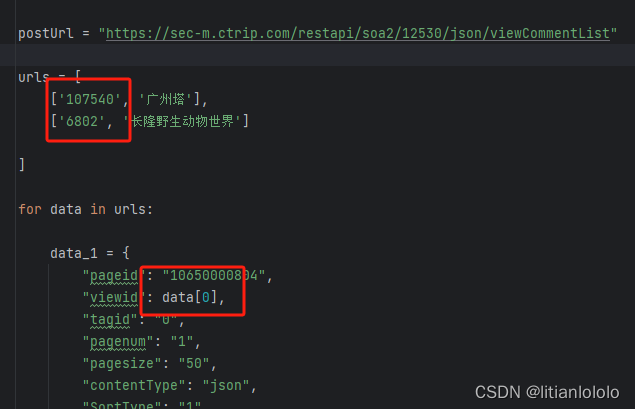
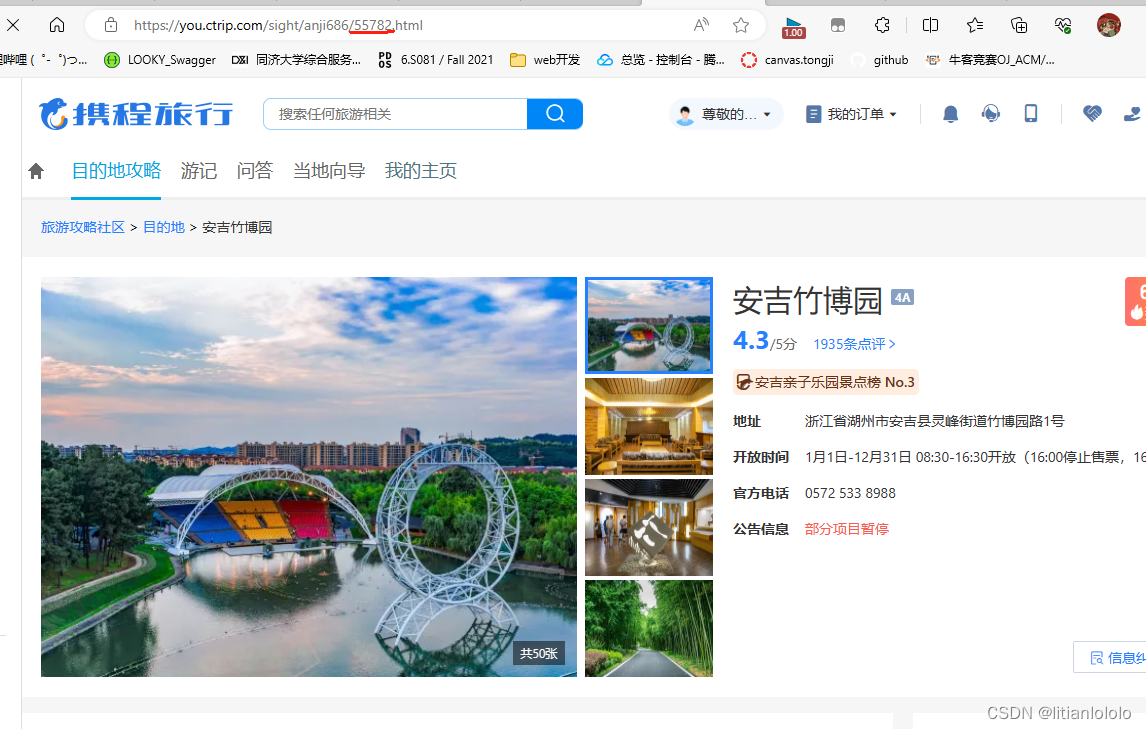
显然,这不符合我的接口的要求,需要实现根据关键词来获取景区id
打开捷程官网首页,F12查看“网络”,输入一个景点的名字,可以发现有一个search的任务,点击打开响应,可以发现我们需要的景区id就在这里
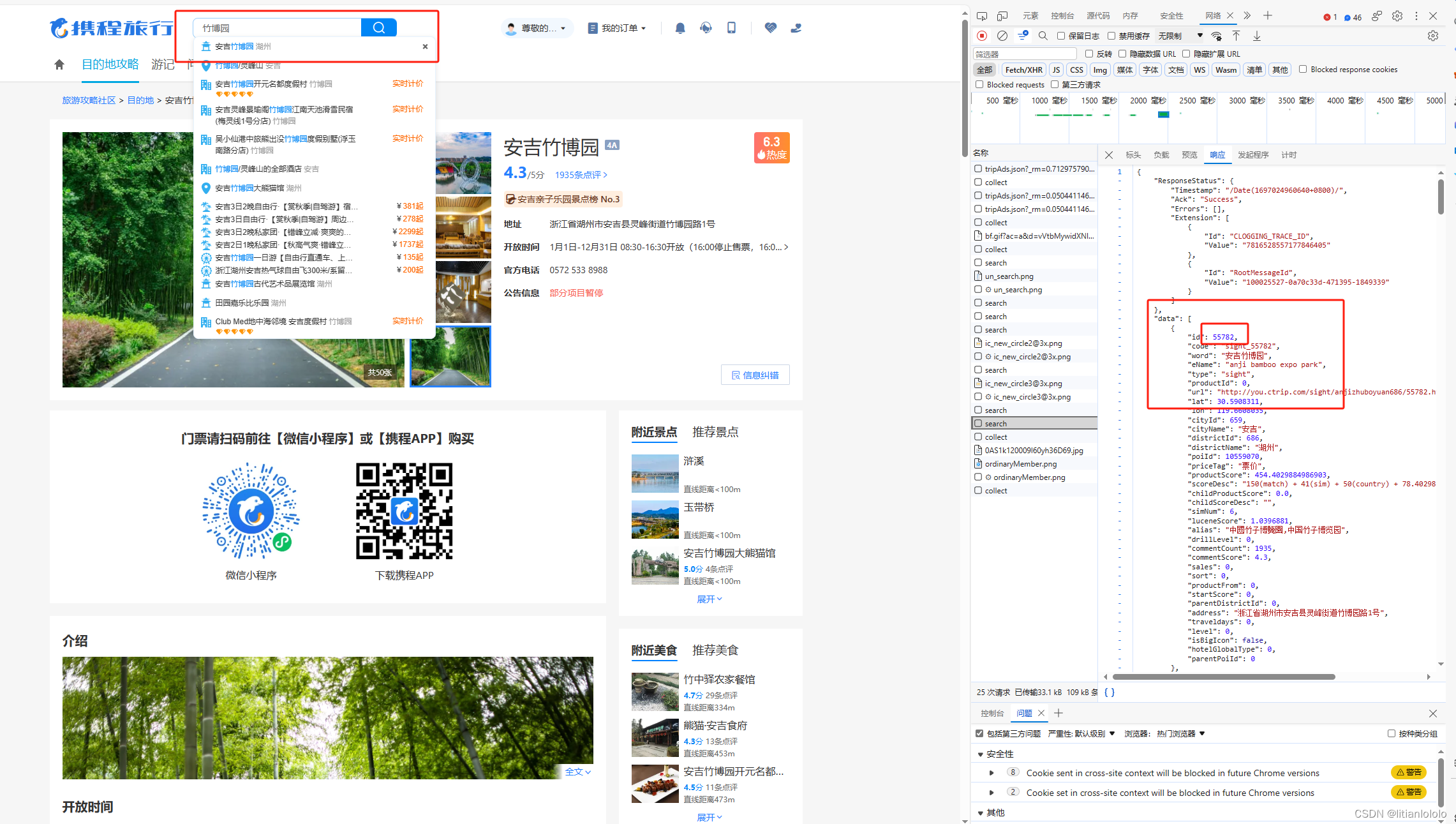
再分别打开标头和负载,就可以找到请求的形式,接下来就很简单了
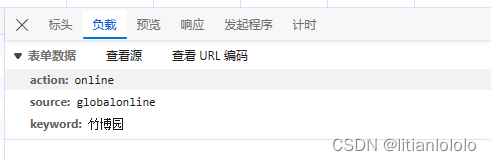
根据上面的标头和负载的形式,写一个请求,来获取景区的id
(传入关键词)
\# 获取关键字参数
keyword = sys.argv[1]
CodeUrl = "https://m.ctrip.com/restapi/soa2/26872/search"
codedata = {
"action": "online",
"source": "globalonline",
"keyword": keyword
}
response = requests.post(CodeUrl, data=json.dumps(codedata)).text
data_dict = json.loads(response)
\# 获取第一个元素的"id"字段的值
id_value = data_dict['data'][0]['id']
得到了景区的id,就可以仿照前面那篇文章写的,去获取景区的评论
postUrl = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
data_1 = {
"pageid": "10650000804",
"viewid": id_value,
"tagid": "0",
"pagenum": "1",
"pagesize": "50",
"contentType": "json",
"SortType": "1",
"head": {
"appid": "100013776",
"cid": "09031037211035410190",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"extension": [
{
"name": "protocal",
"value": "https"
}
]
},
"ver": "7.10.3.0319180000"
}
html = requests.post(postUrl, data=json.dumps(data_1)).text
html = json.loads(html)
这样就把返回的内容存到了html中,解析html,把uid和评论保存在数组中
# 初始化一个空数组,用于存储JSON对象
result_array = []
html1 = requests.post(postUrl, data=json.dumps(data_1)).text
html1 = json.loads(html1)
comments = html1['data']['comments']
for i in comments:
name = i['uid']
content = i['content']
content = re.sub(" ", "", content)
\# 创建一个包含name和content字段的JSON对象
comment_obj = {"name": name, "content": content}
\# 将JSON对象添加到结果数组中
result_array.append(comment_obj)
\# 将结果数组输出为JSON格式
result_json = json.dumps(result_array)
print(result_json)
到此,就实现了根据景区关键词爬取捷程的景区评论的功能
可以使用下面这个接口获取景区的评价
// 不过我只爬取了一页的评论,因为一页的评论已经足够我使用了
完整代码:
# -*- coding: utf-8 -*-
import re
import requests
import json
import sys
# 获取关键字参数
keyword = sys.argv[1]
try:
CodeUrl = "https://m.ctrip.com/restapi/soa2/26872/search"
codedata = {
"action": "online",
"source": "globalonline",
"keyword": keyword
}
response = requests.post(CodeUrl, data=json.dumps(codedata)).text
data_dict = json.loads(response)
# 获取第一个元素的"id"字段的值
id_value = data_dict['data'][0]['id']
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
postUrl = "https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
data_1 = {
"pageid": "10650000804",
"viewid": id_value,
"tagid": "0",
"pagenum": "1",
"pagesize": "50",
"contentType": "json",
"SortType": "1",
"head": {
"appid": "100013776",
"cid": "09031037211035410190",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"extension": [
{
"name": "protocal",
"value": "https"
}
]
},
"ver": "7.10.3.0319180000"
}
html = requests.post(postUrl, data=json.dumps(data_1)).text
html = json.loads(html)
# 初始化一个空数组,用于存储JSON对象
result_array = []
html1 = requests.post(postUrl, data=json.dumps(data_1)).text
html1 = json.loads(html1)
comments = html1['data']['comments']
for i in comments:
name = i['uid']
content = i['content']
content = re.sub(" ", "", content)
# 创建一个包含name和content字段的JSON对象
comment_obj = {"name": name, "content": content}
# 将JSON对象添加到结果数组中
result_array.append(comment_obj)
# 将结果数组输出为JSON格式
result_json = json.dumps(result_array)
print(result_json)
except requests.exceptions.RequestException as e:
print(f"连接失败,错误信息:{str(e)}")
except json.JSONDecodeError as e:
print(f"JSON解析错误,错误信息:{str(e)}")
except Exception as e:
print(f"发生错误,错误信息:{str(e)}")
下面是爬取全部景区第一页评论的代码(也可以稍加修改改成全部页)
不过有一个缺陷,神秘接口很鸡贼的没有在返回中加上景区的中文名,爬下来的也只有景区id,没有使用价值
# 第一个编号是227还是228来着 捷程的景区编号位数长短不一,姑且写个200000000
for n in range(227,200000000):
data_1 = {
"pageid": "10650000804",
"viewid": n,
"tagid": "0",
"pagenum": "1", # 修改为只获取第一页的评论
"pagesize": "50",
"contentType": "json",
"SortType": "1",
"head": {
"appid": "100013776",
"cid": "09031037211035410190",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"extension": [
{
"name": "protocal",
"value": "https"
}
]
},
"ver": "7.10.3.0319180000"
}
try:
html = requests.post(postUrl, data=json.dumps(data_1)).text
html = json.loads(html)
\# comments = html['data']['comments']
IDs = []
names = []
scores = []
contents = []
times1 = []
print(f'正在抓取 id={n}') # 显示正在抓取的n的值
html1 = requests.post(postUrl, data=json.dumps(data_1)).text
html1 = json.loads(html1)
print(html1)
comments = html1['data']['comments']
for i in comments:
name = i['uid']
content = i['content']
content = re.sub(" ", "", content)
time1 = i['date']
names.append(name)
contents.append(content)
print(name, content)
if n == 0:
mode = 'w'
else:
mode = 'a'
pf = pd.DataFrame({'n': n, 'names': names, 'contents': contents})
pf.to_csv("pinglun.csv", encoding="utf-8-sig", header=False, index=False, mode=mode)
except Exception as e:
print(f"连接失败,错误信息:{str(e)}")
continue















 6981
6981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









