







一、每日一题
DataFrame products
-------------+--------+ | Column Name | Type | +-------------+--------+ | name | object | | quantity | int | | price | int | +-------------+--------+
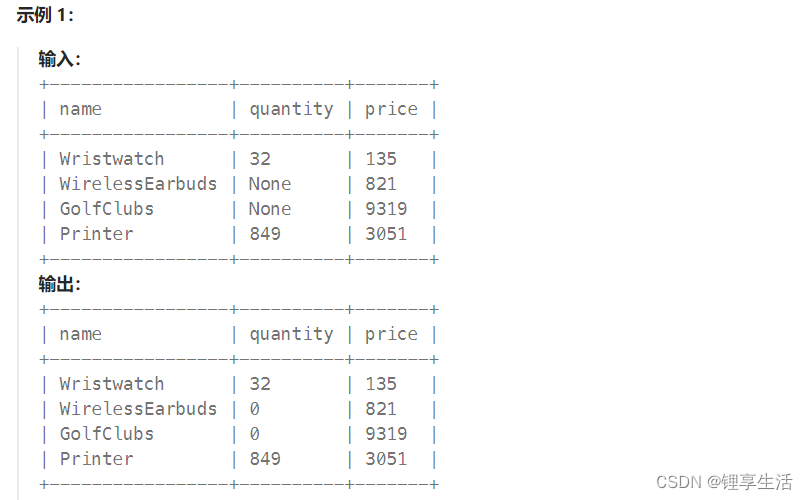
编写一个解决方案,在 quantity 列中将缺失的值
编写一个解决方案,在
quantity列中将缺失的值填充为0。返回结果如下示例所示。
解答:
import pandas as pd
def fillMissingValues(products: pd.DataFrame) -> pd.DataFrame:
products['quantity'] = products['quantity'].fillna(0)
return products题源:力扣
二、总结
fillna() 是 Pandas 库中一个非常实用的方法,用于处理缺失数据(通常表示为 NaN 值)。这个方法可以以多种方式填充DataFrame或Series中的缺失值。以下是 fillna() 方法的一些基本用法和参数总结:
基本用法
1.填充固定值
df.fillna(value, inplace=False)value: 用于替换缺失值的具体值。可以是标量(如0、'missing'等)、列表、字典或Series。inplace: 默认为False,意味着操作不会改变原数据,而是返回一个新的对象。如果设置为True,则直接在原始数据上进行修改。
2.前向填充或后向填充
df.fillna(method='ffill' or 'bfill', limit=None, inplace=False)method: 可以是'ffill'(前向填充,使用前面的非空值填充缺失值)或'bfill'(后向填充,使用后面的非空值填充缺失值)。limit: 指定连续缺失值填充的最大数量。
参数说明
-
axis: 默认为
0,即按列进行填充。如果设置为1,则沿着行进行操作。 -
limit: 当使用
ffill或bfill方法时,限制连续NaN值被填充的最大数量。 -
downcast: (可选)尝试向下转换数据类型以节省内存,例如从
float64转换为float32。
实例
1.常值填充
df['column_name'].fillna(0, inplace=True)2.使用列的均值填充:
df['column_name'].fillna(df['column_name'].mean(), inplace=True)3.前向填充:
df.fillna(method='ffill', inplace=True)














 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









