







机器学习/深度学习中,需要使用训练数据来最小化损失函数,从而确定参数的值。而最小化损失函数,即需要求得损失函数的极值。
求解函数极值时,需要用到导数。对于某个连续函数
f
(
x
)
f(x)
f(x),令其一阶导数
f
′
(
x
)
=
0
f'(x)=0
f′(x)=0 ,通过求解该微分方程,便可直接获得极值点。但当变量很多或者函数很复杂时,
f
′
(
x
)
=
0
f'(x)=0
f′(x)=0的显式解并不容易求得。且计算机并不擅长于求解微分方程。
计算机所擅长的是,凭借强大的计算能力,通过插值等方法(如牛顿下山法、弦截法等),海量尝试,一步一步的去把函数的极值点“试”出来。
而海量尝试需要一个方向感,为了阐述这个方向感,介绍一下方向导数。
- 方向导数
方向导数是偏导数的概念的推广, 偏导数研究的是指定方向 (坐标轴方向) 的变化率,到了方向导数,研究哪个方向可就不一定了。
函数在某一点处的方向导数在其梯度方向上达到最大值,此最大值即梯度的范数。 - 梯度
在一个数量场中,函数在给定点处沿不同的方向,其方向导数一般是不相同的。那么沿着哪一个方向其方向导数最大,其最大值为多少,这是我们所关心的,为此引进一个很重要的概念: 梯度。
函数在某一点处的方向导数在其梯度方向上达到最大值。
这就是说,沿梯度方向,函数值增加最快。同样可知,方向导数的最小值在梯度的相反方向取得,此最小值为最大值的相反数,从而沿梯度相反方向函数值的减少最快。 - 梯度值
在单变量的实值函数中,梯度可简单理解为只是导数,或者说对于一个线性函数而言,梯度就是曲线在某点的斜率。
对于多维变量的函数,比如在一个三维直角坐标系,该函数的梯度就可以表示为公式
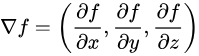
为求得这个梯度值,要用到“偏导”的概念。
γ \gamma γ 在机器学习中常被称为学习率 ( learning rate ), 也就是上面梯度下降法中的步长。
通过算出目标函数的梯度(算出对于所有参数的偏导数)并在其反方向更新完参数 Θ \Theta Θ ,在此过程完成后也便是达到了函数值减少最快的效果,那么在经过迭代以后目标函数即可很快地到达一个极小值。如果该函数是凸函数,该极小值也便是全局最小值,此时梯度下降法可保证收敛到全局最优解。
梯度下降由梯度方向,和步长决定,每次移动一点点。但是每一次移动都是对你所在的那个点来说,往极值方向,所以能够保证收敛。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









