






目录

Flink作为数据处理框架,最终还是要把计算处理结果写入外部存储,为外部应用提供支持
1. 连接到外部系统
在 Flink 中,如果我们希望将数据写入外部系统,其实并不是一件难事。我们知道所有算 子都可以通过实现函数类来自定义处理逻辑,所以只要有读写客户端,与外部系统的交互在任 何一个处理算子中都可以实现。例如在 MapFunction 中,我们完全可以构建一个到 Redis 的连 接,然后将当前处理的结果保存到 Redis 中。如果考虑到只需建立一次连接,我们也可以利用 RichMapFunction,在 open() 生命周期中做连接操作。
这样看起来很方便,却会带来很多问题。Flink 作为一个快速的分布式实时流处理系统, 对稳定性和容错性要求极高。一旦出现故障,我们应该有能力恢复之前的状态,保障处理结果 的正确性。这种性质一般被称作“状态一致性”。Flink 内部提供了一致性检查点(checkpoint) 来保障我们可以回滚到正确的状态;但如果我们在处理过程中任意读写外部系统,发生故障后 就很难回退到从前了。
为了避免这样的问题,Flink 的 DataStream API 专门提供了向外部写入数据的方法: addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外 部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算 子完成的。
Sink 一词有“下沉”的意思,有些资料会相对于“数据源”把它翻译为“数据汇”。不论 怎样理解,Sink 在 Flink 中代表了将结果数据收集起来、输出到外部的意思,所以我们这里统 一把它直观地叫作“输出算子”。
之前我们一直在使用的 print 方法其实就是一种 Sink,它表示将数据流写入标准控制台打 印输出。查看源码可以发现,print 方法返回的就是一个 DataStreamSink。

与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是 通过调用 DataStream 的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));
addSource 的参数需要实现一个 SourceFunction 接口;类似地,addSink 方法同样需要传入 一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指 定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
default void invoke(IN value, Context context) throws Exception当然,SinkFuntion 多数情况下同样并不需要我们自己实现。Flink 官方提供了一部分的框 架的 Sink 连接器。如图所示,列出了 Flink 官方目前支持的第三方系统连接器:

我们可以看到,像 Kafka 之类流式系统,Flink 提供了完美对接,source/sink 两端都能连 接,可读可写;而对于 Elasticsearch、文件系统(FileSystem)、JDBC 等数据存储系统,则只 提供了输出写入的 sink 连接器。 除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一 些其他第三方系统与 Flink 的连接器,如图 5-14 所示。

除此以外,就需要用户自定义实现 sink 连接器了。
2. 输出到文件
最简单的输出方式,当然就是写入文件了。对应着读取文件作为输入数据源,Flink 本来 也有一些非常简单粗暴的输出到文件的预实现方法:如 writeAsText()、writeAsCsv(),可以直 接将输出结果保存到文本文件或 Csv 文件。但我们知道,这种方式是不支持同时写入一份文件的;所以我们往往会将最后的 Sink 操作并行度设为 1,这就大大拖慢了系统效率;而且对于故障恢复后的状态一致性,也没有任何保证。所以目前这些简单的方法已经要被弃用。
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类 RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly once)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink 支持的文件系统。它可以保证精确一次的状态一致性,大大改进了之前流式文件 Sink 的方式。 它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分 区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶” 的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保 存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet) 格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用 StreamingFileSink 的静态方法:
⚫ 行编码:StreamingFileSink.forRowFormat(basePath,rowEncoder)。
⚫ 批量编码:StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径 (basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。 下面我们就以行编码为例,将一些测试数据直接写入文件:
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.util.concurrent.TimeUnit;
public class SinkToFileTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
DataStreamSource<Event> stream = env.fromElements(new Event("Mary",
"./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
StreamingFileSink<String> fileSink = StreamingFileSink
.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15)
)
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5
))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
// 将 Event 转换成 String 写入文件
stream.map(Event::toString).addSink(fileSink);
env.execute();
}
}这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策 略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以 我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
⚫ 至少包含 15 分钟的数据
⚫ 最近 5 分钟没有收到新的数据
⚫ 文件大小已达到 1 GB
3. 输出到Kafka
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为 Flink 的输入数据源和输出系统。Flink 官方为 Kafka 提供了 Source 和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明 不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是,Flink 与 Kafka 的连接器提供了端 到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。关于 这部分内容,我们会在后续章节做更详细的讲解。
现在我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
(1)添加 Kafka 连接器依赖
(2)启动 Kafka 集群
(3)编写输出到 Kafka 的示例代码 我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主 题(topic)命名为“clicks”。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class SinkToKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");
stream
.addSink(new FlinkKafkaProducer<String>(
"clicks",
new SimpleStringSchema(),
properties
));
env.execute();
}
}这里我们可以看到,addSink 传入的参数是一个 FlinkKafkaProducer。这也很好理解,因为 需要向 Kafka 写入数据,自然应该创建一个生产者。FlinkKafkaProducer 继承了抽象类 TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提 交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状 态一致性。关于这部分内容,我们会在后续章节展开介绍。
(4)运行代码,在 Linux 主机启动一个消费者, 查看是否收到数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic clicks我们可以看到消费者可以正常消费数据,证明向 Kafka 写入数据成功。另外,我们也可以 读取 5.2 节中介绍过的任意数据源,进行更多的完整测试。比较有趣的一个实验是,我们可以 同时将 Kafka 作为 Flink 程序的数据源和写入结果的外部系统。只要将输入和输出的数据设置 为不同的 topic,就可以看到整个系统运行的路径:Flink 从 Kakfa 的一个 topic 读取消费数据, 然后进行处理转换,最终将结果数据写入 Kafka 的另一个 topic——数据从 Kafka 流入、经 Flink 处理后又流回到 Kafka 去,这就是所谓的“数据管道”应用。
4. 输出到redis
Redis 是一个开源的内存式的数据存储,提供了像字符串(string)、哈希表(hash)、列表 (list)、集合(set)、排序集合(sorted set)、位图(bitmap)、地理索引和流(stream)等一系 列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构 优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目还是担任了合格的辅助角色,为我们提供了 Flink-Redis 的连接工具。但版本升级略显滞后,目前连接器版本为 1.0,支持的 Scala 版本最新到 2.11。由于我们的测试不涉及到 Scala 的相关版本变化,所以并不影响使用。 在实际项目应用中,应该以匹配的组件版本运行。
具体测试步骤如下:
(1)导入的 Redis 连接器依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>(2)启动 Redis 集群
这里我们为方便测试,只启动了单节点 Redis。
(3)编写输出到 Redis 的示例代码
连接器为我们提供了一个 RedisSink,它继承了抽象类 RichSinkFunction,这就是已经实现 好的向 Redis 写入数据的 SinkFunction。我们可以直接将 Event 数据输出到 Redis:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
public class SinkToRedisTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 创建一个到 redis 连接的配置
FlinkJedisPoolConfig conf = new
FlinkJedisPoolConfig.Builder().setHost("hadoop102").build();
env.addSource(new ClickSource())
.addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
env.execute();
}
}这里 RedisSink 的构造方法需要传入两个参数:
⚫ JFlinkJedisConfigBase:Jedis 的连接配置
⚫ RedisMapper:Redis 映射类接口,说明怎样将数据转换成可以写入 Redis 的类型 接下来主要就是定义一个 Redis 的映射类,实现 RedisMapper 接口。
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class MyRedisMapper implements RedisMapper<Event> {
@Override
public String getKeyFromData(Event e) {
return e.user;
}
@Override
public String getValueFromData(Event e) {
return e.url;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "clicks");
}
}在这里我们可以看到,保存到 Redis 时调用的命令是 HSET,所以是保存为哈希表(hash),表名为“clicks”;保存的数据以 user 为 key,以 url 为 value,每来一条数据就会做一次转换。
5. 输出到Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。ElasticSearch 有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域 应用非常广泛。 Flink 为 ElasticSearch 专门提供了官方的 Sink 连接器,Flink 1.13 支持当前最新版本的 ElasticSearch。 写入数据的 ElasticSearch 的测试步骤如下。
(1)添加 Elasticsearch 连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>(2)启动 Elasticsearch 集群
(3)编写输出到 Elasticsearch 的示例代码
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.HashMap;
public class SinkToEsTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
// 创建一个 ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new
ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer
indexer) {
HashMap<String, String> data = new HashMap<>();
data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type") // Es 6 必须定义 type
.source(data);
indexer.add(request);
}
};
ElasticsearchSink.Builder<Event> esBuilder = new ElasticsearchSink.Builder<Event>(httpHosts,
elasticsearchSinkFunction);
stream.addSink(esBuilder.build());
env.execute();
}
}
与 RedisSink 类 似 , 连 接 器 也 为 我 们 实 现 了 写 入 到 Elasticsearch 的 SinkFunction——ElasticsearchSink。区别在于,这个类的构造方法是私有(private)的,我们 需要使用 ElasticsearchSink 的 Builder 内部静态类,调用它的 build()方法才能创建出真正的 SinkFunction。 而 Builder 的构造方法中又有两个参数:
⚫ httpHosts:连接到的 Elasticsearch 集群主机列表
⚫ elasticsearchSinkFunction:这并不是我们所说的 SinkFunction,而是用来说明具体处 理逻辑、准备数据向 Elasticsearch 发送请求的函数
具体的操作需要重写中 elasticsearchSinkFunction 中的 process 方法,我们可以将要发送的 数据放在一个 HashMap 中,包装成 IndexRequest 向外部发送 HTTP 请求。
6. 输出到MySQL
关系型数据库有着非常好的结构化数据设计、方便的 SQL 查询,是很多企业中业务数据 存储的主要形式。MySQL 就是其中的典型代表。尽管在大数据处理中直接与 MySQL 交互的 场景不多,但最终处理的计算结果是要给外部应用消费使用的,而外部应用读取的数据存储往 往就是 MySQL。所以我们也需要知道如何将数据输出到 MySQL 这样的传统数据库。
写入数据的 MySQL 的测试步骤如下。
(1)添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>(2)打开MySQL,建表
create table clicks(user varchar(20) not null,url varchar(100) not null);
(3)代码
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinkToMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/flink_test")
// 对于 MySQL 5.7,用"com.mysql.jdbc.Driver"
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("root")
.build()
)
);
env.execute();
}
}(4)查看是否成功写入数据
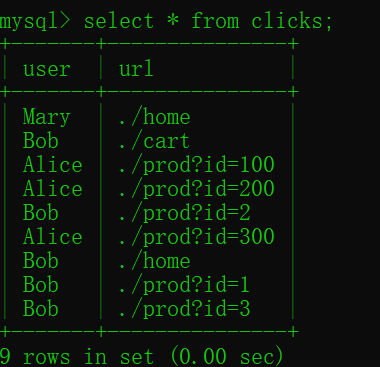
7. 自定义Sink输出
如果我们想将数据存储到我们自己的存储设备中,而 Flink 并没有提供可以直接使用的连接器,又该怎么办呢? 与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction 抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外 部存储。之前与外部系统的连接,其实都是连接器帮我们实现了 SinkFunction,现在既然没有 现成的,我们就只好自力更生了。例如,Flink 并没有提供 HBase 的连接器,所以需要我们自 己写。 在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可 以实现将流里的数据发送出去的逻辑。 我们这里使用了 SinkFunction 的富函数版本,因为这里我们又使用到了生命周期的概念, 创建 HBase 的连接以及关闭 HBase 的连接需要分别放在 open()方法和 close()方法中。
(1)导入依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>(2)实例代码
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import java.nio.charset.StandardCharsets;
public class SinkCustomtoHBase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration
configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入
public Connection connection; // 管理 Hbase 连接
@Override
public void open(Configuration parameters) throws
Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102:2181");
connection =
ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws
Exception {
Table table =
connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new
Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
}
}















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









