







1、Introduction
深度卷积网络好在哪里?
-----它可以加很多层,把网络变得很深,不同程度的层可以得到不同等级的特征。
作者提出一个问题--一个网络只是简单的堆叠就好了嘛?
——不是,当网络变得很深的时候,梯度会出现爆炸或者消失。一个解决方法,初始化时设置一个合适的权重,不要太大也不要太小。又或者在中间加入normalization(包括BN),可以使得校验每个层之间的那些输出和它梯度的那些均值和方差。上述两个方法可以让网络收敛,但是网络变深后,性能会变差(不是过拟合造成的,因为训练误差和测试误差都会变得很差),所以现在网络虽然收敛了,但是不能得到一个好的效果。
考虑一个比较浅的网络版本和一个比较深的网络版本(所谓深的版本是在所说的浅的网络中多加一些层进去),作者说如果你的浅的网络效果还不错的话,理论上深的网络是不应该变差的,因为深的网络加的那些层,总是可以把那些层学的变成一个恒等映射(identity mapping)。实际上做不到,SGD找不到这样一个优解。
这篇文章提出了一个方法,使得显示的构造出一个 identity mapping,深的网络不会变得比浅的网络差。作者命名为deep residual learning framework 。
2、结构
X 为浅层网络的输出。如果我们想要得到的映射为H(X),则我们让添加的非线性网络层去拟合残差映射F(X):=H(X)-X。原始的映射就可以写成F(X)+X。
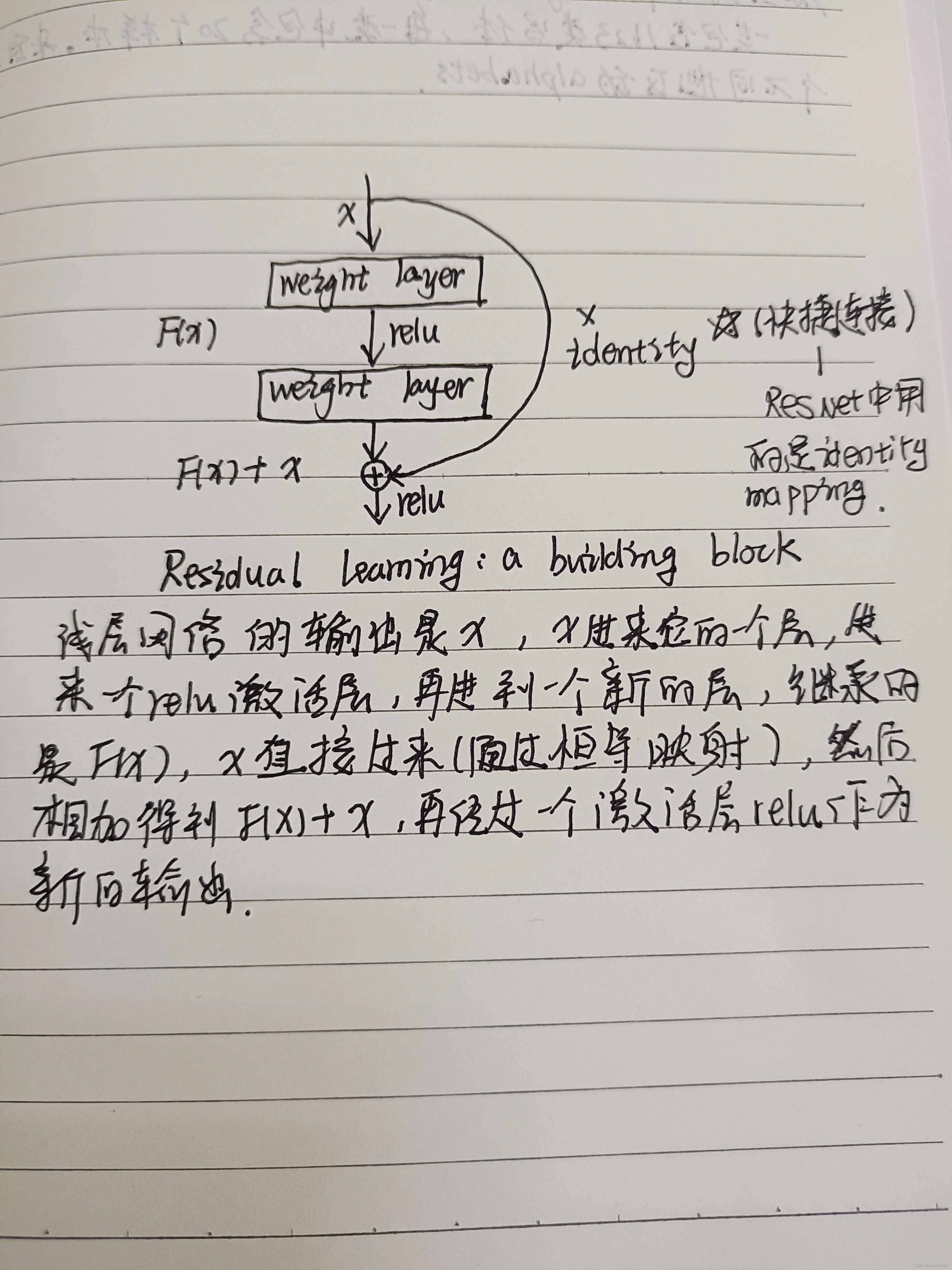
shortcut connection快捷连接通常会跳过 1 个或者多个层,在 ResNet 中快捷连接直接运用了 identity mapping,意思就是将一个卷积栈的输入直接与这个卷积栈的输出相加。
这样有什么好处呢?
- 并没有增加新的参数
- 整个网络也仍然可以由 SGD 进行训练。
- 容易被通用的神经网络框架实现。
F(X)和X直接相加,因此需要保证他们的维度一定要一样。
如何处理输入和输出不同形状的情况?
---第一种,在输入和输出上添加一些额外的零,使得这两个形状能够对应起来,然后可以相加。
--第二种,投影,使用一个1×1卷积调整通道,使得形状可以对应起来。(1×1卷积层特点--在空间维度上不做任何的东西,主要是在通道维度上做改变,选择一个1×1卷积使得输出通道是输入通道的两倍,这样就能将残差连接的输入和输出对应起来。在ResnNet里面,如果把输出通道数翻了两倍,那么输入的高和宽会减小一半,所以这里步幅设置为2,使在高宽和通道上都能匹配上)。第三种,所有连接都做投影。(这里在论文中有做实验比较三种处理方法的优劣)
各种层数的残差结构
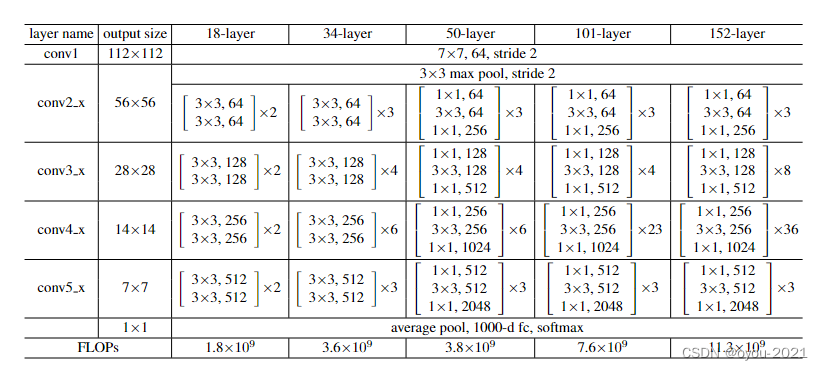
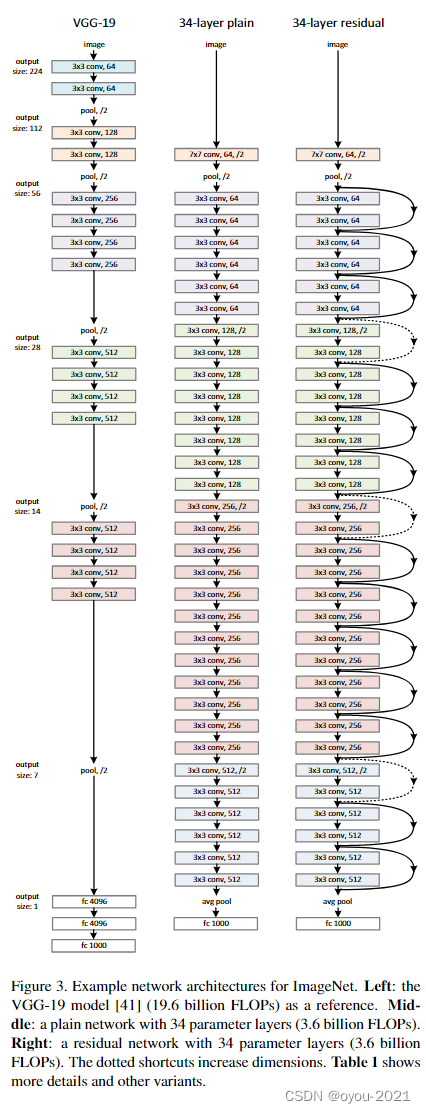
残差网络结构(以34层为例)--VGG-19是浅层网络
更深的残差网络结构(50层以上),结构有所不同,设计了一个bottleneck结构
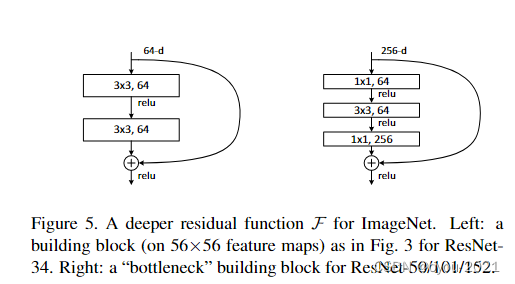
通道数为256时,变得很大,出现的问题是计算复杂度会很高,这里做法是通过1×1卷积投影映射回64维,再做一个3×3通道数不变的卷积,然后再通过1×1卷积投影回去256维,因为输入是256维u,输出要匹配上,这样设计之后复杂度就跟左图差不多了。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









