






1.模型微调详细过程
通过上述步骤能够进入LLaMA Board的Web UI 界面,具体界面如下:
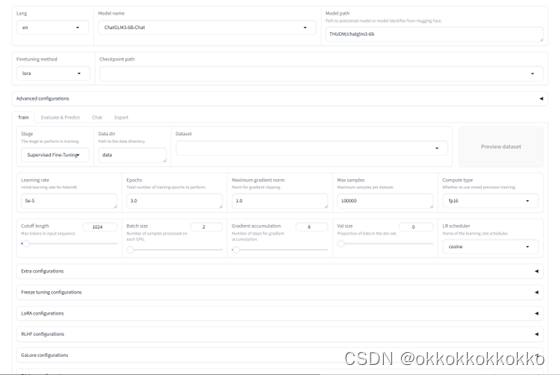
首先通过Lang更改语言为中文
选择下载好的模型名称,在此我们选用了ChatGLM3-6B作为我们的微调模型,并将其下带到了本地,在Linux服务器中放置,在模型路径中输入即可。

微调方法在此我们选择lora微调
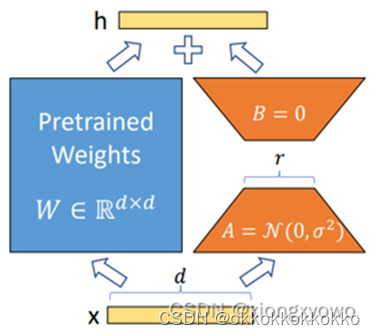
为什么选择lora微调?
- 计算和存储效率
LoRA技术通过引入低秩矩阵进行参数调整,减少了模型训练过程中需要更新的参数数量。相比传统的全参数微调方法,LoRA的参数更新量大大减少,极大地降低了计算成本和存储需求。因此,对于资源有限的环境,LoRA是一种更为高效的微调方法。
- 高效的多任务学习
通过LoRA,可以实现高效的多任务学习。由于其低秩矩阵更新机制,可以在一个共享的基础模型上进行多个任务的微调,这在需要同时处理多个旅游推荐场景(如不同类型的旅游目的地推荐)时尤为有用。
- 减少过拟合风险
LoRA通过低秩矩阵约束参数的更新,能够有效减少过拟合的风险。传统的全参数微调方法可能会在小数据集上出现过拟合现象,而LoRA的低秩适应机制则有助于保持模型的泛化能力。
- 更快的训练速度
由于LoRA只需微调少量参数,训练过程显著加快。特别是在需要频繁更新和测试的迭代开发过程中,LoRA可以显著提高开发效率。
-
具体应用在旅游推荐系统中的优势
-
个性化推荐:LoRA微调后的模型能够更好地理解用户的个性化需求,通过低秩矩阵调整模型参数,以提供更符合用户偏好的旅游推荐。
-
多样化数据处理:从马蜂窝、去哪儿、小红书等平台爬取的数据类型多样,通过LoRA微调可以使模型快速适应不同类型的数据,提高推荐系统的整体性能。
-
实时交互:LoRA微调后的模型具有更快的响应速度和更好的交互能力,能够实时处理用户输入,提供即时的旅游建议和反馈。
继续我们的微调
首先我们需要对数据集进行重构
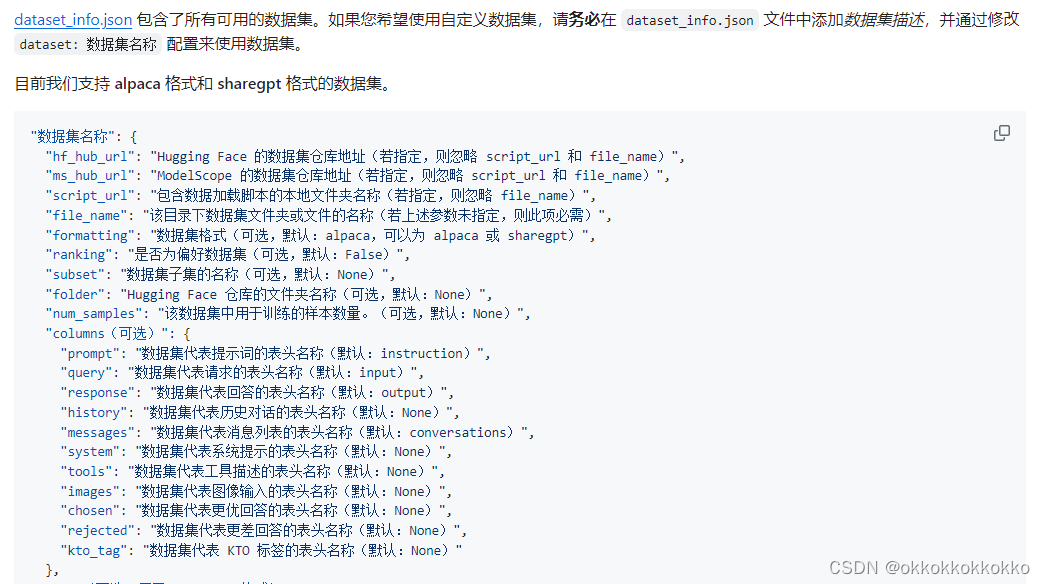 按照要求将我们的数据集信息写入data_info.json文件中,以便框架后续识别
按照要求将我们的数据集信息写入data_info.json文件中,以便框架后续识别
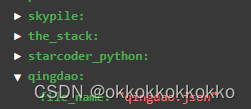
之后将我们的重构好的数据集放入对应文件夹即可,数据集结构要求如下:
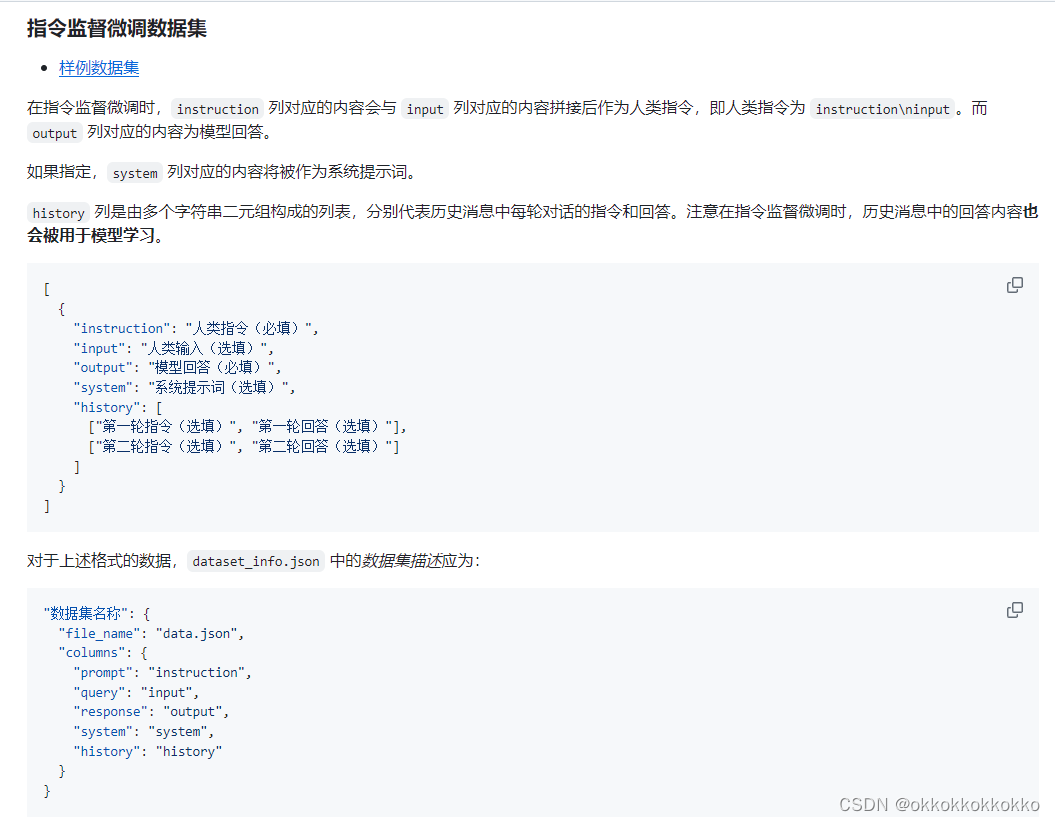
我们将原json重构,效果如下:
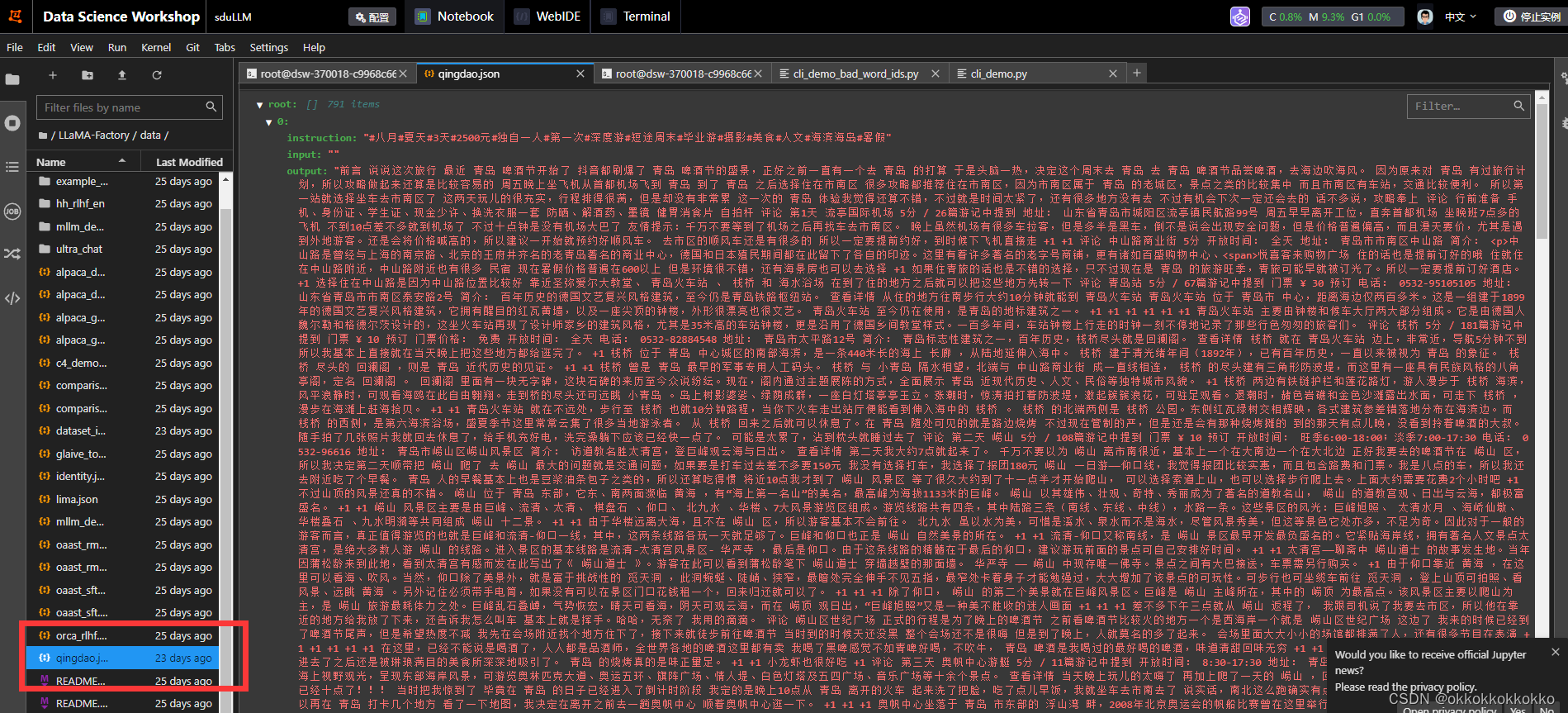
之后我们在webui中可以识别到该数据集,我们可以选择本地的模型路径和数据集
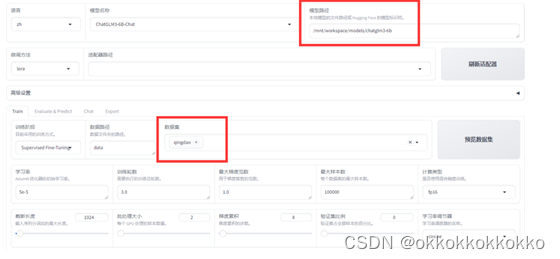
在高级设置中还可以对量化等级、提示模板、RoPE插值方法及加速方式进行选择,在此都选为默认方法。

在数据集中选择好我们的数据集后,设置我们想要的学习率等参数,就可以对模型进行微调训练了。
点击预览还可以查看数据集。
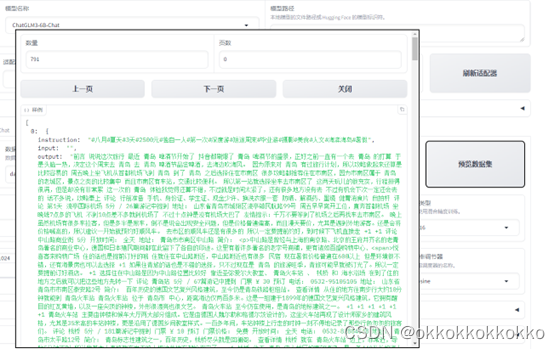
在此可以对一些参数进行设置:

每个参数的意义如下:
-
截断长度(Sequence Length/Max Token Length):
- 意义:表示在训练过程中,每个输入序列的最大长度(通常以词元/Token为单位)。
- 作用:影响内存使用和训练时间。较长的序列可以捕捉更多上下文信息,但会增加计算开销和内存需求。
-
学习率(Learning Rate):
- 意义:控制模型参数在每次更新时的调整幅度。
- 作用:学习率过高可能导致训练不稳定,甚至不收敛;学习率过低可能导致训练速度慢,陷入局部最优解。学习率需要适当调节以平衡训练效率和稳定性。
-
训练轮数(Epochs):
- 意义:完整训练数据集被用来更新模型参数的次数。
- 作用:更多的训练轮数可以让模型更好地拟合训练数据,但也可能导致过拟合。需要根据验证集的表现来确定合适的轮数。
-
最大样本数(Maximum Number of Samples):
- 意义:训练过程中使用的样本总数的上限。
- 作用:限制训练时间和计算资源的消耗。如果数据集很大,可以通过设置最大样本数来控制训练规模。
-
批处理大小(Batch Size):
- 意义:在一次前向和后向传播中使用的样本数。
- 作用:较大的批处理大小可以提高训练效率,利用GPU加速,但需要更多的内存;较小的批处理大小则有助于收敛稳定性,但训练时间较长。
-
梯度累积(Gradient Accumulation):
- 意义:在实际进行参数更新之前累积多个批次的梯度。
- 作用:相当于增大了有效的批处理大小而无需增加显存消耗,可以在显存有限的情况下实现较大批处理大小的效果。
-
学习率调节器(Learning Rate Scheduler):
- 意义:根据训练过程中的特定规则调整学习率。
- 作用:帮助模型在训练初期快速收敛,在后期稳定收敛,防止过拟合。例如,常见的调节器有余弦退火、指数衰减等。
-
最大梯度范数(Max Gradient Norm):
- 意义:梯度裁剪的阈值,用于限制梯度的最大范数。
- 作用:防止梯度爆炸,保证训练的稳定性。通过在参数更新之前对梯度进行裁剪来控制梯度的幅度。
修改本项目中的截断长度、学习率、训练轮数、最大样本数、批处理大小、梯度累积、学习率调节器、最大梯度范数为下图所示:

修改LoRA参数设置如下图所示:
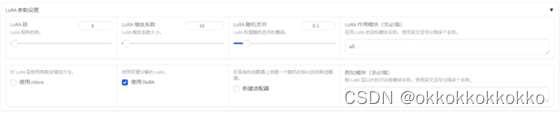
更改输出目录和配置路径

大功告成,现在可以预览命令并进行训练了
点击预览查看命令

点击开始进行训练
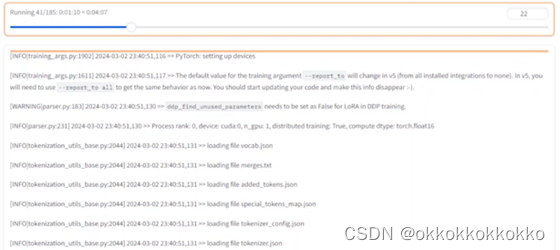
在右侧可以看到loss损失呈下降趋势
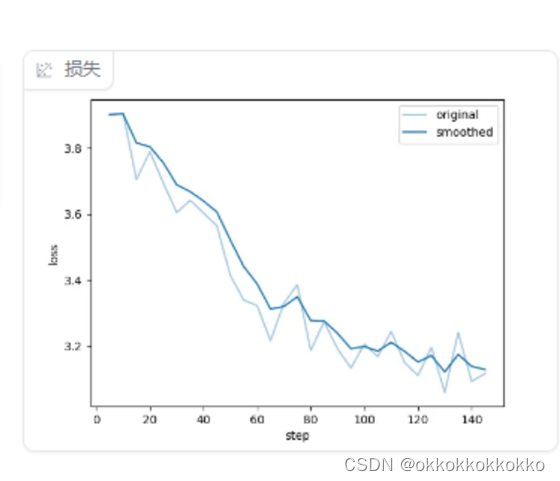
耐心等待,最终训练完毕,如下图:
2.模型加载与使用
训练完成后在本地已经有了微调之后的模型文件,可以借助web ui界面进行调用来试用。
选择Chat选项。
刷新适配器,得到刚刚训练好的适配器。

可以看到模型正在加载中。
等待模型加载完成,显示如下界面。
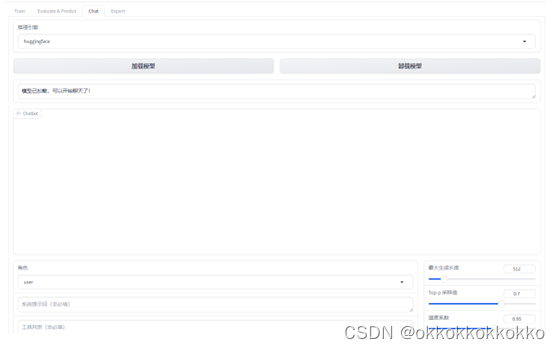
此时即可在此界面输入信息来询问模型。
询问以下问题:
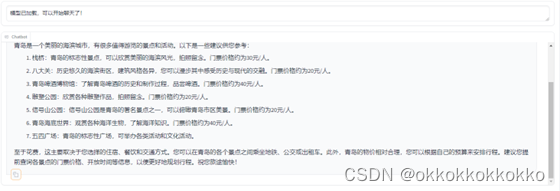
我去青岛可以去哪里玩,花费多少?
以下是模型回答:
而如果直接使用未训练的 ChatGLM3-6B 模型,回答如下:

可以看出,模型微调之后的回答相比之前的回答有了一些明显的改进:
-
结构更清晰:
- 微调之后的回答将景点按顺序列出,并且每个景点都有单独的编号,信息一目了然,更加方便阅读和查找。
- 微调之前的回答虽然也列出了景点,但有些信息混杂在一起,没有清晰的分段。
-
信息更加详细准确:
- 微调之后的回答对每个景点的描述更加具体,包括每个景点的门票价格,这对游客的行程规划非常有帮助。
- 微调之前的回答虽然也提到了一些门票价格,但有些价格不准确(例如栈桥实际是收费的,而非免费的),并且有些价格信息与实际不符(如啤酒博物馆和海底世界的价格)。
-
内容更全面:
- 微调之后的回答不仅涵盖了景点的推荐,还提到了行程规划的建议,包括交通方式、住宿、餐饮等。
- 微调之前的回答虽然也提供了景点推荐和价格估算,但缺乏关于如何更好地安排行程的具体建议。
-
语气更友好:
- 微调之后的回答在结尾加入了祝福语“祝您旅途愉快”,使得整体回答更加亲切和贴心。
- 微调之前的回答则显得较为中性和直接。
-
花费预估更灵活:
- 微调之后的回答在花费预估方面更加灵活,指出具体花费主要取决于住宿、餐饮和交通方式,提示用户根据自己的预算来安排,并建议提前查询各景点的信息。
- 微调之前的回答虽然也提到了花费估算,但相对来说没有那么灵活和具体。
3. 结果
在本次实训项目中,我们基于从马蜂窝、去哪儿和小红书等平台爬取的数据集,使用LoRA方法对ChatGLM3-6B模型进行了微调。通过实验,我们对模型的性能进行了评估,主要实验结果如下:
-
准确率:
- 微调后的模型在已知知识库中的检索比对准确率达到了70%-80%。这一结果表明,通过微调,模型在理解和生成与旅游相关的内容上有了显著提升。
-
对话质量:
- 微调前后的对比结果显示,微调后的模型在对话交互中表现出了更好的结构性和准确性。用户输入如“我去青岛可以去哪里玩,花费多少?”时,微调后的模型能够提供清晰、有条理且详细的回复,包括景点推荐、门票价格和行程安排等信息。
- 微调前的模型回答相对简单,缺乏具体的行程建议,某些信息也不准确。
-
用户体验:
- 微调后的模型在交互过程中表现出更高的亲和力。例如,在回答中增加了祝福语和贴心提示,使得用户体验更加友好和舒适。
- 花费预估方面,微调后的模型更加灵活,能根据不同的住宿、餐饮和交通方式提供合理建议。
-
性能优化:
- 使用LLaMA-Factory的LoRA微调技术,显著降低了训练时间和GPU显存消耗。相比传统的全参数微调方法,LoRA微调提供了3.7倍的加速比,同时在实际任务中的性能表现也更优。
4. 结论
本次项目通过对ChatGLM3-6B模型进行LoRA微调,成功构建了一个与风景对话的交互式旅游推荐系统。实验结果显示,微调后的模型在准确率、对话质量和用户体验方面均有显著提升。具体结论如下:
-
模型微调有效性:
- LoRA微调方法在减少计算成本和存储需求的同时,显著提升了模型的适应性和推荐准确性。模型能够更好地理解用户的个性化需求,并提供详尽且准确的旅游建议。
-
用户交互体验:
- 微调后的模型在对话过程中能够提供结构化、详细且友好的回复,使用户获得更佳的使用体验。这一特性对于旅游推荐系统尤为重要,能有效提升用户满意度和参与度。
-
系统性能优化:
- 通过LLaMA-Factory开源项目的技术支持,我们在训练效率和资源消耗方面取得了较大优化。LoRA微调技术在多任务学习、减少过拟合风险和加快训练速度方面展现了显著优势。
5. 未来工作
- 性能优化:
- 进一步微调模型:继续收集和标注更多高质量的旅游数据,对模型进行更细致的微调,提高模型对复杂问题的理解和回答能力。
- 增强模型的多语言支持:虽然目前的模型已经支持中文,但我们将进一步优化其在其他语言环境下的表现,以便服务更多国际用户。
- 新增功能:
- 实时天气预报:集成天气API,使系统能够根据用户所选旅游目的地和时间,提供实时的天气预报和穿衣建议。
- 个性化行程规划:开发智能行程规划功能,根据用户的兴趣爱好和时间安排,提供个性化的旅游行程建议,包括景点、餐饮、住宿等方面的推荐。
- 与LangChain框架结合:
- 对话管理优化:利用LangChain框架对对话流进行更加精细的管理,提高系统对复杂对话场景的处理能力。
- 任务链集成:通过LangChain框架将不同的任务模块有机结合,实现从用户输入到旅游推荐的自动化流程,提高系统的整体效率和用户体验。
- 制作Web页面:
- 前端设计与开发:设计并开发一个用户友好的Web页面,使用户能够方便地在线与微调后的模型进行问答。前端页面将具备良好的视觉设计和交互体验,支持多种设备访问。
- 后端集成与部署:利用LangChain框架,将微调后的模型集成到后端服务中,并部署到云服务器上,确保系统的稳定性和可扩展性。
- 用户账户与数据管理:开发用户账户管理功能,支持用户注册、登录、数据保存和个性化设置等,提供更贴心的服务。
通过上述工作,我们将进一步提升交互式旅游推荐系统的功能和性能,为用户提供更加智能、便捷和个性化的旅游服务体验。我们的目标是打造一个全方位的智能旅游助手,满足用户在旅游规划、出行和分享等各方面的需求。















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









