






 文章介绍了Pandas库中的DataFrame对象,包括使用pd.read_csv加载CSV数据,利用loc和iloc进行数据索引,以及通过布尔数组进行条件选择。此外,还提到了Series与DataFrame的关系,以及如何通过query和groupby进行复杂的数据筛选和分组。
文章介绍了Pandas库中的DataFrame对象,包括使用pd.read_csv加载CSV数据,利用loc和iloc进行数据索引,以及通过布尔数组进行条件选择。此外,还提到了Series与DataFrame的关系,以及如何通过query和groupby进行复杂的数据筛选和分组。
lec3 Pandas, Part1
DataFrames
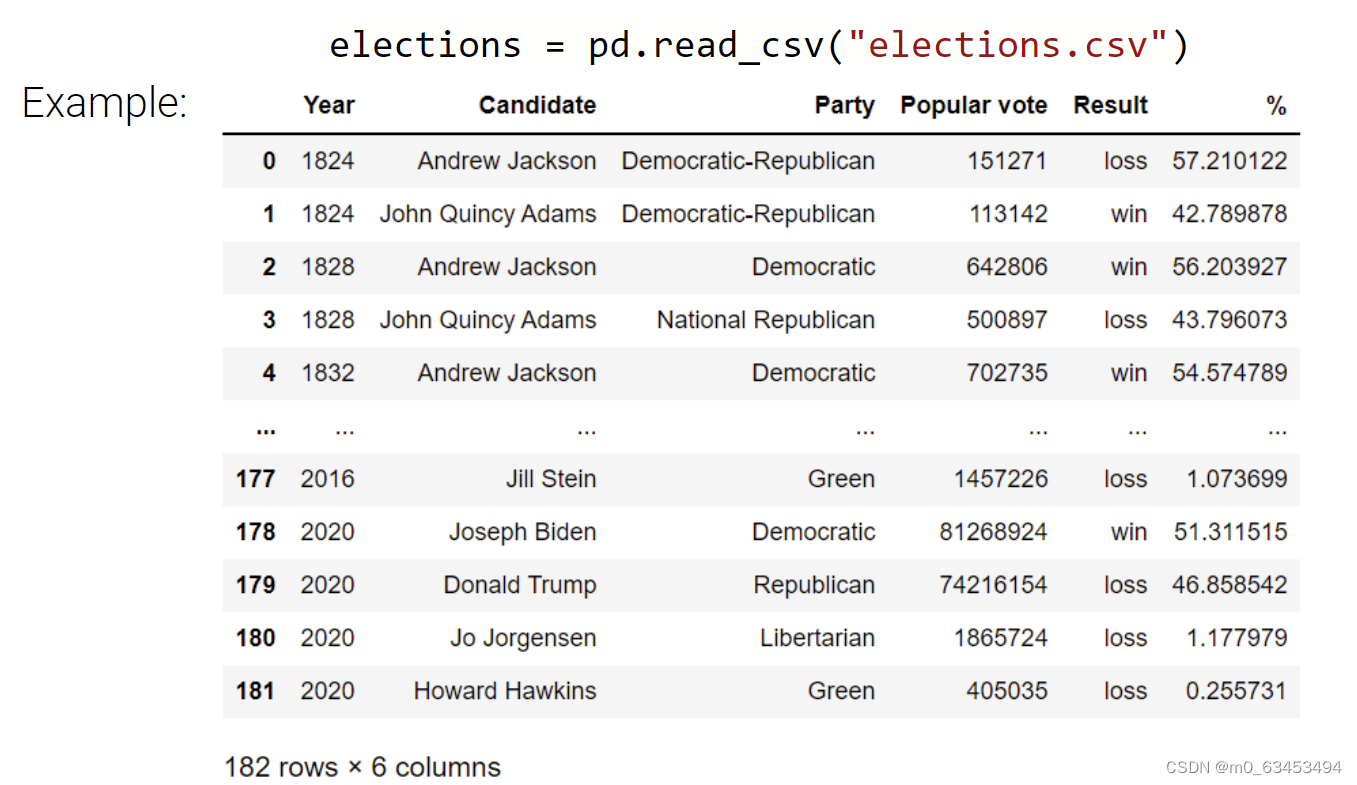
通过pd.read_csv()读取csv文件,获取表格,这是最常用的数据格式(Tabular data)
The API for the DataFrame class is enormous.
Full documentation is at https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
- Compare with the Table class from Data8: http://data8.org/datascience/tables.html
- We will only consider a tiny portion of this API.
Indexing with loc, iloc, and []
elections.loc[0:4]
获取从0-4行的数据,包括4
elections.head(5)
获取前五行数据
elections.tail(5)
获取最后五行数据、
elections.loc[0:4, “Year”:“Party”]
首先,对行切片,从0-4(包括0、4)
再对列切片,从Year到Party
loc
参数可以是
- 列表
- 切片(前闭后闭)
- single value
elections.loc[[1,5,2], [“Year”,“Party”]]
iloc(和loc的显著差别是,loc可以使用label名来获取,而iloc只能传入数字)
iloc selects items by number
参数可以是
- 列表
- 切片(前闭后开?)
- single value
loc vs. iloc
通常使用loc
- 当列的顺序被打乱,loc的代码可能仍然有效
- elections.loc[ : , [“Year”, "Candidate]]比xxx.iloc[ : , [0, 1]]更容易理解
[]
[] only takes one argument, which may be:
- A slice of row numbers.(左闭右开)
- A list of column labels.
- A single column label.
总结
Selection operators:
- loc selects items by label. First argument is rows, second argument is columns.
- iloc selects items by number. First argument is rows, second argument is columns.
- [] only takes one argument, which may be:
- A slice of row numbers.
- A list of column labels.
- A single column label.
实践上,[]更加常用
- 对于许多常见的用例来说,[]的语法更加简洁
- []在现实世界中比loc更常见
DataFrames, Series, and Indices
在之前会发现,在获取dataframe的单个列的时候,输出的似乎不是一种表格的形式,看起来是一种纯文本
可以发现:
type(elections)
将得到:
pandas.core.frame.DataFrame
而
type(elections[“Candidate”])
将得到:
pandas.core.series.Series
Data Frame与Series的关系
我们可以将Data Frame看作是一组Series组成的,他们共享着相同的index

如何将Series转换为Data Frame:
- 使用to_frame()
- elections[“Candidate”].tail(5).to_frame()
- 将列索引改为列表形式
- elections[[“Candidate”]].tail(5)
Index
Index可以是非数字的,构成索引的行标签可以不是唯一的
Sometimes you’ll want to extract the list of row and column labels.
- For row labels, use DataFrame.index
- For column labels, use DataFrame.columns
Conditional Selection
Boolean Array Input
Another input type supported by loc and [] is the boolean array.
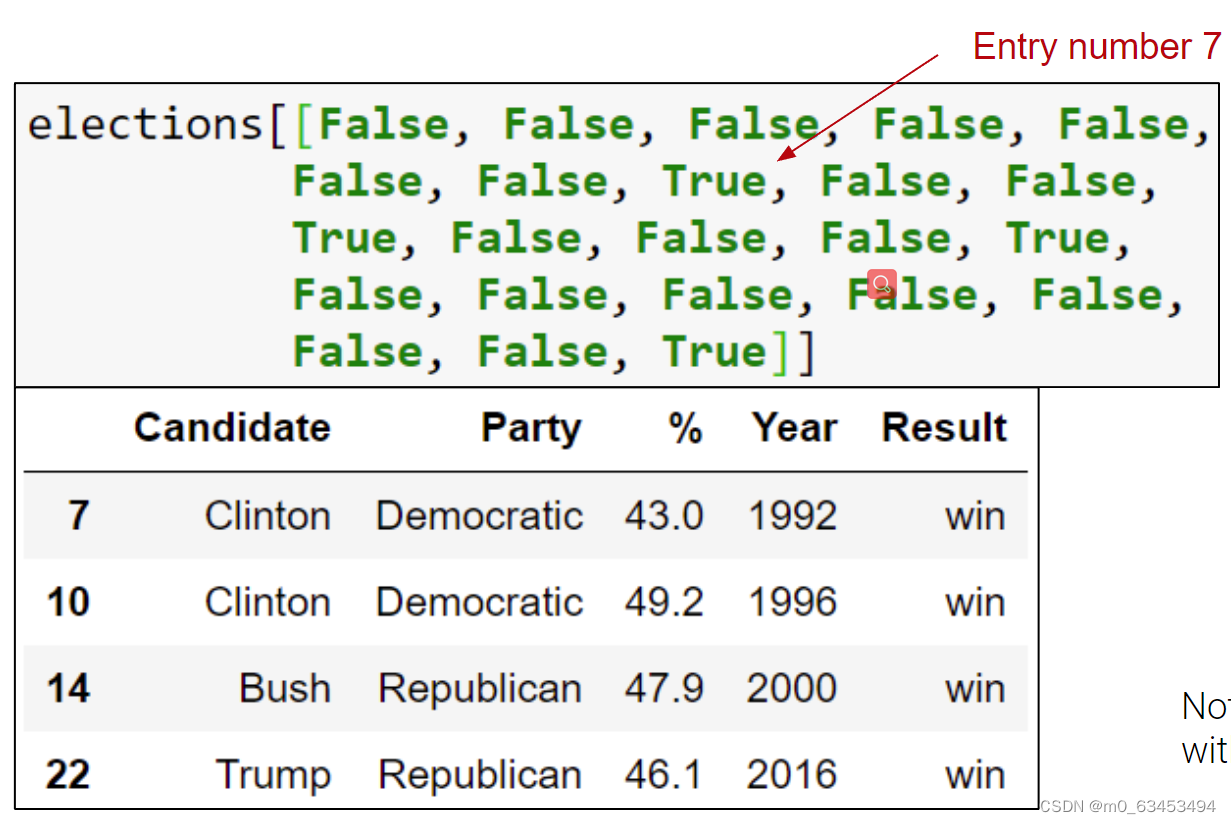
Useful because boolean arrays can be generated by using logical operators on Series.
可以为[]或者loc传入一个Boolean数组,将会得到在Boolean数组为true的索引位置的实际value
这提供了很大的便利,因为:
- Boolean数组可以使用Series的逻辑运算符给出
- 布尔序列可以使用各种运算符组合,允许根据多个标准过滤结果
但是,当你在筛选某个列index可以满足多个条件的时候,将会非常麻烦
elections[(elections["Party"] == "Anti-Masonic") |
(elections["Party"] == "American") |
(elections["Party"] == "Anti-Monopoly") |
(elections["Party"] == "American Independent")]
panda提供了一些方法:
- .isin
a_parties = ["Anti-Masonic", "American", "Anti-Monopoly", "American Independent"] elections[elections["Party"].isin(a_parties)] - .str.startswith
elections[elections["Party"].str.startswith("A")] - .query
- Query has a rich syntax.
- Can access Python variables with the special @ character
elections.query('Year >= 2000 and Result == "win"') parties = ["Republican", "Democratic"] elections.query('Result == "win" and Party not in @parties') - .groupby.filter (see lecture 4)
Handy Utility Functions
np.mean(winners)求平均数
max(winners)求最大值
- size/shape
- describe
- sample获得简单随机样本,参数是期望获得的样本大小,同时还可以设置replace = True,这样,这个随机抽样就是可放回的
- value_counts: counts the number of occurrences of a each unique value in a Series.
- uniques:returns an array of every unique value in a Series.
- sort_values:The DataFrame.sort_values and Series.sort_values methods sort a DataFrame (or Series).
- The DataFrame version requires an argument specifying the column on which to sort
elections.sort_values("%", ascending = False)//第二个参数是升降序

















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









