






SVM介绍
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,SVM可以用于线性和非线性分类问题,回归以及异常值检测
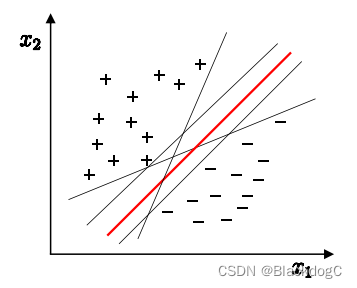
其基本原理是通过在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点到超平面的距离最大化。
最大间隔与分类
如何做到分类

超平面方程

最大间隔的推导与求解
划分超平面又w与b共同决定,空间中任意点到超平面的距离可表示为

如果能做到正确分类,则有以下式子

距离超平面最近的几个点使得式子成立,这几个点被称为支持向量
其中表示的是两个异类支持向量到超平面的距离之和为
,被称为"间隔"
所以为了最大化间隔,只需要最小化
对偶问题
我们希望求解式:
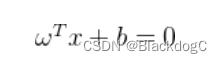
来得到大间隔划分超平面所对应的模型,其中 ω 与 b 是模型参数。我们看到上面的SVM的基本型本身是一个凸二次规划问题。这里采用拉格朗日乘子法可得到其"对偶问题",也就是每条约束添加拉格朗日乘子ai>=0;
![]()
其中 α=(α1,α2,... ,αm). 令 L(ω,b,α) 对 ω 和 b 的偏导为零可得

将上式代回,即可得式,“对偶问题”:
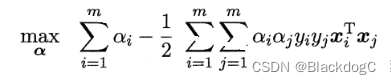
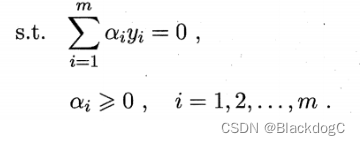
解出 α 后,求出 ω 与 b 即可得到模型
![]()
这显示出支持向量机的一个重要性质:训练完成后?大部分的训练样本都不需
保留,最终模型仅与支持向量有关。
核函数
我们假设训练样本是线性可分的,即存在一个划分超平面能将训练样本正确分类。然而在现实任务中,原始的样本空间内,也许并不存在一个能正确划分两类样本的超平面。比如下面"异或"问题就不是线性可分的:

这时可将样本从原始空间映射到更高维的特征空间,使得样本在这个特征空间内线性可分。例如在上图,若将原始的二维空间映射到一个合适的三维空间,就能找到一个合适的划分超平面。对于任意维度,只要原始样本空间为有限维,那么就一定有一个更高维特征空间使样本可分。
令 ![]() 表示将 x 映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为:
表示将 x 映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为:
![]()
同理,与上面得式子类似,就是将单个x换为![]()

其对偶问题则是


最终的式子为:
![]()
这里便显示出了模型最优解可通过训练样本的核函数展开,这一展式亦称"支持向量展式 "。
但问题是xi的映射是什么样的,我们这里还是不能确定形式
这里给出一个定理:

只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用.事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射。换言之,任何一个核函数都隐式地定义了一个称为"再生核希尔伯特空间" (Reproducing Kernel Hilbert Space ,简称 RKHS) 的特征空间.
我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能至关重要。需注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式地定义了这个特征空间。于是,"核函数选择"成为支持向量机的最大变数。如果核函数选择不合适,则意味着将样本映射到了一个不太合适的特征空间,它的性能不佳。
在这里,列出了几种常用的核函数。
软间隔与正则化
引入“软间隔”的概念, 允许SVM在一些样本上不满足约束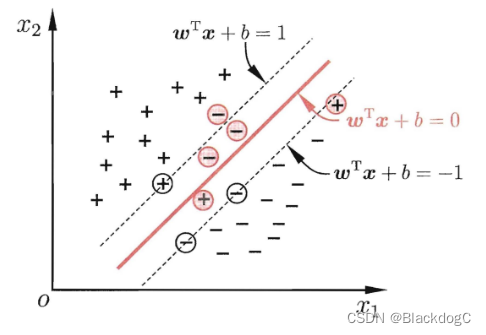
某些样本不需要满足:

当然,在最大化间隔的同时,不满足约束的样本应尽可能少.于是,优化目标可写为:

其中 C>0 是二个常数, 是 "0/1损失函数"

![]() 非凸、非连续,数学性质不太好,使得式优化目标函数不易直接求解.于是,人们通常用其他一些函数来代替
非凸、非连续,数学性质不太好,使得式优化目标函数不易直接求解.于是,人们通常用其他一些函数来代替, 称为"替代损失" (surrogate 10ss).。替代损失函数一般具有较好的数学性质,如它们通常是凸的连续函数且是
的上界。下面给出了三种常用的替代损失函数:

简单实现svm分类
准备数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
# 只做一个简单的二分类,获取分类是山鸢尾、杂色鸢尾的数据,同时取2维的特征就行了
x = x[y<2, :2]
y = y[y<2]
#分别绘制出分类是0和1的点,不同的scatter颜色不一样
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()

实现svm
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
#数据归一化
standardscaler = StandardScaler()
standardscaler.fit(x)
x_standard = standardscaler.transform(x)
svc = LinearSVC(C=1e9)
svc.fit(x_standard, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(np.linspace(axis[0], axis[1], int((axis[1] - axis[0])*100)).reshape(1, -1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2])*100)).reshape(1, -1),)
x_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(x_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
w = model.coef_[0]
b = model.intercept_[0]
# w0*x0 + w1*x1 + b = 0
# x1 = -w0/w1 * x0 - b/w1
plot_x = np.linspace(axis[0], axis[1], 200)
up_y = -w[0]/w[1] * plot_x - b/w[1] + 1/w[1]
down_y = -w[0]/w[1] * plot_x - b/w[1] - 1/w[1]
up_index = (up_y >= axis[2]) & (up_y <= axis[3])
down_index = (down_y >= axis[2]) & (down_y <= axis[3])
plt.plot(plot_x[up_index], up_y[up_index], color='black')
plt.plot(plot_x[down_index], down_y[down_index], color='black')
plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(x_standard[y==0, 0], x_standard[y==0, 1], color='red')
plt.scatter(x_standard[y==1, 0], x_standard[y==1, 1], color='blue')
plt.show()
















 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









